はじめに
前回、【論文読み】画像内の文字を自然に別の文字と入れ替えるSTEFANNの紹介という論文を紹介しましたが、関連手法の紹介です
まずSTEFANN: Scene Text Editor using Font Adaptive Neural Networkでは以下のような問題がありました
- 単語単位ではなく、文字単位で置換するため、置き換えたい文字が画像内のソースとなる文字と同じ長さという制限がある
- アルファベットのone-hotベクトルを使用して学習するため、多言語対応していない
SRNetはこの制限がなく、STEFANNより自由度の高い編集が可能です
SRNetのGitHubリポジトリはこちら
TL;DR
簡単にいうと
「オリジナルのスタイルを維持したまま、シーンテキスト画像からテキストを置き換えることができる、テキスト編集作業のためのEnd-to-Endネットワークを
- 前景テキストのスタイルを抽出し、スケルトンを用いて入力テキストに変換する
- スタイル画像を適切なテクスチャで消去して背景画像を得る
- 変換されたテキストを消去された背景にマージする
という3つのステップで実現する」手法です
下のように、画像内の文字を自然に編集することができます。(左が入力となるソース画像、右が出力画像)

手法
ネットワークモデルはこんな感じです
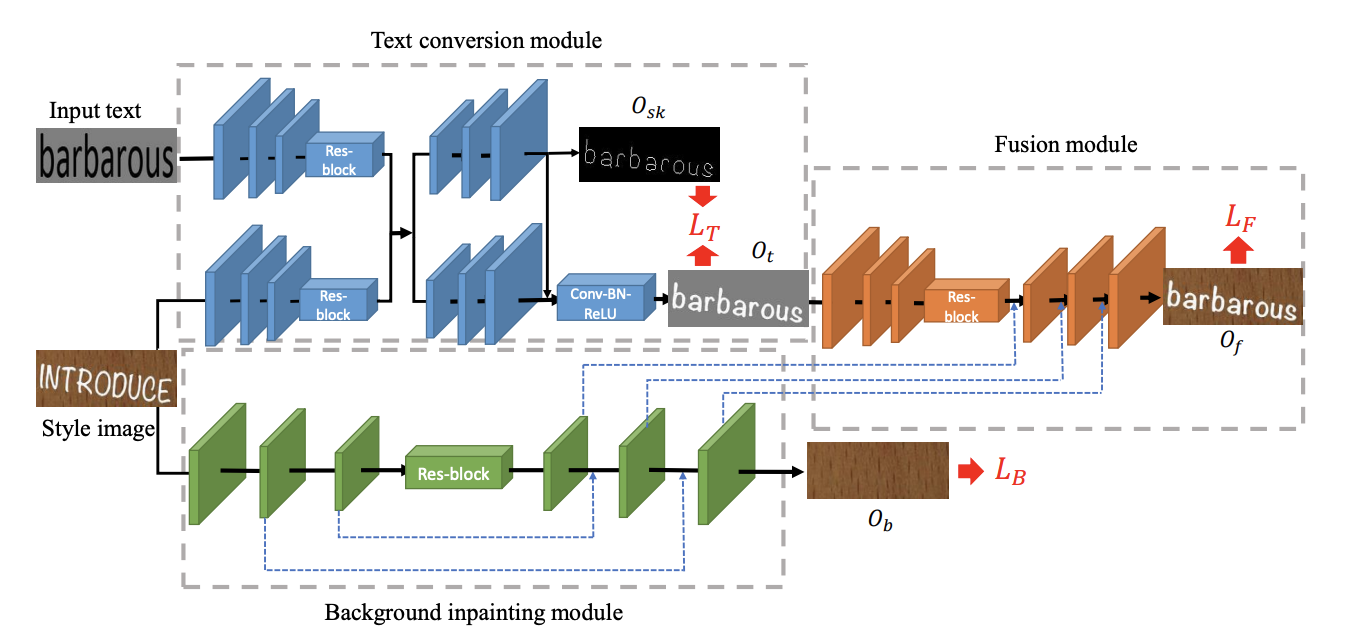
先ほどの3つのステップとモジュールの対応関係は以下のようになります
- 前景テキストのスタイルを抽出し、スケルトンを用いて入力テキストに変換する:Text conversion module
- スタイル画像を適切なテクスチャで消去して背景画像を得る:Background inpainting module
- 変換されたテキストを消去された背景にマージする:Fusion module
Text Conversion Module
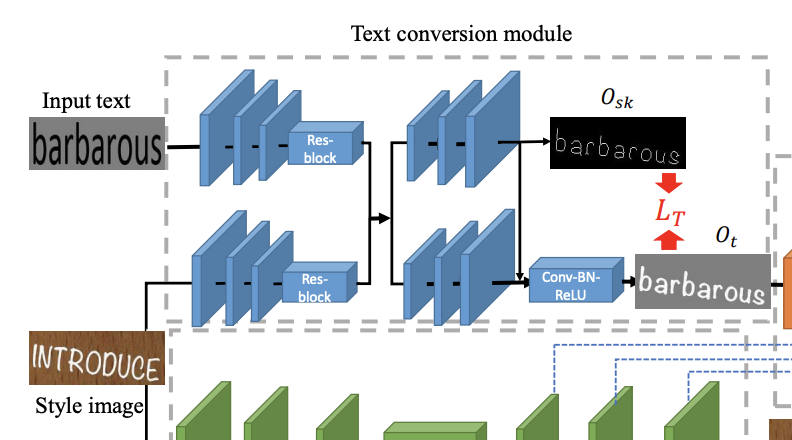
ソース画像$I_s$(モデル図でいうとStyle Image)と対象テキスト画像$I_t$(モデル図でいうとInput text)を入力として、$I_s$から文字部分のスタイルを抽出し、$I_t$の文字に変換します
ここで、特徴的なのがSkeleton-guided Learning Mechanismです。
簡単にいうと、人間は文字のスケルトン(フォントや色などの情報を除いた文字としての情報)を認識して、文字の意味を理解しているので、それを考慮して文字を変換しよう、ということです。
どう考慮するかというと、スケルトンと生成された文字を比較してスケルトン誤差とし、Text Conversion Moduleの誤差$L_T$に含めます。
Skeleton-guided Learning Mechanism 他の自然なオブジェクトとは異なり、人間は、テキストのスケルトンまたはグリフに応じて主に異なるテキストを区別します。そのためには、テキストスタイルを変換した後も、テキストのスケルトンを保持しておく必要がある。これを実現するために,本研究ではスケルトン学習機構を導入する.具体的には、3つのアップサンプリング層と1つの畳み込み層からなるスケルトン応答ブロックにシグモイド活性化関数を加えてシングルチャンネルのスケルトンマップを予測し、スケルトンヒートマップとデコーダ出力を深度軸に沿って連結する。スケルトン応答マップの再構成品質を測定するために、クロスエントロピー損失の代わりにサイコロ損失[18]を使用する。数学的には、スケルトン損失は次のように定義される。 ここで,$N$はpixellの数,$T_{sk}$はスケルトン基底真理値マップ,$O_{sk}$はスケルトンモジュールの出力マップである.さらにL1損失を採用してテキスト変換モジュールの出力を監視している。 スケルトンロスと組み合わせると、テキストコンバージョンロスは
詳しい内容(deepl翻訳)
レンダリング対象のテキストを、フォントと背景の画素値を127に固定した標準画像にレンダリングし、レンダリングした画像を対象テキスト画像$I_t$と呼ぶ。テキスト変換モジュール(図2の青色部分)は、元画像$I_s$と対象テキスト画像Itを入力として、元画像$I_s$から前景スタイルを抽出し、対象テキスト画像$I_t$に転送することを目的としている。特に、前景スタイルには、フォント、色、幾何学的変形などのテキストスタイルが含まれている。このようにして、テキスト変換モジュールは、対象テキストのセマンティクスと元画像のテキストスタイルを持つ画像$O_t$を出力する。
本研究では,エンコードデコーダFCNを採用している.符号化には,元画像を3つのダウンサンプリング畳み込み層と4つの残差ブロック[9]で符号化し,入力テキスト画像も同じアーキテクチャで符号化した後,2つの特徴量を深さ軸に沿って連結する.さらに、よりロバストなテキストを生成するために、スケルトンガイド学習機構を導入している。テキスト変換モジュールを表すために$G_T$を使用し、出力は次のように表現することができます。

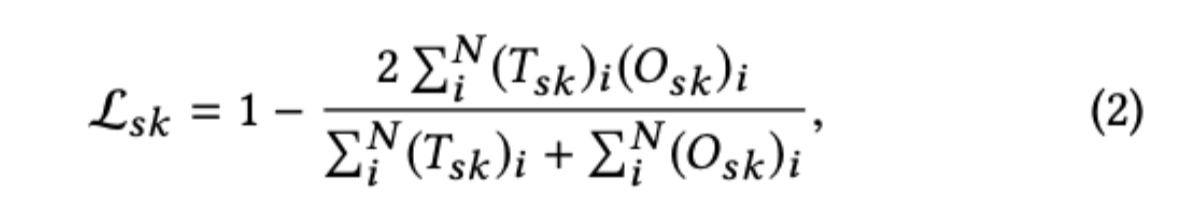
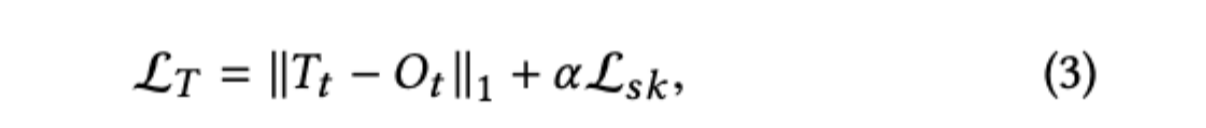
ここで,$T_t$はテキスト変換モジュールの基底真理値,$\alpha$は正則化パラメータであり,本論文では1.0に設定されている.
Background Inpainting Module
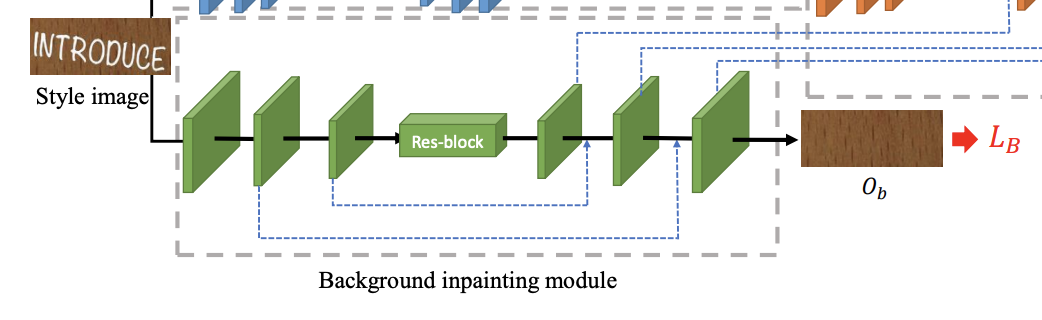
元画像$I_s$のみを入力とし、テキスト部分を消去し、適切なテクスチャで埋めた背景画像$O_b$を出力します。
ここで、$T_b$はバックグラウンドの基底真理値である。式は、逆境損失とL1損失を組み合わせたものであり、追試では$\beta$を10としている。
詳しい内容(deepl翻訳)
本モジュールでは、ワードレベルの消去タスクを用いて背景を取得することを主な目的としています。図2の緑の部分に示すように、本モジュールは元画像$I_s$のみを入力とし、テキストストロークの全画素を消去し、適切なテクスチャで埋めた背景画像$O_b$を出力します。入力画像は、ストライド2で3つのダウンサンプリング畳み込み層で符号化され、4つの残差ブロックで追従した後、デコーダは3つのアップサンプリング畳み込み層を介して、元のサイズの出力画像を生成する。各層の後にリークReLU活性化関数を使用し、出力層にはtanh関数を使用する。背景生成器を$G_B$と呼ぶ。視覚効果をよりリアルにするためには、背景の質感を可能な限り復元する必要がある。U-Net[23]は、ミラーリングされたレイヤ間にスキップ接続を追加することを提案しており、物体のセグメンテーションや画像から画像への変換タスクを解くのに非常に効果的でロバストであることが証明されている。ここでは、このメカニズムをアップサンプリング処理で採用しており、同じサイズの以前のエンコーディングフィーチャーマップを連結して、よりリッチなテクスチャを確保している。これにより、ダウンサンプリング時に失われた背景情報を復元することができます。
本研究では、他のフルテキスト画像消去法[21,35]とは異なり、単語レベルの画像を対象としています。単語レベルの画像に表示される文字は比較的標準的なスケールであるため、ネットワーク構造はシンプルで整然とした設計となっています。Zhangら[35]の研究にヒントを得て、より現実的な外観を学習するために敵対学習を追加しています。背景画像判別器$D_B$の詳細なアーキテクチャについては、3.4節で述べる。背景塗装モジュールの全損失関数は、以下のように定式化されています。
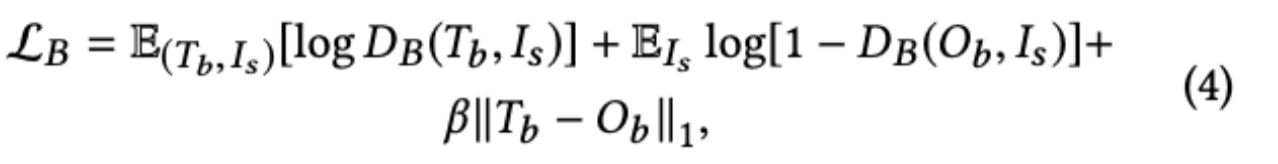
Fusion Module
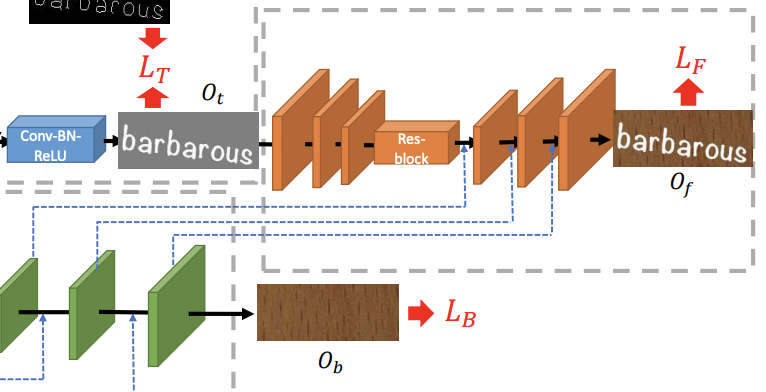
Text Conversion Moduleの生成画像$O_t$とBackground Inpainting Moduleのアップサンプリング層の重みを用いて、文字情報と背景情報を合成します。
また、$L_F$にVGG-19学習済モデルの層の重みを使用したVGG Lossを組み込むことで微妙に崩れている文字を補正したりすることもしているみたいです
ここで、$T_f$は編集されたシーン画像の基底真理値である。ここでは、敵対的損失とL1損失のバランスをとるために$\theta_1=10$としている。 VGG-Loss
詳しい内容(deepl翻訳)
融合モジュールは、対象となるテキスト画像と背景テクスチャ情報を調和的に融合させ、編集されたシーンテキスト画像を合成するように設計されている。図2のオレンジ色の部分が示すように、融合モデルもエンコーダ-デコーダFCNのフレームワークを踏襲している。まず、テキスト変換モジュールで生成された前景画像を、3つのダウンサンプリング畳み込み層と残差ブロックからなるエンコーダに供給する。次に、3つのアップサンプリング畳み込み層とConvolution-BatchNorm-LeakyReLUブロックからなるデコーダで最終的な編集画像を生成します。ここで注目すべきは、背景塗りモジュールのデコード特徴量マップを、融合デコーダのアップサンプリング段階で、同じ解像度の対応する特徴量マップに接続していることである。このようにして、背景のディテールが大幅に復元された画像が出力され、テキストオブジェクトと背景が良好に融合され、合成のリアリズムを実現した画像が出力されます。ここでは、融合生成器とその出力をそれぞれ$G_F, O_f$と呼ぶ。また、ここでは adversarial lossを加えており、対応する識別器DFの詳細な構造については3.4節で紹介する。まとめると、融合モジュールの最適化目標は以下のように定式化できる。
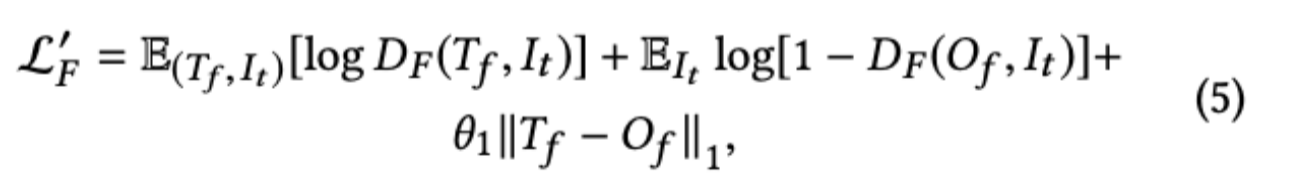
歪みを低減し、よりリアルな画像を生成するために、知覚損失[13]とスタイル損失[6]を含む融合モジュールにVGG-Lossを導入した。知覚的損失$L_{per}$は、その名の通り、事前に学習したネットワークの活性化マップ間の距離を定義することで、ラベルと知覚的に類似しない結果に対してペナルティを与えるものである(ImageNet[25]で事前に学習したVGG-19 model[28]を採用している)。一方,スタイル損失$L_{style}$はスタイルの違いを計算する.VGG-loss $L_{vgg}$は以下によって表される
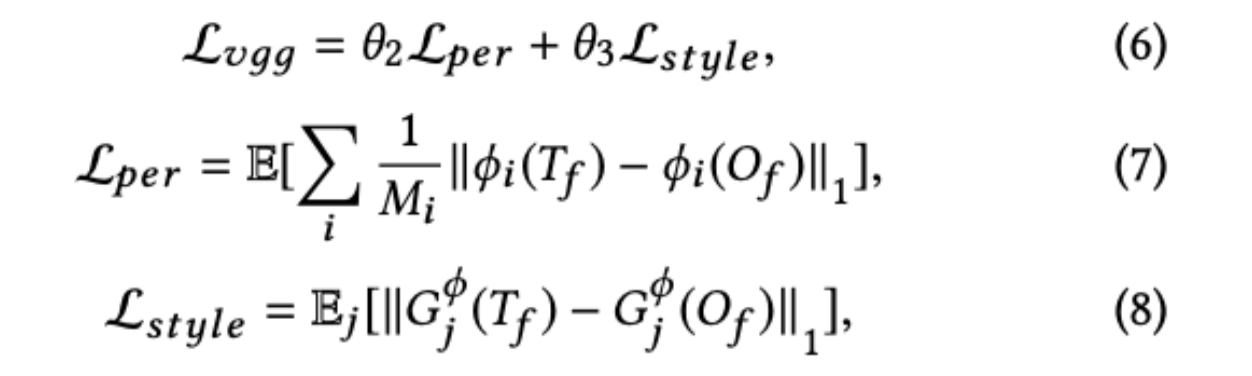
ここで$\phi_i$はVGG-19モデルのrelu1_1,relu2_1,relu3_1,relu4_1,relu5_1層からの活性化マップであり、$M_i$は$i$番目の層で得られた特徴マップの要素サイズであり、$G$はグラム行列$G(F)=FFT∈Rn×n$であり、重み$θ_2$と$θ_3$はそれぞれ1と500に設定されています。融合モデルの全体的な学習目的は以下の通りである。

学習方法
GANの学習のような形式で学習します。損失関数は
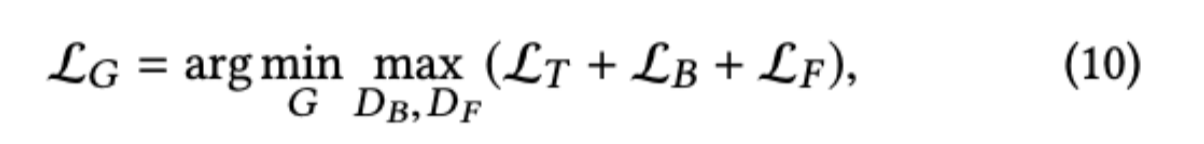
のようになります。ここで出てくる$L_T,L_B,L_f$はぞれぞれのモジュールの損失、$D_B,D_F$はそれぞれBackground Inpainting Module, Fusion Moduleの出力画像を本物かどうか2クラス分類をするDiscriminatorです。
データセット
データセットは学習用と、評価用の2つを用います。
学習用
学習用のデータセットはスクリプトによって生成します。

このように、
- 背景画像を含むソース画像
- 変換後の文字の画像
- 返還後の文字のスケルトン
- 返還後の文字でスタイルはソース画像(背景なし)
- ソース画像の背景
- 期待する出力
- バイナリマスク
で構成されています。
学習データの生成スクリプトはモデルとは別のリポジトリにあります
GitHubのリポジトリ
評価用
評価用のデータセットは現実世界の画像を使います。
使用するのはICDAR2013(2013 International Conference on Document Analysis and Recognition for Competition)のテキストシーン画像データセットです。

結果
執筆時に単語レベルのテキスト編集タスクがまだなかったため、Pix2pixを用いての比較です。一目瞭然ですが、SRNetの方はかなり自然に編集できていると言えます。

また、STEFANNでできなかった多言語での変換ですが、すこし違和感があるもののARを用いた翻訳などにも応用できそうですね

まとめ
- オリジナルのスタイルを維持したまま、シーンテキスト画像からテキストを置き換えることができる、テキスト編集作業のためのEnd-to-Endネットワークを3ステップで実現した
- 任意の文字数で、文字を変換することができる
- 多言語に対応にした文字変換ができる