あいさつ
みなさんこんにちは、エンジニアの弘輝です!
最近、業務でAWS Glueというサービスを利用しているんですが、
「クローラーやデータカタログって、結局何のためにあるんだろう?」
と役割が分からなくなったので、整理するために記事にしてみようと思います。
こんな方に役に立つかも🙋
・Glueを業務で使い始めた方
・AWSの資格勉強している方の参考になれば幸いです!
構成図
今回はS3バケットに入ってるcsvデータをDynamicFrame化し、データ活用していく例を見ていこうと思います。
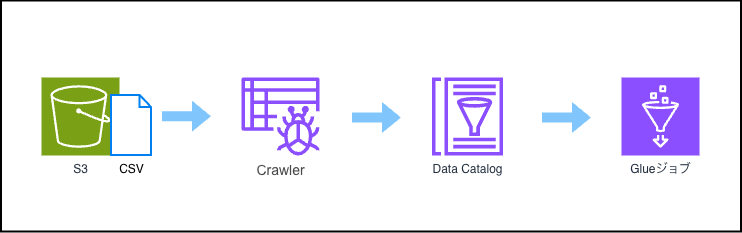
それぞれの役割
| サービス | 役割と機能 |
|---|---|
| S3 | 処理対象のCSVなどのファイルデータ(生データ)が格納されている場所です。 |
| クローラー | データ構造を自動検出する役割を担います。S3内のファイルをスキャンし、データの構造(スキーマ)や形式を自動で分析し、データカタログにテーブルとして登録します。登録されるカタログテーブルはクローラーが自動で作成してくれます。 |
| データカタログ | メタデータの一元管理するサービスです。クローラーがスキャンしたデータの構造、形式、場所などのメタデータ(データに関する情報)を一元的に管理します。データそのものは保持していません。 あくまでも「どのような構造をしているか」の情報のみを管理しています。 |
| Glueジョブ | データ処理の実行環境です。Pythonなどのコード(AWS Lambdaのように)を記述し、ETL処理を実行します。今回の場合コード内でデータカタログの情報を利用し、S3内のデータをDynamicFrameなどのデータ型に変換して処理を行います。 |
大まかな流れ
例えばS3://test/data/20251121/という階層に CSV データが入っているとします。
この場合、まずクローラーの Data Sourcesという設定にS3://test/dataを指定してからクローラーを実行します。するとデータカタログが作成されます。
クローラーを実行することで、S3上のフォルダ構造を読み取り、自動的にパーティションとしてデータカタログに登録してくれます。
今回の場合20251121というフォルダ名をデータの区切り(パーティション)として認識しデータカタログに登録されます。
# データカタログの情報を利用してS3データを読み込み、DynamicFrameに変換
dynamic_frame = glue_context.create_dynamic_frame.from_catalog(
database="データベース名",
table_name="データカタログテーブル名",
push_down_predicate = "データカタログに登録されたパーティションに対する条件式"
)
その後、上記のようにDynamicFrame化していきます。
# push_down_predicateの指定方法
push_down_predicate = "partition_0 = '20251121'"
データカタログがフォルダをパーティション(例:partition_0)として認識しているため、上記の様に指定することで、S3全体を読み込まずに必要なフォルダ(20251121/)配下のデータだけを効率的に取得することができます。
補足:
今回のような20251121という単なる数字のフォルダの場合AWS Glueのクローラーはデフォルトで partition_0, partition_1... というような名前を付けます。
S3のフォルダ作成時に キー = 値 の形式にしておくと、クローラーが自動的に「列名」と「値」を認識してくれます。この形式を Hive形式 と呼びます。
-
通常のフォルダ
- パス:
s3://.../2025/11/ - カタログ上の列名:
partition_0,partition_1
- パス:
-
Hive形式
- パス:
s3://.../year=2025/month=11/day=21/ - カタログ上の列名:
year,month,day(フォルダのキー名がそのまま列名になる)
- パス:
なぜクローラーとデータカタログが必要なのか?
ここから今回の本題です。
実際、Lambdaから直接S3のパスを指定してpandas DataFrame への変換処理を行うことは可能です。
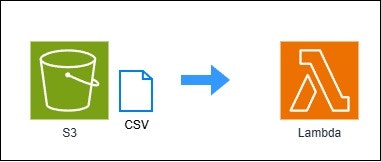
Lambdaを使用しS3データを直接pandas DataFrameに変換
比較用の参考コード
import pandas as pd
import boto3
from io import StringIO
def lambda_handler(event, context):
s3 = boto3.client("s3")
bucket = "my-bucket"
key = "path/to/data/sample.csv"
try:
# S3からデータ取得
obj = s3.get_object(Bucket=bucket, Key=key)
# データを読み込んでデコード
body = obj["Body"].read().decode("utf-8")
# Pandas DataFrameに読み込む
df = pd.read_csv(StringIO(body))
print(df.head())
return {"statusCode": 200, "body": "Success"}
except Exception as e:
print(f"Error: {e}")
return {"statusCode": 500, "body": "Error"}
# ※実行するにはLambdaレイヤーでpandasを追加する必要があります
ですが調べたところによると、クローラーとデータカタログを使用することで、
いいことがたくさんありました! 👏
クローラーとデータカタログを使うメリット
1.🚀 スキーマ管理を自動化
クローラーは S3などのAWS上のデータをスキャンし、列名・型・パーティション構造などを自動で推論 してくれます。そのため、新しいファイルが追加されても クローラーを実行することで手軽に変更を反映することができます。
2.⚡ クエリの最適化と高パフォーマンス化
データカタログを参照することで、必要なデータだけを S3 から読み込む ように最適化できます。そのためスキャン量を削減でき、処理時間の短縮につながります。
3.🔁 クロスサービスで再利用できる
一度クローラーでテーブルを登録すれば、 複数の AWS サービスから同じテーブル定義を再利用できます。
- Athena → SQL クエリ実行
- EMR / Glue ETL → そのままメタデータを利用
-
QuickSight → データソースとして読み込み
など
AWSを使う上で他AWSサービスからも再利用できるというのはかなり利点ですね。😎
⚠️ 注意点(実際にハマったポイント)
実際に自分が経験したミスなんですが、
S3 に新しいフォルダが追加されても、クローラーを実行しない限りデータカタログには反映されません。
例)S3://test/data/20251121/ →日付部分が違う日付(20251122など)でフォルダが作られた場合など
そのため、クローラーを最新化しないまま Glue ジョブを実行すると、
- データカタログのパス情報が古いまま
- 新しいパーティションやファイルを認識できない
- 結果として 「該当データが見つからない」エラー が発生⚠️
という状況に陥ります。
これに気づかずにGlueジョブでエラーを何度も出してしまいました…。😑
現在の業務ではこの問題を回避するため、以下のような構成を採用しています。
- 時間ベースのトリガーでクローラーを定期実行
- クローラーが 正常終了したこと をトリガーとしてGlue ジョブ側を起動
こうすることで、もしS3 に新規ファイルが追加されていてもクローラーがデータカタログを最新化し最新状態のままジョブが動くというパイプラインを構築できます。
まとめ
今回はGlue周辺サービスの基本的な話をさせていただきました。
Lambda を使ってコードでゴリ押すこともできますが、AWS のサービス同士を組み合わせてアーキテクチャを構築することで、より多くのメリットが得られることが理解できました。これが”AWSネイティブ”ですね。
最近触り始めたので、間違っていた箇所などあればコメントいただけると幸いです。🙇
ここまで読んでくれてありがとうございました。
何かの参考になれば嬉しいです。