0. 概要
強化学習といえば2015年くらいから飛躍的な進化を遂げてきた機械学習アルゴリズムです。教師ありだけれども、それを報酬といった形で与えるため、教師あり/なし学習とも少し異なる技術です。技術的にもかなり成熟してきていて様々な支援ライブラリがあります。そこで、今回は強化学習の理論はさておき、まずは体験ということで、自分でゲームを作ってみて、それをDQNで最適化するとどのような感じになるのかを確かめていきたいと思います。
以下のようなものを開発します。
黄色がゴール。緑色がプレイヤーです。
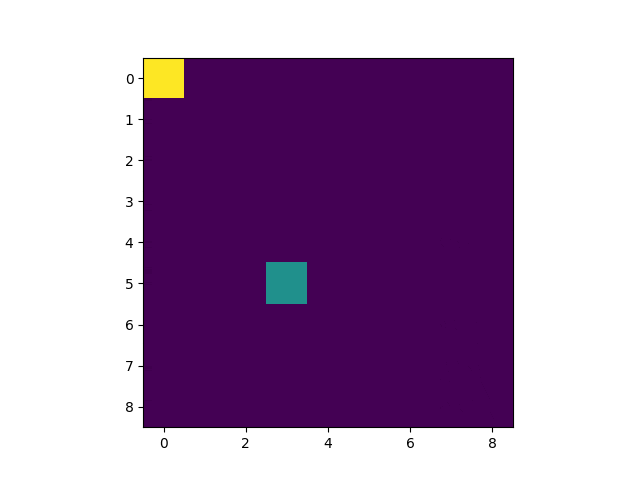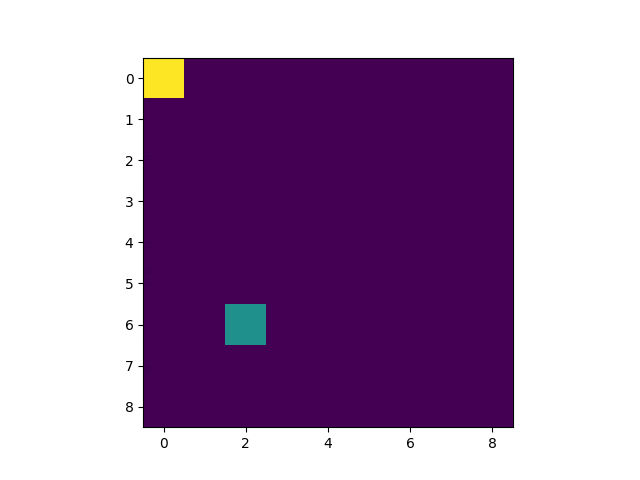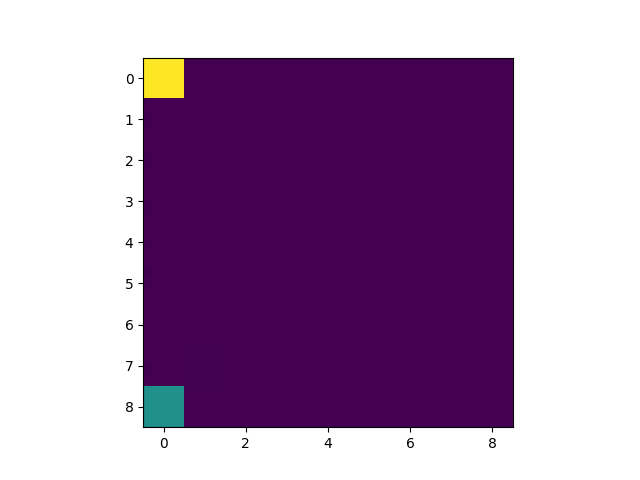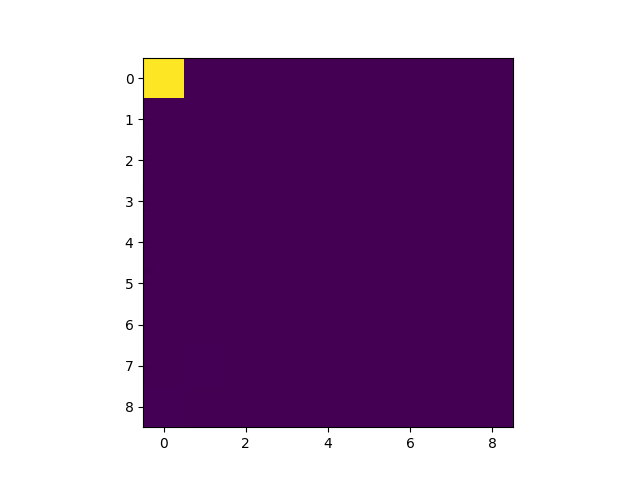
1 Epoch目
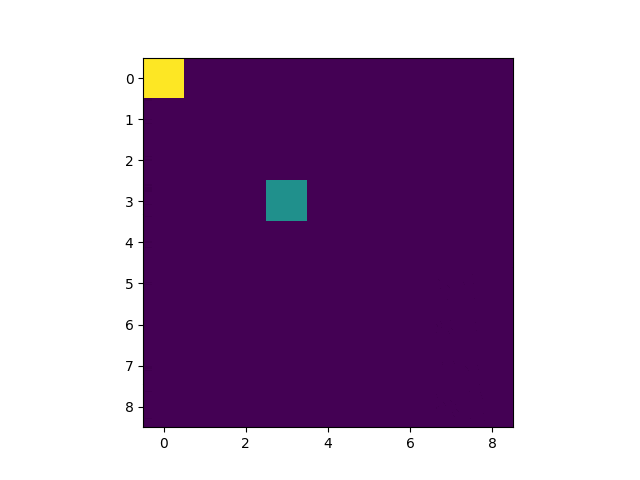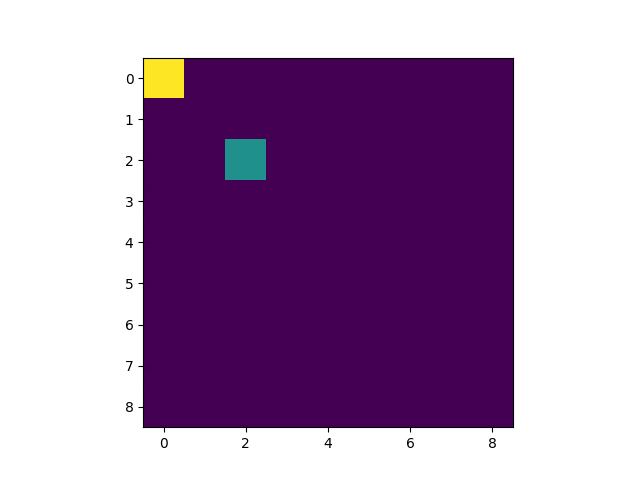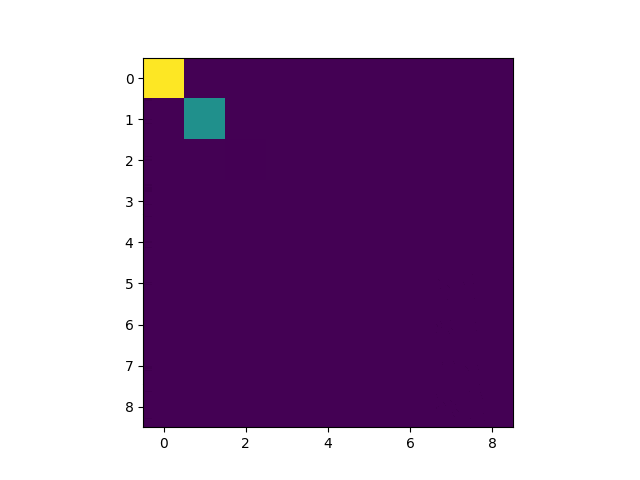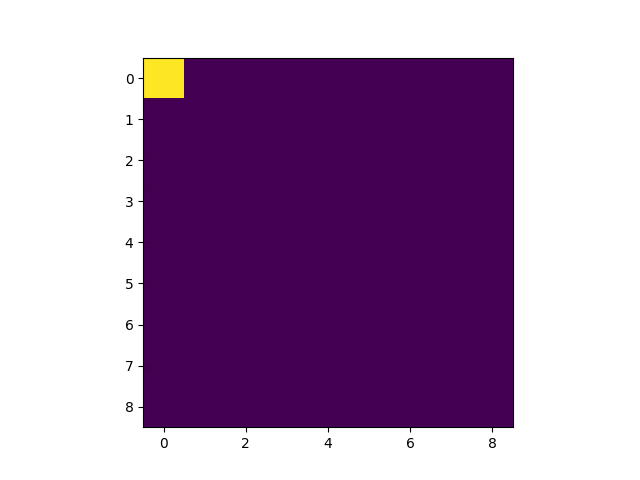
5 Epoch目
1. 環境構築
まず、強化学習を実装する上で重要な要素が2つあります。それは「学習」及び「ゲーム」です。
「学習」、すなわち強化学習は一般的なニューラルネットワーク(NN)から構成されます。
強化学習のNNにおいて入力値は観測値(もしくは状態)と呼ばれ、ゲーム画面やプライヤーの位置などチーティングなしで取得できるようなデータを入れます。次に、出力はアクションと呼ばれ、ゲームに対してどのような行動を取るかを出力します。
「ゲーム」は、上述したアクション及び観測値の2つを入出力できるような形式(スケルトン)にしておく必要があります。
このスケルトン、換言してゲームそのものは「gym」というライブラリを使うことによって、簡単に実装することができます。
今回は「ゲーム」に「Gym」ライブラリを使い、強化学習に「kera-rl2」ライブラリを使います。
以下のコマンドでサクッとAnaconda上で環境を構築します。
$ conda create -n rl
$ conda activate rl
$ pip install tensorflow-gpu==2.1.0
$ pip install keras==2.3.0
$ python -c 'import tensorflow as tf; print(tf.__version__)'
$ pip install keras-rl2
$ pip install gym
2. 自作ゲーム
では、強化学習に最適化させたい簡単な探索ゲームを作りたいと思います。
9×9のマップでプレイヤーが4方向自由に移動出来て、左上にゴールがあるような非常に簡易的なものです。
2.1. 実装
まずはGymライブラリを使って以下のように実装します。
import numpy as np
import gym
from gym import spaces
class myGame(gym.Env):
metadata = {'render.modes': ['human']}
# Actions
A_L = 0
A_R = 1
A_U = 2
A_D = 3
def __init__(self, grid_size=5):
super(myGame, self).__init__()
# fields
self.grid_size = grid_size
self.fieldmap = np.zeros((grid_size, grid_size))
self.agent_pos = np.array([int(grid_size*0.5), int(grid_size*0.5)])
self.goal_pos = np.array([0, 0])
self.action = 0
self.reward = 0
# action num
n_actions = 4
self.action_space = spaces.Discrete(n_actions)
# low=input_lower_limit, high=input_higher_limit
self.observation_space = spaces.Box(low=0, high=self.grid_size, shape=(2,), dtype=np.float32)
def reset(self):
# initial position
self.agent_pos = np.array([int(self.grid_size*0.5), int(self.grid_size*0.5)])
# numpy only
return np.array(self.agent_pos).astype(np.float32)
def step(self, action):
# fetch action
if self.A_L == action:
self.agent_pos[0] -= 1
if self.A_R == action:
self.agent_pos[0] += 1
if self.A_U == action:
self.agent_pos[1] -= 1
if self.A_D == action:
self.agent_pos[1] += 1
# moving limit
self.agent_pos[0] = np.clip(self.agent_pos[0], 0, self.grid_size-1)
self.agent_pos[1] = np.clip(self.agent_pos[1], 0, self.grid_size-1)
# goal and reward
done = False
#reward = 0
reward = (self.grid_size * 0.5) - np.abs(self.goal_pos[0] - self.agent_pos[0])
reward += (self.grid_size * 0.5) - np.abs(self.goal_pos[1] - self.agent_pos[1])
reward *= 0.05
if self.agent_pos[0] == self.goal_pos[0] and self.agent_pos[1] == self.goal_pos[1]:
done = True
reward += 1000
# fetch variables
self.action = action
self.reward = reward
# infomation
info = {}
return np.array(self.agent_pos).astype(np.float32), reward, done, info
# draw
def render(self, mode='human', close=False):
if mode != 'human':
raise NotImplementedError()
draw_map = ""
for i in range(self.grid_size):
for j in range(self.grid_size):
if self.goal_pos[0] == j and self.goal_pos[1] == i:
draw_map += "G "
else:
if self.agent_pos[0] == j and self.agent_pos[1] == i:
draw_map += "O "
else:
draw_map += "X "
draw_map += '\n'
print("Action:", self.action, "Agent:", self.agent_pos, "Reward:", self.reward)
print(draw_map)
補足
少しだけ解説します。ゲームにおける「観測値の空間」は以下で表現されます。
self.observation_space = spaces.Box(low=0, high=self.grid_size, shape=(2,), dtype=np.float32)
これは、プレイヤーの位置x, yの2変数を0~9(グリッド最大数)で表現しているという意味です。
次に、「アクションの空間」は以下で表現されます。
self.action_space = spaces.Discrete(n_actions)
これは、離散値でいくつの行動をとることが出来るかを示しています。今回は左右上下の4つの行動をとれるようにしています。
2.2. 実行
実行コードを書きます。以下のコードを同じソースコードか、外部から呼び出して実行すればゲームが動作します。
env = myGame(grid_size=9)
obs = env.reset()
env.render()
n_steps = 10
for step in range(n_steps):
print("Step {}".format(step + 1))
myaction = 1 # L, R, U, D
obs, reward, done, info = env.step(myaction)
print('obs=', obs, 'reward=', reward, 'done=', done)
env.render()
if done:
print("Goal !!", "reward=", reward)
break
今回は、取り合えず右に進み続けるようにしてあります。
実行結果
以下のような結果を得られます。
Agentがプレイヤーの位置、Rewardが報酬です。
今回の例ではゴールから離れていくことになるので報酬が減っています。
Action: 0 Agent: [4 4] Reward: 0
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X O X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 1
obs= [5. 4.] reward= 0.0 done= False
Action: 1 Agent: [5 4] Reward: 0.0
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X O X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 2
obs= [6. 4.] reward= -0.05 done= False
Action: 1 Agent: [6 4] Reward: -0.05
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X O X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 3
obs= [7. 4.] reward= -0.1 done= False
Action: 1 Agent: [7 4] Reward: -0.1
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X O X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 4
obs= [8. 4.] reward= -0.15000000000000002 done= False
Action: 1 Agent: [8 4] Reward: -0.15000000000000002
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X O
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
3. DQN
先ほど作ったゲームのプレイヤー(Agent)を自動で動作させて最適な動作(アクション)を探索させます。
本来なら数百行必要なのですがkeras-rl2のライブラリを使うことで10行にも満たないコード量で強化学習を実現できます。
import gym
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import Adam
from rl.agents.dqn import DQNAgent
from rl.policy import *
from rl.memory import SequentialMemory
from simulator import myGame
import numpy as np
# gym
env = myGame(grid_size=9)
print("-Initial parameter-")
print(env.action_space) # input
print(env.observation_space) # output
print(env.reward_range) # rewards
print(env.action_space) # action
print(env.action_space.sample()) # action
print("-------------------")
# model
window_length = 1
input_shape = (window_length,) + env.observation_space.shape
nb_actions = env.action_space.n
c = input_data = Input(input_shape)
c = Flatten()(c)
c = Dense(128, activation='relu')(c)
c = Dense(128, activation='relu')(c)
c = Dense(128, activation='relu')(c)
c = Dense(128, activation='relu')(c)
c = Dense(128, activation='relu')(c)
c = Dense(nb_actions, activation='linear')(c)
model = Model(input_data, c)
print(model.summary())
# rl
memory = SequentialMemory(limit=50000, window_length=window_length)
policy = EpsGreedyQPolicy() #GreedyQPolicy()# SoftmaxPolicy()
agent = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=100, target_model_update=1e-2, policy=policy)
agent.compile(Adam())
agent.fit(env, nb_steps=3000, visualize=False, verbose=1)
agent.save_weights("weights.hdf5")
# predict
obs = env.reset()
n_steps = 20
for step in range(n_steps):
obs = obs.reshape((1, 1, 2))
action = model.predict(obs)
action = np.argmax(action)
print("Step {}".format(step + 1))
print("Action: ", action)
obs, reward, done, info = env.step(action)
print('obs=', obs, 'reward=', reward, 'done=', done)
env.render(mode='human')
if done:
print("Goal !!", "reward=", reward)
break
実行結果
学習後のpredict以下を表示しています。
Step 1
Action: 0
obs= [3. 4.] reward= 0.1 done= False
Action: 0 Agent: [3 4] Reward: 0.1
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X O X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 2
Action: 0
obs= [2. 4.] reward= 0.15000000000000002 done= False
Action: 0 Agent: [2 4] Reward: 0.15000000000000002
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X O X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 3
Action: 0
obs= [1. 4.] reward= 0.2 done= False
Action: 0 Agent: [1 4] Reward: 0.2
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X O X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 4
Action: 2
obs= [1. 3.] reward= 0.25 done= False
Action: 2 Agent: [1 3] Reward: 0.25
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X O X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 5
Action: 2
obs= [1. 2.] reward= 0.30000000000000004 done= False
Action: 2 Agent: [1 2] Reward: 0.30000000000000004
G X X X X X X X X
X X X X X X X X X
X O X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 6
Action: 2
obs= [1. 1.] reward= 0.35000000000000003 done= False
Action: 2 Agent: [1 1] Reward: 0.35000000000000003
G X X X X X X X X
X O X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 7
Action: 0
obs= [0. 1.] reward= 0.4 done= False
Action: 0 Agent: [0 1] Reward: 0.4
G X X X X X X X X
O X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Step 8
Action: 2
obs= [0. 0.] reward= 1000.45 done= True
Action: 2 Agent: [0 0] Reward: 1000.45
G X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
X X X X X X X X X
Goal !! reward= 1000.45
見事に最速でGoalまで行くことが出来ています。
このようなKeras-rl2を使うと5分位で強化学習を実装できてしまうので、興味がある人はぜひ実装して見てください。