動画解析を行うための手法をいろいろ調べている中で、Microsoftから提供されている「VideoIndexer」というサービスを触ってみたのですが、想像以上に色々な項目を、精度高く解析することができたので、できることをまとめる記事を書いてみました。
VideoIndexerとは
Microsoftから提供されているCognitiveServicesという、AIと呼ばれる機能をAPIとして提供しているサービスの中の一つで、動画をアップロードするだけでその動画に含まれる様々な要素を解析します。
GUIのツールとして提供されていますが、アップロード・解析ともにAPIも用意されているので、独自にシステム開発を行いそれに組み込むことができます。
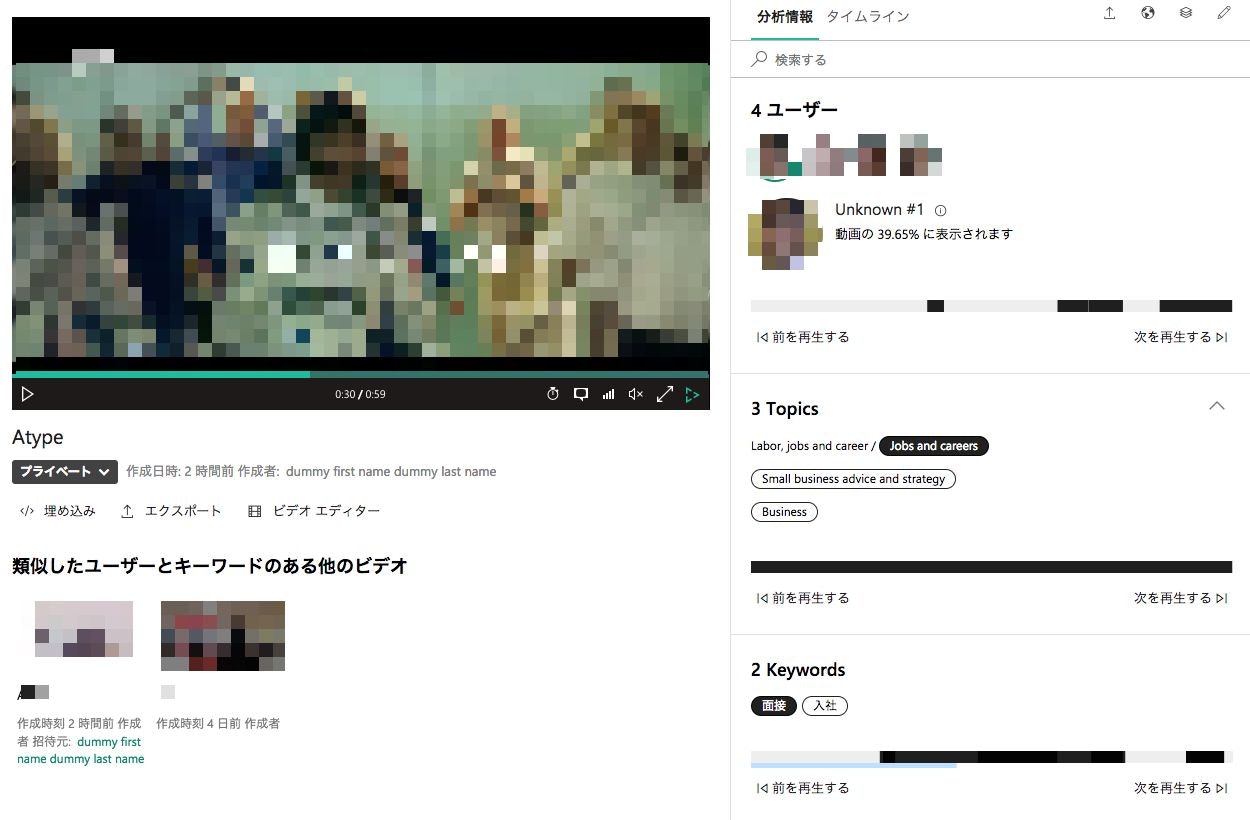
上記の画像は、GUIツールに動画をアップロードした後の画面です。念のために著作権対策でモザイクをかけている部分もありますがご了承ください・・・
それでは、解析できる要素について一つ一つ挙げていきます。
動画の登場人物

動画内に映っている人の顔を認識・解析し、どの人が動画のどの部分(何秒のところか)に映っているかを割り出します。また、映っている人が著名人であればその人の名前も表示されます。上記画像では著名人ではない人であるためUnknownと表示されています。著名人かどうかの判断は、Bingサーチエンジンで画像検索して結果が出るか出ないかが基準になっているようです。
OCR
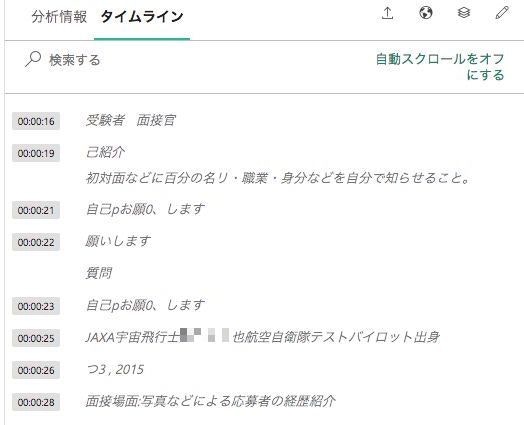
動画の中に映っているテロップなどを読み取り、テキストデータとして取得することができます。またそのテロップが動画のいつのタイミングで流れたかも検知しています。
日本語がおかしい部分がないわけではないですが、総じてちゃんと文字起こしできている印象です。
会話内容
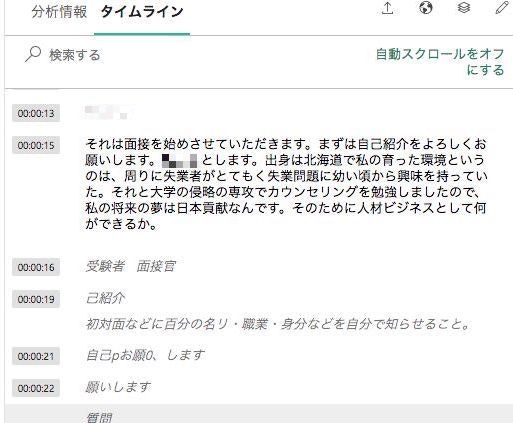
テロップ以外にも、動画の中で話された内容をSpeechToTextし、話されたタイミングと一緒にテキストデータを取得できます。
上記画像の中で、グレーではなく黒文字の部分が実際に話された内容です。(グレー部分はOCR)
こちらも音量や滑舌にもよりますが、割と高い精度で文字起こしできている印象です。
キーワード抽出
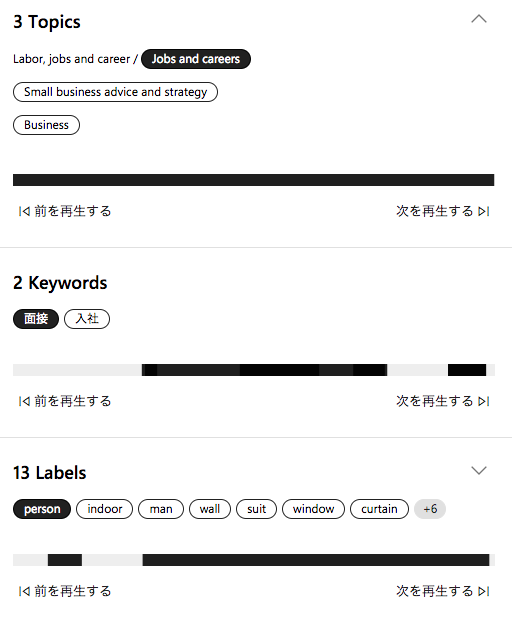
動画内で話された内容やOCRしたテキストから、動画の要点、キーワードになるような単語を類推します。
ここでいうTopicsは、動画が何についてのものなのか、
Keywordsはそのまま動画内でよく出るキーワード、
LabbelsはKeywordsよりも重要度は下がりますが、動画内に映っていた要素がいくつか取得できます。
その他
動画内のチャプター自動認識や、数秒毎のスクリーンショットなども取得できそうです。
同CognitiveServicesの中にあるComputerVision、SpeechToText、TextAnalytics、Faceなどのサービスが総合的に組み合わさって提供されているイメージを感じました。
取得できるJSON(一部)
{
・・・
"faces": [{
"id": 1241,
"videoId": "xxxxxxxxxx",
"referenceId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"referenceType": "Bing",
"knownPersonId": "00000000-0000-0000-0000-000000000000",
"confidence": 0.9084,
"name": "xxxxxxxxxxxxxx",
"description": null,
"title": null,
"thumbnailId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"appearances": [{
"startTime": "0:00:34.167",
"endTime": "0:00:55.355",
"startSeconds": 34.2,
"endSeconds": 55.4
}],
"seenDuration": 21.2,
"seenDurationRatio": 0.321
}, {
・・・
}],
"keywords": [{
"id": 0,
"name": "楽天賞mvp",
"appearances": [{
"startTime": "0:00:05.138",
"endTime": "0:00:07.941",
"startSeconds": 5.1,
"endSeconds": 7.9
}],
"isTranscript": false
}, {
・・・
}],
"sentiments": [{
"sentimentKey": "Neutral",
"appearances": [{
"startTime": "0:00:02.59",
"endTime": "0:00:22.59",
"startSeconds": 2.6,
"endSeconds": 22.6
}, {
"startTime": "0:00:22.6",
"endTime": "0:00:42.8",
"startSeconds": 22.6,
"endSeconds": 42.8
}, {
"startTime": "0:00:42.81",
"endTime": "0:01:05.986",
"startSeconds": 42.8,
"endSeconds": 66
}],
"seenDurationRatio": 0.9595
}],
"audioEffects": [{
"audioEffectKey": "Silence",
"appearances": [{
"startTime": "0:00:02.133",
"endTime": "0:00:02.133",
"startSeconds": 2.1,
"endSeconds": 2.1
}],
"seenDurationRatio": 0.0323,
"seenDuration": 2.133
}],
"topics": [{
"id": 0,
"name": "Ethics",
"referenceUrl": "https://en.wikipedia.org/wiki/Category:Ethics",
"iptcName": null,
"confidence": 0.682,
"appearances": [{
"startTime": "0:00:04.204",
"endTime": "0:00:10.744",
"startSeconds": 4.2,
"endSeconds": 10.7
}]
}, {
・・・
}],
・・・
"insights": {
"version": "1.0.0.0",
"duration": "0:01:06.048",
"sourceLanguage": "ja-JP",
"language": "ja-JP",
"transcript": [{
"id": 0,
"text": "楽天には日本一になって世界で買うという可能性がとても秘めていると思うので、自分が日本一にして世界で戦うようにするっていうところをやっていきたいなと思う。",
"confidence": 1,
"speakerId": 1,
"language": "ja-JP",
"instances": [{
"adjustedStart": "0:00:02.59",
"adjustedEnd": "0:00:32.59",
"start": "0:00:02.59",
"end": "0:00:32.59"
}]
}, {
・・・
},
"ocr": [{
"id": 0,
"text": "Hossy",
"confidence": 454.1013,
"left": 233,
"top": 144,
"width": 126,
"height": 39,
"language": "ja-JP",
"instances": [{
"adjustedStart": "0:00:04.204",
"adjustedEnd": "0:00:10.744",
"start": "0:00:04.204",
"end": "0:00:10.744"
}]
}, {
・・・
},
},
・・・
}
たくさんの項目が取れすぎて全部を載せられなかったので、一部だけ抜粋しました。
「faces」の項目では、映っている人の名前や類似度(confidence)、映っている箇所(appearances)などが取得できていますね。「referenceType」の部分がBingとなっているので、データソースはBingなのでしょう。
「sentiments」では、言ってることのポジネガを判別しています。ここではNeutralと出ているのでポジティブな内容でもネガティブな内容でもない、ということですね。
「audioEffects」はまだちょっとよくわかってないのですが、動画の音声パターンについて指していると思われます。確かにBGMなども流れず少し静かめな動画ではあります・・・
他には拍手している場合、会話している場合、なども取得できるようです。
「topics」では抽出した内容と、それについてのWikipediaのURLが付随されているのが驚きでした。取得できたURLに対してスクレイピング・・・などで応用の幅が広がりそうです。
感想
動画をアップロードするだけでかなりいろんな情報を取得できるのは驚きで、特に文字起こしの精度が高かったのが個人的に刺さったポイントでした。
今回試した動画はナレーション系のものをアップして試したのですが、会話している場合や、喋る人の滑舌などの条件で色々変わる気がするのでもう少しいろんな動画で試してみたいと思っています。
また、登場している人物やキーワードなどにもWikipediaのURLが付随されて取得できるので、そこからスクレイピングなどすれば取得できる項目も広がりそうです。
もうちょっと色々触ってみたいなあと思います。