これはなんの記事?
COTOHA APIでマジカルバナナAIを作って、実際に使ってみたよ記事。
実際にCOTOHA APIを利用したAIの構築から遊んでみた結果までを記事にしています。
ソースコードは近いうちに載せますので、定期的にこの記事をチェックしておくと良いかも…?
そして国産Web API Advent Calendar 2018 21日目の投稿です。
あといくつ寝れば…ですね!
COTOHA APIとは?
COTOHA APIを知らない方向けにざっくり説明しますと、自然言語をいい感じに解析してくれるAPIサービスです。
詳しくはこちらを参照いただければと思います。
マジカルバナナとは?
COTOHA APIを使ってなにかしら遊んでみようということで、選ばれたのはマジカルバナナでした。
マジカルバナナってどれくらい有名なんでしょうね?
簡単に説明すると、単語の連想ゲームです。(例:バナナ→すべる→氷→冷蔵庫→…)
もっと知りたい方はこちらのページをご覧ください。
今回、実際にCOTOHA APIを利用したAIの構築から遊んでみた結果までを記事にしています。
ソースコードは近いうちに載せますので、定期的にこの記事をチェックしておくと良いかも…?
やりたいこと
コンピュータにマジカルバナナをさせたい。
具体化すると、コンピュータにお題を与えたときに、連想語を返却させたい。
既存のマジカルバナナシステムはword2vecを用いてベクトル的に近い単語を出すのが主流らしいのですが、これでは膨大なコーパスが必要になってしまいます。
今回はもっと手軽に連想語を習得したいということで、自然言語処理的ロジックを用いて連想語を学習させていきます。
というのは表向きでCOTOHA APIを使いたかったからですね、はい。
マジカルバナナAIの大まかな流れは以下です。
[モデル構築編]
1. コーパスから連想語のペアを取得する
2. 連想語ペアをネットワークにする
[モデル利用編]
1. ユーザの入力ワードからネットワークをたどり連想語候補を取得する
2. 入力ワードと連想語候補の類似度を算出し、最終的な連想語を決定する
各工程について、以下で詳しく説明していきます。
モデル構築編
1. コーパスから連想語のペアを取得する
構文情報から特定のルールに則った単語ペアを連想語として学習させます。
抽出ルールについて
COTOHA APIの構文解析APIで取得できる単語の品詞情報と、単語間の意味関係ラベルおよび依存関係ラベルを用いて、文章中の2単語を連想語ペアとして取得します。
具体的には以下のようなルールを実装しました。
A. 同じ種類の単語、対応する語
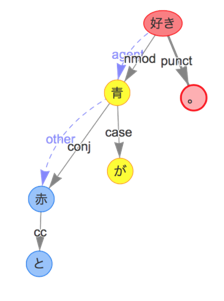
- 例文:「赤と青が好き。」
- 抽出したいペア:「赤」&「青」
- 抽出ルール※:
[N1,conj,N2] & [N1,other,N2] ====> (N1,N2)- 名詞N1(
赤)と名詞N2(青)間の構文的に並列になっており、N1(赤)とN2(青)間に有意な関係性が存在しない場合、N1(赤)とN2(青)は連想語とする。
- 名詞N1(
※N:名詞、V:動詞、A:形容詞、X:品詞問わず
B. 名詞ー動詞
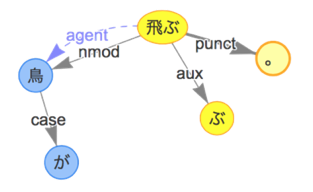
- 例文:「鳥が飛ぶ。」
- 抽出したいペア:「鳥」&「飛ぶ」
- 抽出ルール:
[V,agent,N] ====> (N,V)- 名詞N(
鳥)が主として動詞V(飛ぶ)を行う場合、N(鳥)とV(飛ぶ)は連想語とする
- 名詞N(
C. 名詞ー形容詞
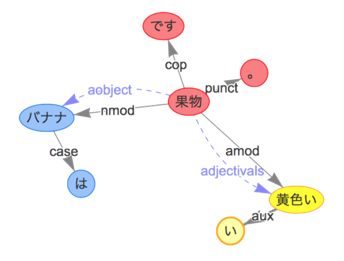
- 例文:「バナナは黄色い食べ物です。」
- 抽出したいペア:
バナナ&黄色い - 抽出ルール:
[N1,aobject,N2] & [N1,adjectivals,A] ====> (N2,A)- 名詞N2(
バナナ)が名詞N1(果物)という属性を持っており、N1(果物)がA(黄色い)で形容される場合、N2(バナナ)とA(黄色い)は連想語とする。
- 名詞N2(
D. クラスーインスタンス
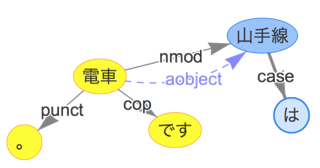
- 例文:「山手線は電車です。」
- 抽出したいペア:
電車&山手線 - 抽出ルール:
[N1,aobject,N2] & [N1,cop,X] ====> (N2,N1)- 名詞N2(
山手線)が名詞N1(電車)という属性を持っており、N1(電車)が連結詞X(です)を持つ場合、N2(山手線)とA(電車)は連想語とする。
- 名詞N2(
E. その他
上記以外にも、以下のようなルールを組み込みました。
それぞれがどのような意味かはリファレンスをご参照いただければと。
[N1,aobject,N2] ====> (N2,N1)
[N1,agent,N2] ====> (N2,N1)
[N1,aobject,N2] & [N1,adjectivals,A] ====> (N2,A)
[N1,aobject,N2] & [N1,cop,X] ====> (N2,N1)
[X,agent,N1] & [X,cause,N2] ====> (N1,N2)
[X,agent,N1] & [X,adjectivals,N2] ====> (N1,N2)
[N,adjectivals,A] ====> (N,A)
[N,adjectivals,N2] ====> (N,N2)
[A,aobject,N] ====> (N,A)
[N1,conj,N2] & [N1,other,N2] ====> (N1,N2)
[N1,nmod,N2] & [N1,other,N2] ====> (N1,N2)
[N1,adjectivals,X] & [X,agent,N2] ====> (N2,N1)
[N1,adjectivals,N2] & [N1,nmod,N2] & [N2,case,X] ====> (N1,N2)
[N1,aobject,N2] & [N1,amod,X] ====> (N2,X)
[N1,aobject,N2] & [N1,amod,A] ====> (N1,A)
[N1,amod,A] ====> (N1,A)
[V,agent,N] ====> (N,V)
2. 連想語ペアをネットワークにする
コーパスから連想語のペアを取得するで得られた連想語をノードとして実際にネットワークを構築します。
適当な文章を入力したときのネットワークを見てみましょう。
まず、
バナナは黄色い果物です。
という文を入力したときの構文解析結果と連想ペアネットワークを見てみましょう。

ルールC「名詞ー形容詞」
(抽出ルール:[N1,aobject,N2] & [N1,adjectivals,A] ====> (N2,A))より、
["果物",aobject,"バナナ"] & ["果物",adjectivals,"黄色い"] ====> ("バナナ","黄色い")
となり、"バナナ"と"黄色い"を連想ペアとして取得します。
同様に、
[N1,aobject,N2] ====> (N2,N1)
より、
["果物",aobject,"バナナ"] ====> ("果物","バナナ")
となり、"果物"と"バナナ"を連想ペアとして取得します。
またまた同様に、
[N,adjectivals,A] ====> (N,A)
より、
["果物",adjectivals,"黄色い"] ====> ("果物","黄色い")
となり、"果物"と"黄色い"を連想ペアとして取得します。
以上3つの連想ペアをネットワークに起こすと上図右のようになります。
続いて
リンゴは赤い果物です。
という文を追加で入力したときの構文解析結果と連想ペアネットワークをご覧ください。
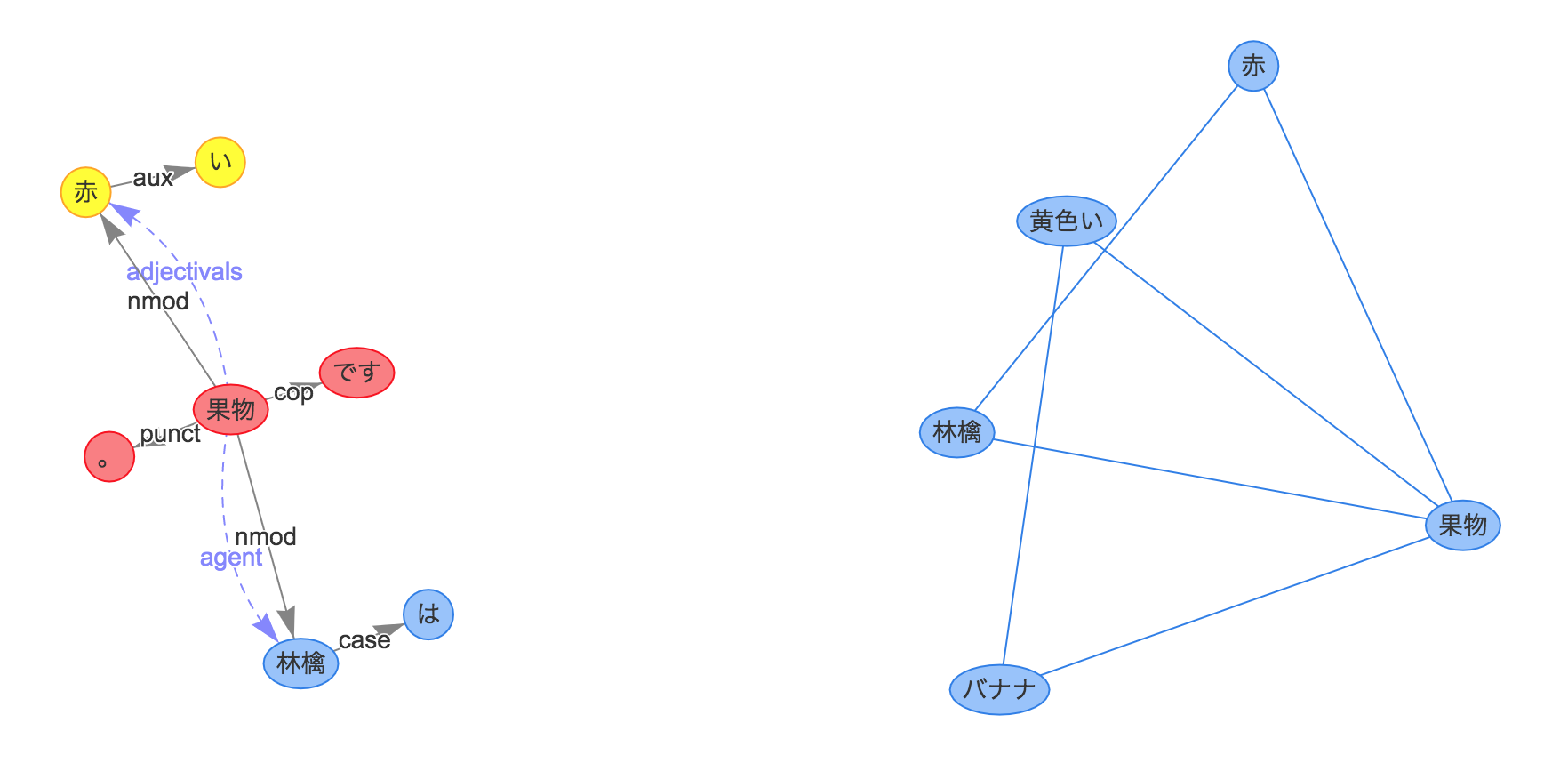
連想ペアの取得は、先程の文と全く同じルールで抽出できますね。
ただ、今回の連想ペアをネットワークに落とし込む際、既存のネットワークと"果物"ノードが競合してしまいます。
そのような場合は、競合ノードをハブとしてネットワーク同士を結合します。
そうしてできあがったのが、上図右のネットワークになります。
上記のようにデータを学習させていった結果、連想ペアネットワークを構築していきます。
モデル利用編
1. ユーザの入力ワードからネットワークをたどり連想語候補を取得する
ユーザがワードを入力したら、連想ペアネットワーク中から入力語と隣接しているノード一覧を取得します。
2. 入力ワードと連想語候補の類似度を算出し、最終的な連想語を決定する
連想語候補の中から、COTOHA APIの類似度算出APIを利用し、最も類似度が高い単語を選択します。
できたもの
以上の工程を踏んで完成したマジカルバナナゲームが以下になります!

全体的にいい感じですが、中でも
ポケモン→サトシ
ポケモンマスター→夢
とかは面白いですね。
彼の夢はポケモンマスターになることだ みたいな文が学習データにあったんでしょうか。
今回は学習用コーパスとして日本語Wikipediaのdumpデータから取得した14万文弱(全体の約2%)を利用しました。
この程度のデータ量でもまずまずの感じの結果が出ていますが、もちろんコーパスを拡充させればより精度が上がることが見込まれます。
同じコーパスを使ってword2vecでマジカルバナナをした場合との精度比較、とかもいつかやってみたいですね。
まとめ
COTOHA APIでマジカルバナナゲームを作りました。
- 連想ペア取得ルールが足りないんじゃなかろうか
- 連想語候補を絞り込む際のロジックとして、類似度が最も高いものを使う、という手法でいいのか
などなど改善点はありますが、それっぽく動いたので満足です。
みなさんも是非COTOHA APIを使って面白いものや役立つものを作ってみてください!
ちなみに…
だいぶ時間が空いてしまいましたが、2018年10月27日〜28日に明星大学日野キャンパスで開催されたオープンソースカンファレンス2018 Tokyo/Fallに参加してきました。
カンファレンスの中で自然言語処理入門と活用というタイトルで講演も行ったのですが、その中で今回のマジカルバナナゲームについても触れているのでよろしければそちらも是非。
さらなる余談ですが、数あるQiita記事の中で「マジカルバナナ」タグをつけたのはこの記事が初です。
今後も増えることはないでしょう。(多分)