内容
pycharmでmermaid記法が使えるようになりました。
しかし、日本語を図中に書くと文字化けするという問題が発生します。
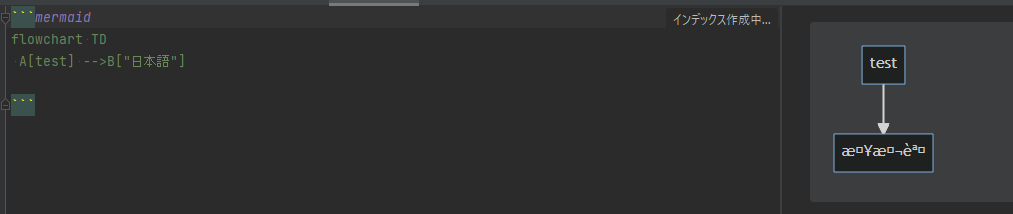
最終的に解決はしませんでしたが、理由はわかりましたので共有しておきます。
解析する
以下のような文字化けが起こっています。
日本語 → æ¥æ¬èª
あんまり見たことないタイプの文字化けですね。
よくあるタイプの文字化けだとわけのわからん漢字がでてきますけど、出てきたのはラテン語ですした。
ラテン語の文字コードといえばlatin-1なので、UTF-8→ bytes → latin-1の変換が起こったのではないかと目星をつけて検証していきます。
検証環境はpython REPLを使用します。
>>> data = '日本語'
>>> data.encode('UTF-8').hex()
'e697a5e69cace8aa9e'
日本語をUTF-8でエンコードすると、'e697a5e69cace8aa9e'という16進数で表現されていました。
これをlatin-1でデコードしてみます。
>>> bytes.fromhex('e697a5e69cace8aa9e').decode('latin-1')
'æ\x97¥æ\x9c¬èª\x9e'
これで最初に出た文字化けと一致しますね。
従って、pycharmのこのバグはUTF-8で書かれた文字列をlatin-1でエンコードしてしまっていることによるものだと判明しました。
今後
調べてみると、中国語も変換されていないと公式ページで報告されていますね。 VSCodeのほうでは普通にエンコードできるので、時間が解決する問題でしょう。
マークダウン自体は書けるので、表示だけを別のエディタなどで表示しておけばいいかな?