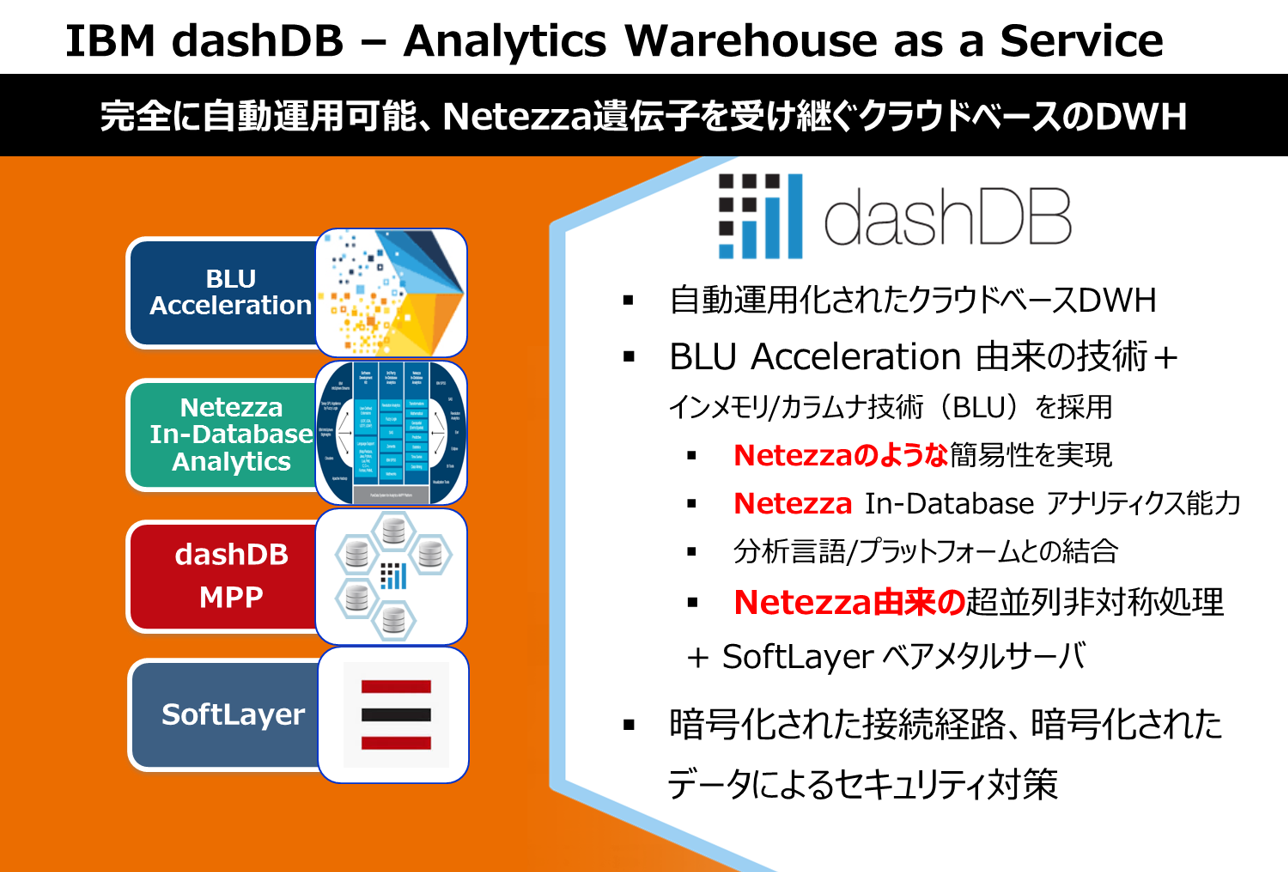
dashDB MPPとは何か?
dashDB MPPとはIBM Bluemix上で提供されるクラウドデータウェアハウスサービス(DBaaS)であり、フルマネージドで提供されるサービスです。IBM DWHアプライアンスであるPuradata System for Analytics(Netezza)由来の簡易性(チューニング不要、物理設計不要)、超並列アーキテクチャ、In-Database Analytics機能を備え、DB2 BLU由来のインメモリカラムナー技術を実装しています。クラウドデータウェアハウスサービスとして提供されますが、共用クラウド基盤ではなく、IBM SoftLayer上の専用ベアメタルサーバーが使用されており、3ノードから25ノード(2016年3月時点)、最大データ容量100TBまで拡張可能なMPP(Massive Parallel Processing)アーキテクチャ、スケーラビリティを持ったクラウドデータウェアハウスサービスです。
dashDB MPP概要
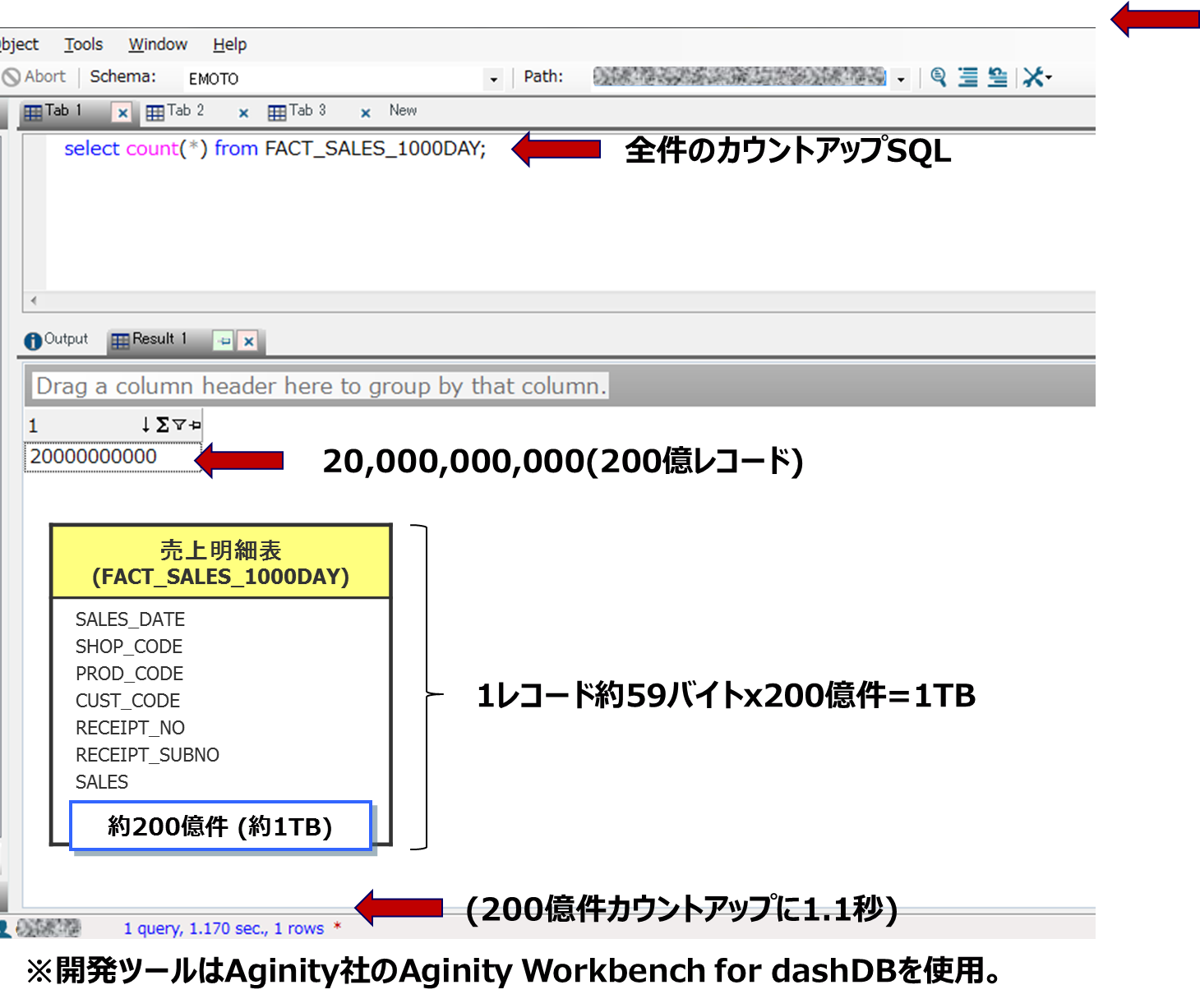
dashDB MPP 4ノードは200億件(1TB)のフルスキャンに何秒かかる?
今回、dashDB MPP 4ノードを使える機会を頂いたので、是非大量データのスキャン性能、パフォーマンスを計測してみたいと思い、下記のようなケースをやってみました。今回用意したFACT_SALES_1000DAY表は200億件のレコード(1レコード: 約59バイト x 200億件 = 1TB)を使用してフルスキャンを掛けてみたいと思います。まずは本当に200億件入っているか、カウントアップで確認してみたいと思います。
では次にこの200億件のデータに対して、フルスキャンを掛けてみたいと思います。ただし単純にフルスキャンをかけても面白くないので、%xxxx%のあいまい検索をかけて前方・後方不一致を確認させることで全データを検索した後、検索対象レコードの売上金額をSUM関数で合計を取得、Group By, Order by句を使用して、店舗ごとにグループ化、ソートを行った上で売上金額上位の店舗から10位を表示する形としました。
では検索やってみましょう!
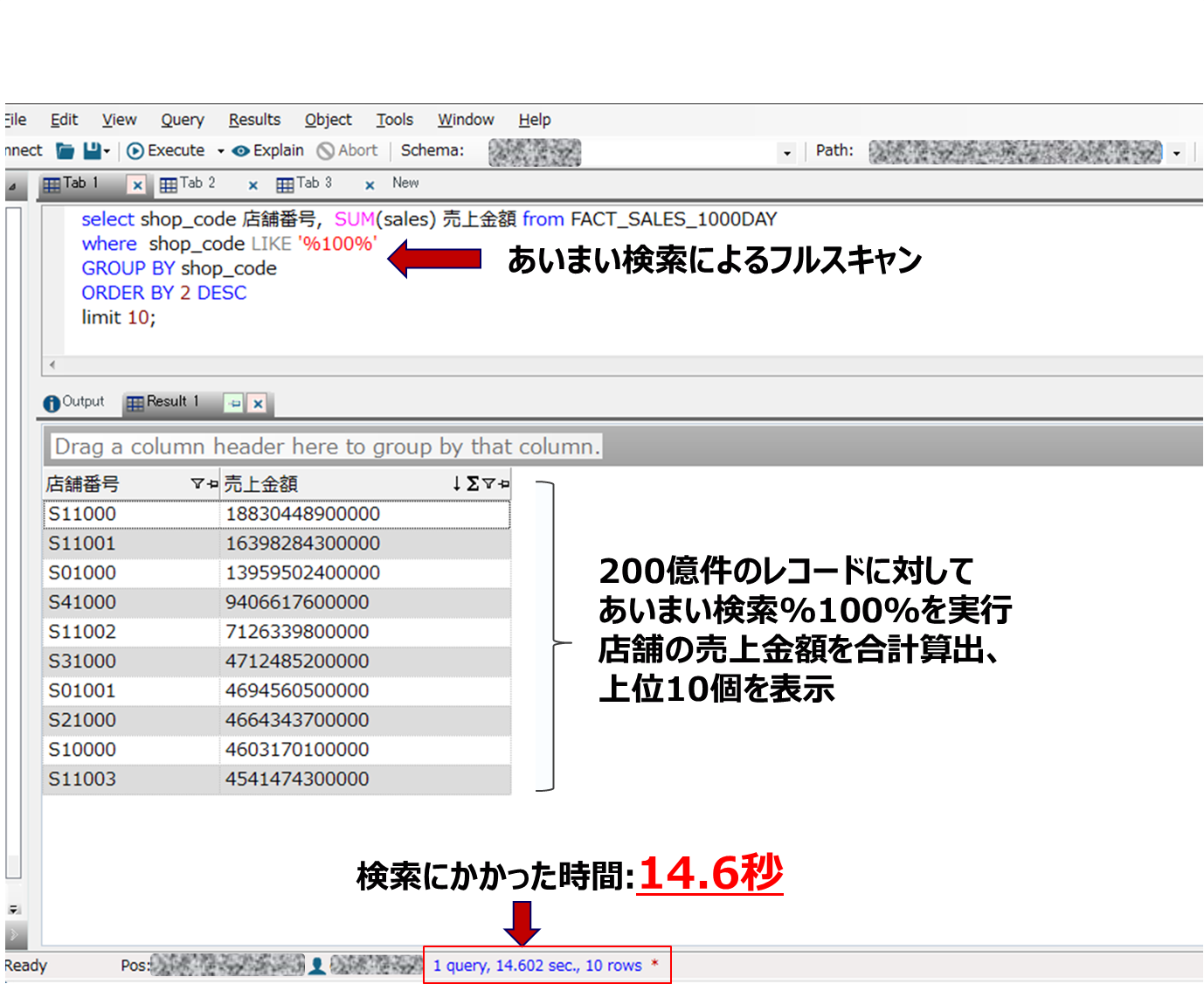
おー、200億件,1TBのあいまい検索に14秒って速いですね~。初回から何回やっても誤差は1秒以内なのであまりスピード変わらないですね。200億14秒ということは、100億件相当であれば、7秒程度で読めるってことだと思うので、dashDB MPP 4ノードとはいえ並のDWHシステムではないですね。
ただ実際のBIシステムにおいて200億件の売上全データを集計して見るということはあまりしないと思います。多くのケースでは全データ集計処理というよりは、多くのBIクエリが店舗、製品(商品)、期間、顧客等の視点から、データの傾向やパターンを分析するというのが多いかと思います。
なので、今度は200億件を持った明細表から全表検索ではなく、少しだけ視点を変えて1ヶ月分のデータ(6億4000万件)に対して同じようなクエリを実行したらどうなるか見てみたいと思います。
dashDB MPP 4ノードは200億レコードから1ヶ月分のデータを読むのに何秒かかる?
今回は先程使用したクエリに日付範囲指定として2012年1月の指定を追加したクエリを実行していみたいと思います。ちなみに今回データロードしただけなので、通常のRDBMSでやっているような、パラメータ変更、物理設計、インデックス作成、パーティショニング作成といった作業は実施していません。この状態で日付範囲指定で検索をかけた場合、どうなるか試してみ見ました。
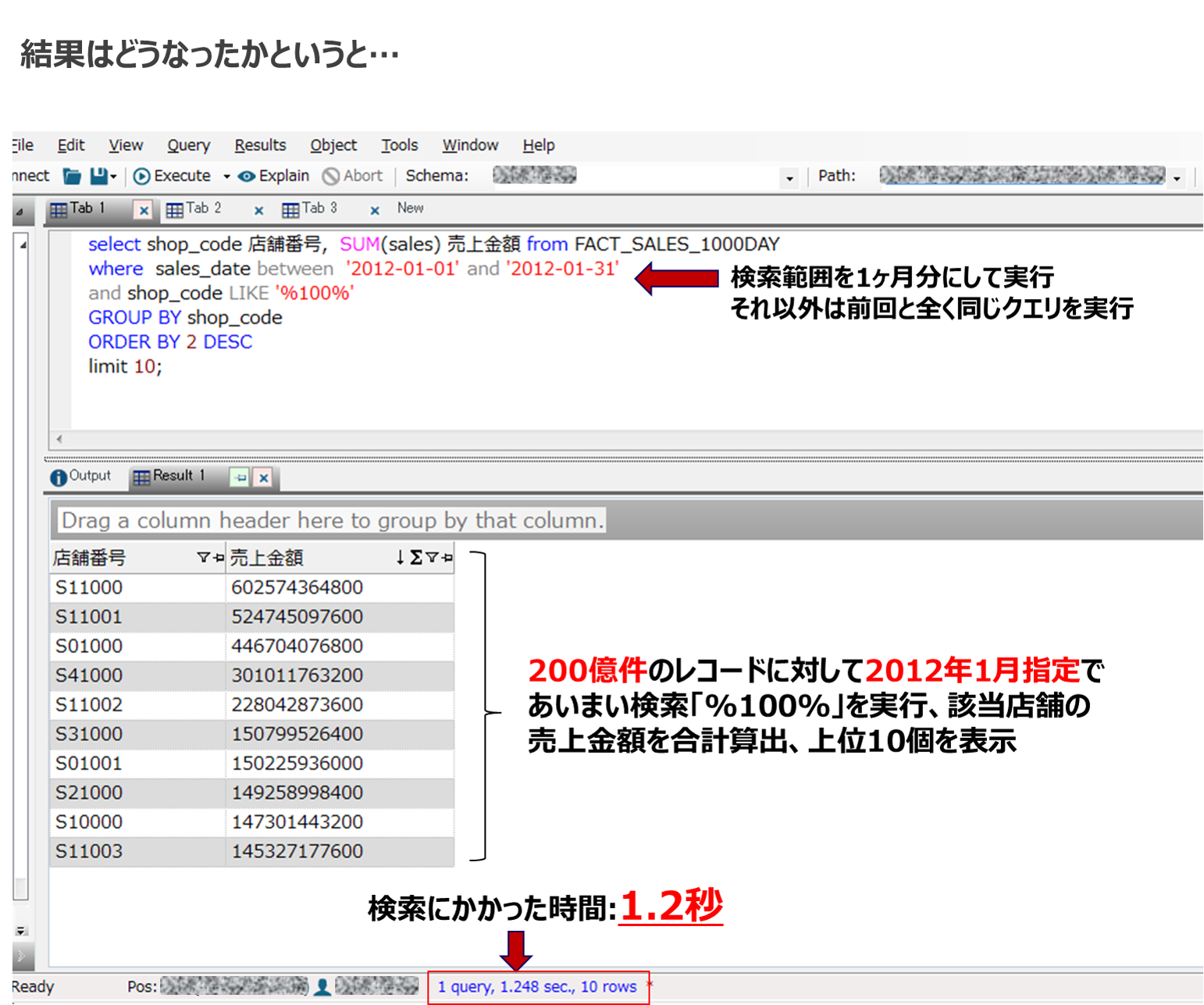
フルスキャンでかかっていた時間が何のチューニングもなしに1/10以下に短縮された。
検索範囲が特定されると自動的に読み込み範囲が絞られているのか、検索処理時間が短くなっています。このあたりはNetezzaで使用されていた特許技術であるZone Mapと同じような技術が実装されているのではと思います。
今回はまず簡単に出来そうなところで、大量データの単体検索性能や日付範囲指定した際に処理時間がどうなるかを実際に動かして見てみました。次回以降はより現場で使われそうな分析軸を想定したクエリを使用した場合の処理スピード感やIn-Databaseアナリティクス機能についても実際に動かして試していきたいと思います。
参考資料
Make Big Data small with IBM dashDB Enterprise MPP
Now Available: dashDB Enterprise MPP
Introducing dashDB MPP: The Power of Data Warehousing in the Cloud