こんにちは、donaldchiです。
今回は、2014年にACLで発表された Dependency-Based Word Embeddingsという論文を読んだので、そのメモを共有します。 自分がわかる程度のメモなので、超ざっくりしていますが、誰かに参考になれればと思い、編集せずにいきなり貼っておきます。何か間違ったところや指摘があれば、コメント欄で書いてくださると幸いです。
一言まとめ
word2vecにおけるCBOWやSkip-Gramのコンテキストは線形コンテキスト(linear context)であって、ターゲット単語前後windowサイズ分の単語しか考えていない。本手法では任意コンテキストの応用を主張し、Skip-Gram with Negative samplingを一般化する。例として文中の係り受け関係(dependency)を用いた分散表現を求め、実験を通してその有効性を主張している。
論文情報
- タイトル: Dependency-Based Word Embeddings
- 著者: Omer Levy and Yoav Goldberg
- 論文リンク: https://levyomer.files.wordpress.com/2014/04/dependency-based-word-embeddings-acl-2014.pdf
- スライド: https://levyomer.files.wordpress.com/2014/06/dependency-based-word-embeddings-acl-2014.pptx
- ソースコード: https://bitbucket.org/yoavgo/word2vecf
- ブログ: https://levyomer.wordpress.com/2014/04/25/dependency-based-word-embeddings/
概要・背景
- 単語間のsemantic and syntactic類似度が計算できる表現を求めたい。例えば、
pizzaとhamburgerは関連性があるのに、従来の単語表現(e.g. one-hot)だとこういう関連性が無視される - 関連性を扱うために、「似たようなコンテキストをもつ単語は似ている」(words in similar contexts have similar meanings)というHarris (1954)のdistributional hypothesisの元で様々なアプローチが出ている
- そのうちもっとも良い精度を出しているアプローチがNeural Embeddingsである
- denseなvectorで単語を表現可能
- 単語間の類似度計算が可能になる
- 有名なのはword2vecで、その中でもskip-gram with negative samplingを用いた単語分散表現がSOTAを達成している
- word2vecは線形コンテキスト(linear context, Bag-of-words context)を用いて分散表現を求めている
- 違うコンテキストを用いたアプローチは違う単語表現を生成していて、単語間の類似性も違ってくる
- Bag-of-words contextの場合、topical 類似度が計算される。
e.g.
| Target Word | Bag-of-words (similar words) related to dance |
|---|---|
| dancing | singing dance dances dancers tap-dancing |
新規性
- 任意のコンテキストに対応できるようにskip-gramを一般化するのを主張
- 具体例として、係り受け(dependency)関係を用いて単語分散表現を求める
手法
- Goldberg and Nivre, 2012のdependency parsing技術を用いてdependency構造解析を行う
- e.g.
Australian scientist discovers star with telescopeを分析した場合を考える
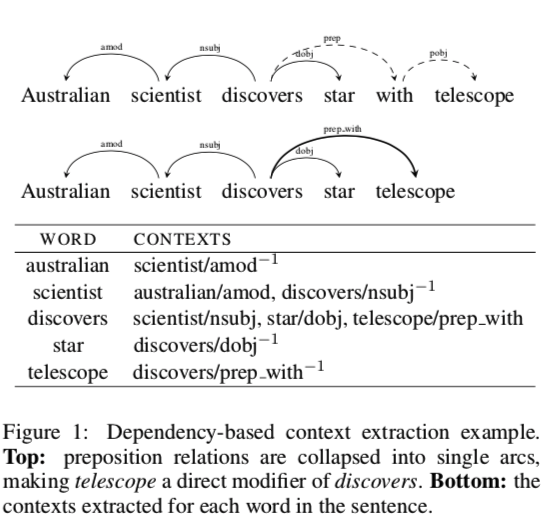
- prepostion関係がある場合は、係り受け関係先の単語は無視して、その一方先の単語を考える
- e.g. discoversとwithがpreposition関係で、withとtelescopeがobject of a preposition関係である時、withを無視して、telescopeがdiscoversのコンテキストになる
- ターゲット単語 w、wの修飾語(modifier)をm_1, m_2, ..., m_k、headを h、dependency関係ラベルをlbl(e.g. nsubj, amod, prepなど)とした場合、単語wのコンテキストは (m_1, lbl_1), ..., (m_k, lbl_k), (h, lbl_1^-1)となる。
- e.g. window_size=1とした場合、例文のコンテキストは、上図のテーブル内容のようになる。
- 上のステップで得たコンテキストとSkip-Gram with Negative sampling技術を用いて、単語の分散表現を求める
結果と論文内の議論
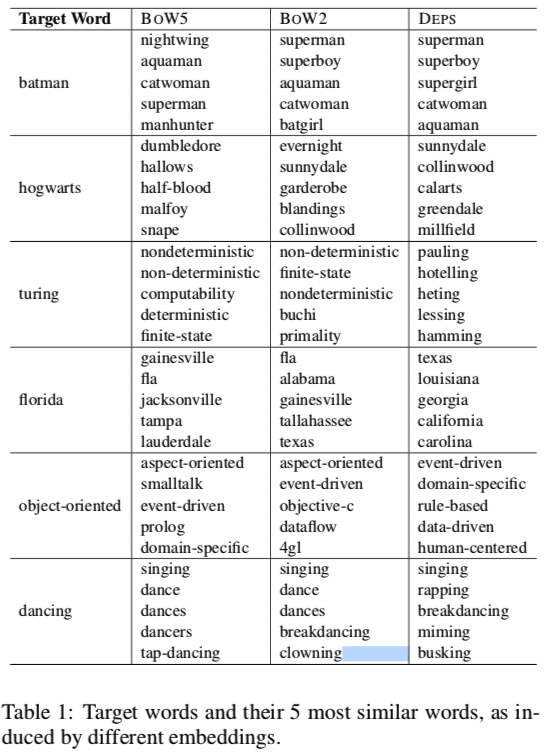
- Bag-of-Word contexts find words that associate with target word
w, while Dependency parsing contexts find words that behave like target wordw。Turney, 2012 described this distinction as domain similarity versus functional similarity。
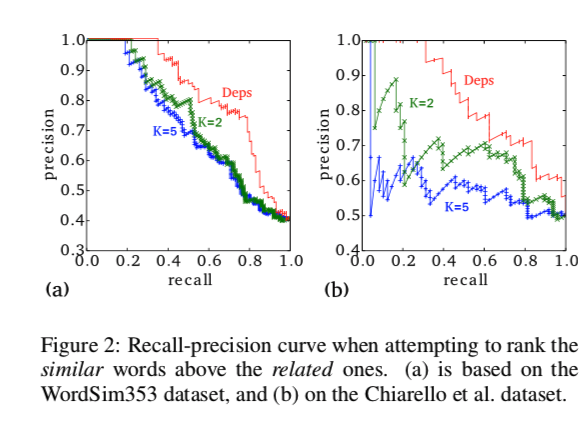
-
domain similarityをもつ単語ペアとfunctional similarityをもつ単語ペアが混ざっているデータを用いて各種コンテキストを用いた分散表現によるコサイン類似度を計算した。まだこの類似度によって予測された結果を用いて、recall-precision curveを描いたのが上図である - 結果から、確かにdependency contextによる分散表現が
functional similarityを掴んでいることがわかる
考察
- 本手法は実験で、word2vecとは違くfunctional similarityが高い単語同士が類似度が高いことがわかっている。
- 結局
functional similarityは係り受け関係中で同じ役割をしている単語間の類似度をさしている。 - dependency parsing contextは結局syntatic contextを利用したことになる。