【新人教育 資料】第6章 SQLへの道 〜ソート編〜
あらすじ
新人がいっぱい入ってくる。新人のレベルもバラバラ。教育資料も古くなっているので、更新しましょう。
どうせなら、公開しちゃえばいいじゃん。という流れになり、新人教育用の資料を順次更新していくことにしました。
※後々、リクエストに応じて更新することが多いのでストックしておくことをおすすめします。
自分はTEMONA株式会社でCTOをしていますが、頭でっかちに理論ばっかり学習するよりは、イメージがなんとなく掴めるように学習し、実践の中で知識を深めていく方が効率的に学習出来ると考えています。
※他の登壇やインタビュー記事はWantedlyから見てください。
教育スタイルとしては正しい事をきっちりかっちり教えるのではなく、未経験レベルの人がなんとなく掴めるように、資料を構成していきます。
以下のようなシリーズネタで進めます。
では、今回もはじめていきましょう!
SQL ソート ORDER BY
ソートは、データの並べ替えのことです。昇順、降順のことですね。
めちゃくちゃ大事な事が標準SQL規格99に書いてあります。
mariadbのドキュメントを参考に見てみると
https://mariadb.com/kb/en/sql-99/order-by-clause/
An ORDER BY clause may optionally appear after a <query expression>: it specifies the order rows should have when returned from that query (if you omit the clause, your DBMS will return the rows in some random order). The query in question may, of course, be a VALUES statement, a TABLE statement or (most commonly) a SELECT statement. (For now, we are ignoring the possibility that the SQL statement is DECLARE CURSOR, since that is strictly a matter for "SQL in host programs", a later chapter.)
要約するとORDER BY で並び替えを明示しない限り、RMDBSの実装に委ねることになるということです。
特にPostgreSQLは追記型DBのアーキテクチャを採用しているので、ORDER BY でソートを明示しないと
びっくりするぐらい順序が変わってしまいます。
データベースの管理として追記型DBでは、レコードに更新があった場合に、元々あったレコードを利用するのではなく、前のあったレコードとは別に新しいレコードを追加させて、前のレコードのポインタ(位置情報だけを)を消すようなアーキテクチャです。
今回は紹介しませんが
PostgreSQLでは、あるテーブルをORDER BY 句でソートキーを明示せずにSELECTし、結果を取得した後、特定のレコードをUPDATE文で更新をした後、再度SELECTすると結果の順序が変わるのが確認出来ると思います。
では実際にSQLとしてどのようにソートを表現するのか見ていきましょう。
事前準備(終わっていない人は実行)
前回同様に、勉強用のレポジトリを用意しているので
下記のレポジトリをForkして、Readmeを参考に環境構築をしてください。
https://github.com/TEMONA/mysql_study
※全てにおいて自己責任でお願いします。
上記の事前準備が終わっていることとして、下記の説明を進めていきます。
$ mysql -u root
mysql> use mysql_study;
ORDER BY
SELECT * FROM テーブル名 ORDER BY ソートしたいカラム[,ソートしたいカラム] 並び順の指定
| 指定 | 説明 |
|---|---|
| ASC | 昇順 |
| DESC | 降順 |
並び順の指定を省略した場合はASCがデフォルトです。
複数のソートキーも対応しています。はじめに書くほど優先でカラムが実行されます。
弊社が用意したレポジトリのテストデータを利用した場合には
ユーザテーブルに1,000件データが入っているので、例にとりみていきましょう。
今までに教えていないところも触れながらいきます。
SELECT COUNT データの件数を数える
データの件数を数えます。
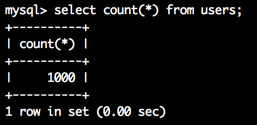
select count(*) from テーブル名;
実際に実行してみましょう
select count(*) from users;
LIMIT 取得する件数を表示する
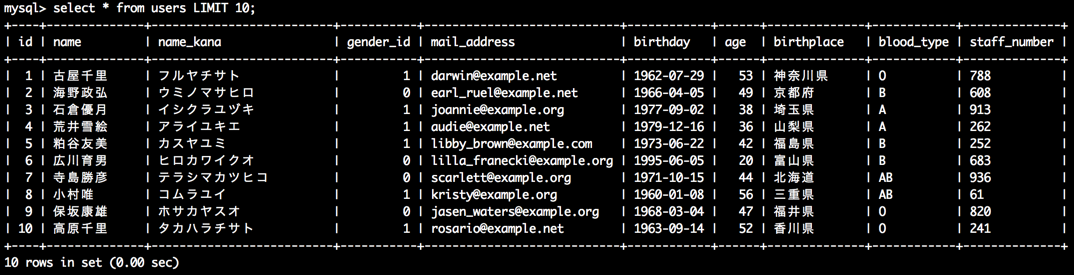
select * from テーブル名 LIMIT 取得件数;
実際にやってみましょう。
select * from users LIMIT 10;
画像を見て頂くとわかりますが、ageの列をみると、並びはバラバラですね。
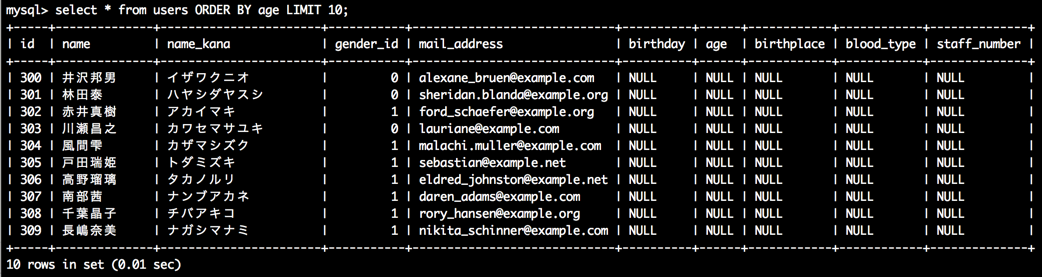
ORDER BY 並び順を省略してみる
select * from users ORDER BY age LIMIT 10;
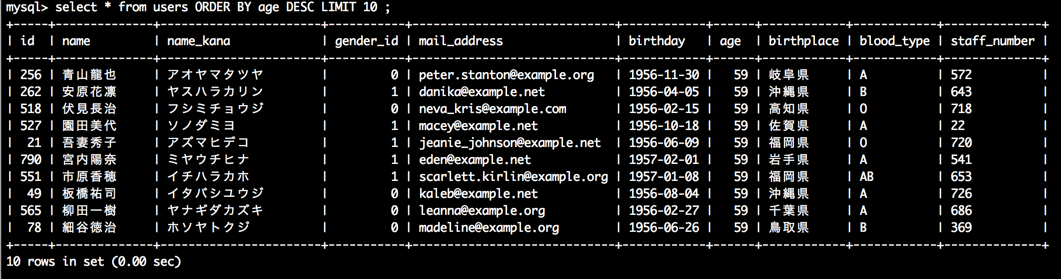
ORDER BY ASC
select * from users ORDER BY age LIMIT 10;
DESCRIBE
テーブルの定義情報を確認することが出来るのがDESCRIBE文です。
DESCRIBE テーブル名;
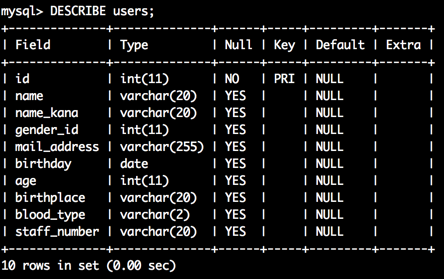
上記の図で説明すると
左のカラムから「Field(カラム名)」、「Type(データ型)」、「Null(null制約)」、「Default(初期値)」、「Extra(その他)」となります。
RMDBSの種類によってDESCRIBE文の構文は違うので注意してください。
EXPLAIN
ここからは少しコストの話しも含めて理解するために「EXPLAIN」というSQLをご紹介します。
RMDBSではオプティマイザという機能があり、データの分布情報を示す、統計情報に合わせてRMDBSの内部で処理の最適化を行ってくれます。EXPLAINを使う事で内部の実行コストがある程度分かります。
EXPLAIN 出力フォーマット
| カラム | 意味 |
|---|---|
| id | SELECT 識別子。 |
| select_type | SELECT 型 |
| table | 出力行のテーブル |
| partitions | 一致するパーティション |
| type | 結合型 |
| possible_keys | 選択可能なインデックス |
| key | 実際に選択されたインデックス |
| key_len | 選択されたキーの長さ |
| ref | インデックスと比較されるカラム |
| rows | 調査される行の見積もり |
| filtered | テーブル条件によってフィルタ処理される行の割合 |
| Extra | 追加情報 |
詳細のところはまたどこかで説明するとして今回紹介しておきたいのは
「type」です。
| 種類 | 説明 |
|---|---|
| const | PRIMARY KEYまたはUNIQUEインデックスのルックアップによるアクセス。最速。 |
| eq_ref | JOINにおいてPRIARY KEYまたはUNIQUE KEYが利用される時のアクセスタイプ。constと似ているがJOINで用いられるところが違う。 |
| ref | ユニーク(PRIMARY or UNIQUE)でないインデックスを使って等価検索(WHERE key = value)を行った時に使われるアクセスタイプ。 |
| range | インデックスを用いた範囲検索。 |
| index | フルインデックススキャン。インデックス全体をスキャンする必要があるのでとても遅い。 |
| ALL | フルテーブルスキャン。インデックスがまったく利用されていないことを示す。OLTP系の処理では改善必須。 |
詳細は以下のページを御覧ください。
MySQL 5.6 リファレンスマニュアル / ... / EXPLAIN 出力フォーマット
実際にEXPLAIN文を追加してSQLクエリを実行していきましょう。
主キーをソートキーに指定してみる
EXPLAIN SELECT * FROM users ORDER BY id DESC LIMIT 10 ;
「type」が「index」になっていますね。
「rows」が「10」になっていますね。
これは索引となるINDEXだけをみたので、検索時に触った件数が「10」件だった事が読み取れます。

主キー以外をソートキーに指定してみる
では主キー以外をソートキーに指定してみるとどうでしょうか?
EXPLAIN SELECT * FROM users ORDER BY name DESC LIMIT 10 ;
「type」が「all」になっていますね。
「rows」が「100」になっていますね。
「Extra」が「Using filesort」になっていますね。
これは索引となるINDEXだけが存在しなかったため、テーブルの情報を全件検索した後に、ソート(並び替え)を行ってから、結果を表示していることが読み取れます。名前のカラムに対して降順で10件取得したいだけなのに、わざわざテーブルの全件を検索してから、並び替えた後に検索結果を10件と絞り込んでいます。
このテーブルの全件を検索してからという箇所が大変やっかいな話しなのです。
【新人教育 資料】ハードウェア編で紹介した、まな板や冷蔵庫の話で説明します。
RMDBSはパフォーマンスを最大化するためにハードウェアのリソース(CPU,メモリ,HDD)を頑張って利用する設計に大抵はなっていますが、このテーブル上のデータを律儀に全件を検索してからというのは、モノを取り出すのに遅い、冷蔵庫から毎回データを取り出していることになります。
しかも10件だけ表示したいのに、テーブルの全件を検索するなんて、とてもナンセンスですよね。
100件だけだったら、何も差を感じないと思いますが、これがテーブルに保持されているレコード件数が1000万件だったらどうでしょうか?想像してみてください。

最近のRMDBSのオプティマイザもだいぶ頭が良くなっていますが、解決するには色々チューニングも含めて対応していく必要があります。
※少しむずかしい話もしってみたいという人は以下のページをよく読んでみてください。
8.2.1.15 ORDER BY の最適化
照合順序というお話
あとで書きます。
演習
- データ量の多いareasテーブルで色々ソートしてみましょう。
- 【新人教育 資料】第5章 SQLへの道 〜絞込編〜で紹介しているSQLをEXPLAINで実行してみましょう。
参考文献
mysql5.6 リファレンスマニュアル: https://dev.mysql.com/doc/refman/5.6/ja/
あとがき
この章で紹介しましたが、ORDER BY句がない場合は取得順序に保証がありません。特にPostgreSQLのような追記型だと如実に困るのでORDER BY句は必ず入れるようにしましょう。例えば、何かのデータの表示をID降順で表示させたい場合には、UPDATE文が実行されしまうと、表示順序が変わってしまいます。ORDER BYを明示で入れることが必要です。
実際にはDBをデータ移行する自体が発生しましたとか、マスタ用のデータで表示順序を変えたいみたいな要望が出たりするので
データ保持用のカラム以外に、表示順序番号みたいなカラムを別途用意し、意図的に表示順序変えられるようにするなどの考慮が必要になってきます。
次回は「【新人教育 資料】第7章 SQLへの道 〜集合関数(SUM、MAX、MIN、AVG、COUNT)編〜」をお送りする予定です。
明日はヒカラボに登壇する予定です。もしかしてこの記事を見てくれている人もお会いするかもしれないですね。もし見たって人がいれば声をかけてください。