はじめに
データサイエンス・機械学習っておもしろそうだけど、どうやって勉強すすめたらいいんだろう?というところから2月に勉強をスタートし、勉強のinputだけではなく実践したいと思って3月にKaggleのコンペに参戦!
その結果がなんと、銀メダル (+上位3%)をとることができました!
この記事では、そんな自分の勉強してきた過程とコンペを進めてきた流れをまとめてみようと思っているので、一例として見てもらえると嬉しいです!

概要
➀コンペの紹介
➁コンペ終了までの流れ
(コンペ参加する前→コンペ参加後)
③コンペ中にしていたその他の勉強
今回参加したコンペ
M5 Forecasting - Accuracy コンペ (2020年3月~6月)

今回取り組んだコンペは、この時系列データのテーブルコンペで、内容としては、アメリカの小売大手であるウォルマートの「商品の売り上げ予測」
過去約5年間分のデータが与えられた上で、その後に続く1か月(28日分)の売り上げ予測をするといったものでした。
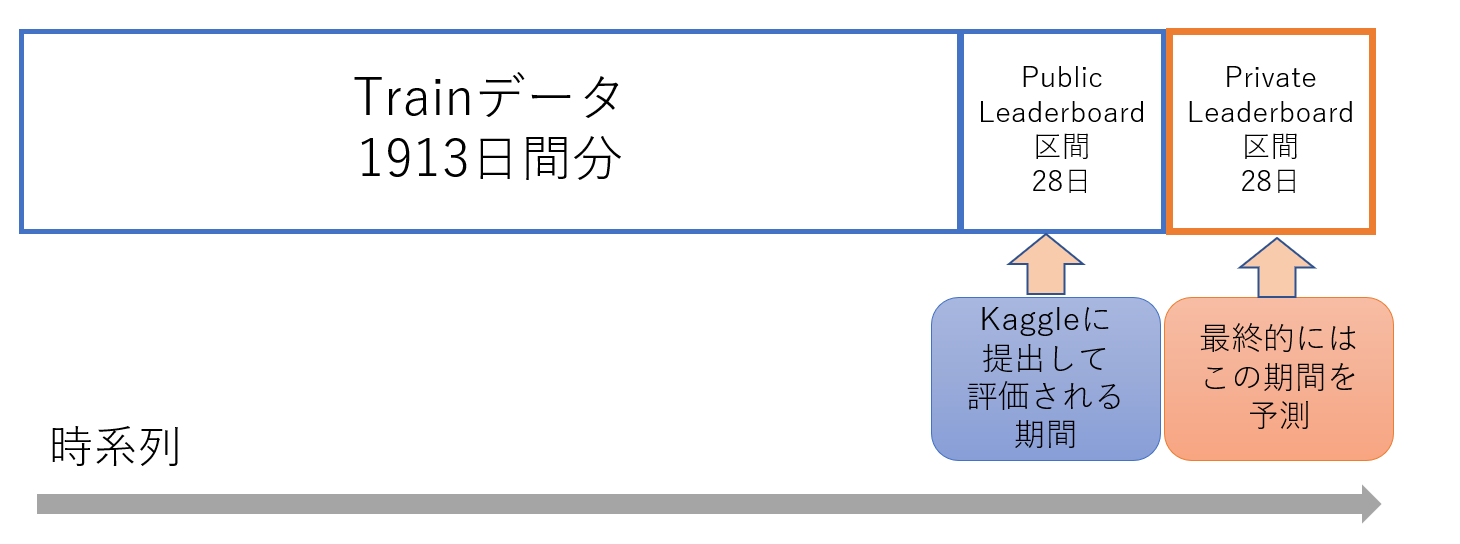
(感想としては、データ量が多かった......。 メモリの使い方も含めて、効率の良いプログラムを考えさせられたコンペにもなりました)
タイムライン
3月から6月末までの4か月間のコンペで、タイムラインとしては、以下のように進んでいきました。
3/3 コンペ開始
↓
3月の中旬 コンペに参戦
↓
6/1 Public Leaderboard の期間の正解データ公開
(Kaggleに予測結果を提出しても、自分の相対的な順位がわからない目隠し状態に! )
↓
6/30 コンペ終了
結果
記事の冒頭でもふれましたが、
結果は... 114位(上位3%) ![]() !! (純粋にうれしい!)
!! (純粋にうれしい!)
・エントリー数:88,742
・チーム数:5,558
コンペに取り組むまでの流れ(勉強のしはじめ)
python以外のプログラミング言語の経験はありましたが、この時点では、自分自身pythonを使ったことがなかったので、pandasって何?matplotlibって何?というような基本的なライブラリですら知らない状態から始めました。
この期間は、主に、機械学習やpythonの基礎知識を吸収する期間として考えていました。内容としては、別の記事(機械学習をゼロから学ぶための勉強法)にまとめてあるので、詳しくはこの記事を参照してもらえればと思いますが、ここでは簡単にまとめて話すと、
以下の3点をおさえられるような本・サイトを見つけて、勉強をしていったというような流れです。
➀機械学習の基礎知識をつける(単語・用語の理解)
→ 機械学習&ディープラーニングのしくみと技術がこれ1冊でしっかりわかる教科書 (本)
➁ライブラリの使い方を理解 (numpy,pandas,matplotlibなどデータサイエンスで必須なもの)
➂実際にコンペに挑戦(Kaggle)するための入門書
→実践Data Scienceシリーズ PythonではじめるKaggleスタートブック (本)
M5コンペに参加してから
友人と4人で参加したコンペでありましたが、Kaggleのメダル対象コンペは全員はじめてということと、長期間のコンペということもあり、探りさぐりで進めてました。ここでは、他メンバーからの助力もありつつですが、チームのタスク・進捗管理の役割を担当していたので、進めていった大まかな流れや使っていたツールについて以下ではその概観をまとめていこうと思います。
全体として、チームでやっていたこと
・週に一度のミーティング
進捗の共有や、ノートブックなどの情報共有、わからないところの質問、検討等。
これを週1で行えたのは、今回のような長期的なコンペではとても有効だとおもった。ここで、今後の方針やタスク管理の話もできたので、とても進めやすかったです。
Slack
週1ミーティングを待たずに、気になったこと等があれば、Slackで情報共有、検討を行った。また、メンバーがSlackをよく使っている人が多かったので、Slackと以下のようなツールを連携させて、通知を集中させることによって、よりKaggleに専念できるようにしてました!
Trello
進捗管理ツールの1つ。
Slack と連携させることで、trelloに進捗を書いたらSlackに通知、Slackからtrelloの更新ができるように。
GitHub
コードの共有など。
Slackと連携させることにより、pushしたときに、commitしたメッセージがSlack にも通知させられるようにした(いちいち、pushしたことを報告しなくていいので便利!)
あとは、容量の重いデータなどはDriveで共有。
(序盤) EDA・前処理中心(全員)
どのコンペでも基本だと思いますが、まず「データの理解・把握」に努めて進めてました。
コンペ開始後2,3週間後にコンペに参加したので、他の人のノートブックも集まりつつあったので、それらを読みつつ、自分たちで解析しつつといった感じです。
(初心者としての戦い方)
個人的に、このころ留意していたこととしては、kaggleを始める前に「勉強してた内容を定着・実践させられるように」という目標を立てて進めてました。
上で紹介したような本やサイトだと、titanicを例にして、基本的な流れや使い方を学ぶことはできるとは思うのですが、やはり実践してみないとつかめないこともあるということで、自分で気になるデータを可視化させたり、処理を行うためにはどうしたらいいかなということを考えながら、前述の本やサイトに戻ったり、他のメンバーに聞いたりして進めていきました。
(中盤)EDA・前処理とモデル作りでの分業(2:2)
全員で前処理を進めていって、ある程度データの概観がつかめてきたあたりで、前処理をそのまま続けるメンバーとモデル作りを進めるメンバーとに役割を分担して進めていこうという話になりました。
どのくらい前処理をしたらいいのかといったペース配分がわからず、最終的にはここで考えた特徴量を活かすことができなかったという点もあったので、次回への反省にしたいなと思いつつ、個人的には、役割を分担したことで自分のタスクがわかりやすくなり、集中できたかなと思ってます。
(初心者としての戦い方)
まだ、前処理が慣れきっていない部分ともう少し経験を積みたいという想いから、中盤では自分は前処理に専念してました。EDA・前処理と一言でいっても意味は広いと思いますが、主に序盤ではデータの可視化・分析を、中盤からはそれを受けてのデータ加工を中心に勉強・実践していきました。
(終盤)前処理しつつも、モデル作り重視(1:3)
終盤に入り、時間的な制約も感じつつあったので、方針を確定させた上で、前処理を中心に行っていた自分も、モデル作りに参戦。
特に、この終盤では、順位の動きが全くわからない目隠し状態に入ってしまっていたので、相対的な位置がわからず試行錯誤したりという感じでした。
(初心者としての戦い方)
後述の通り、AtmaCupを通してモデル作りは経験していたものの、時系列データに関しては取り組んだことはなく、わからない点も多かったので、メンバーから教えてもらいながら取り組めたのは大きかった。また、期間的な問題もあり、この部分に関しては、先行して取り組んでいたメンバーに頼る部分が大きかったので、自分でも複数モデルを作ったり、検証期間を複数とるなどができるように今後頑張っていきたいと感じた。
まとめ
一人でコンペに参加することと比べて、チームでコンペに参加できるとできることの幅が広がりそうと感じていましたが、実際にそうだと思う反面、チームで進めていく上での難しさという面も感じました。私自身Kaggleで初めてのメダル対象コンペだったので、その中で、チームを組んで良かったという点をあげるとすると、以下の点だと思います。
<チームを組んで良かったこと>
- わからないことを気軽に質問できる。
- 役割分担ができるので、自分の勉強したいことを集中して、順番にこなすことができる+得意分野で役割を分担することもできる (一人で始めるとしたら、前処理、モデル作りの勉強をしながら、それらを実装しなければいけないのでかなり大変だと思う)
- 異なる視点からのアプローチ案がでてくるので、一人だけで考えているときより、より多くのアイデアや手法を考えることができる。
最後に、データサイエンス始めたての自分が一人だけでは、このメダル取るまではたどり着けなかったと思っているので、一緒にKaggleのコンペに参加し、質問に応じてくれた友人達に感謝を伝えたいと思っています! 改めてありがとうございました‼
コンペ中に並行して勉強していたこと
少し本編から外れるので「おまけ」といった形になりますが、最後にこのコンペの期間中に他に取り組んでいた勉強(こと)について紹介します。
また自分のアウトプットの一環として、記事にまとめようかとも考えているので、ここでは、簡単にまとめておきますが、主に取り組んでいたのは以下の3つです。
Machine Learning (Coursera) (2020年4月~5月)
ライブラリの使い方も理解してきて、実践で使えるようになってきたものも、どのような仕組みで機械学習を行っているのかがわからない部分もあり、理論的な部分を学ぼうと思って、受けた講座。
理論的な学習をmatlabを使ってできたので、より機械学習を理解する勉強になってよかった。
DeepLearing基礎講座 (東大・松尾研) (2020年4月~)
このコンペでは用いなかったが、深層学習/Deep Learningについて理解したいと思っていたので、受けている講座。
機械学習・深層学習の基礎の部分のみならず、CNN,RNN,強化学習,VAEなどを講義を通して学習し、その後の演習で実践しながら理解ができるようになっているので勉強になっている。(現在進行形)
AtmaCup#5 (2020年5月29日~6月6日)
EDA・前処理・モデル作りの一連の流れを一人で一度やってみたいと思い、参加したコンペ。
内容としては、時系列なしの、テーブル+信号データのコンペ
分析内容が難しかったということもあったが、参加者の中には日本人Kagglerの上位層も複数いて、コンペ終了後のエッセンスの公開や振り返り会では、勉強になることも多かった。