
ClickHouseの使い方についてまとめました!
これを読めば運用できるはずです。
ClickHouseは、主に集計などに最適化されたDBで、容量削減と高速化が期待できます。
書く内容は、「dockercompose,migration,go-clientサンプル」「テーブルの作成テクニック」「パーティション、ORDER BY」「レプリケーション」などを載せます。
2020/01最新
ネットに上がってる記事では、ClickHouseはupdateできないと書いてありますが、updateできるようになってます。これによってテーブルの持ち方などが変わります。
ClickHouse概要
・集計など、大量のデータをreadする処理に最適化されたDBです。
・トランザクションなどを使う処理は苦手です。
・インサート時に「sumやavgなどをその時に計算」してくれる特殊なテーブルなどもある。
・mysqlなどと違い、カラムごとで列でデータを保存するので、同じデータが重複してると、めっちゃ圧縮してくれる。
・コスパ最強。awsなら、EC2とかで動かせば良い。
・マルチマスター形式で、データのシャーディングもできる。
・mysqlとほぼ同じ構文。
・集計するなら、mysqlで同じことをやろうとするとclickhouseの方が圧倒的に早い。
ベンチマーク
容量削減
1/10ぐらいになると言われています。
ただ、データによります。
完全にランダムな文字列が連続するデータではほぼ圧縮されないです。
逆に、似通ったデータや空が多いデータはめっちゃ圧縮される。
メモリとCPUはどっちを増やせば高速になる?
クエリの実行速度をあげたいときは、cpuコア数を増やします。
複数コアで並列に実行してくれるため、高速になります。
メモリ(RAM)は、「同時のクエリ呼び出し数」に比例して増やすと良いです。
また、データキャッシュもされているので、同じデータを連続で叩くこと多い場合はメモリを増やすと効果的です。
テーブル作成
ClickHouseは適切にテーブル作成をする必要があります。
検索高速化のためテーブル作成を以下に書きます。
ORDER BY(重要)
CREATE TABLE時にORDER BYを指定できます。
「order by」には、「group by」で使うカラムを指定すると、高速化することができます。
データインサート時に、指定したカラムで順にソートされて保存されます。
CREATE TABLE テーブル名 (
id String,
group_id String,
name String,
date Date
)
ENGINE = MergeTree()
ORDER BY (date, id, group_id);
上のように作成すると、「date, id, group_id」順でデータがソートされた状態でデータが保存されます。
主に、select時の「group by」がめっちゃ高速になります。
PARTITION BY
「partition by」は、高速化のために使うものでは無いです。
削除が高速にできます。
一般的な用途では、「データを入れ直したい単位(日付など)」などでパーティションを切っておけば良いです。
https://clickhouse.yandex/docs/en/query_language/alter/#alter_manipulations-with-partitions
CREATE TABLE テーブル名 (
a_id String,
b_id String,
date Date
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(date)
ORDER BY (date, a_id, b_id);
マージテーブルとは
マージテーブルは、複数のテーブルに対してクエリを実行できるテーブルです。
正規表現で検索して全テーブルから検索します。
updateができなかった頃は、日別にテーブルを作成して、マージテーブルで検索していましたが、今はupdateができるので、なかなかこのテーブルは使わないはずです。
マージテーブルの注意
「そのDBに含まれるテーブル数」が増えるにつれて、検索速度が落ちます。
(正規表現で検索しているため。思ったよりも速度落ちる。)
テーブル1個辺り、めっちゃメモリ(RAM)を使うので注意
基本的にはテーブル分割でなく「order by」を使えばOK。
データが増えすぎてきたら、cpuコア数を増やすorサーバを増やす。
各言語のClickHouseクライアントライブラリ
以下にまとまっています。
https://clickhouse.yandex/docs/en/interfaces/third-party/client_libraries/
レプリーケーションとシャーディング
zookeeperと一緒に使う。
データを複製しておき、一つのサーバが落ちたら、もう一つのサーバを見に行くには、
「レプリケーションテーブル」と「分散テーブル」を使えばOK。
・レプリケーションテーブルとは
データを各サーバに「分割」or「複製」することができるテーブル。
・分散テーブルとは
各サーバのテーブルを跨いで操作することができるテーブル。
シャードとは
分散させるときに、シャードという言葉が出てきます。
具体例を挙げると、
シャード1に「サーバA、サーバB」
シャード2に「サーバC、サーバD」
シャード3に「サーバE、サーバF」
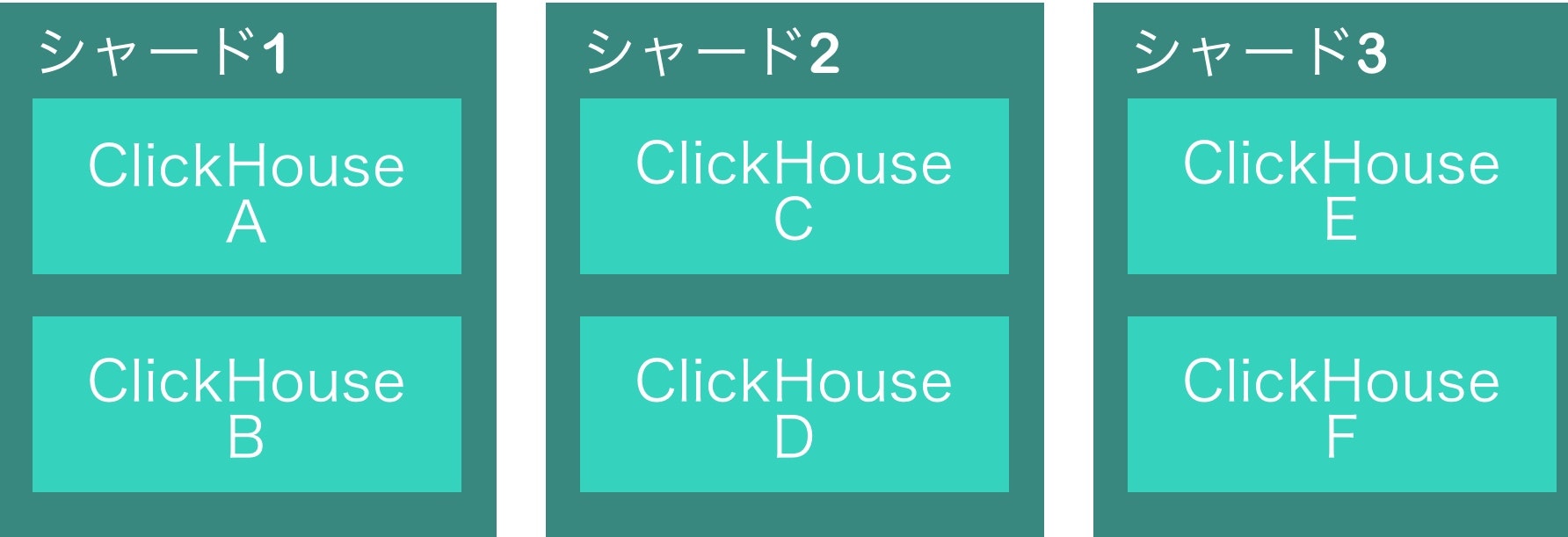
以上の構成だった場合、
「サーバA」「サーバB」には、「同じく複製されたデータ」が入ります。
「サーバA」「サーバC」「サーバE」には、分割されたデータが入ります。
このようにデータの分割する単位がシャードだと思います。
実際に試しにデータインサートしてみたら、
うまい具合にシャードごとに分散された状態になりました。
dockerのサンプルも数日後に載せます。
フェイルオーバー
複数サーバの内、「一つが落ちた場合」に「生きてるサーバに行くようにする」には、
レプリケーションしたサーバを、ALBやHAProxyなどを使って見に行くようにする。
上の図で言うと、シャード1のClickhouseAが死んだらClickHouseBをみに行くようにする。
実際には、マルチマスターなので、どれか生きてるサーバにアクセスするようにすれば、ClickHouseがzookeeperと連動して自動的にみに行ってくれる。
テーブルデータタイプ
mysqlなどとほぼ同じの型があります。
一覧はここにあります。
気をつけるとこと
・nullはなるべく使わない。
・mysqlのvarchar型と、ClickHouseのFixedStringとはちょっと挙動が違うので、stringで入れる。
(FixedString(10)は、10文字キッカリ入れないといけない。検索するなら、ヌル文字を入れて検索しないといけへん)
・Bool型は、int8型で扱う。
clickhouse環境をローカルで作成する。
以下のファイルを用意します。
version: "3.7"
services:
clickhouse:
image: yandex/clickhouse-server
container_name: "clickhouse"
ports:
- 8129:8129
- 9000:9000
以下のコマンドでclickhouseクライアントを立ち上げます。
// コンテナ起動する
docker-compose up -d
// コンテナに入る
docker-compose exec clickhouse bash
// コンテナに入ったらクライアントに入る。
clickhouse-client
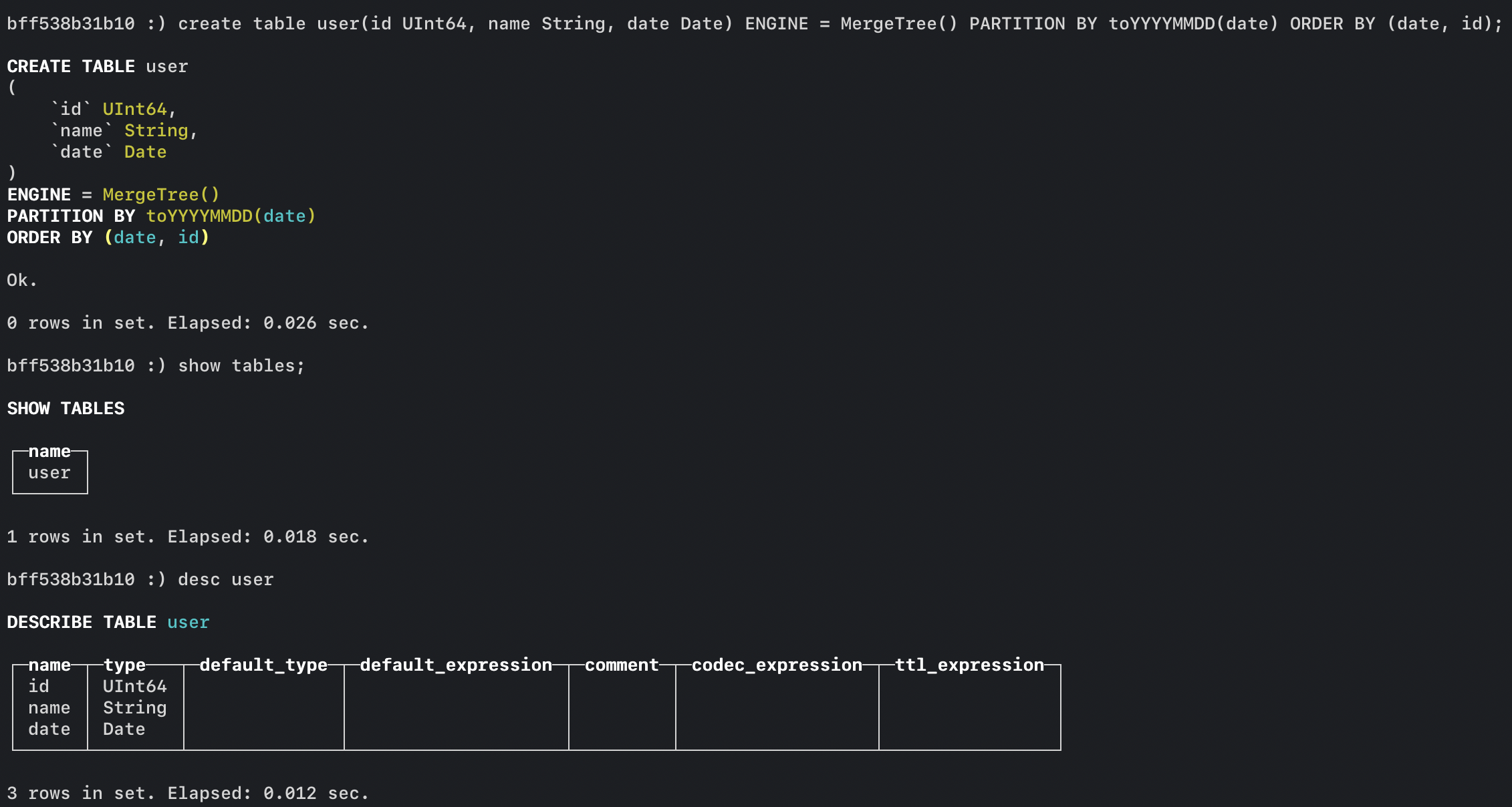
以下のようにクエリを叩けます。
マイグレーション
今回はこのライブラリを使用しました。
・golang-migrate
以下の3ファイル+1フォルダを作成します。
・docker-compose.yml
version: "3.7"
services:
ch-migrate:
build:
context: ./
dockerfile: Dockerfile
container_name: "ch_migrate"
volumes:
- ./migrations:/src/migrations
- ./Makefile:/src/Makefile
tty: true
・Dockerfile
FROM golang:1.13-alpine
ENV VERSION v4.7.1
RUN apk add make vim --no-cache git
RUN go get -v -d github.com/golang-migrate/migrate/cli \
&& go get -v -d github.com/lib/pq
WORKDIR /go/src/github.com/golang-migrate/migrate
RUN git checkout ${VERSION} \
&& go build -tags 'clickhouse' -o ./bin/migrate ./cli
WORKDIR /src
・migrationsフォルダの作成
(ここに1ファイルずつマイグレーションのファイルが作成される。)
mkdir migrations
・Makefile
PATH := ./migrations/
HOST := clickhouse
PORT := 9000
DATABSE := default
DATABASE_URL := 'clickhouse://${HOST}:${PORT}/${DATABSE}'
EXT := sql
MIGRATE := /go/src/github.com/golang-migrate/migrate/bin/migrate
# コマンド
## make create NAME=create_table_name
.PHONY: create
create:
${MIGRATE} create -ext ${EXT} -dir ${PATH} ${NAME}
.PHONY: up
up:
${MIGRATE} -database ${DATABASE_URL} -path ${PATH} up
.PHONY: down
down:
${MIGRATE} -database ${DATABASE_URL} -path ${PATH} down
コンテナの中に入ります。
docker-compose up -d
docker-compose exec ch-migrate ash
以下のコマンドでマイグレーションファイルの作成をします。
// マイグレーションファイルの作成
make create NAME=create_table_name
作成されたファイルにクエリを書きます。
vim ./migrations/2019000000000_create_table_name.up.sql
// 以下を書く
create table user(id UInt64, name String, date Date) ENGINE = MergeTree() PARTITION BY toYYYYMMDD(date) ORDER BY (date, id);
vim ./migrations/2019000000000_create_table_name.down.sql
// 以下を書く
drop table user;
ここまでできれば、マイグレートが行えます。
Clickhouseクライアントと共に確認してみてください。
// マイグレート
make up
// ロールバック
make down

goでclickohuseへインサート
clickhouse-goを使用します。
READMEのサンプルとほぼ同じです。
クエリビルダーを使うのがオススメですが、以下では使わずに実装してます。
package main
import (
"database/sql"
"fmt"
"log"
"time"
"github.com/ClickHouse/clickhouse-go"
)
var ConnectionCH *sql.DB
func setDriver() error {
var err error
databseURL := fmt.Sprintf("tcp://%s:%s", "127.0.0.1", "9000")
ConnectionCH, err = sql.Open("clickhouse", databseURL)
if err != nil {
return err
}
if err := ConnectionCH.Ping(); err != nil {
if exception, ok := err.(*clickhouse.Exception); ok {
fmt.Printf("[%d] %s \n%s\n", exception.Code, exception.Message, exception.StackTrace)
} else {
return err
}
return err
}
return nil
}
func repositoryInsertUser() error {
var (
tx, _ = ConnectionCH.Begin()
stmt, _ = tx.Prepare("INSERT INTO user (id, name ,date) VALUES (?, ?, ?)")
)
defer stmt.Close()
for i := 0; i < 100; i++ {
if _, err := stmt.Exec(
i,
"name",
time.Now(),
); err != nil {
return err
}
}
if err := tx.Commit(); err != nil {
return err
}
return nil
}
func main() {
if err := setDriver(); err != nil {
log.Fatal(err)
}
if err := repositoryInsertUser(); err != nil {
log.Fatal(err)
}
}
上のでは、Prepareでクエリを先にDBに保存し、トランザクションによって、データを一括でインサートすることによって高速にインサートできます。
もしトランザクションやPrepareを使っていなかったら、5倍ぐらいの時間がかかるはずです。
これで、clickhouseへインサートできるようになりました。
githubのREADMEにより詳しく書いてあります。
amazon linux2で動かす
・インストール
sudo su -
sudo yum install -y curl epel-release
curl -s https://packagecloud.io/install/repositories/altinity/clickhouse/script.rpm.sh |
sudo os=centos dist=7 bash
// インストールする
sudo yum install -y clickhouse-server clickhouse-client
// clickhouseサーバーを起動する
sudo /etc/init.d/clickhouse-server restart
・クライアントの起動
// clickhouseクライアント起動する
clickhouse-client
// デバック用 ログが出る
clickhouse-server --config-file=/etc/clickhouse-server/config.xml
同時接続に耐えられるか
goで並列にクエリ実行して、検証したら普通に問題ないぐらい耐えました。
細かいところは今度載せます。
まとめ
・「圧縮により容量削減」と「高速化」ができるので、コスト削減できる。
・集計サーバを構築中で、コスパが重要の時はおすすめ。
・古いシステムで、RDB上に集計の役割を持たせている場合、その部分だけClickHouseに移動するとかも良い。
・clikchouseクライアントアプリとか誰か作って欲しい。