はじめに
階層的クラスタリングの結果として得られるデンドログラムの並べ替えアルゴリズムを調べていたところ、SciPyやMATLABで実装されているOptimal Leaf Orderingという手法を知りました。
しかしこの手法の日本語での解説ページが見当たらなかったため、元論文を参考にアルゴリズムの解説とC++での実装をまとめたいと思います。
前置き
そもそも階層的クラスタリングとは?
まずクラスタリングとはなにか?について簡単に説明したいと思います。詳しく知りたい方は他の詳細な解説ページの参照をお勧めします。
参考ページ例:
クラスタリングとは与えられたデータ間の距離(類似度)によってクラスタ(グループ)に分ける手法のことです。
クラスタリングには大きく分けて階層的クラスタリングと非階層的クラスタリングの2つの手法がありますが、今回は階層的クラスタリングについてのアルゴリズムとなります。
デンドログラム(樹形図)
階層的クラスタリングによって得られたデータ間の関係を、線で結ぶことによって得られる図をデンドログラム(樹形図)と言います。

引用:https://docs.scipy.org/doc/scipy-1.7.1/reference/reference/generated/scipy.cluster.hierarchy.dendrogram.html
デンドログラムの問題点
このデンドログラムを書くにあたって問題になることがあります。それは
データ同士の配置をどうするか?
という点です。次の2つのデンドログラムを例にします。

引用:Bar-Joseph Z, Gifford DK, Jaakkola TS. Fast optimal leaf ordering for hierarchical clustering. Bioinformatics. 2001; 17: S22—S29.
2つのデンドログラムは赤丸で囲まれた部分(データ3とデータ4,5の結合クラスタ)を左右反転させたものです。
両者を比較すると、数字の並び順は異なりますがクラスタ同士の構造、つまりどのクラスタ同士が結合しているかという部分は全く同じになっています。
このようにデンドログラムのデータ配置順は一意に決まりません。
構造は同じでも並び順が違うだけで視覚的に得られる情報が異なる場合もあるようです。
この図はデータ数が5つだけなので並び順はそれほど重要では無いですが、もっと多くのデータ数の場合は並び順が重要になりそうだ、ということは想像できると思います。
最適な順番を得るアルゴリズム
そのデンドログラム配置問題を解決するための、より良い配置順を得るアルゴリズムというのはいくつかあるようです。
その中でもOptimal Leaf Orderingと呼ばれるアルゴリズムがいくつかのライブラリやソフトウェアで用いられているみたいです。例えば、様々なページで階層的クラスリングの実装に用いられているSciPyでもこのアルゴリズムは存在しています(scipy.cluster.hierarchy.optimal_leaf_ordering)。
じゃあSciPyを使えよ、という話なのですがアルゴリズムの勉強も兼ねてC++で実装したいと思います。
Optimal Leaf Ordering
理論式
理論式へ移る前に注意点として、このページでは論文の中身を全て解説するわけではなく、あくまでもアルゴリズムの実装に必要なところのみの解説となります。その他について知りたいことがあれば元論文をご覧ください。それでは、理論式を見ていきたいと思います。
D^\varphi(T) = \sum_{i=1}^{n-1} S\!\left( z_{\varphi_i},\, z_{\varphi_{i+1}} \right)
ここで
n=データ数、S=データ間の類似度行列、z=デンドログラムに含まれるデータ、
Φ=デンドログラムの可能な順序付け空間、φ∈Φ、T=あるデンドログラムのパターン
となっています。
この式において、$D^φ(T)$を最大化する$φ$見つけることがゴールです。
はい、何を言っているかさっぱり分かりませんね。少なくとも私はこれだけを見せられても何のことだか分かりません。
ですが私なりに解釈してみると、$ \sum_{i=1}^{n-1}S(z_{\varphi_i}, z_{\varphi_{i+1}})$の最大化、つまり
隣り合うデータ間の類似度の合計値が最も大きいとき、その並び順が最適なデンドログラムの並び順である
というところでしょうか。
アルゴリズム
やっと本題となります。こちらが実装目標のアルゴリズムです。

図1 アルゴリズム
まず用語解説です。
本アルゴリズムはデンドログラムを木構造に見たてて説明されています。デンドログラムは木構造そのものだからですね。木構造については様々なページで説明されています。
例:
以降デンドログラムはルート(根)と記載します。
$v$はルートに含まれるノードを表しており(ルートも$v$に含まれます)、$|v|$はノードに含まれるリーフ(葉)の数を表します。
また、$v_l, v_r$はそれぞれ$v$を構成する左部分木、右部分木を表します。
図2として木構造の例を引用します。
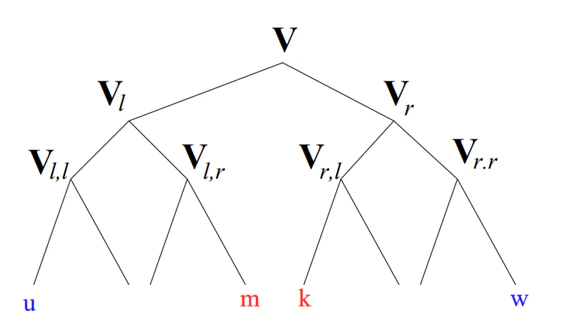
図2 木構造
各ノード$v$について、$v$をルートとする部分木の最適な順序付けのコストを求めて
$M(v)$ と表記します。
本アルゴリズムでは、$u∈v_l, w∈v_r$のすべてのリーフのペアにおける$M(v, u, w)$を計算します。これは$v$の左端のリーフが$u$で、右端のリーフが$w$の場合における、$v$の最適な順番を表しています。
何言ってんの?って感じがしますが、あるノードが持つ全てのリーフの中から最適な左端($u$)と右端($w$)のリーフを選ぼうとしているわけです。何をもって最適なのか、は次のように定義されています。
あるリーフ$m∈v_l, k∈v_r$において、$u$が一方、$w$がもう一方にあり、$m,k$が中央にある場合(図2参照)の最適な$v$の順序は
M(v_l, u, m) + M(v_r, w, k) + S(m, k)
となります。$M(v,u,w)$を求めるには全ての$m,k$のペアを試し、結果の値の内で最も高いスコアのものを採用します。これは次式で表すことができます。
M(v, u, w) =
\max_{\substack{m \in v_{l,r}\\ k \in v_{r,l}}}
\Bigl( M(v_l, u, m) + M(v_r, w, k) + S(m, k) \Bigr)
$v_{l,r}$は$v_l$の右部分木、$v_{r,l}$は$v_r$の左部分木を表します。
つまりあるノード$v$のスコアを求めるには$v$を構成する$v_l, v_r$の中から、最もスコアが高くなるような$u,m,k,w$を選べばよいわけですね。
また$M(v)$を求めるには$M(v_{l})$が必要になり、$M(v_{l})$を求めるには$M(v_{l,l})$が必要になり…となるため図1では再帰的に処理をしています。
そうやって全てのリーフペアのスコアを計算し終えたら、ルートの中から最もスコアが高い$u,m,k,w$を選び、これまた再帰的に答えを辿っていきます。これは動的計画法の考え方と同じですね(多分)。
補足1
これでアルゴリズムの説明は終了ですが、間違いやすそうなポイントとして$u,m,k,w$は全て、ノードではなくリーフです。
このアルゴリズムは、あくまでもリーフを最適な順番に並べる手法である、ということを頭に入れておかないと理解できなくなります(なった)。
というのもリーフを並べることができれば、ノードの位置は自動的に決まるのでノードの並び順を考慮する必要はありません。
実装
それではアルゴリズムを実装したいと思いますが、ここでとても大きな問題点があります。それはこのアルゴリズムは、既にクラスタリングが終了していることを前提としており、その結果を並べ替えるための手法です。つまり別途クラスタリングを行う必要があります。
え、じゃあどうやってC++でクラスタリングするの…
一応、C++のライブラリやpythonでクラスタリングした結果を使うこともできますが、せっかくなのでクラスタリングの方もC++で実装したいと思います。ただし、これは本ページの本筋ではないので深く解説をせずにさらっと行きます。
クラスタリングのソースコード
というわけで、まずはクラスタリングのソースコードになります。
#include <iostream>
#include <vector>
#include <fstream>
#include <cmath>
#include <cfloat>
using matrix = std::vector<std::vector<double>>;
using matrix_i = std::vector<std::vector<int>>;
struct Cluster {
int root;
int left_node;
int right_node;
int isleaf;
};
matrix load_data(std::string filename, int& data_n, int& dimension) {
std::ifstream ifs(filename);
/*
if (!ifs) {
std::cerr << "no such as file\n";
exit(0);
}
*/
ifs >> data_n;
ifs >> dimension;
matrix data(data_n, std::vector<double>(dimension));
for (int i = 0; i < data_n; i++) {
for (int j = 0; j < dimension; j++) {
ifs >> data[i][j];
}
}
ifs.close();
return data;
}
// ------------(1)------------
matrix euclidean(const matrix& data, int data_n, int dimension) {
matrix ret(data_n, std::vector<double>(data_n));
for (int i = 0; i < data_n; i++) {
for (int j = 0; j < data_n; j++) {
ret[i][j] = 0;
if (i == j) ret[i][j] = -1.0;
else {
for (int k = 0; k < dimension; k++) {
ret[i][j] += (data[i][k] - data[j][k]) * (data[i][k] - data[j][k]);
}
//ret[i][j] = sqrt(ret[i][j]);
}
}
}
return ret;
}
// ------------(2)------------
std::vector<Cluster> ward_method(matrix& dist_matrix, int data_n, int max_cluster) {
std::vector<Cluster> cluster(max_cluster);
for (int i = 0; i < data_n; i++) {
cluster[i].isleaf = 1;
cluster[i].left_node = -1;
cluster[i].right_node = -1;
cluster[i].root = -1;
}
for (int i = data_n; i < max_cluster; i++) {
cluster[i].isleaf = 0;
cluster[i].left_node = -1;
cluster[i].right_node = -1;
cluster[i].root = -1;
}
std::vector<int> is_merged(max_cluster, 0);
std::vector<int> cluster_mass(max_cluster, 0);
for (int i = 0; i < data_n; i++)
cluster_mass[i] = 1;
for (int n = data_n; n < max_cluster; n++) {
double min_dist = DBL_MAX;
int clus1 = -1, clus2 = -1;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (i == j) continue;
// ------------(3)------------
if (dist_matrix[i][j] < min_dist && !is_merged[i] && !is_merged[j]) {
min_dist = dist_matrix[i][j];
clus1 = i;
clus2 = j;
}
}
}
cluster[n].left_node = clus1;
cluster[n].right_node = clus2;
cluster[clus1].root = n;
cluster[clus2].root = n;
cluster_mass[n] = cluster_mass[clus1] + cluster_mass[clus2];
is_merged[clus1] = 1;
is_merged[clus2] = 1;
for (int i = 0; i < n; i++) {
if (is_merged[i]) continue;
double nr = cluster_mass[i];
double nz = cluster_mass[n] + nr;
double clus1_mass = cluster_mass[clus1];
double clus2_mass = cluster_mass[clus2];
dist_matrix[i][n] =
dist_matrix[i][clus1] * (clus1_mass + nr) +
dist_matrix[i][clus2] * (clus2_mass + nr) -
dist_matrix[clus1][clus2] * nr;
dist_matrix[i][n] /= nz;
dist_matrix[n][i] = dist_matrix[i][n];
}
}
return cluster;
}
int main() {
int data_n, dimension;
// ------------(4)------------
matrix data = load_data("iris.txt", data_n, dimension);
matrix dist_matrix = euclidean(data, data_n, dimension);
int max_cluster = data_n * 2 - 1;
dist_matrix.resize(max_cluster);
for (int i = 0; i < max_cluster; i++)
dist_matrix[i].resize(max_cluster);
std::vector<Cluster> cluster = ward_method(dist_matrix, data_n, max_cluster);
}
重要な部分(1)
データ間の距離計算にはクラスタリングで一般に用いられるユークリッド距離を用います。
コメントアウトしてある
//ret[i][j] = sqrt(ret[i][j]);
は、本来ユークリッド距離はベクトルの差のノルムで求めますが、後述するward法では距離を2乗した値を使用します。
ですのでわざわざ平方根を計算した値を、さらに2乗するのは非効率なので距離計算の時点で平方根計算は行いません。平方根を計算しなくても距離の大小関係は変わりません。
例えば、最小距離値(クラスタ結合距離)が必要な場合は、sqrt(min_dist)で求めることができます。
重要な部分(2)
上述したようにクラスタ結合距離の計算にはward法を用います。結合距離の計算手法は代表的なものに最短距離法、最長距離法、群平均法、ward法などがありますが、中でもward法は直感的によい結果を得やすいことが経験的に知られています。
重要な部分(3)
ward法の結合クラスタ探索において
dist_matrix[i][j] < min_dist
と書いていますが、これは距離が最も小さい(近い)クラスタ同士を探しています。
論文中では類似度(similarity)という言葉を用いて、類似度を最大化する、という表現が使われていますが、
類似度が大きい=距離が近い(小さい)
であり、語感的には真逆ですが意味は同じです。ややこしいのでご注意ください。
重要な部分(4)
使うデータはとりあえずirisデータセットです。scikit-learnのsklearn.datasets.load_irisデータそのままです。load_data関数は本当に適当なので必要に応じて書き換えください。
Optimal Leaf Ordeirngのソースコード
ここからが本題のソースコードです。
struct Table{
int left_leaf, right_leaf;
double score;
};
using OptimTable = std::vector<std::vector<std::vector<Table>>>;
matrix_i set_subleaf_list(const std::vector<Cluster>& cluster, int data_n, int max_cluster) {
matrix_i subleaf_list(max_cluster);
for (int i = 0; i < data_n; i++) {
subleaf_list[i].push_back(i);
}
for (int i = data_n; i < max_cluster; i++) {
int sub_size = subleaf_list[cluster[i].left_node].size();
for (int j = 0; j < sub_size; j++)
subleaf_list[i].push_back(subleaf_list[cluster[i].left_node][j]);
sub_size = subleaf_list[cluster[i].right_node].size();
for (int j = 0; j < sub_size; j++)
subleaf_list[i].push_back(subleaf_list[cluster[i].right_node][j]);
}
return subleaf_list;
}
int is_subleaf(const matrix_i& subleaf_list, int clus, int leaf) {
for (int i = 0; i < subleaf_list[clus].size(); i++)
if (subleaf_list[clus][i] == leaf) return 1;
return 0;
}
アルゴリズムの実行のためには、あるノードに含まれる全てのリーフの情報が必要なのでそれを求めるset_subleaf_list関数と、
あるリーフがあるクラスタに含まれているかを調べるis_subleaf関数です。
void register_table(OptimTable& table, int clus, int u, int w, int m, int k, double score) {
table[clus][u][w].score = score;
table[clus][u][w].left_leaf = m;
table[clus][u][w].right_leaf = k;
table[clus][w][u].score = score;
table[clus][w][u].left_leaf = k;
table[clus][w][u].right_leaf = m;
}
std::pair<double, std::pair<int, int>> get_optim(OptimTable& table, int clus, const std::vector<Cluster>& cluster, const matrix_i& subleaf_list, const matrix& dist_matrix,
int leaf_u, int leaf_w, int m_index, int k_index, int u_isleaf, int w_isleaf) {
double min_score = DBL_MAX;
int optim_m = 0, optim_k = 0;
for (int m = 0; m < subleaf_list[m_index].size(); m++) {
int leaf_m = subleaf_list[m_index][m];
double M_right;
if (u_isleaf) M_right = 0.0;
else M_right = table[clus][leaf_u][leaf_m].score;
for (int k = 0; k < subleaf_list[k_index].size(); k++) {
int leaf_k = subleaf_list[k_index][k];
double M_left;
if (w_isleaf) M_left = 0.0;
else M_left = table[clus][leaf_w][leaf_k].score;
double score = M_right + M_left + dist_matrix[leaf_m][leaf_k];
if (score < min_score) {
min_score = score;
optim_m = leaf_m;
optim_k = leaf_k;
}
}
}
return { min_score, { optim_m, optim_k } };
}
void optOrdering(OptimTable& table, int clus, const std::vector<Cluster>& cluster, const matrix& dist_matrix, const matrix_i& subleaf_list) {
//(1)
if (cluster[clus].isleaf) {
table[clus][0][0] = { clus, clus, 0.0 };
return;
}
else {
//(2)
int left_node = cluster[clus].left_node;
int right_node = cluster[clus].right_node;
int left_right_node = cluster[left_node].right_node;
int right_left_node = cluster[right_node].left_node;
int left_left_node = cluster[left_node].left_node;
int right_right_node = cluster[right_node].right_node;
if (left_right_node == -1) left_right_node = left_node;
if (right_left_node == -1) right_left_node = right_node;
if (left_left_node == -1) left_left_node = left_node;
if (right_right_node == -1) right_right_node = right_node;
optOrdering(table, left_node, cluster, dist_matrix, subleaf_list);
optOrdering(table, right_node, cluster, dist_matrix, subleaf_list);
//(3)
for (int u = 0; u < subleaf_list[left_left_node].size(); u++) {
int leaf_u = subleaf_list[left_left_node][u];
for (int w = 0; w < subleaf_list[right_left_node].size(); w++) {
int leaf_w = subleaf_list[right_left_node][w];
auto res = get_optim(table, clus, cluster, subleaf_list, dist_matrix,
leaf_u, leaf_w,
left_right_node, right_right_node,
cluster[left_left_node].isleaf,
cluster[right_left_node].isleaf);
double min_score = res.first;
int optim_m = res.second.first;
int optim_k = res.second.second;
register_table(table, clus, leaf_u, leaf_w, optim_m, optim_k, min_score);
}
for (int w = 0; w < subleaf_list[right_right_node].size(); w++) {
int leaf_w = subleaf_list[right_right_node][w];
auto res = get_optim(table, clus, cluster, subleaf_list, dist_matrix,
leaf_u, leaf_w,
left_right_node, right_left_node,
cluster[left_left_node].isleaf,
cluster[right_right_node].isleaf);
double min_score = res.first;
int optim_m = res.second.first;
int optim_k = res.second.second;
register_table(table, clus, leaf_u, leaf_w, optim_m, optim_k, min_score);
}
}
for (int u = 0; u < subleaf_list[left_right_node].size(); u++) {
int leaf_u = subleaf_list[left_right_node][u];
for (int w = 0; w < subleaf_list[right_left_node].size(); w++) {
int leaf_w = subleaf_list[right_left_node][w];
auto res = get_optim(table, clus, cluster, subleaf_list, dist_matrix,
leaf_u, leaf_w,
left_left_node, right_right_node,
cluster[left_right_node].isleaf,
cluster[right_left_node].isleaf);
double min_score = res.first;
int optim_m = res.second.first;
int optim_k = res.second.second;
register_table(table, clus, leaf_u, leaf_w, optim_m, optim_k, min_score);
}
for (int w = 0; w < subleaf_list[right_right_node].size(); w++) {
int leaf_w = subleaf_list[right_right_node][w];
auto res = get_optim(table, clus, cluster, subleaf_list, dist_matrix,
leaf_u, leaf_w,
left_left_node, right_left_node,
cluster[left_left_node].isleaf,
cluster[right_right_node].isleaf);
double min_score = res.first;
int optim_m = res.second.first;
int optim_k = res.second.second;
register_table(table, clus, leaf_u, leaf_w, optim_m, optim_k, min_score);
}
}
}
}
register_table関数とget_optim関数はoptOrdering関数のヘルパーです。
(1)
もしclusがリーフだった場合はスコア0を返します。
(2)
left_nodeなどはclusを構成するノードのインデックスです。図1ではleft_left_nodeやright_right_nodeなどの記載はありませんが、左部分木や右部分木の構成可能なペアを探索するためには必要な情報です。
と言うのも図1通りに
for (u in left_node)
for (w in right_node)
for (m in left_right_node)
for (k in right_left_node)
~~
のようにループを回すとuがleft_right_node内に含まれている場合や、wがright_left_nodeに含まれている場合まで探索することになってしまいます。
そのようなときのm,kが最適なペアとして選ばれてしまうとデンドログラムの構造を崩してしまい、最適経路逆探索の時にうまくいかなくなってしまいます(なった)。
それを回避するために左部分木と右部分木を、さらに左右に分割し、片方を探索する場合はもう片方を候補として探索するという風に処理します。
std::vector<int> get_optim_order(const OptimTable& table, const std::vector<Cluster>& cluster, const matrix_i& subleaf_list, int clus, int u, int w) {
if (cluster[clus].isleaf) {
return { clus };
}
int vl = -1, vr = -1, m, k;
m = table[clus][u][w].left_leaf;
k = table[clus][u][w].right_leaf;
if (is_subleaf(subleaf_list, cluster[clus].left_node, m) &&
is_subleaf(subleaf_list, cluster[clus].right_node, k)) {
vl = cluster[clus].left_node;
vr = cluster[clus].right_node;
}
else if (is_subleaf(subleaf_list, cluster[clus].left_node, k) &&
is_subleaf(subleaf_list, cluster[clus].right_node, m)) {
vl = cluster[clus].right_node;
vr = cluster[clus].left_node;
}
/*
else {
}
*/
auto left_order = get_optim_order(table, cluster, subleaf_list, vl, u, m);
auto right_order = get_optim_order(table, cluster, subleaf_list, vr, k, w);
left_order.insert(left_order.end(), right_order.begin(), right_order.end());
return left_order;
}
std::vector<int> optimal_leaf_ordering(const std::vector<Cluster>& cluster, const matrix& dist_matrix, const matrix_i& subleaf_list, int data_n, int max_cluster) {
OptimTable optim_table(max_cluster);
for (int i = 0; i < data_n; i++) {
optim_table[i].resize(1);
optim_table[i][0].resize(1);
}
for (int i = data_n; i < max_cluster; i++) {
optim_table[i].resize(data_n);
for (int j = 0; j < data_n; j++) {
optim_table[i][j].resize(data_n, { -1,-1,0 });
}
}
int root = max_cluster - 1;
optOrdering(optim_table, root, cluster, dist_matrix, subleaf_list);
double optim_socre = DBL_MAX;
int optim_u = -1, optim_w = -1;
for (int u = 0; u < subleaf_list[cluster[root].left_node].size(); u++) {
int leaf_u = subleaf_list[cluster[root].left_node][u];
for (int w = 0; w < subleaf_list[cluster[root].right_node].size(); w++) {
int leaf_w = subleaf_list[cluster[root].right_node][w];
if (optim_table[root][leaf_u][leaf_w].left_leaf != -1 &&
optim_table[root][leaf_u][leaf_w].right_leaf != -1) {
if (optim_table[root][leaf_u][leaf_w].score < optim_socre) {
optim_socre = optim_table[root][leaf_u][leaf_w].score;
optim_u = leaf_u;
optim_w = leaf_w;
}
}
}
}
return get_optim_order(optim_table, cluster, subleaf_list, root, optim_u, optim_w);
}
get_optim_orderでルートの最適なu,wを受け取り、それを元に部分木を構成するノードを探索していきます。
vl,vrの選択ですが、optOrdeingではvl,vrを固定せずにどちらも左右の部分木をとりうる、という体で探索しています(そもそもcluster[].left_nodeとcluster[].right_nodeはクラスタリング時に適当に決めているだけです)。
なのでm,kがleft_nodeに含まれているのか、right_nodeに含まれているのかをチェックしてから正しい方向にget_optim_orderを再帰します。
最終的な結果はサイズdata_nのvectorとして返し、配列の順番通りにデータを並べるとアルゴリズムによって得られた最適な並びのデンドログラムになります(なるはず)。
最終的なソースコード
#include <iostream>
#include <vector>
#include <fstream>
#include <cmath>
#include <cfloat>
using matrix = std::vector<std::vector<double>>;
using matrix_i = std::vector<std::vector<int>>;
struct Cluster {
int root;
int left_node;
int right_node;
int isleaf;
};
matrix load_data(std::string filename, int& data_n, int& dimension) {
std::ifstream ifs(filename);
/*
if (!ifs) {
std::cerr << "no such as file\n";
exit(0);
}
*/
ifs >> data_n;
ifs >> dimension;
matrix data(data_n, std::vector<double>(dimension));
for (int i = 0; i < data_n; i++) {
for (int j = 0; j < dimension; j++) {
ifs >> data[i][j];
}
}
ifs.close();
return data;
}
matrix euclidean(const matrix& data, int data_n, int dimension) {
matrix ret(data_n, std::vector<double>(data_n));
for (int i = 0; i < data_n; i++) {
for (int j = 0; j < data_n; j++) {
ret[i][j] = 0;
if (i == j) ret[i][j] = -1.0;
else {
for (int k = 0; k < dimension; k++) {
ret[i][j] += (data[i][k] - data[j][k]) * (data[i][k] - data[j][k]);
}
//ret[i][j] = sqrt(ret[i][j]);
}
}
}
return ret;
}
std::vector<Cluster> ward_method(matrix& dist_matrix, int data_n, int max_cluster) {
std::vector<Cluster> cluster(max_cluster);
for (int i = 0; i < data_n; i++) {
cluster[i].isleaf = 1;
cluster[i].left_node = -1;
cluster[i].right_node = -1;
cluster[i].root = -1;
}
for (int i = data_n; i < max_cluster; i++) {
cluster[i].isleaf = 0;
cluster[i].left_node = -1;
cluster[i].right_node = -1;
cluster[i].root = -1;
}
std::vector<int> is_merged(max_cluster, 0);
std::vector<int> cluster_mass(max_cluster, 0);
for (int i = 0; i < data_n; i++)
cluster_mass[i] = 1;
for (int n = data_n; n < max_cluster; n++) {
double min_dist = DBL_MAX;
int clus1 = -1, clus2 = -1;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (i == j) continue;
if (dist_matrix[i][j] < min_dist && !is_merged[i] && !is_merged[j]) {
min_dist = dist_matrix[i][j];
clus1 = i;
clus2 = j;
}
}
}
cluster[n].left_node = clus1;
cluster[n].right_node = clus2;
cluster[clus1].root = n;
cluster[clus2].root = n;
cluster_mass[n] = cluster_mass[clus1] + cluster_mass[clus2];
is_merged[clus1] = 1;
is_merged[clus2] = 1;
for (int i = 0; i < n; i++) {
if (is_merged[i]) continue;
double nr = cluster_mass[i];
double nz = cluster_mass[n] + nr;
double clus1_mass = cluster_mass[clus1];
double clus2_mass = cluster_mass[clus2];
dist_matrix[i][n] =
dist_matrix[i][clus1] * (clus1_mass + nr) +
dist_matrix[i][clus2] * (clus2_mass + nr) -
dist_matrix[clus1][clus2] * nr;
dist_matrix[i][n] /= nz;
dist_matrix[n][i] = dist_matrix[i][n];
}
}
return cluster;
}
matrix_i set_subleaf_list(const std::vector<Cluster>& cluster, int data_n, int max_cluster) {
matrix_i subleaf_list(max_cluster);
for (int i = 0; i < data_n; i++) {
subleaf_list[i].push_back(i);
}
for (int i = data_n; i < max_cluster; i++) {
int sub_size = subleaf_list[cluster[i].left_node].size();
for (int j = 0; j < sub_size; j++)
subleaf_list[i].push_back(subleaf_list[cluster[i].left_node][j]);
sub_size = subleaf_list[cluster[i].right_node].size();
for (int j = 0; j < sub_size; j++)
subleaf_list[i].push_back(subleaf_list[cluster[i].right_node][j]);
}
return subleaf_list;
}
struct Table{
int left_leaf, right_leaf;
double score;
};
using OptimTable = std::vector<std::vector<std::vector<Table>>>;
int is_subleaf(const matrix_i& subleaf_list, int clus, int leaf) {
for (int i = 0; i < subleaf_list[clus].size(); i++)
if (subleaf_list[clus][i] == leaf) return 1;
return 0;
}
void register_table(OptimTable& table, int clus, int u, int w, int m, int k, double score) {
table[clus][u][w].score = score;
table[clus][u][w].left_leaf = m;
table[clus][u][w].right_leaf = k;
table[clus][w][u].score = score;
table[clus][w][u].left_leaf = k;
table[clus][w][u].right_leaf = m;
}
std::pair<double, std::pair<int, int>> get_optim(OptimTable& table, int clus, const std::vector<Cluster>& cluster, const matrix_i& subleaf_list, const matrix& dist_matrix,
int leaf_u, int leaf_w, int m_index, int k_index, int u_isleaf, int w_isleaf) {
double min_score = DBL_MAX;
int optim_m = 0, optim_k = 0;
for (int m = 0; m < subleaf_list[m_index].size(); m++) {
int leaf_m = subleaf_list[m_index][m];
double M_right;
if (u_isleaf) M_right = 0.0;
else M_right = table[clus][leaf_u][leaf_m].score;
for (int k = 0; k < subleaf_list[k_index].size(); k++) {
int leaf_k = subleaf_list[k_index][k];
double M_left;
if (w_isleaf) M_left = 0.0;
else M_left = table[clus][leaf_w][leaf_k].score;
double score = M_right + M_left + dist_matrix[leaf_m][leaf_k];
if (score < min_score) {
min_score = score;
optim_m = leaf_m;
optim_k = leaf_k;
}
}
}
return { min_score, { optim_m, optim_k } };
}
void optOrdering(OptimTable& table, int clus, const std::vector<Cluster>& cluster, const matrix& dist_matrix, const matrix_i& subleaf_list) {
if (cluster[clus].isleaf) {
table[clus][0][0] = { clus, clus, 0.0 };
return;
}
else {
int left_node = cluster[clus].left_node;
int right_node = cluster[clus].right_node;
int left_right_node = cluster[left_node].right_node;
int right_left_node = cluster[right_node].left_node;
int left_left_node = cluster[left_node].left_node;
int right_right_node = cluster[right_node].right_node;
if (left_right_node == -1) left_right_node = left_node;
if (right_left_node == -1) right_left_node = right_node;
if (left_left_node == -1) left_left_node = left_node;
if (right_right_node == -1) right_right_node = right_node;
optOrdering(table, left_node, cluster, dist_matrix, subleaf_list);
optOrdering(table, right_node, cluster, dist_matrix, subleaf_list);
for (int u = 0; u < subleaf_list[left_left_node].size(); u++) {
int leaf_u = subleaf_list[left_left_node][u];
for (int w = 0; w < subleaf_list[right_left_node].size(); w++) {
int leaf_w = subleaf_list[right_left_node][w];
auto res = get_optim(table, clus, cluster, subleaf_list, dist_matrix,
leaf_u, leaf_w,
left_right_node, right_right_node,
cluster[left_left_node].isleaf,
cluster[right_left_node].isleaf);
double min_score = res.first;
int optim_m = res.second.first;
int optim_k = res.second.second;
register_table(table, clus, leaf_u, leaf_w, optim_m, optim_k, min_score);
}
for (int w = 0; w < subleaf_list[right_right_node].size(); w++) {
int leaf_w = subleaf_list[right_right_node][w];
auto res = get_optim(table, clus, cluster, subleaf_list, dist_matrix,
leaf_u, leaf_w,
left_right_node, right_left_node,
cluster[left_left_node].isleaf,
cluster[right_right_node].isleaf);
double min_score = res.first;
int optim_m = res.second.first;
int optim_k = res.second.second;
register_table(table, clus, leaf_u, leaf_w, optim_m, optim_k, min_score);
}
}
for (int u = 0; u < subleaf_list[left_right_node].size(); u++) {
int leaf_u = subleaf_list[left_right_node][u];
for (int w = 0; w < subleaf_list[right_left_node].size(); w++) {
int leaf_w = subleaf_list[right_left_node][w];
auto res = get_optim(table, clus, cluster, subleaf_list, dist_matrix,
leaf_u, leaf_w,
left_left_node, right_right_node,
cluster[left_right_node].isleaf,
cluster[right_left_node].isleaf);
double min_score = res.first;
int optim_m = res.second.first;
int optim_k = res.second.second;
register_table(table, clus, leaf_u, leaf_w, optim_m, optim_k, min_score);
}
for (int w = 0; w < subleaf_list[right_right_node].size(); w++) {
int leaf_w = subleaf_list[right_right_node][w];
auto res = get_optim(table, clus, cluster, subleaf_list, dist_matrix,
leaf_u, leaf_w,
left_left_node, right_left_node,
cluster[left_left_node].isleaf,
cluster[right_right_node].isleaf);
double min_score = res.first;
int optim_m = res.second.first;
int optim_k = res.second.second;
register_table(table, clus, leaf_u, leaf_w, optim_m, optim_k, min_score);
}
}
}
}
std::vector<int> get_optim_order(const OptimTable& table, const std::vector<Cluster>& cluster, const matrix_i& subleaf_list, int clus, int u, int w) {
if (cluster[clus].isleaf) {
return { clus };
}
int vl = -1, vr = -1, m, k;
m = table[clus][u][w].left_leaf;
k = table[clus][u][w].right_leaf;
if (is_subleaf(subleaf_list, cluster[clus].left_node, m) &&
is_subleaf(subleaf_list, cluster[clus].right_node, k)) {
vl = cluster[clus].left_node;
vr = cluster[clus].right_node;
}
else if (is_subleaf(subleaf_list, cluster[clus].left_node, k) &&
is_subleaf(subleaf_list, cluster[clus].right_node, m)) {
vl = cluster[clus].right_node;
vr = cluster[clus].left_node;
}
/*
else {
}
*/
auto left_order = get_optim_order(table, cluster, subleaf_list, vl, u, m);
auto right_order = get_optim_order(table, cluster, subleaf_list, vr, k, w);
left_order.insert(left_order.end(), right_order.begin(), right_order.end());
return left_order;
}
std::vector<int> optimal_leaf_ordering(const std::vector<Cluster>& cluster, const matrix& dist_matrix, const matrix_i& subleaf_list, int data_n, int max_cluster) {
OptimTable optim_table(max_cluster);
for (int i = 0; i < data_n; i++) {
optim_table[i].resize(1);
optim_table[i][0].resize(1);
}
for (int i = data_n; i < max_cluster; i++) {
optim_table[i].resize(data_n);
for (int j = 0; j < data_n; j++) {
optim_table[i][j].resize(data_n, { -1,-1,0 });
}
}
int root = max_cluster - 1;
optOrdering(optim_table, root, cluster, dist_matrix, subleaf_list);
double optim_socre = DBL_MAX;
int optim_u = -1, optim_w = -1;
for (int u = 0; u < subleaf_list[cluster[root].left_node].size(); u++) {
int leaf_u = subleaf_list[cluster[root].left_node][u];
for (int w = 0; w < subleaf_list[cluster[root].right_node].size(); w++) {
int leaf_w = subleaf_list[cluster[root].right_node][w];
if (optim_table[root][leaf_u][leaf_w].left_leaf != -1 &&
optim_table[root][leaf_u][leaf_w].right_leaf != -1) {
if (optim_table[root][leaf_u][leaf_w].score < optim_socre) {
optim_socre = optim_table[root][leaf_u][leaf_w].score;
optim_u = leaf_u;
optim_w = leaf_w;
}
}
}
}
return get_optim_order(optim_table, cluster, subleaf_list, root, optim_u, optim_w);
}
int main() {
int data_n, dimension;
matrix data = load_data("iris.txt", data_n, dimension);
matrix dist_matrix = euclidean(data, data_n, dimension);
int max_cluster = data_n * 2 - 1;
dist_matrix.resize(max_cluster);
for (int i = 0; i < max_cluster; i++)
dist_matrix[i].resize(max_cluster);
std::vector<Cluster> cluster = ward_method(dist_matrix, data_n, max_cluster);
matrix_i subleaf_list = set_subleaf_list(cluster, data_n, max_cluster);
auto result = optimal_leaf_ordering(cluster, dist_matrix, subleaf_list, data_n, max_cluster);
for (int i = 0; i < result.size(); i++) {
std::cout << result[i] << std::endl;
}
}
アルゴリズの最適化
アルゴリズムの実装は無事終了しました。しかし薄々気づいてる方もいらっしゃると思いますがこのアルゴリズムには少し問題があります。それは計算コストが高いということです。
この点は論文中でも言及されており、同論文中ではオリジナルアルゴリズムの改良も紹介されています(すごい!)。
ですがオリジナルアルゴリズムの実装で力尽きてしまったので改良アルゴリズムには着手しません。
(いつか実装したいと思います)
実際に使ってみる
デンドログラム作成
せっかく実装してみたのでirisデータを使ってデンドログラムを作ってみたいと思います。
最適化アルゴリズムを適用しない場合とした場合で比較したいと思います。

最適化なし
最適化あり
これを見た人は、一体なにが変わっているんだ?と思っているかもしれません。私は思いました。
しかし、よく見てみると最適化ありの方が隣り合うクラスタの距離が近そうかも?
ヒートマップ作成
実は元論文では結果をデンドログラムではなくヒートマップで示していました。というわけでヒートマップでも比較してみます。
使用データは論文で言及されていた人工データを使います。原文では
「We generated 100 data points for each of the 1000 leaves.For each leaf we set 40 consecutive points to -1, and then flip them to 0 or 1 with low probability.The rest of the points were generated at random.」
となっています。これをソースコードに直すと次のようになるでしょうか。
#include <iostream>
#include <fstream>
#include <random>
int main() {
int leavs = 1000;
int dimension = 100;
double p_flip = 2.0 / 40.0; // 0.05
std::mt19937 gen(0);
std::uniform_real_distribution<double> urd(0.0, 1.0);
std::uniform_int_distribution<int> uid(0, 1);
std::uniform_int_distribution<int> sp(0, dimension - 40);
std::ofstream ofs("artificial_data.txt");
for (int i = 0; i < leavs; i++) {
std::vector<int> result(dimension);
for (int j = 0; j < dimension; j++) {
result[j] = uid(gen);
}
int start_point = sp(gen);
for (int j = start_point; j < start_point + 40; j++) {
double p = urd(gen);
if (p > p_flip) {
result[j] = -1;
}
}
for (int j = 0; j < dimension; j++) {
ofs << result[j];
ofs << '\t';
}
ofs << '\n';
}
ofs.close();
}
これで生成したデータを最適化アルゴリズムによって並べ替え、ヒートマップにします。

最適化なし

最適化あり
これははっきりと違いが分かりますね。ランダムに挿入した連続データの位置が、近いもの同士で隣接していることが分かります。右上が若干最適じゃない感がありますが、最適リーフ選択を変えればもっとよくなるかも?
結論
Scipyを使いましょう。
参考文献
Bar-Joseph Z, Gifford DK, Jaakkola TS. Fast optimal leaf ordering for hierarchical clustering. Bioinformatics. 2001; 17: S22—S29.
https://academic.oup.com/bioinformatics/article/17/suppl_1/S22/261423
https://docs.scipy.org/doc/scipy-1.7.1/reference/reference/generated/scipy.cluster.hierarchy.dendrogram.html
https://jp.mathworks.com/help/stats/optimalleaforder.html
https://www.bunkyo.ac.jp/~hotta/lab/courses/2014/2014hts/14hts-5note.pdf