T字形ER手法という言葉を知ったのはSQLアンチパターン 幻の26章「とりあえず削除フラグ」を見たときでした
削除も更新もしない ーー
「ほーん、そんなんあるんか」って感じでしたw
全部履歴テーブルみたいにすれば良いのかな?と勝手に思っていましたが、これわかってないとまずいなと思ったので本買って読んでみました
今回読んだ本
T字形ER データベース設計技法
どうやら通称「黒本」と呼ばれているらしく、現在は絶版らしいです(なぜかamazonに置いてあったw)
よくよく調べてみたら「黒本」が一番古いらしく、「論考」、「赤本」、「いざない」と新しい本が出ていました
前提が変わっているらしく、今から本買う人は一番新しい本買ったほうが良いかも?
T字形ER手法というのは古い呼び方らしく、現在はTM(Theory of Models)と呼ばれています
最新の情報が欲しい方は下記URLをチェック!
最近ではZoomを使った講演も行っているみたいです
佐藤正美の問わず語り 事業分析・データベース設計 Theory of models
さておき、今回黒本から学んだ内容を書いていこうと思います
(バージョンによる差異はあるようなのですが、実際に使う技術的な部分はあまり変更されていないようなのでさらっと知りたい人には十分だと思います)
※正しくは「TM」ですが、僕がまだTMをちゃんと理解していないため以降T字形ER手法と書かせてもらいます
※これから出てくる例は黒本を参考に一部自分好みに修正しています
#T字形ER手法とは
T字形ER手法は、現行のコード体系に準拠しながらビジネスを逆解析する手法のこと
つまり、ビジネスをデータ構造を使って表現しよう、という試みがT字形ER手法です
既にあるコード体系からモデリングを行うため、自分たちで勝手にIDやNoを追加してはいけません
#T字形ER手法の体系
T字形ER手法で使われる技法は下記のようになっています
5つの技法(基本技法)
- identifier
- resourceとevent
- 対照表
- 対応表
- サブセット
2つの例外(拡張技法)
- みなしエンティティ
- turbo-files
4つのルール(基本技法)
- resource : resource
- resource : event
- event : event
- 再帰(recursive)
番外編ルール(拡張技法)
- 1つのエンティティから派生する複数の対照表は統合できる
では、それぞれ説明していきます!
##identifier
identifierとは、「従業員番号」や「顧客コード」のようなもののことです
しかし、これは一意でなくても問題ありません
むしろ実際のビジネスを考えるとひとつのデータで一意となっているものって珍しい?
僕の経験上でも、複合キーのような形で一意になるものが意外と多い気がします
##entity
entityとは、identifierから「番号」や「コード」を取り除いた「従業員」や「顧客」のことです
identifierが無ければentityを生成することはできません
つまり、「顧客コード(identifier)」がなければ「顧客(entity)」は生成できません
ここがT字形ER手法の事実を元にモデリングを行う、という部分に繋がってきていますね!
##resourceとevent
entityをresourceとeventのどちらかに分類します
下記が分類のやり方です
- eventになるもの
①タイムスタンプを採取できること
それを行った日付があり、「それはいつ起こったの?」という質問ができるもの
②監査証跡が保管されている
端的に言うと、数量や金額のこと
帳票等が保管されているもの
- resourceになるもの
event以外のentity
簡単な見分け方として、後ろに「~する」を付けて成立すればevent、しなければresource
ただし、たまにresourceでも「~する」が成立する場合があるので気を付けて…
###表し方
eventは左から順に時系列順で並べ、resourceはeventの上、または下に書きます
こんな感じになります
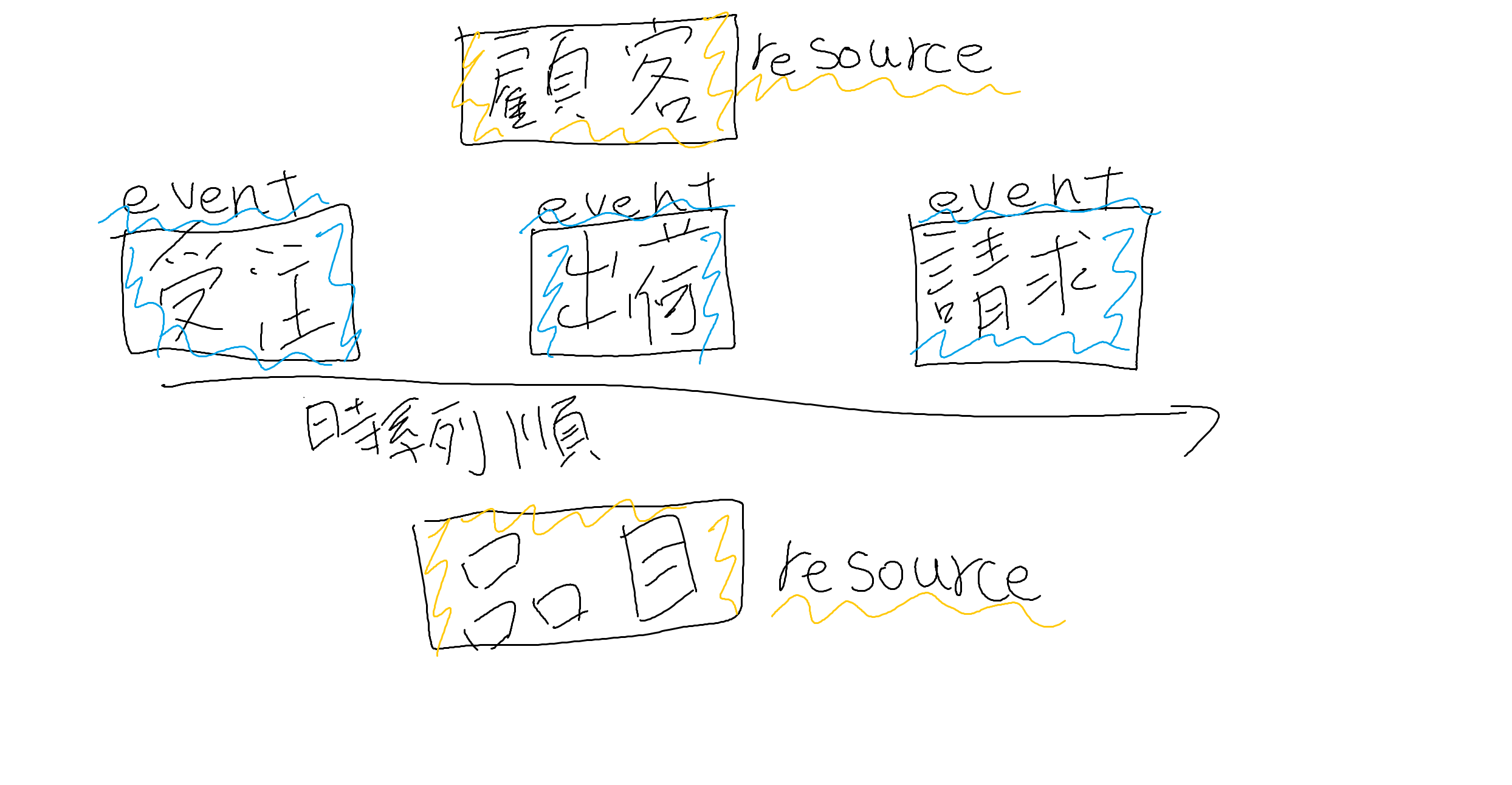
それぞれのentity配下にはidentifier(顧客番号、受注番号等)と、それに付随するアトリビュート(受注日、受注数等)が配置されます
このアトリビュートも現行から抽出したデータであり、勝手に生成してはいけません
「合計請求金額」のような計算結果は他のアトリビュートと区別して分けたいため、(D)を付けて表記します
こんな感じになります
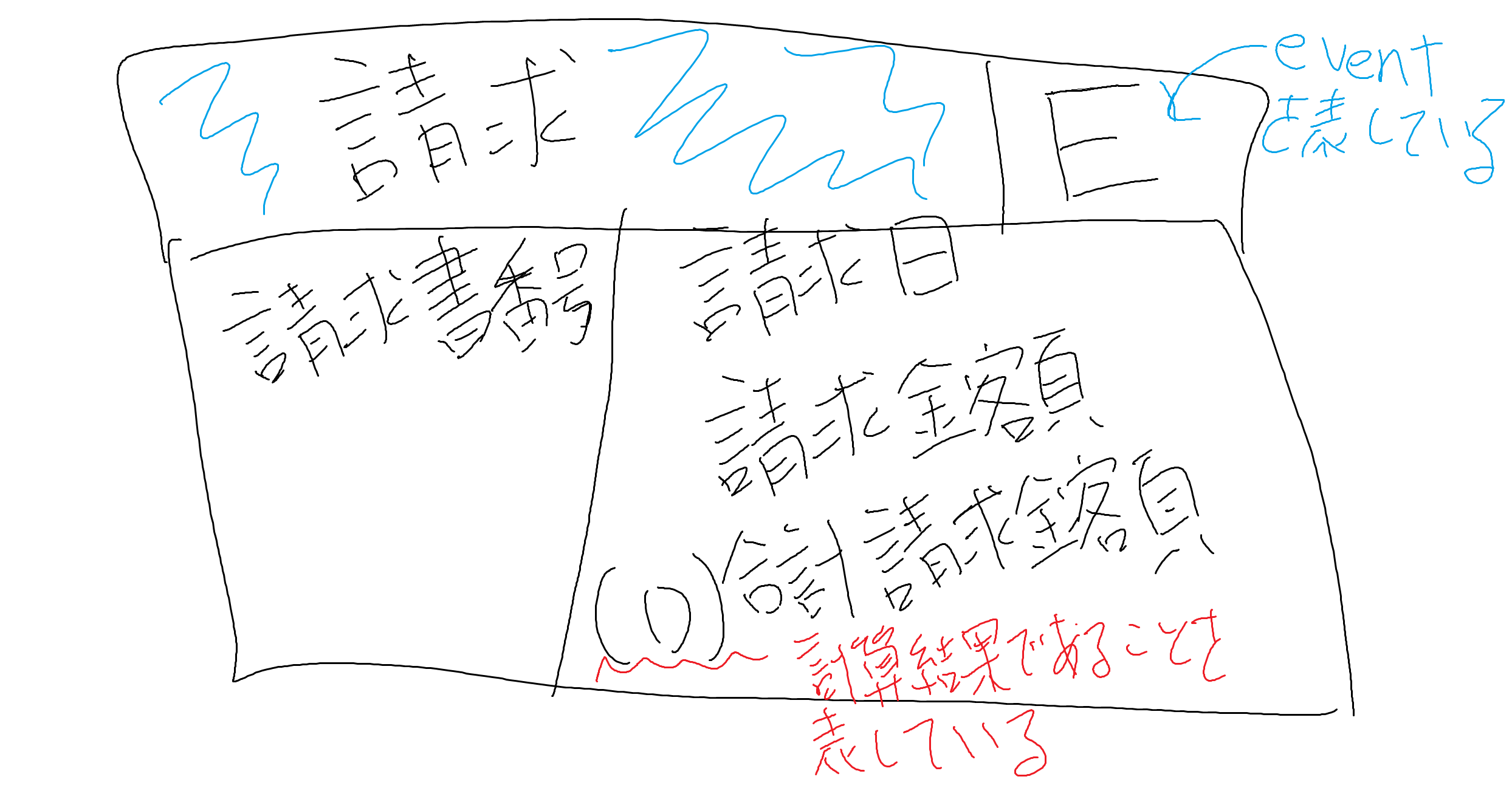
(手書きでやるもんじゃないってことを書いた後に気付いたw)
ここで重要なのはresourceです
resourceが2つ以上あるのであれば、eventを逆生成することができます
ビジネス上のものを一覧として並べたときに、eventが少なく、resourceが多ければ、resourceの組み合わせの分だけeventを新たに作れる可能性があり、ビジネスを広げられる可能性がある、ということになります
逆に、eventが多く、resourceが少ない場合はeventに制約されてしまっており、ビジネスを広げられる可能性は少ない、ということになります(断言している訳ではないですが…)
##4つのルール
eventとresourceの関係性には以下のパターンがあります
そのパターンによって、何を行うかが変わってきます
- resource : resource
この場合には後述する対照表を生成する
- resource : event
この場合にはeventにresourceの○○番号を挿入する
(R)と表記を加える
- event : event
この場合、二つのパターンがある
①1:1、1:多の場合であれば、時系列の遅いeventに直前のeventの○○番号を挿入する
②多:1、多:多の場合であれば、後述する対応表を生成する
- 再帰(recursive)
通常、entityは相手のentityが存在して関係性を持つが、たまに相手が自分自身になっているパターンがある
部品entityの相手は部品entityで、これを組み合わせることで…のような場合、再帰(となる
同じentity内だとしてもそれはレコード構造が同じだけであり、別々の部品であるのでこのようなことが起こる(これこそがレコードが存在している意味!)
##対照表
resource : resource のパターンの時に生成する
例えば、従業員と部門というresourceがあるとする
この間に、従業員・部門対照表を生成する
こんな感じになります
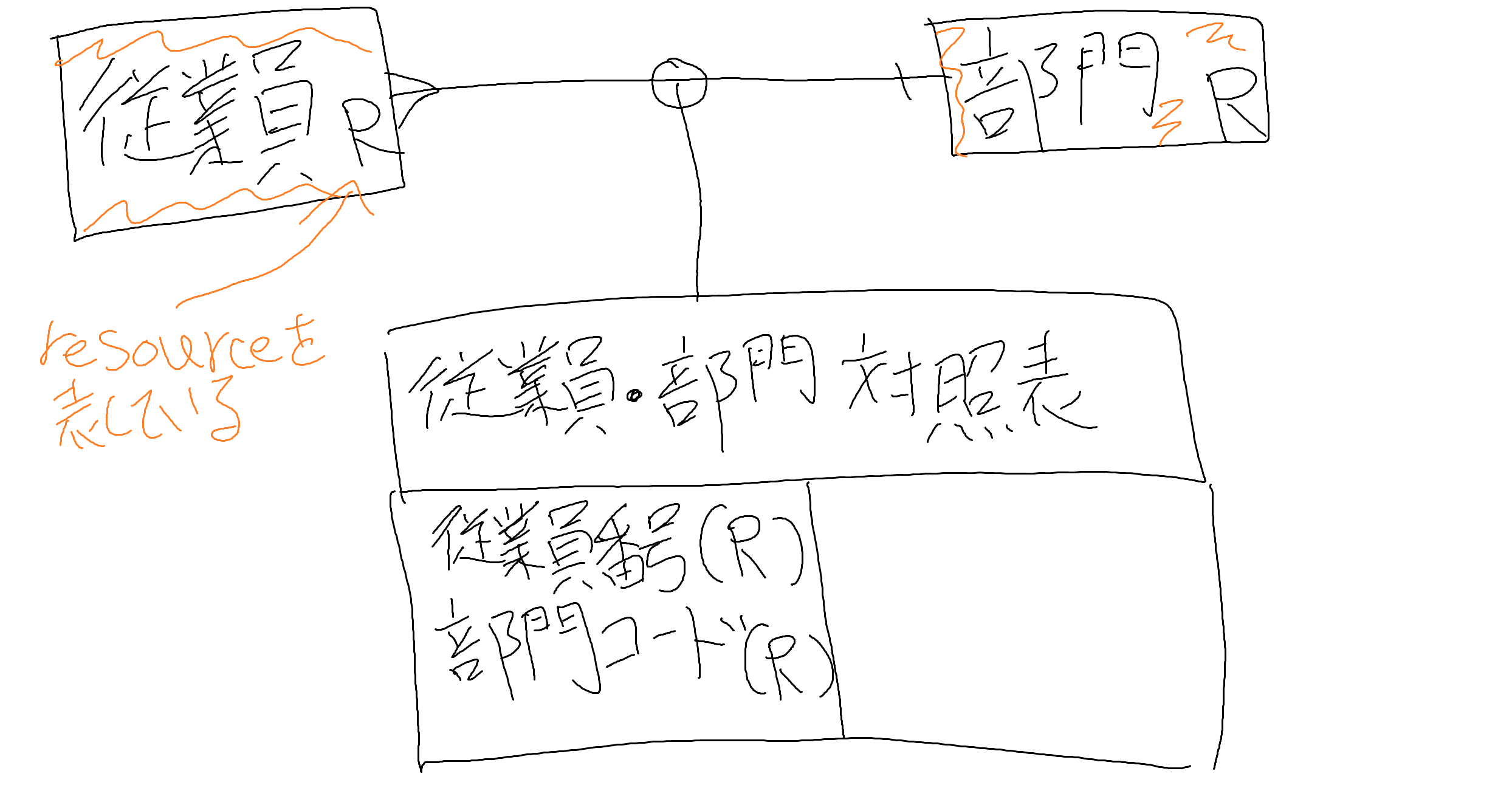
対照表にある「従業員番号」、「部門コード」はそれぞれのresourceから持ってきています
従業員・部門対照表にタイムスタンプを挿入すると、「配属」というeventになります
実を言うと、この対照表ってeventだったりします
※T字形ER手法では、3つ以上のresourceから対照表を生成することはありません。3つ以上のresourceから対照表を生成してしまうと、ビジネスの解析ができなくなってしまう可能性があるからです
##対応表とは
ノリは対照表みたいな感じなのですが、eventには時系列があるため少し事情が変わってきます
event : event が1:1、1:多であれば対応表は必要ありません
event : event が多:1、多:多の場合は対応表が必要になります
こんな感じになります
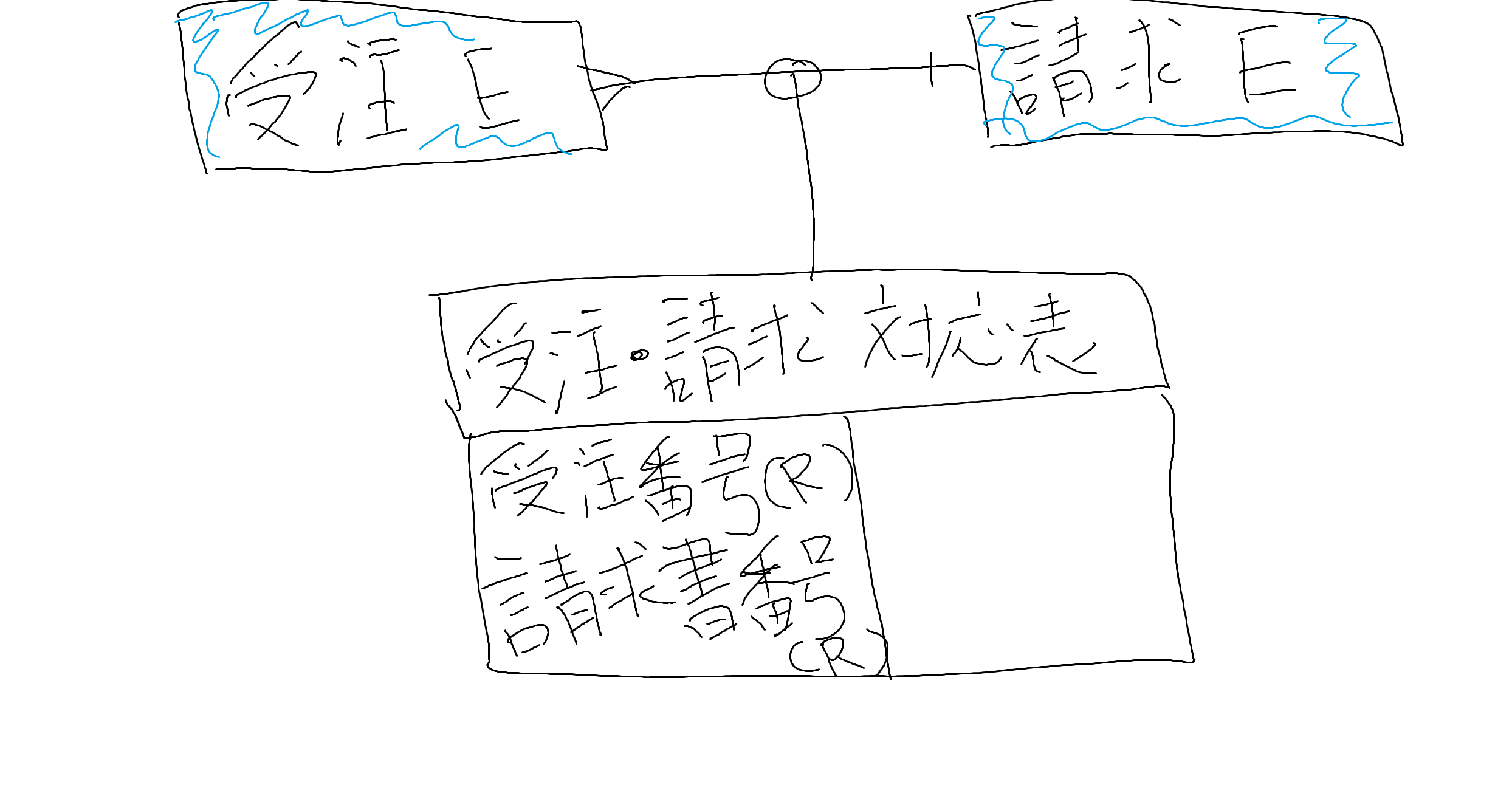
対照表と同じように、それぞれのeventから「受注番号」、「請求書番号」を持ってきています
対応表を生成しないとデータがおかしくなる可能性があるので、条件に一致した場合には絶対に対応表を生成してください!
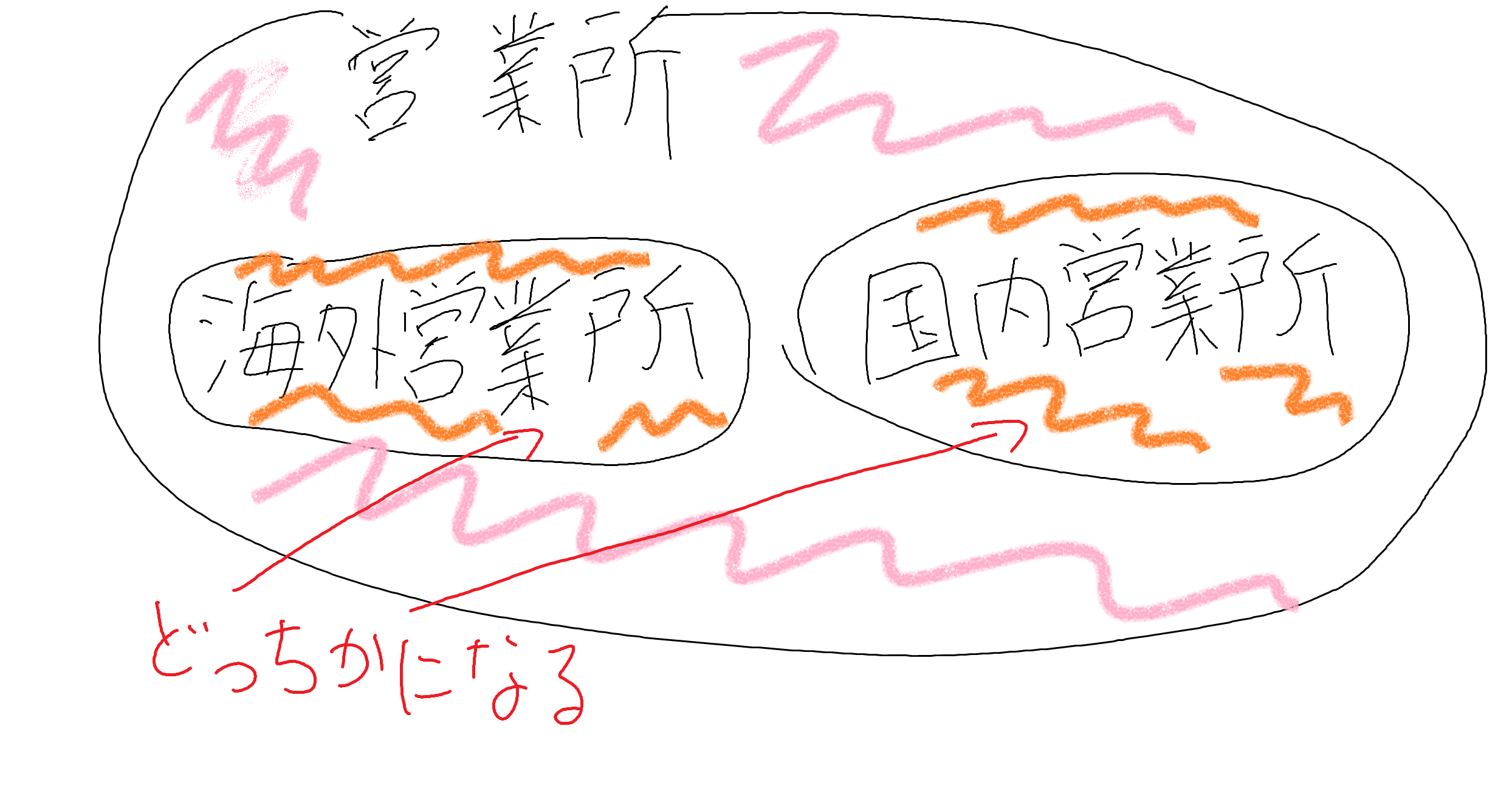
##サブセット
営業店コード、従業員コードのように表現されているものをサブセットと呼びます
サブセットはクラスの継承のような形になることがあります
例えば、営業所に営業所区分コードがあり、海外営業所と国内営業所に分けられる…というような感じです
サブセットの階層が深くなることがありますが、どんどん深くして行ってしまって大丈夫です
ただし、事実を表現すること!
上位のサブセットと同じレコード・レイアウトになるものを同一のサブセットと呼びます
上位のサブセットと違うレコード・レイアウトになるものを相違のサブセットと呼びます
上位のサブセットは下位のサブセットを包含していますが、同じ階層のサブセットはorの関係になります
こんな感じです
###アトリビュートのnull値について
テーブル設計をしていると、たまにどうしても一回nullを設定しておき、後からnullをupdateする、という方法をやりたくなってしまうときがあります
しかし、T字形ER手法ではこのやり方は認めていません
そもそも、nullを設定しなければならないテーブル設計がおかしい、という話です
例えば、「取引先」というresourceのアトリビュートとして「取引開始日」があったとします
これだけであれば問題ありませんが、諸事象により取引が停止した時には「取引停止日」が欲しくなってきます
「とりあえず「取引先」のアトリビュートに「取引停止日」を追加っと…
アレ?こうすると取引を停止していない取引先の「取引停止日」は決まってないぞ…
とりあえずnullにしとけ!」
これです!これがダメなんです!w
T字形ER手法では「取引先」サブセットの下位サブセットとして「active」、「過去」を定義してあげます
「active」には下記を追加します
・取引先コード(上位サブセットのidentifier)
・名称
・所在地
・取引開始日
「過去」には「active」に加えて下記を追加します
・取引停止日
これでアトリビュートのnull値を回避することができます
※T字形ER手法ではモデリングしたものをそのまま実装に落とすため、この方法では「取引会社テーブル」、「取引停止会社テーブル」のようになると思います。命名についてはモデルの名前を引っ張ってくるため、「active」、「過去」のような名前ではなく、もう少しわかりやすい名前を付けてあげたほうが良いかもしれません
##みなしエンティティ
みなしエンティティとは、entityの純度を高めるために使う手法のことです
みなしエンティティはVE(Virtual Entity)と呼ぶこともあります
みなしエンティティが使えるパターンには下記のものがあります
- 1つのresourceの中にeventが混入している
- 1つのresourceの中に他のresourceが混入している
- 1つのeventの中にresourceが混入している
- 1つのeventの中に他のeventが混入している
例えば、「従業員」というresourceを構成する要素が下記のようになっているとします
・従業員番号(identifier)
・名前
・住所
・前会社名
このような場合、「前会社名」をみなしエンティティとしてくくりだします
こんな感じになります
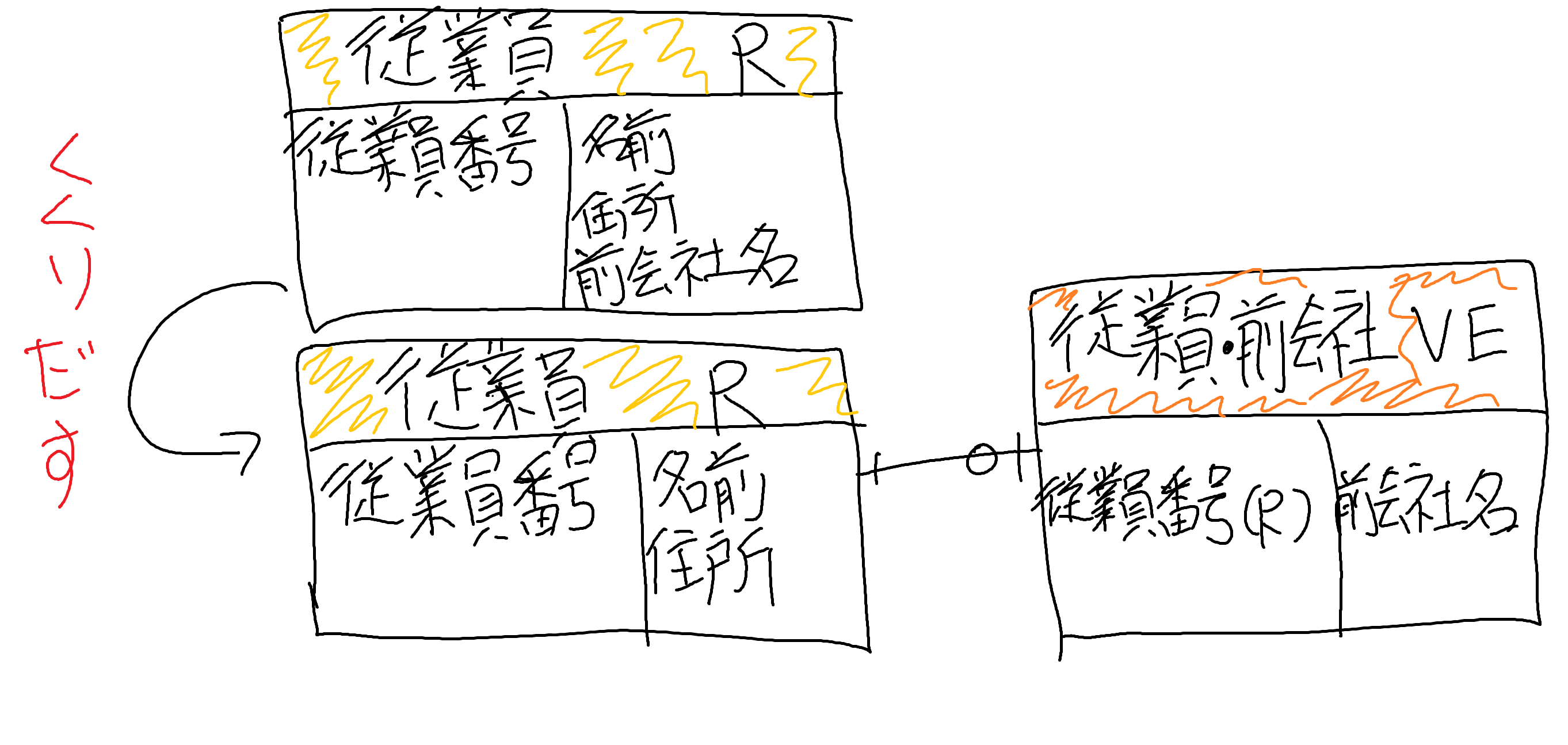
※前会社が存在しない人もいるため、0、または1、という関係性になっている
みなしエンティティは派生元となったidentifier(今回の場合は従業員番号)をそのまま使う
みなしエンティティは通常のentityとは異なるため、派生元でないentityとは関係性を結ばない
このようにみなしエンティティを使うことによってアトリビュートのnull値を避けられる上、entityの純度を高めることもできます
##ターボファイル
パフォーマンスを高速化するために利用される方法のこと
ターボファイルとは、目的別に分けられたviewのようなもののこと
(黒本ではデータマートのようなもの、とも説明されている)
元になるentityからデータをコピーして持ってくる
これはデータ構造を表すものではなく単にアクセスするための部分であるため、その他のentityとは区別しなければならない
ターボファイルはパフォーマンスを考えたときの一時的な回避策のようなもので、いつでも捨てられるようにしておかなければならない
##番外編ルール(拡張技法)
1つのエンティティから派生する複数の対照表は統合できる
例えば、下記のresourceがあったとします
- 倉庫
- 棚
- 製品
これらの対照表として下記が生成できます
- 倉庫・棚対照表
- 棚・製品対照表
この2つの対照表を統合して下記の対照表を生成することができます
- 倉庫・棚・製品対照表
この対照表にタイムスタンプと数量というアトリビュートを置いてあげれば、「在庫」を表現することができます
このように、resourceを組み合わせると対照表を生成でき、対照表を他のentityと組み合わせて…ということが出来るため、モデルで表現できる幅が広がります!
だから最初にresourceが重要って話だったんですね…
※前述していますが、対照表はeventです!
#まとめ・感想
T字形ER手法について簡単に説明してみました
どうだったでしょうか…
T字形ER手法からはDDDに近いものを感じました
ただ、事実を元にする、という部分への力の入れ方が強いと感じました
(identifierが無いものからはentityを生成できない、ってすごくない?)
近いと感じつつもやはりアプローチの仕方が別物なので、新しい発見がいくつもありました
全部のテーブルにタイムスタンプ付ければT字形ER手法になるんじゃね?とか勝手に思っていたのですが全然違いましたw
厳密なルールがあり、誰が作っても同じモデルが出来上がる、という点がすごい部分だと思いました
実際の黒本には更に多くの図が書いてあり、より細かい説明や例も書いてあるため、もう少し詳しく知りたい人は是非買ってみてください
新しいバージョンでは「L-真」、「F-真」という考え方も追加されています!
下記URLを参考に、もう少しTMについて深堀していっても良いかもしれません
データモデリング ~佐藤正美氏、若手エンジニアにデータモデリングを語る~
他の記事