こんな感じでできそう
df_groupby = df.groupby("地区2019")
df_groupby.mean() #地区2019の平均
Like!
下記のようなデータフレームがございましてカタログ、地区別毎に前年比の表示と過去3年間の平均を計算し取得させたいです。
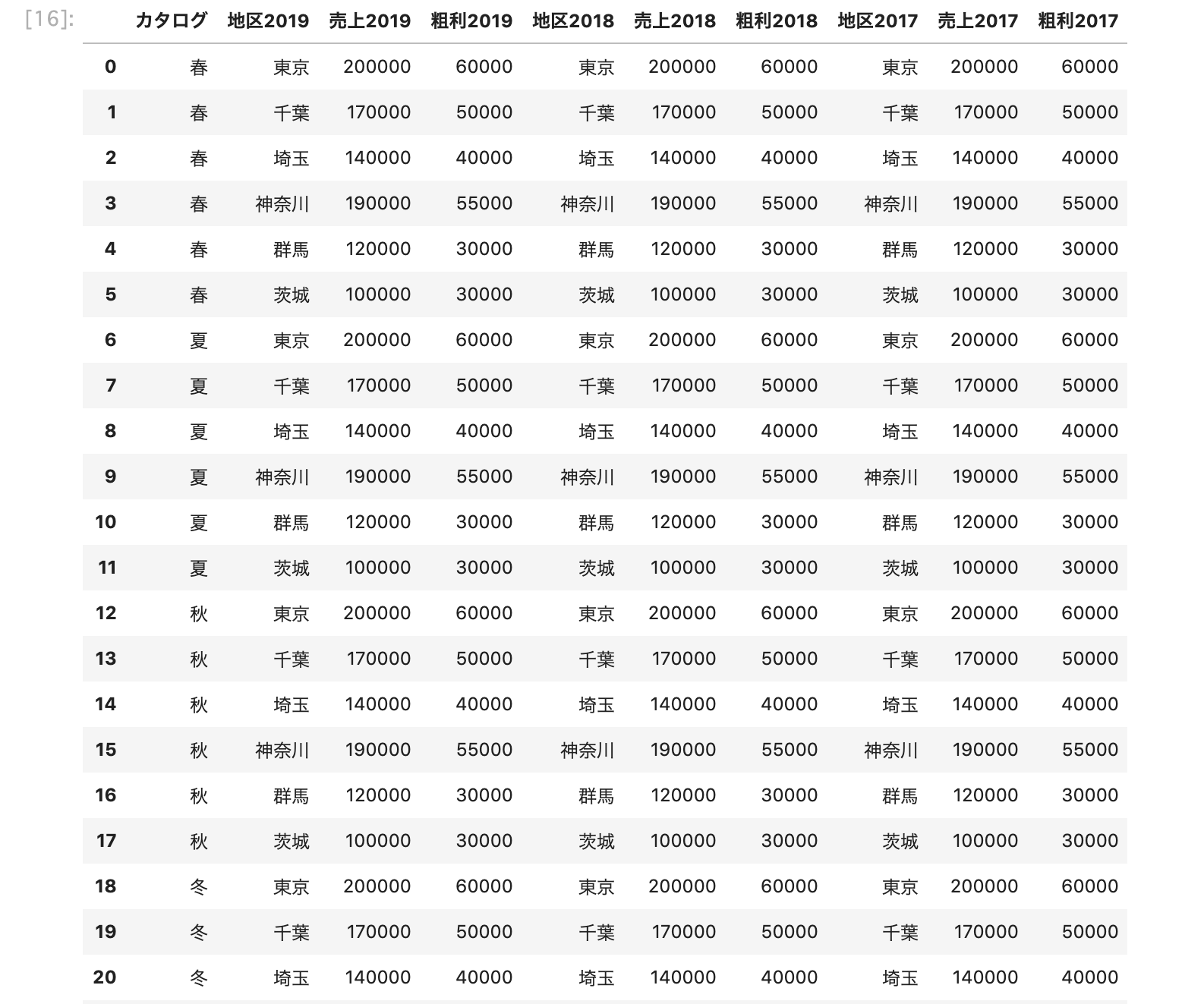
Excelファイルを直接手動で計算すれば出来るとは思うのですが、なんとかPythonで自動化出来ないものかな?
と思い質問させて頂きます。
どなたかご教授いただけましたら幸いです...
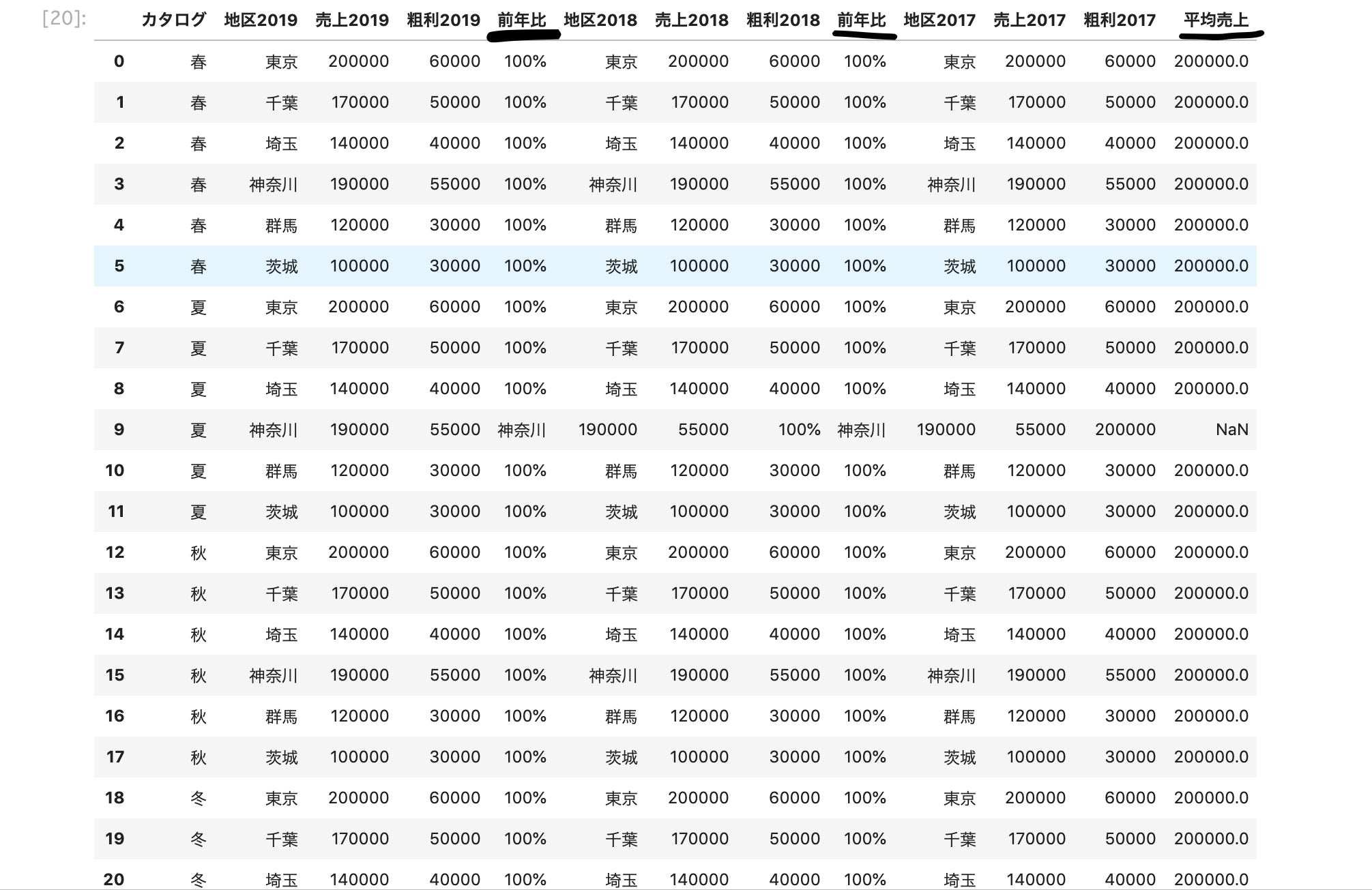
前年比の列を作成
df["売上2019"][0] / df["売上2018"][0] * 100
df["売上2019"][1] / df["売上2018"][1] * 100
.
.
.
で1行づつ計算する事も考えましたが、月によってはデータの無い地域もあるため地域との紐付けが無いと
誤って計算をしてしまうなと思い。
出来る事ならば地域名と紐付けがされて計算処理される方法は無いものかと考えてます。
こんな感じでできそう
df_groupby = df.groupby("地区2019")
df_groupby.mean() #地区2019の平均