
harness-starter-kitは魔法ではない。エラーを早く表に出すためのもの
こんにちは。韓国出身のジュニア開発者です。
日本語はツールの助けも借りながら整えています。少し不自然な表現があればご容赦ください。
前回の記事では、harness-starter-kit を実プロジェクトに入れてみた最初の体験を書きました。
そのとき私が一番気にしていたのは、次のようなことでした。
- エージェントがテンプレートを雑にコピーしないか
- 既存プロジェクトの構造を壊さないか
- 誰もメンテナンスしない
docs/ディレクトリが増えるだけにならないか
今回は、その後 dogfood を続ける中で学んだことを書きます。
harness の価値は、エージェントをすぐに賢くすることではないかもしれません。
もっと現実的な価値は、エラーを早く表に出し、そのエラーをリポジトリに覚えさせることです。
最初の期待は少しずれていた
最初は、私もこう考えていました。
プロジェクトに AGENTS.md、検査スクリプト、decision docs、failure docs があれば、エージェントのミスは明らかに減るのではないか。
今は、その言い方は少し早すぎると思っています。
エージェントは、それでもミスをします。
たとえば、次のようなことは起こりえます。
- 境界条件を忘れる
- 現在のプロジェクトに合わない実装を書く
- 検査を一つ漏らす
- ある失敗を一時的な問題として流してしまう
- 変更してはいけない生成ファイルを編集する
だから今の私は、こうは言いません。
harness-starter-kit によってエージェントが賢くなった。
むしろ、こう言いたいです。
harness-starter-kit は、一部のエラーを発見し、記録し、検査し、再利用できる場所を作る。
この二つは、かなり違います。
二つの dogfood repo
現在、私は主に二つの実プロジェクトでこのスターターキットを試しています。
一つは Django プロジェクトです。
harness_starter_kit_django
もう一つは Next.js プロジェクトです。
today-bus
この二つは、役割が少し違います。
Django dogfood: 安定した local / CI harness
Django dogfood repo は、安定したサンプルに近い存在です。
中には次のようなものがあります。
AGENTS.mddocs/decisions/docs/failures/scripts/check_harness.py.github/workflows/harness-check.yml.harness/source.json- adoption report / update report
このプロジェクトで確認できたことがあります。
starter kit は、対象プロジェクトを特定の共通構造に変える必要はありません。
Django プロジェクトがもともと持っているコマンドや workflow に合わせられます。
たとえば、この repo の normal check は Python らしい形です。
python scripts/check_harness.py
この wrapper は、おおよそ次のチェックを実行します。
- docs drift check
- structure check
- encoding hygiene check
- effectiveness plan check
manage.py checkmanage.py test
同じ check は GitHub Actions にも接続しました。
この repo は、私にとっては次のような dogfood 例です。
安定した local / CI harness の dogfood サンプル。
一方で、問題も見つかりました。
local kit reference に refresh gap があったのです。
つまり、target repo が記録している starter kit source と、現在の starter kit の最新内容との間に差が出ることがあります。
そのため、/harness update と .harness/source.json が重要になります。
そうしないと、harness を採用したあと、対象 repo がどのバージョンの kit を参照しているのかわからなくなりやすいからです。
Today Bus dogfood: 外部APIと failure memory
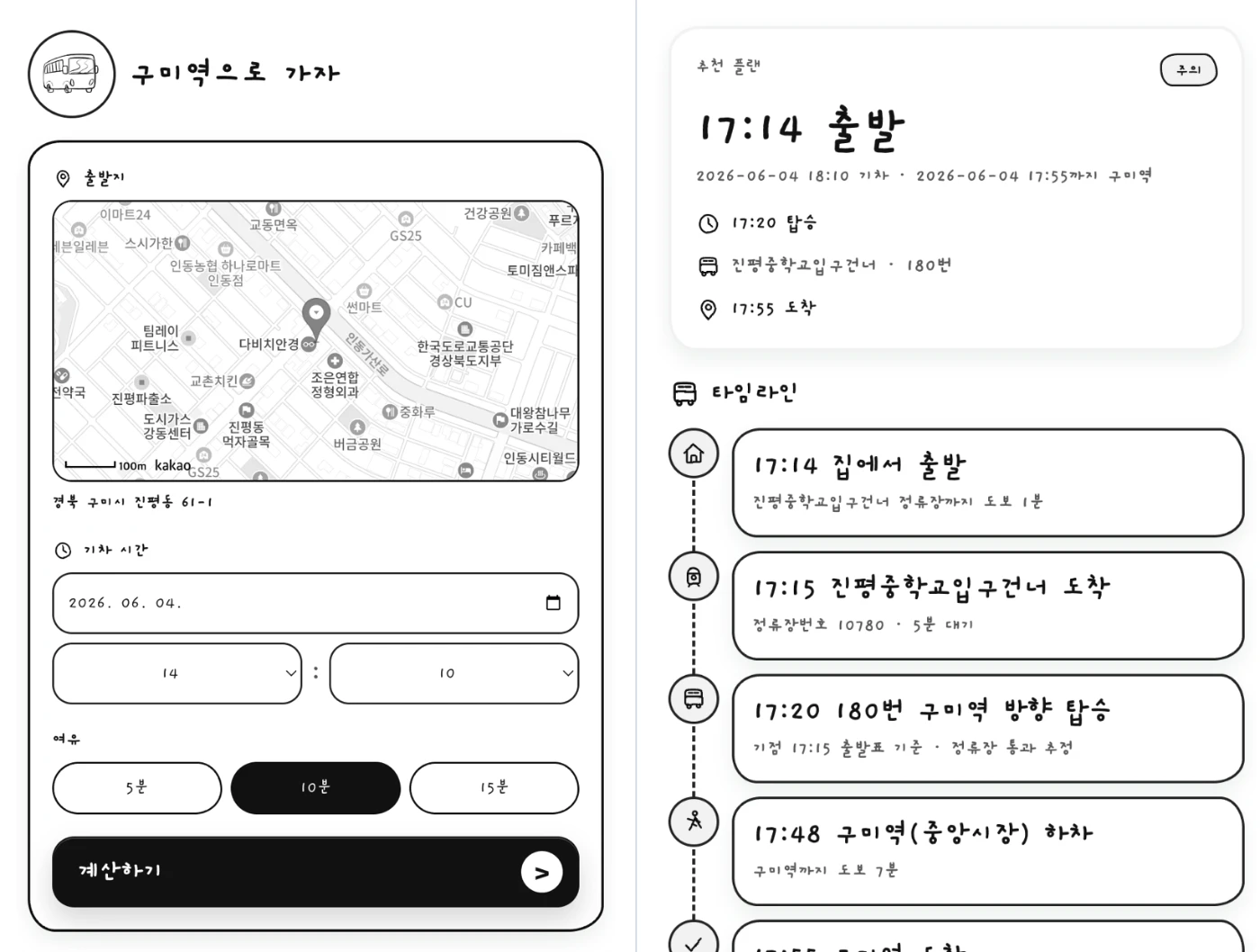
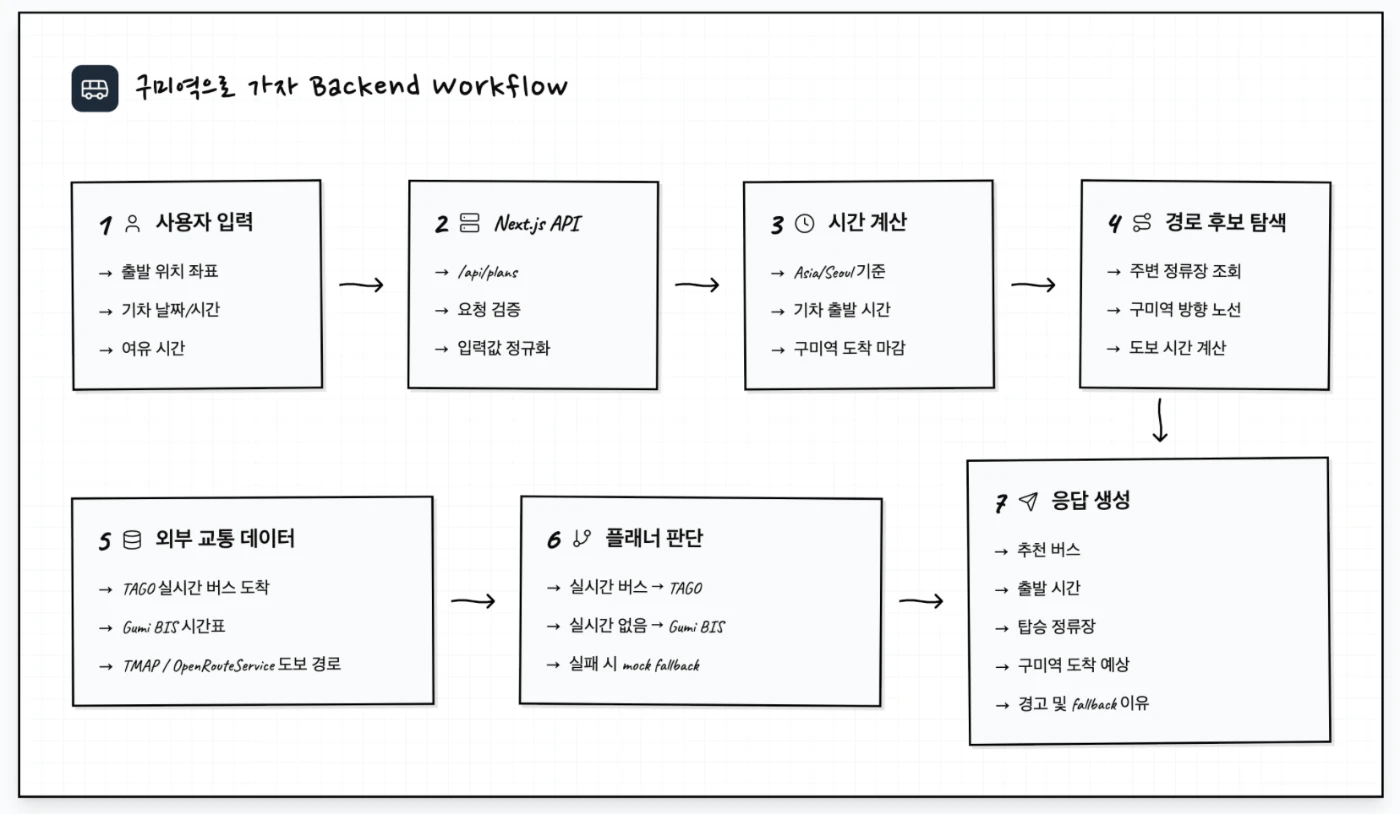
もう一つの dogfood repo は today-bus です。
これは Next.js のプロジェクトで、目的は次のようなものです。
구미역 の列車に間に合うために、いつ出発し、どのバス停まで歩き、どのバスに乗ればよいかを計算する。
このプロジェクトは、多くの外部データソースに依存しています。
- TAGO public transit API
- Gumi BIS timetable
- TMAP walking route
- OpenRouteService walking route
- Kakao map input
そのため、Django dogfood よりも複雑です。
ここでよく起きる問題は、単純な lint error ではありません。
- live API と mock fallback をどう分けるか
- provider が空の結果を返したときにどう扱うか
- service key を client に漏らさないこと
- 外部 API パラメータの大文字小文字が一致しないこと
- live smoke check を default gate に入れてよいか
- failure note に「問題があった」とだけ書くのではなく、再発防止の方法まで書くこと
Today Bus の normal gate は、現在こうなっています。
npm run check:harness
おおよそ、次の処理を実行します。
npm run lint
npm run test:planner
npm run typecheck
npm run build
node scripts/check-harness.mjs
ここで test:planner は deterministic local test です。
live API に依存しないので、normal gate に入れやすいテストです。
一方で、TAGO / TMAP / OpenRouteService の live smoke check は、簡単に default gate へ入れるべきではありません。
これらは次のものに依存するからです。
- credentials
- network
- quota
- provider uptime
- 現在の公共データの状態
この区別は、私にとって重要でした。
以前なら、単純にこう考えていたかもしれません。
API smoke check があるなら全部実行すればいい。
今は、もう少し慎重です。
deterministic local check は normal gate に入れる。
live API check は、それが本当に安定し、安全で、default verification に向いている場合を除いて、focused/manual のままにする。
check:harness の失敗が、逆に harness の価値を教えてくれた
Today Bus で一度、npm run check:harness が失敗しました。
最初は悪いニュースに見えました。
でも後から見ると、これは harness がちゃんと働いた例でした。
失敗したのは次のコマンドです。
npm run typecheck
エラーは .next/dev/types/validator.ts を指していました。
これは Next.js dev server が生成する型ファイルで、アプリケーションのソースではありません。
問題は「app source の実装が間違っていた」ことではありません。
active dev server が stale / malformed な generated artifact を残し、tsc がそれを読んでしまったことでした。
ここで大事なのは、次の点です。
.next/配下の生成ファイルを手で直してはいけない。
check を通すために generated output を編集してはいけない。
最終的には、次のように対応しました。
next typegen && tsc --noEmit --incremental false
つまり、npm run typecheck の前に Next.js generated types を更新し、そのあと TypeScript check を実行するようにしました。
この失敗は、チャットログだけには残りませんでした。
failure record として、次のファイルに残りました。
docs/failures/0005-next-dev-validator-typecheck-artifact.md
同時に、decision も記録しました。
docs/decisions/0017-refresh-next-generated-types-before-typecheck.md
ここに、今の私が harness の価値を感じる理由があります。
以前なら、この問題はこう終わっていたかもしれません。
次からは
next typegenを先に実行しよう。
そして、次の新しいセッションではまた忘れる。
今は、repo の durable memory になりました。
- 何が失敗したのか
- なぜ失敗したのか
- 何を変更してはいけないのか
- 現在の代替策は何か
- どの check が再び検出できるのか
failure memory は、ただの読み物では足りない
以前から failure note を書くことはありました。
でも今は、「何が起きたか」だけを書くのでは足りないと思っています。
たとえば、次のような記録です。
ある API パラメータの大文字小文字が間違っていた
ある provider が変な error を返した
ある CI が失敗した
もちろん、こうした記録にも意味はあります。
でも、検査につながっていなければ、「読めば役に立つが、同じ失敗を防げないドキュメント」になりがちです。
そこで kit では、次の考え方を強調しています。
failure memory は detection または prevention につながっているべきです。
つまり、docs/failures/*.md には次のような情報が必要です。
- どの test がこの失敗を検出するのか
- どの fixture がこのケースをカバーしているのか
- どの smoke check が検証できるのか
- どの lint / drift check が止めるのか
- 自動化できない場合、どの manual review point で確認するのか
Today Bus の TAGO パラメータの大文字小文字問題は、その一例です。
ある endpoint が必要としていたのは、次の名前でした。
nodeid
しかし、誤って次のように扱っていました。
nodeId
この小さな違いによって、provider は単一バス停での絞り込みを行わず、検索範囲が広がり、場合によっては rate limit に近づいてしまいました。
この問題は、failure note に書くだけでは終わらせませんでした。
planner/provider test にも接続しました。
単に「nodeid の大文字小文字に注意」と書くより、こちらのほうがずっと信頼できます。
Doctor score は agent effectiveness ではない
この過程で、もう一つはっきりしたことがあります。
Harness Doctor は有用ですが、エージェントが強くなったことを証明する道具ではありません。
Doctor が見られるのは、repo に durable evidence があるかどうかです。
- agent instructions
- local checks
- decision records
- failure records
- adoption report
- CI / validation hints
これは harness health signal です。
しかし、次のことは証明できません。
- エージェントが間違ったファイルを変更しにくくなった
- 同じバグを繰り返しにくくなった
- reviewer の手戻りが減った
- first-pass verification の成功率が上がった
これらは task outcome records や effectiveness report で見る必要があります。
だから今は、次のように分けています。
Harness health:
repo に durable rules / checks / memory があるか
Agent effectiveness:
実際のタスクで、エージェントのミスや手戻り、失敗の再発が減っているか
これが、私がこのプロジェクトを過度に宣伝したくない理由でもあります。
言えるのは、こういうことです。
この kit は、ルール、チェック、失敗経験をリポジトリに置く助けになりました。
でも、まだこうは言えません。
エージェントの品質が明確に上がったと証明できました。
後者には、もっと多くの実タスクのデータが必要です。
今見ている maturity signal
今、私は target repo の harness が成熟しているかどうかを、docs の有無だけでは判断しません。
むしろ、次のようなシグナルを見ています。
- エージェントが
AGENTS.mdからプロジェクトルールを読めるか - normal verification gate が明確か
- deterministic local checks が normal gate に入っているか
- live / slow / credential-based checks が分離されているか
-
docs/decisions/に実際の構造上の意思決定が記録されているか -
docs/failures/に繰り返したくない失敗が記録されているか - failure note が test / fixture / smoke check につながっているか
-
/harness updateがファイル上書きではなく selective refresh になっているか - Harness Doctor のスコアと effectiveness claim が分けて説明されているか
一つ一つは複雑ではありません。
ただ、これらが組み合わさると、エージェントの作業が単発のチャットコンテキストに依存しにくくなります。
これはインストールツールというより、メンテナンスのループ
今の私にとって、harness-starter-kit は単なる installer ではありません。
むしろ、次のようなループです。
ルールを発見する
リポジトリに書く
できるだけ検査にする
失敗したら記録する
記録を検出手段につなげる
次の update / refresh / review で改善する
初回 adoption だけを見ると、いくつかのファイルを追加しただけに見えるかもしれません。
でも継続して dogfood すると、本当に価値があるのは feedback loop だとわかります。
特に失敗が起きたあと、repo は次のような問いを持てるようになります。
- この失敗は記録すべきか
- 記録するなら、どの check が検出できるか
- check がないなら、その理由は何か
- このルールは AGENTS、ADR、failure note、final report のどこに置くべきか
- この変更は normal gate に入れるべきか、それとも focused/manual のままにするべきか
これらの問いは、エージェントの仕事を「コードを書いて終わり」にしないためのものです。
次にやりたいこと
これからも、より多くの実プロジェクトで evidence を集めたいと思っています。
たとえば、次のようなものです。
- さらに多くの adoption report
- さらに多くの task outcome records
- Go / Rust / iOS / Rails / Laravel profile
- monorepo adoption example
- GitLab CI adoption note
- よりわかりやすい workflow diagram
- README onboarding の改善
そして、次の点も観察し続けたいです。
同じ種類の agent mistake は本当に減るのか。
あるいは、少なくとも以前より早く見つかるようになるのか。
Doctor score が上がるだけでは不十分です。
本当に価値があるのは、次のようなことです。
- reviewer の手戻りが減る
- known failure の再発が減る
- check が問題を早く表に出す
- 新しいセッションでもプロジェクトコンテキストを引き継ぎやすい
プロジェクトリンク
GitHub:
Cursor / Claude Code / Codex のような coding agent をよく使っていて、
「新しいセッションのたびにプロジェクトルールを説明し直す」ことに困っている方がいれば、ぜひ見てみてください。
この考え方に問題があると思う場合も、ぜひ率直に指摘してください。
私はまだジュニア開発者なので、きれいな言葉よりも、実際に役立つフィードバックがほしいです。