【注】当たり前の内容かもしれませんが試した結果なので記事にしました。
概要
この記事は、以前の記事「【資金不足でも高性能AIを諦めない!】低スペックPCでクラウド&ローカルLLMを両立させる究極のハイブリッド戦略」で紹介したLM Studio環境の 「その後」 の追加記事です。
元の記事:
前回の記事公開後、シンプルなチャットクライアントを使用した実運用と、その説明動画の作成を通じて、LLMをさらに快適かつ効率的に活用するための課題が明確になりました。
その課題解決のために作ったのが、 「回答者キャラクター設定型」 と 「テキストエディタ選択箇所回答特化型」 の2つの拡張クライアントです。
| 時期 | 主な成果物 | 役割と課題 |
|---|---|---|
| 前のQiita記事公開時 | シンプルなチャットクライアント | 技術検証と動作確認。しかし、実運用で課題が顕在化。 |
| 動画作成時 | LLM-LANの説明とシンプルなクライアントのデモ | LM Studio環境の動作実証(LLM-LAN)。 |
| その後の実験 | 拡張2種を追加 | 顕在化した課題を解決し、ローカルLLMを実用ツールへ |
説明動画(LLM-LANの説明とシンプルなクライアントのデモ):
1. 動画で実証した後に見えたローカルLLMの「課題」と拡張の動機
動画のデモで、低スペックPCでもLM Studioが実用的な速度で動作することは証明されました。しかし、使用モデル(GPT-OSS-20Bなど)の 「素の特性」 が、その後の日常的な利用において以下の課題を引き起こしました。
| 顕在化した課題(モデルの「素」の傾向) | 拡張の動機 | 解決策(拡張クライアント) |
|---|---|---|
| 事務的な堅苦しさ、表多用、冗長 | 回答の人格やスタイルを制御したい。 | 回答者キャラクター設定型 |
| 全力の長文回答(=リソース消費大) | PCの推論負荷を下げ、応答速度を向上させたい。 | 回答者キャラクター設定型 (長さ制御) |
| 定型作業のプロンプト入力が面倒 & 回答の対象が曖昧になりがち | 特定のタスクに特化させ、作業効率を極限まで高めたい & 回答の対象を限定することで推論時間を短縮したい。 | テキストエディタ選択箇所回答特化型 |
この課題解決こそが、シンプルなチャットクライアントから、機能特化型の2つのクライアントへと拡張した最大の理由です。
2. 拡張された3種類のLM Studio連携クライアント
開発された3つのクライアントは、それぞれ異なる目的を達成するための特化型インターフェースです。
| クライアント名 | 端的な特徴 | 課題解決の貢献度 |
|---|---|---|
| 1. シンプルなチャットクライアント | 基本的なストリーミング対話環境 | 【技術検証の完了】 API連携とMarkdown表示の土台。 |
| 2. 回答者キャラクター設定型 | システムプロンプト/回答長さをUIから制御 |
【性能と人格の制御】 回答の冗長性を解消し、max_tokens制限により応答速度と効率を大幅に改善。 |
| 3. テキストエディタ選択箇所回答特化型 | エディタのドラッグ選択箇所に対する知識抽出(要約、解説など) | 【作業効率の向上】 定型タスクのプロンプト入力が不要に。LLMを文書処理ツールとして統合。 |
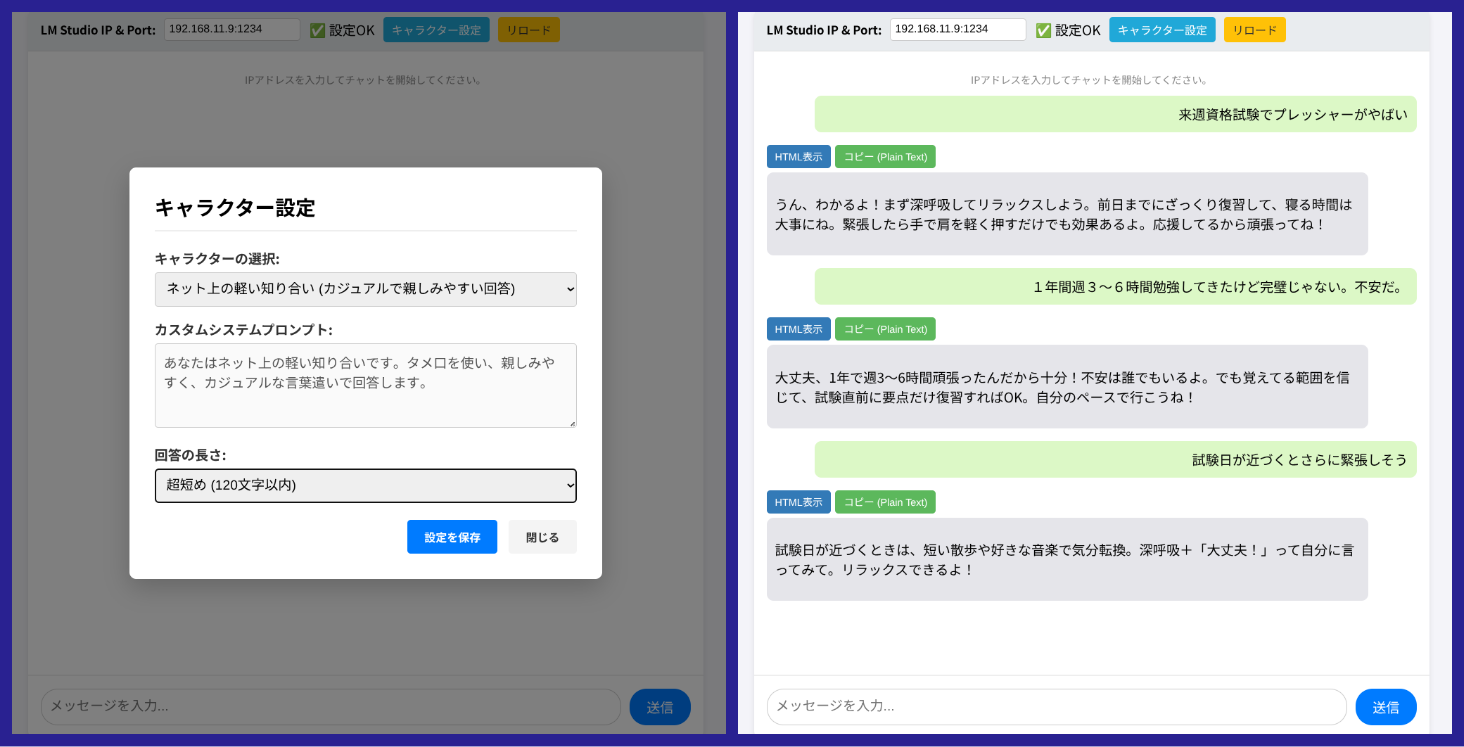
3. 【重要】キャラクター設定型クライアントによる性能と効率の担保
特に低スペック環境における 「長文回答による遅延」 という課題を直接解決したのが、キャラクター設定型クライアントです。
-
課題解決の仕組み: このクライアントでは、UIで回答の長さ(例: 120文字以内)を選択させ、その設定をAPIリクエストの
max_tokensパラメーターに変換して送信します。 - 効果: モデルが指定トークン数を超えると強制的に応答が終了するため、PCの推論負荷が大幅に下がります。これにより、動画で実証されたスムーズな動作を、より効率的かつ継続的に担保できるようになりました。
- 人格制御: 同時にシステムプロンプトを設定できるため、「堅苦しい」という課題も解消し、実用性と快適性を両立させます。
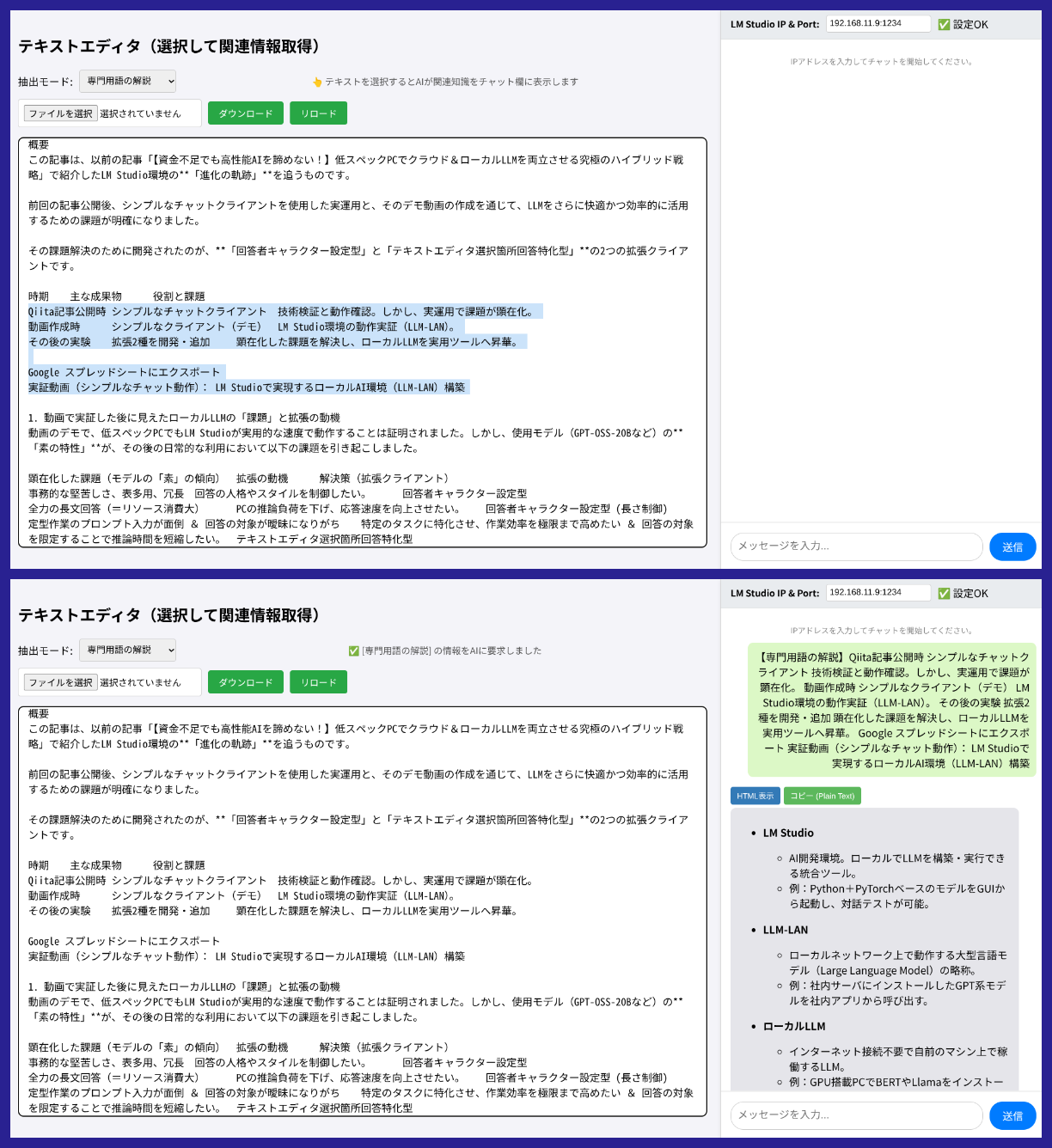
4. 知識抽出型クライアントによるワークフローの改善
知識抽出型クライアントでは、シンプルなチャットでは難しかった「文書の特定部分に対する作業」を可能にし、実用的な速度と精度を目指しました。
-
回答の範囲限定による高速化:
従来のチャットでは、長文をペーストするとLLMが文書全体を考慮しようとするため、推論に時間がかかりがちです。このクライアントでは、回答してほしい 「ごく特定の箇所」のみをドラッグで選択 します。これにより、LLMが処理する入力テキストの量が最小限に限定され、結果として回答までの時間が短縮されます。これは、非力なPCでローカルLLMを動かす上での、極めて重要な速度対策の一つです。
-
直感的で効率的:
「文章をドラッグ選択」し、プルダウンメニューでタスクを選ぶだけで、最適なプロンプトが自動生成・送信されます。コピペとプロンプト入力の手間がなくなり、LLMを 「編集作業のアシスタント」 としてシームレスに組み込めます。
結論
この3つのカスタムクライアントの開発は、シンプルな技術検証(Qiita記事・動画)から始まり、実運用で生じた課題(速度、リソース、スタイル)を一つ一つ解決していく、ローカルLLMを実用化するためのアプローチでした。
シンプルなクライアントで土台を築き、キャラクター設定型で性能と効率を担保し、知識抽出型で具体的な作業効率を向上させるという、役割分担となりました。
これらのスニペットは以下のURLにまとめていますので、よろしければ、ご自身のLM Studio環境でお試しください。
スニペット公開URL:
https://sf-os.work/snip/snipetg/sgroup_1760148091_e2526d8d.html