AWSを用いて転移学習して熱帯魚の画像判別機を作る
設定した課題
例えば下のような熱帯魚のカラシン目カラシン科の主要な46種を判別させる。

アークレッドペンシルフィッシュ
AWSのサービスである「Rekognition」が似ていると思われるが、熱帯魚の種類名までは分からないので、自分たちでモデルを組むことにした。
流れ
1.物体認識をして与えられた画像から、魚のところを切り取るモデル
2.切り取られた画像に映る熱帯魚の種類を当てるモデル
の2つを作り、組み合わせる。
学習データの収集
chromeの拡張機能である、googleimagedownloadを用いた。
googleで種類名を検索して検索上位に出てくる画像を用いている。
このサイトを参考にした
調べた種類とは関係がない写真(水槽など)、別の魚(金魚など)の写真も少なからず、混ざってしまっているのでこれらを除く必要がある。
モデル1 (物体認識)
イメージ図

↓
魚のみ切り抜く!!!
使ったデータの説明
魚が写っている写真をアノテーションして、学習用の画像データ800枚、validationデータ用の画像データを100枚作り、学習に用いた。
このサイトを参考にした
欠損値はない
前処理
手作業で、VOTTというものを使い、画像データにアノテーションをした。
その際ある種類のカラシンに特化した物体認識にならないように、各種のカラシンから均等にデータを選んだ。
アルゴリズムの選択
・AWSのRekognitionという物体認識ができる既存のサービスを使う
・AWSの物体検出の埋め込みアルゴリズム(Object Detection)を使う
の2通りを考えた
Rekognitionを使うことが出来るのであれば、それが最良だったのだが、座標を取り出すやり方が分からなかったので、諦めて、2つ目の案を使った。
元々のObject Detectionをそのまま使ってみると例えば下の画像のように魚が、人やモーターバイクと認識されてしまっていて魚は認識できなかったので、自分で学習データを用意して学習させて用いることにした。

結果、解釈
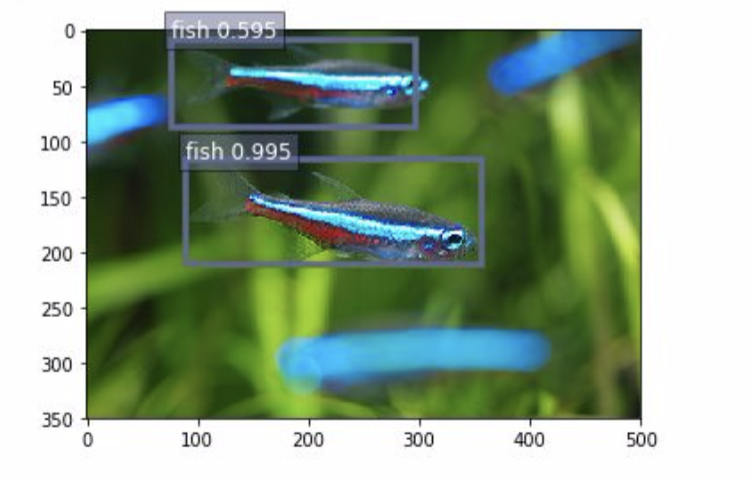
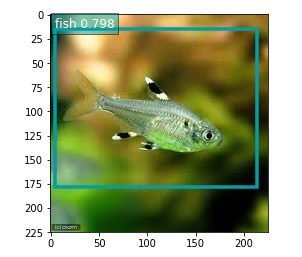
画像に魚が一匹しか写っていない時は高い精度で魚と認識される。
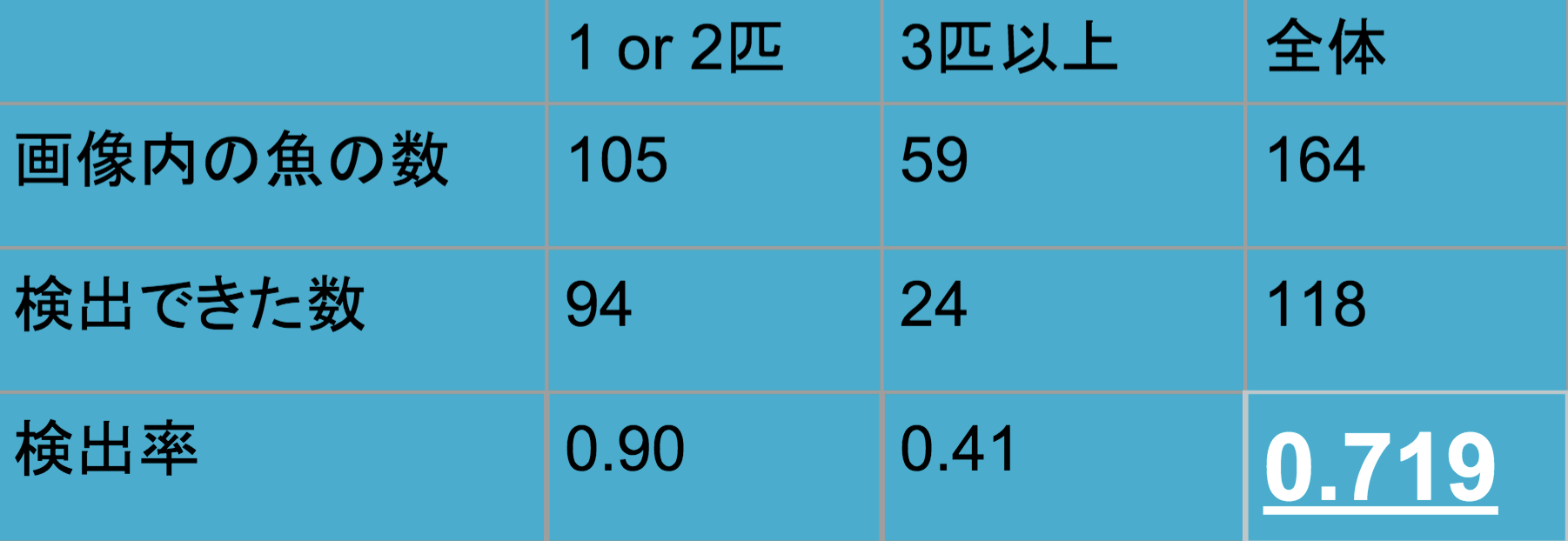
二匹写っている時は約5割と、精度が下がってしまうものの閾値を下げれば、魚の位置を認識できそうだ。

それ以上の数になると、精度はかなり悪くなってしまう。
学習データの数を増やせば精度は上がるのであろうが、アノテーションを手作業で行ったため、データ数には限界があった。
このモデルなしで、モデル2だけで、判別することも考えたのだが、(つまり、魚がどこかに写っている画像をそのまま学習させる、ということ)
モデル2(切り取った画像にうつる魚の種類を当てるモデル)
使ったデータの説明
・46種それぞれについて約20枚ずつ(合計約1000枚)の画像データ
・データの分布はほぼ均等である。(各種約20枚ずつだから)
・欠損値はない
・魚の種類名をフォルダの名前にして、そのフォルダに画像データを入れることで、画像と種類名を対応させてある。
前処理の工夫
・魚に関係がない画像(例えば水槽など)や、別の種類の魚の画像が少なからず混じってしまっているので、目視で排除した。
・学習に使う画像は下のように 一匹の魚のみがうつるようにトリミングした。

例えば上のような画像は下のように切り取った。

・ノイズに影響を受けにくいモデルを作るために、学習させる画像はランダムに回転、左右を反転させた。
(魚のところのみを切り取った画像で学習させているので、上下移動や、左右移動、拡大などは行わなかった。)
アルゴリズムの選択
魚の大量なデータを集めることは難しいので、少ない画像でも高い精度が出せる転移学習を選択した。
転移学習以外でやろうとしても画像が少なすぎてできないのではないかと予想した。
まず自分でモデルを作ってみた。
kerasのVGG16をbasemodelに用いた。
github
切り取らずにそのままの画像(つまり魚が中央に写っていなかったり、複数の魚が写っている画像)で学習させることも考え、試してみたのだが、精度は約2%と極めて悪かったので、魚のところを切り抜いて学習させることにした。そうしたところ、

精度は約20%で、低かった。
データ数を増やせば精度が上がるのでは?と、データの拡張を行い学習データを約10倍に増やしたのだが、精度は増やす前よりも下がってしまった。拡張をしたことにより、画質の悪いデータが沢山含まれてしまったことが原因かと思われる。
データの拡張に使ったコード
次に以下の方法で試した。
AWSのsagemakerの埋め込みアルゴリズムである「Image classification training with format demo」を利用してみた。このアルゴリズムも転移学習を用いている。
データはs3に格納し、GPUはp2.xlargeを用いた。
結果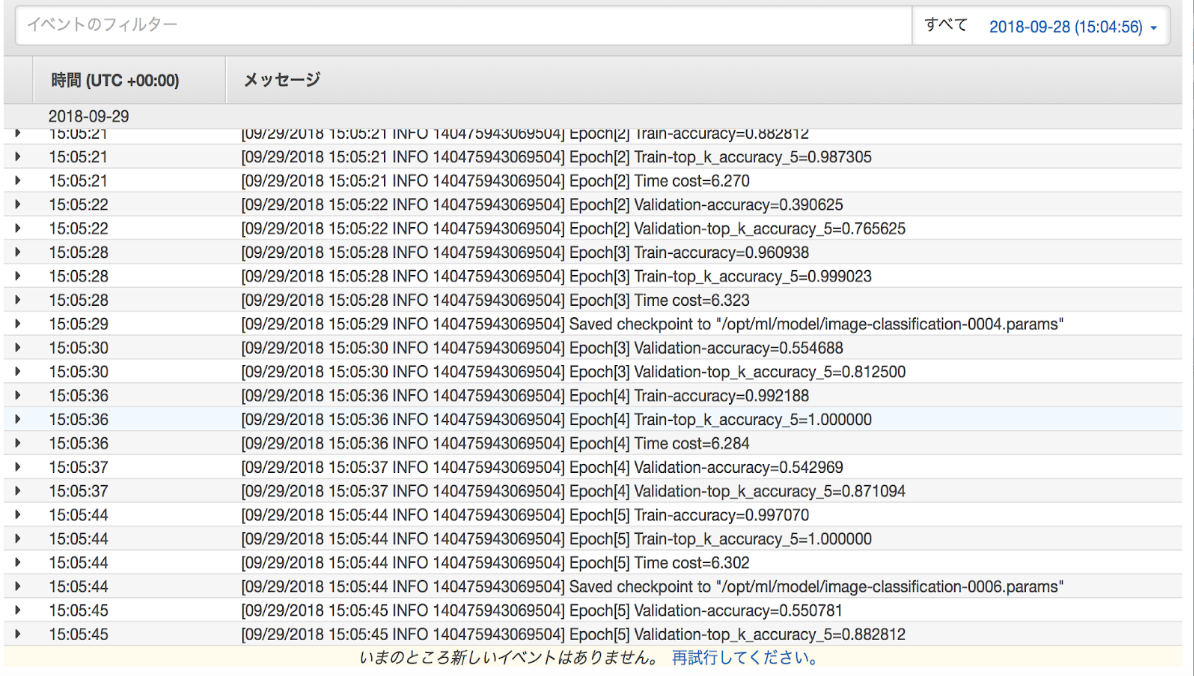
validationデータでの精度は、約60%となった。
精度が低かった理由はデータ数が少なすぎたからではないだろうか。
今後の展望
モデルの精度が低いのには学習データの数が少ないこと以外にも、何か原因があると予想しているのだが、探りきれず、残念だった。
現段階では2つのモデルを作ったものの、それらを組み合わせて、サービスの形にするところまでできていないので、そこに取り組みたい。