最近、Xでこんな投稿が話題になりました。
- 「LLM Knowledge Bases」:ソースドキュメントをraw/ディレクトリに集め、LLMがMarkdownのwikiに自動コンパイル。Q&Aで使い、その結果をwikiにフィードバックして強化していく循環構造
- 「Your Company is a Filesystem」:会社の業務をファイルシステムとして表現し、Unixのファイル権限で組織の権限管理を再現する思想
共通するのは、 LLM + ファイルシステム + シンプルな構造 = 強力なナレッジ基盤 という考え方です。
これらの手法が大いにバズって支持されています。
仕組みとしては非常にコンパクトで優れているな~と思います!
ただ、大企業のIT企画部門で働いてきた立場からすると、率直にこう感じました。
これ、エンタープライズの現場で適用できるイメージがまったく湧かない。
Xでは盛り上がっているものの、実際に何千人もの社員がいる組織でこの仕組みが機能するのか。その違和感がずっと引っかかっていました。
この記事では、その違和感を「仮説」として言語化し、大企業の現場目線で検証していきます。
この記事でわかること
- mdベースのナレッジ管理が「小規模だから成立する」構造的な理由
- 大企業の現場で何が壊れるのか(実体験ベース)
- 本当のボトルネックは技術ではなく組織構造にあるという視点
- 組織構造をどう変えればよいかの提言と、現実的な導入パターン
仮説:mdベースのナレッジ管理は「小さいから成立する」のでは
まずは、私の仮説から。
仮説:mdベースのナレッジ管理が機能するのは、以下の3つの前提条件が揃っているからであり、大企業ではこの前提が成立しない。
その3つの前提条件とは、次のとおりです。
前提①:自分で作って自分で使う
Karpathyのナレッジベースは、作る人=使う人=直す人です。データの取り込みも、wikiの構成も、Q&Aも、すべて本人が回しています。
この「三者が同一人物」という状態は、情報管理において最も強い構造です。入力者と利用者が同じだから、自分にとって使いやすい形でデータが自然に整っていきます。
前提②:ナレッジの量が少なく、文脈が一義的
Karpathyのwikiは約100記事・40万語規模と紹介されています。個人の研究テーマに絞られているため、同じ用語が違う意味で使われることがありません。
「売上」と書いたら「売上」。解釈の揺れが発生しない世界です。
前提③:SSOTが自然に担保される
自分で作って自分で使っているため、Single Source of Truth、つまり 唯一の正しい情報源 を維持するための合意プロセスが不要です。「どれが最新版?」という問いが発生しない。
この3つの前提をファイルシステムで例えると、個人のナレッジ管理は chmod 777 で全部回る世界です。誰でも読めて、誰でも書けて、それで何も問題が起きない。
では、大企業ではどうでしょうか?ここからは、この仮説を現場の実態に照らして検証していきます。
検証①:大企業の現場で何が起きているか
「作る人≠使う人≠管理する人」の世界
大企業では、前提①(自分で作って自分で使う)が真っ先に崩れます。
データを入力する人と、それを活用する人と、管理ルールを決める人が全員別人です。そして、この三者の利害は一致しません。
- 入力する人:「面倒だから最低限でいい」
- 活用する人:「もっと詳細に入れてほしい」
- 管理する人:「ルールを守ってほしい」
綺麗なデータを入力するコストは入力者が負担し、その恩恵は別の人が享受する。このコストとベネフィットの非対称性がある限り、データ品質は必ず劣化します。
大企業の現場は「ゴミデータ」だらけ
前提②(ナレッジの量が少なく、文脈が一義的)も成立しません。大企業のビジネスの現場は、率直に言ってゴミだらけです。
- 書きかけのファイルやメモ
- 間違った数値で作られたExcel
- 扱いにくいパワーポイントやPDF
- フォルダの奥底で眠る「最終版_v3_確定_修正済み.xlsx」
チャットやメールにも情報は散らばっていますが、暗黙知的なやり取りが多く、AIで扱うにはあまりにもノイズが多いです。
さらに、同じ「売上」という言葉でも、事業部ごとに定義が違うことは珍しくありません。量の問題ではなく、 文脈の多義性 こそが大企業のデータを複雑にしています。
ITリテラシーの差という現実
大企業にはたくさんの人がいます。ITリテラシーも千差万別で、低い人のほうが圧倒的に多いのが現実です。
そして企業は人を守らなければならない。そうなると、仕組みは下のレベルに合わせざるを得ません。
「Markdownで書いてください」「ファイル名の命名規則を守ってください」。こうしたルールを全社員に徹底することが、どれだけ難しいか。大企業で働いたことがある方なら、想像できるのではと思います。
Claude CodeやCopilotを全員が使いこなせるようになることは、まず無理でしょう。
SSOTの維持は人の力では不可能
前提③(SSOTが自然に担保される)も崩れます。
SSOTの担保、つまり「唯一の正しい情報源」を維持し続けること。個人なら自然にできるこれが、大企業では極めて難しい。
人の手でやることは現実的に不可能です。では、AIにやらせればいいのか。理論的にはそうですが、セキュリティ・コンプライアンス・ガバナンスの観点から、AIに社内データを自由に触らせることのハードルは非常に高いのが現実です。時代的にも大きなリスクは取りたくないのが、大企業の本音ではないでしょうか。
運用崩壊のループ
結果として、大企業のナレッジ管理は以下のループに陥ります。仕組みを作ったのはいいものの、ナレッジが登録されず、いつの間にか形骸化している。
そして、また新たにナレッジ集約が大事!と、違う人が仕組みを作り出す。
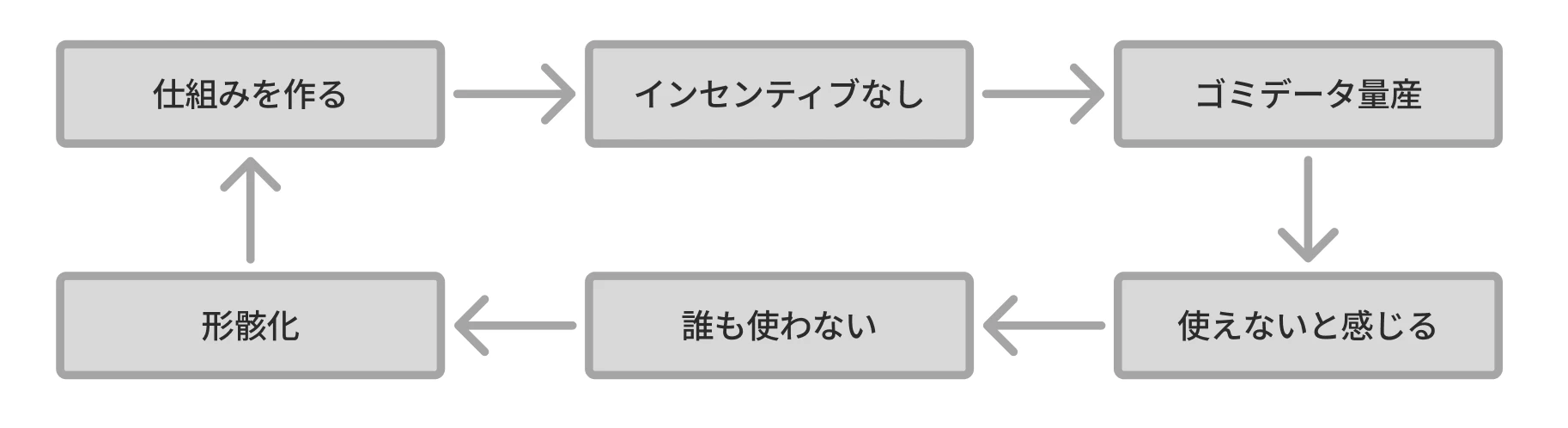
- 仕組みを作る
- 使う人のインセンティブがない
- ゴミデータが量産される
- 「使えない」と感じる人が増える
- 誰も使わなくなる
- 責任者も形骸化する
ここまでの検証で、仮説の前半部分、つまり「小さいから成立する」は確認できました。しかし、もう一歩踏み込むと、もっと根の深い問題が見えてきます。
検証②:技術の問題ではなく、組織構造の問題だった
「合意形成コスト」が技術コストを上回る
大企業でAIデータ活用が進まない原因を整理すると、技術的な制約よりも 「合意形成にかかるコスト」が圧倒的に大きい ことに気づきます。
- 「どのデータが正しいのか」を決めるのに、関係者の合意が必要
- 「誰がデータを管理するのか」を決めるのに、部署間の調整が必要
- 「どこまでAIに触らせるか」を決めるのに、法務・セキュリティの承認が必要
つまり、問題は技術ではなく、複雑化した 組織の意思決定構造 にあります。
データメッシュが示す方向性
ここで参考になるのが、データメッシュという考え方です。
データメッシュは「データを中央集権的に管理する」のではなく、 データを生み出すチームがそのデータのオーナーシップを持つ という設計思想です。
この原則を整理すると、次のようになります。
| データメッシュの原則 | 大企業に当てはめると |
|---|---|
| ドメイン型データオーナーシップ | 誰が責任者・意思決定者かを明示する |
| データをプロダクトとして扱う | ワークできる責任者を配置する |
| 連合型ガバナンス | 大きすぎない組織に分割する |
データメッシュやデータプロダクト、マイクロサービス。ソリューションの選択肢は存在しています。しかし、 オーナーシップを取れる構造になっていない組織 では、これらを導入しても機能しません。
データメッシュも思想としては素晴らしくても、現実を考えたらただの理想に過ぎないということです。
「適切なサイズ」がカギになる
では、オーナーシップが機能する組織のサイズとは、どれくらいでしょうか。
参考になる概念が2つあります。
ダンバー数(約150人) :人間が顔と名前と関係性を把握できる上限です。これを超えた瞬間、組織は「人間関係」ではなく「ルールと制度」で動かざるを得なくなります。
Amazonの2ピザチーム(6〜10人) :ピザ2枚で全員が食べられるサイズ。このサイズなら、ゴミデータを入れたら自分に跳ね返る。入力者と利用者の距離が近いため、コストとベネフィットの非対称性が解消されます。
分割の単位は、組織図ではなく ビジネスケイパビリティ(何の仕事をしてるか) で切るのが効果的です。「この仕事を完結させるのに必要な情報とプロセスを持った最小ユニット」を1つの単位とし、それぞれにデータプロダクトオーナーを置く。
全社統一の「データ管理部」を1つ作るより、100チームに100人の責任者がいる状態の方が、はるかに機能すると考えられます。
現実的にできるかどうかは差し置いて・・・。
考察:では大企業はどう変わればよいか
組織構造への提言
ここまでの検証を踏まえると、私の考えはこんな感じです。
AIデータ活用を機能させるには、技術導入の前に「責任者を明示し、大きすぎない単位に分割する」という組織設計が必要
具体的には、次の3点です。
1. 責任者・意思決定者を明示する
「データの品質に責任を持つ人」が誰なのかを、曖昧にしない。部署名ではなく、名前のある個人に紐づけることが重要です。
よくあるのが、「このデータの管理責任は○○部にあります」という状態。部署に責任を持たせた瞬間、誰も自分ごとにはなりません。複数人が責任者になっているケースも同様です。共同利用しているデータだからと、責任者が5人いるというのもNG。
また、責任者というと課長や部長、事業部長など偉い人を据えたがります。でも、実際それでは機能しません。責任者とは「このデータが間違っていたとき、自分が困る人」です。その人を名前で指名する。それだけで、データの品質は変わります。
2. 大きすぎない組織に分割する
ダンバー数を超えた均質な大集団では、責任の所在が曖昧になります。ビジネスケイパビリティごとに分割し、それぞれが自律的にデータを管理できる状態を目指します。
500人の部門に「ナレッジを整理して」と号令をかけても動きません。でも、8人のチームに「自分たちの業務に必要な情報を整理して」と伝えれば、自然と動き始めます。
大事なのは、分割の単位を「組織図」ではなく「仕事の完結単位」で切ること。営業部・企画部という箱ではなく、「この案件を回すために必要な情報とプロセスを持つ最小チーム」で考えるということです。
組織の分割思想を変えることになるので、非常に難易度は高いですが。
3. 組織図の変更ではなく、責任構造の変更
1も2も組織図を書き換えましょうという話ではありません。既存の組織の中で、この情報は誰が正しく保つ責任を持つのか、という 責任の所在を定義していく 作業です。
組織改編は大仕事ですし、政治的なハードルも高い。でも、「この情報の正本はAさんが持つ」「この定義についてはBさんが最終判断する」という責任の紐づけは、組織図を変えなくてもできます。
既存の組織図は変えないとしても、なるべく小さな単位でチームを区切りデータの責任者を据えていくことが、AI活用の大前提になっていくのではと思います。
構造変革の現実的な壁
正直に言えば、これを大企業の中から推進するのは非常に難しいと思っています。
- 事業部長は「うちの部を小さくしたくない」(権限縮小に見える)
- 情シスには分割の権限がない(技術はわかるが組織は触れない)
- 経営層は細かい話に興味がない(「AIで何かやって」で終わる)
つまり、 「誰がこの整理・分割をやるのか」に答えられる人が、大企業の中にほぼいない というのが実態です。
外部からの圧力(コンサルティング、規制対応、深刻なインシデント)がない限り、大企業が自発的にこの構造変革に踏み込むケースは少ないのが現実だと思います。
それでも、この構造変革なしに技術だけ導入しても同じ結果になる。ここは声を大にして言っておきたいポイントです。
現実的な導入パターン:4ステージアプローチ
とはいえ、こんな理想論だけでは前に進まないこともわかっています。なので、現実的に着手できるアプローチとして、4つのステージを考えてみました。

Stage 1:島を作る
特定のチーム(5〜15人)で、限定ドメインのナレッジを構造化します。全社展開は考えない。「このチームでは機能する」という状態を、まず1つ作ることが目的です。
技術はシンプルに。社内LLM APIとベクトルDBがあれば十分です。権限管理は既存のActive Directoryに乗せます。
ポイントは、 この段階で「誰がデータの責任者か」を必ず決めること です。島の中にオーナーを置く。技術的に完璧である必要はないけれど、責任構造だけは最初から入れておく。これがないと、Stage 2に進んだ途端に崩壊します。
成功の定義もシンプルにしましょう。「チーム内の情報検索にかかる時間が減った」「同じ質問が繰り返されなくなった」。このレベルで十分です。
Stage 2:島同士をつなぐ
成功した島を2〜3個つないで、横断検索を実現します。ここで初めて「同じ言葉の定義が違う」問題に本格的にぶつかります。
たとえば、営業チームの「受注」と経理チームの「受注」は、タイミングも定義も違う。これを統一しようとすると永遠に終わらない。
全社統一スキーマを先に作ろうとすると詰みます。島ごとの語彙をマッピングする「翻訳層」を作るほうが現実的です。各チームのデータ定義はそのまま残し、チーム間をつなぐ部分だけ共通語を最小限で合意する。
最大の罠は「全社統一スキーマを先に作ろう」とすること。これをやると、Stage 2で何年も止まります。
Stage 3:統制レイヤーをかぶせる
権限制御・監査ログ・データリネージュを本格実装します。ここまで来て初めて「エンタープライズRAG」と呼べるものになります。
具体的には以下のような要件が入ってきます。
- 誰がどのデータにアクセスできるかの制御(部署・役職・案件単位)
- 「AIがこの回答を出した根拠はどのデータか」を追跡できるログ
- データの更新履歴と出所の管理(リネージュ)
Stage 1・2で実績を作っているからこそ、ここでの投資判断の根拠になります。いきなりこのStageから始めると、要件が膨らみすぎて動けなくなるので注意が必要です。
Stage 4:自律的に進化する仕組み
AIによる定期的な矛盾検出・陳腐化検知・欠損補完を自動化します。Karpathyが個人のwikiでやっていた「linting」を、組織レベルで実現するステージです。
たとえば、「この文書は6ヶ月更新されていません。関連する文書は3件更新されています。確認が必要ではありませんか?」とAIが自動で検知・通知する。人間がやっていた鮮度管理をAIが担うことで、運用崩壊ループから脱却する仕組みです。
「情報が勝手にきれいになる組織」。ここまで到達できれば、それ自体が競争優位になります。
最大の失敗パターンは、Stage 1を飛ばしていきなりStage 3から始めることです。「まず統制を整えてから」という発想は一見正しそうに見えますが、実績も実感もない状態でガバナンスだけ先に作ると、現場は「また使えない仕組みが降ってきた」と感じます。
まとめ
この記事では、「mdベースのナレッジ管理は小さいから成立するのではないか」という仮説を立て、大企業の現場目線で検証しました。
振り返ると、次のような構造が見えてきます。
- mdベースのナレッジ管理が機能する前提は「作る人=使う人=直す人」「文脈が一義的」「SSOTが自然に成立する」の3つ
- 大企業ではこの3つの前提がすべて崩れる。ゴミデータ、文脈の多義性、運用崩壊ループが発生する
- 根本的なボトルネックは技術ではなく、 組織の意思決定構造 にある
- 構造変革(責任者の明示・適切なサイズへの分割)が先で、技術導入はその後
- 現実的にはStage 1「島を作る」から始めて、段階的に広げていくアプローチが有効
大事なのは、技術を導入することではなく、 技術が機能する構造を先に作ること です。
みなさんの組織では、「このデータの品質に責任を持つ人」は誰ですか? その人は、実際に機能していますか?
この問いに即答できないとしたら、技術導入の前にやることがあるかもしれません。
そして、この問いが「経営課題」として認識されない限り、どんな技術を導入しても、また同じ結果になるかもしれません。
おまけ:NGパターン
NG① いきなり全社統一基盤を作ろうとする
「全社で使えるAIナレッジ基盤を作ろう」。経営層からこの号令が出ること、ありますよね。
各部署の「うちの要件」が際限なく出てきて、誰も合意できないまま時間だけが過ぎる。
営業部は「顧客情報を検索したい」。法務は「契約書のナレッジを管理したい」。人事は「社内制度のFAQを自動化したい」。全部正しい要件ですが、全部を1つの基盤で満たそうとした瞬間、要件定義は永遠に終わりません。
要件が膨らむ → スコープが決まらない → ベンダー選定が進まない → 半年経っても何も動いていない。このパターン、大企業のIT企画では「あるある」ではないでしょうか。
Stage 1(島作り)から始めましょう。「全社で使える」を捨てて、「このチームで回る」を先に証明する。1つの成功事例を作ることが、全社展開への最短ルートです。
NG② 技術導入で組織構造の問題を解こうとする
「まずはRAG基盤を導入しましょう」。ベンダーやコンサルからこう提案されるケースも多い。
RAG基盤を入れた。しかし、データが汚い。古い。重複だらけ。精度が出ない。
「やっぱりAIは使えないね」という結論になり、投資が無駄に終わる。
これは技術の問題でしょうか? そうではありません。AIの精度は入力データの品質に依存します。そしてデータの品質は、データに責任を持つ人が明確かどうかに依存します。
つまり、 「AIの精度が低い」の根っこには「データの責任者が不在」という組織の問題がある ということです。
技術導入の前に、データの責任者と意思決定者を明示しましょう。小さいユニットに分割して、責任を持てる状態を先に作る。RAGの導入はそのあとです。
NG③ 仕組みを作って「あとは運用してね」で終わる
プロジェクトとして仕組みを構築し、リリース完了。「あとは各部署で運用してください」。
システム開発のプロジェクトでは当たり前の流れですが、AIを使ったナレッジ管理ではこれが致命的です。
半年後には誰もデータを更新していない。ゴミデータが溜まり、検索結果が使い物にならなくなる。「あの仕組み、今誰か使ってる?」と聞くと、誰も答えられない。
なぜこうなるか。ナレッジの入力は「誰かの本来業務の合間にやる作業」であり、やらなくても目の前の仕事には困らないからです。仕組みの利用が義務化されていない限り、人は楽な方に流れます。
「人間が運用する前提」で設計する限り、この問題は構造的に解決しません。AIによるゴミ検知・鮮度チェック・欠損補完の仕組みを、最初から設計に組み込むこと。「人が頑張る」ではなく「仕組みが回る」設計にすることが重要です。
関連記事