概要
AWSを利用したデータ集積・集計の流れでよくあるパターンの1つとしては、
Jsonデータ -> AWS IoT -> Kinesis Streams -> Kinesis Firehose -> S3 -> Glue -> Athena -> BIツール
というのがよくあるかと思います。
内容が古いので更新中
内容が古いので更新中
内容が古いので更新中
内容が古いので更新中
データ入り口
Jsonデータ -> AWS IoT -> Kinesis Stream としていますが、他にも
Jsonデータ -> API Gateway -> Kinesis Stream
ログ -> Fluentd -> Kinesis Stream
非Jsonデータ -> AWS IoT(API Gateway) -> Lambda(Json変換) -> Kinesis Stream
など沢山あるかと思います。
(場合によっては、kinesis Streamsを使用せずに直接Kinesis Firehoseに保存するのもありかと思います)
データ保存
Kinesis Firehose -> S3(gzip圧縮など)
集計・可視化
GlueのCrawlerでパーティション作成 -> AthenaでSQL実行 -> BIツール(QuickSight etc)で可視化
この構成の課題
以下の「Amazon Athena のパフォーマンスチューニング Tips トップ 10」でも書いてありますが、
https://aws.amazon.com/jp/blogs/news/top-10-performance-tuning-tips-for-amazon-athena/
「Athena の場合は、デフォルトでデータ圧縮が行われ、かつ分割可能な Apache Parquet や Apache ORC といったファイルフォーマットの利用をおすすめします」
本当はParquetを使いたいのに、Firehoseが対応していないから、生データをgzipなどで圧縮するといった運用が多かったと思います。
もしくは、どうしてもParquetが必要な場合は、GlueのETLジョブを使ってParquet変換を行ったり、EMRを使ったりなどありますが、割りとめんどくさいことが多いです。
このアップデートでFirehoseの機能でParquet変換ができるようになったので、さっそく試してみたいと思います。
ドキュメント
- https://aws.amazon.com/jp/about-aws/whats-new/2018/05/stream_real_time_data_in_apache_parquet_or_orc_format_using_firehose/
- https://docs.aws.amazon.com/firehose/latest/dev/record-format-conversion.html
手順
1. Kinesis FirehoseへのJSONデータ保存
この部分は今回の検証の本質ではないので、大きく省略しています。
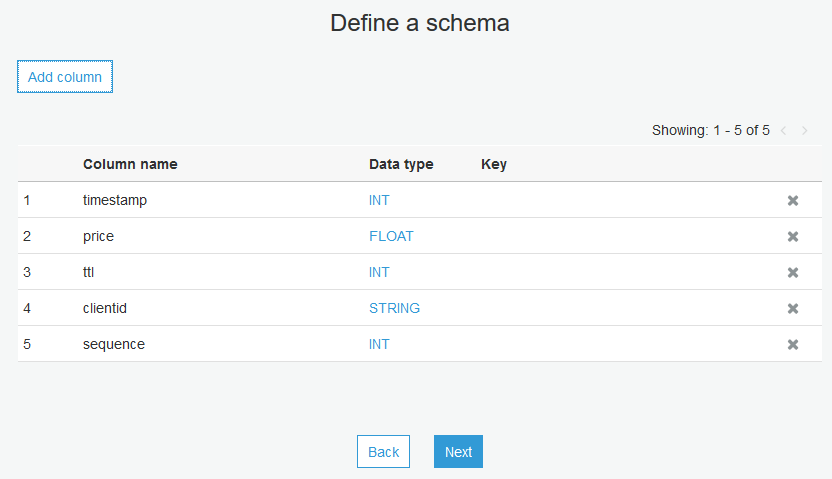
{"timestamp": 1528156109, "price": 0.067, "ttl": 1528192109, "clientid": "device1", "sequence": 2}
上記のフォーマットのJSONを毎秒 AWS IoTに送って、rule actionでKinesis Firehoseへ保存するようにしています。(timestampはデータ作成時のcurrent unixtime, priceはとあるspot instanceの価格-あまり変動しない-、ttlは10時間後のunixtime、clientidはAWS IoTのthingsのclient id)
別の検証で作ったのを使いまわしただけなので、要はJSON形式のデータがKinesis Firehoseへ入ればなんでもいいです。
2. GlueでParquet保存用のテーブルを手動作成
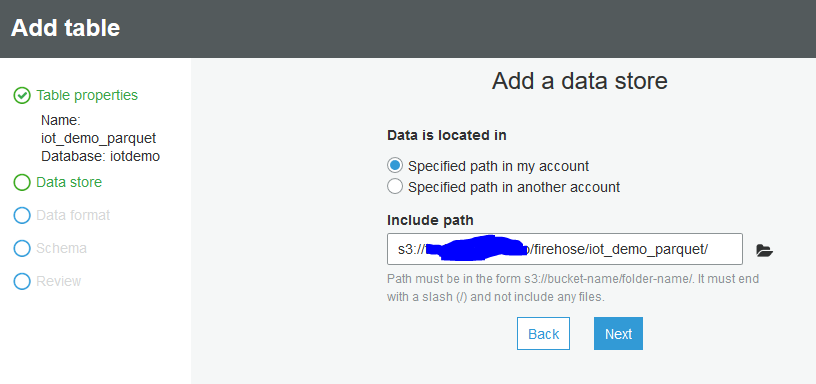
データの保存先を指定
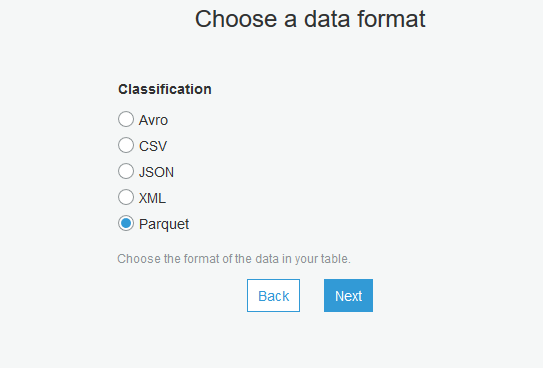
Parquetを選択
スキーマを定義
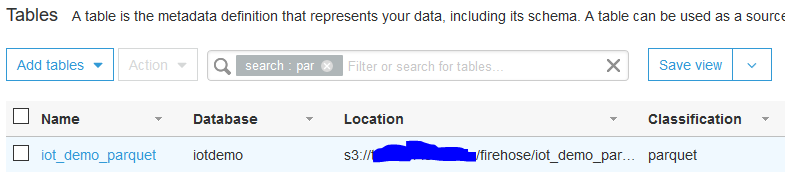
一応確認
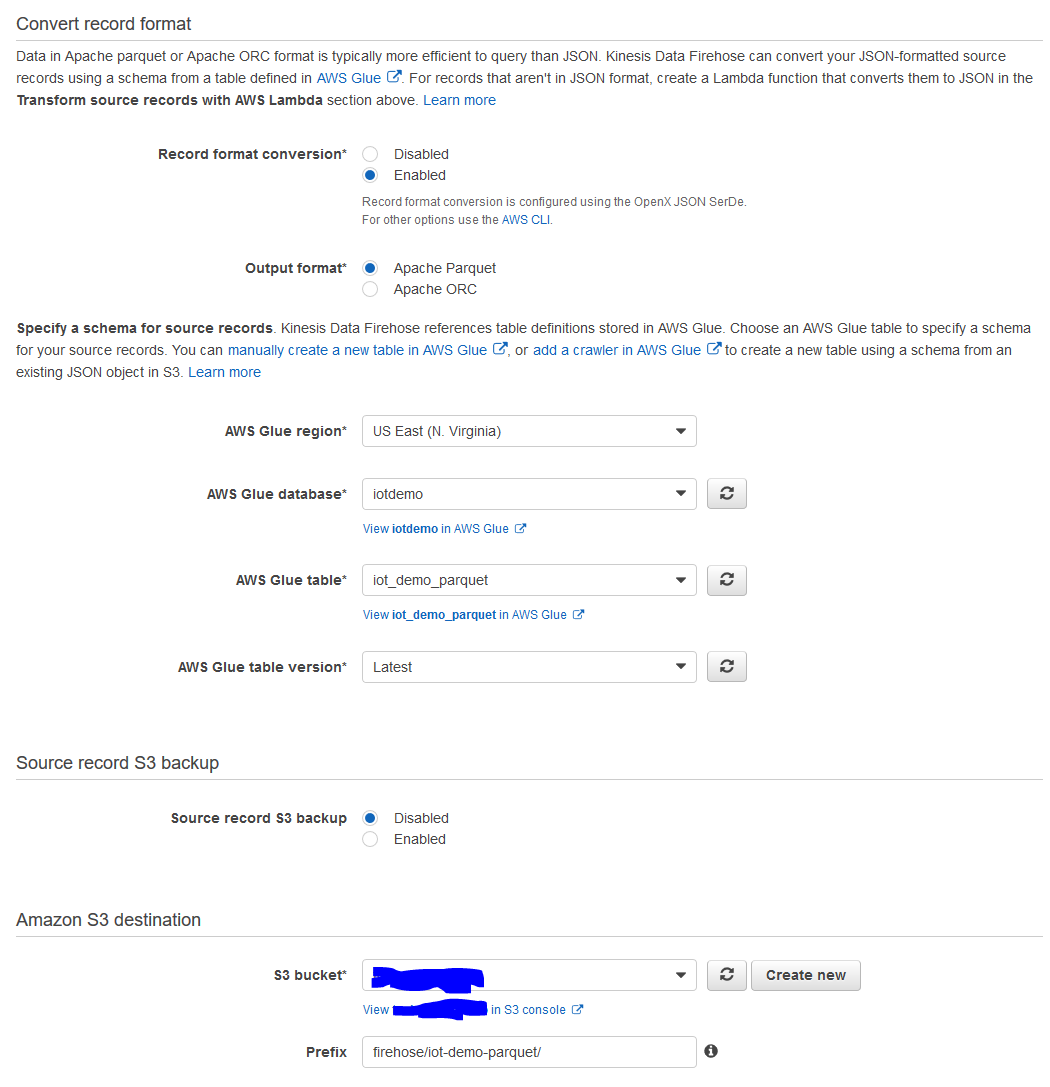
3. Firehoseの設定でParquet変換を実行
「Convert record format」の部分を以下のように変更しました
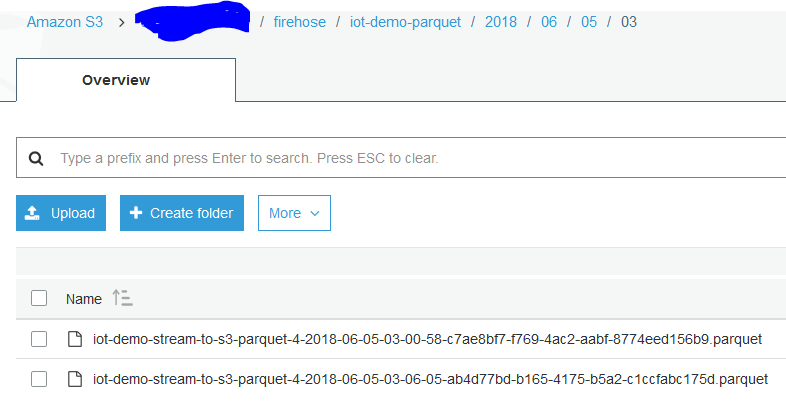
4. しばらく待ってs3へデータが保存されていることを確認
5. Glue-crawlerの設定
パーティションを作成するために、Glue上でcrawlerの設定を行う
以下はパラメータ
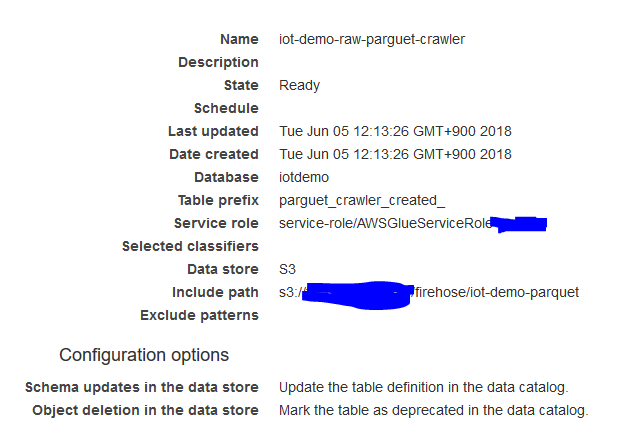
実行間隔はon demandにしていますが、例えば毎日集計等を行う場合は、毎日かつ集計が始まる前にクローリングが終わるようにスケジュールの設定を行う
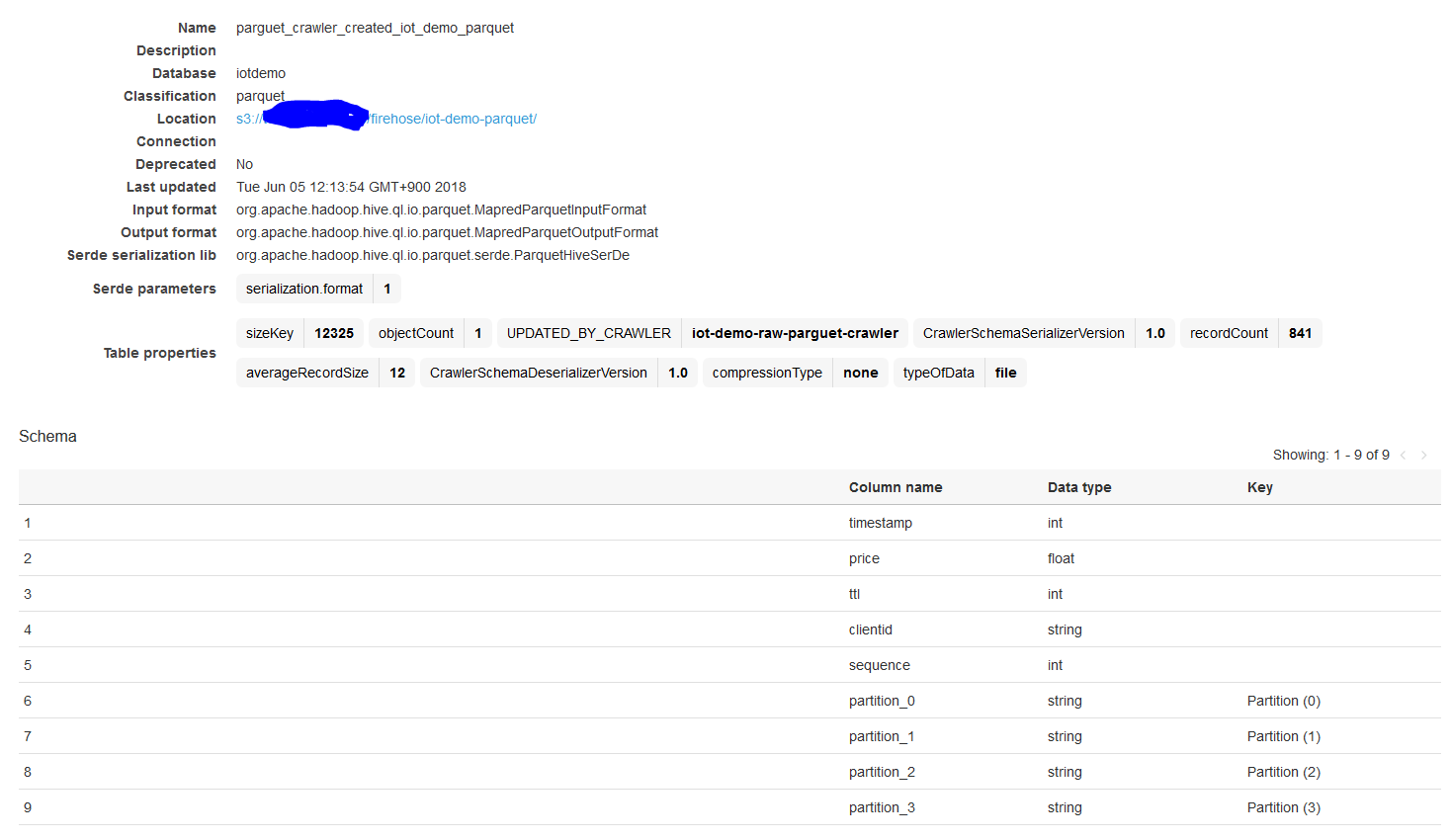
6. 作成されたテーブルの確認
こんな感じで作成されました
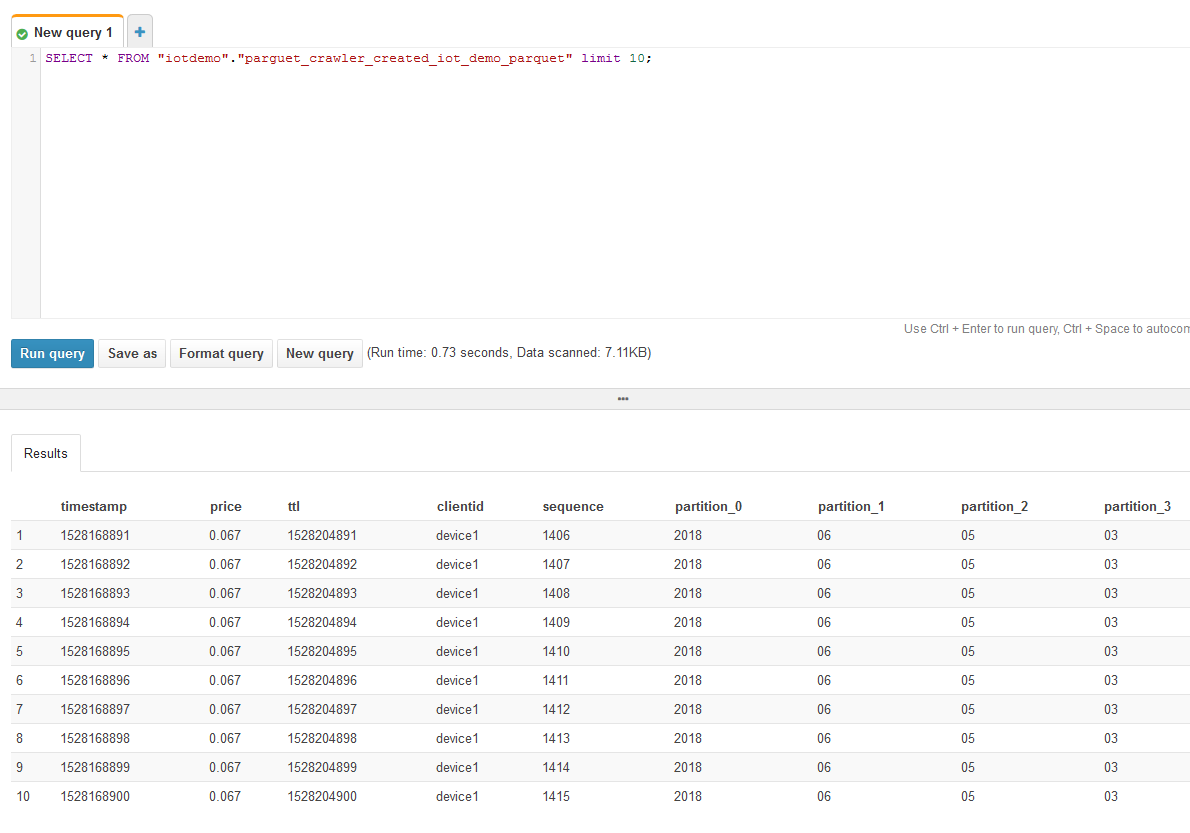
7. Athenaでクエリ実行
select * かつ、パーティション使ってないので、Parquet + パーティション化の恩恵はないクエリですが、通常業務で使うクエリだと大分効果が期待できるのではないでしょうか。
考察と課題
冒頭に記載したベストプラクティスである、Parquet(or ORC)を使うかつパーティション化を満たした上で簡単にAthenaを利用することができます。
ただ若干の懸念としては、Crawlerが走ったあとにそのデータはAthenaで使えるようになるので、例えば日時でクローラーを動かす場合は、クエリ結果は最長24時間前からのデータは反映されていないことになります。設定上最短で5分間隔でクローリングできるようですが、短すぎるのはGlueの利用料が増加するのでやめたほうがいいかもしれません。このあたりのチューニングは、欲しいデータの鮮度とGlue料金のバランスを取る必要がありそうですね。
もう一つの懸念(というほどのものではないですが) 時間単位でパーティションが作成されてしまうことです。YYYY/MM/DD/HH のフォーマットでfirehoseからデータが吐かれるので仕方ないのですが、実際時間でパーティションを区切ることはあまりないかもしれません。デフォルトの制限で、1テーブルにつき、20,000までなんどで、毎時間パーティション作ってると、2-3年で上限に達するので、上限緩和申請が必要になります。
概要ですが、上記の課題「リアルタイムにより近く」「パーティションの数を減らす」の解決方法も記載します。
改善概要(概要だけにとどめます) (上記の手順5から分岐します)
5. Lambdaを作成し、s3へputされたParquetファイルをhive 形式で保存し直す
FirehoseからS3へデータが保存(PUT)されるのをトリガーにLambdaを呼び出し、
/year=2018/month=06/day=03/xxxxxxxxxx.parquet
といったkey名でファイルを新規PUTする。
(これを利用すれば、例えば日本時間でディレクトリ構造を作成することも可能です)
6. Athenaから手動でテーブルを作成
(参考URL)
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partitions.html#scenario-1-data-already-partitioned-and-stored-on-s3-in-hive-format
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-online-seminar-2017-amazon-athena/27
7. 定期的に(or クエリ実行前に) MSCK REPAIR TABLEを実行する
https://www.slideshare.net/AmazonWebServicesJapan/amazon-athena/19
実行時間は事前検証で把握しておく必要あり
8. Athenaでクエリを発行
考察
この方法だと、Glueのcrawlerは使用していないですが、その代わりMSCK REPAIRをその都度実行して新規データをパーティションに追加する必要があります。
その他の方法だと、同じページに記載されていますが、ずっと先の期間までALTER TABLE ADD PARTITIONする方法があります。
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-online-seminar-2017-amazon-athena/27
まとめ
目的は単純で「Parquetかつパーティション化されているデータをいかに簡単に作成して、Athenaで利用するか」ですが、最も単純な方法は前半に紹介した方法だと思います。データの鮮度は欲しい(今入ったデータはすぐにクエリ対象にしたい)といったケースだと、後半に記載した情報になるのではないでしょうか?
余談
s3へのPUTをトリガーにLambdaを起動させるパターンですが、極稀にLambdaが起動しない場合があるのでご注意を。一応頻度は検証してみましたが、100万回やっても全部Lambda起動しました。
https://qiita.com/asahi0301/items/a88760dd38fe0f5fcee1