中学生でもわかる生成AI
LLM(大規模言語モデル)は、人間のように言葉を理解し、考え、文章を作る人工知能です。その中核には「ニューラルネットワーク」と呼ばれる仕組みがあり、これは人間の脳の神経細胞(ニューロン)をまねた構造です。多くのニューロンが層になって情報を伝え合い、小さな計算を積み重ねながら複雑な判断を行います。各ニューロンは入力を受け取り、重みをかけて次の層に出力します。これを何億回も繰り返すことで、LLMは単語の意味や文の構造、文脈の流れを深く理解できるようになります。学習の方法は、人間が読書や会話から言葉を覚えるのと似ています。LLMはインターネット上の膨大な文章を読み込み、言葉の並び方や使われ方の規則を統計的に学習します。たとえば「今日はとても」と入力されたとき、そのあとに「暑い」「寒い」などどんな言葉が続くかを確率的に予測します。この「次に来る言葉を予想する」作業を何兆回もくり返すことで、自然で一貫した文章を作り出せるようになるのです。このとき、言葉はすべて数の並び(ベクトル)として扱われます。似た意味の言葉は数の空間で近い位置に配置されるため、LLMは「意味の近さ」や「関係性」を数学的に扱えます。たとえば、「猫」と「犬」は近く、「空」と「勉強」は遠くに位置します。こうした数値表現によって、言葉の意味を数の世界で理解できるようになるのです。LLMの中心構造は「トランスフォーマー」と呼ばれ、その中で最も重要な役割を果たすのが「アテンション(Attention)」です。これは文の中でどの言葉に注目すべきかを判断する仕組みで、いわば“注目の目”のようなものです。たとえば「りんごを食べた。おいしかった。」という文では、「おいしかった」を理解する際に「りんご」に注意を向けます。こうした関連付けを多層的に行うことで、モデルは単語の関係だけでなく、文全体の意味や話の流れも理解できるようになります。近年では、LLMは言葉だけでなく画像・音声・動画なども理解できるようになり、「マルチモーダルAI」へと進化しています。これにより、写真を見て説明したり、音声を文字に変換したり、グラフを読み取って分析することも可能です。言語、視覚、聴覚といった異なる情報を統合することで、AIは人間により近い形で世界を理解できるようになりました。つまり、LLMとは、ニューラルネットワークが情報を処理し、トランスフォーマーが文脈を読み解き、マルチモーダル技術によって「見る・聞く・話す」力を獲得した、言葉を中心とする人工の知能システムです。その結果、AIは文章の生成だけでなく、翻訳、要約、画像認識、対話など、多様な場面で活用されるようになっています。
生成AIと数学
【中学数学と生成AI】
| 分野 | 代表トピック | 対応するAI直感 |
|---|---|---|
| 数と式 | 四則演算・文字式・連立方程式・比例反比例 | ニューラル計算(y=w·x+b) |
| 関数 | 一次関数・二次関数・変化の割合 | 活性化関数の入出力変化 |
| 図形・座標 | 距離・角度・位置 | 画像ピクセル・最近傍探索 |
| 確率 | 事象・期待値 | トークン確率・乱数生成 |
| 統計 | 平均・分散 | 誤差・損失関数の直感 |
【高校数学と生成AI】
| 分野 | 代表トピック | 対応するAI直感 |
|---|---|---|
| 微分・積分 | 勾配・極値・面積 | 勾配降下法・最適化 |
| 三角関数 | 周期・位相・合成 | 波・フーリエ基礎 |
| 指数・対数 | e・log・単調性 | softmax・確率対数損失 |
| ベクトル | 内積・角度 | 類似度・Attention |
| 行列・線形変換 | 行列積・写像 | 層計算(W x+b) |
| 複素数 | オイラーの直感 | FFT・位相回転 |
| 確率・統計 | 分布・分散・標準偏差 | 信頼度・誤差解析 |
【大学数学と生成AI】
| 分野 | 代表トピック | 対応するAI直感 |
|---|---|---|
| 線形代数 | PCA・SVD・固有分解 | 埋め込み・特徴抽出 |
| 微分積分学 | 偏微分・ヘッセ行列 | 二次近似・収束解析 |
| 最適化理論 | 凸最適化・KKT | 正則化・Adam |
| 確率・統計学 | ベイズ・マルコフ過程 | 生成確率モデル(VAE/GAN) |
| 情報理論 | エントロピー・KL | 損失・知識蒸留 |
| フーリエ解析 | FFT・畳み込み定理 | 画像・音声の周波数処理 |
| 学習理論 | 汎化境界・交差検証 | モデル選択・正則化評価 |
| 数値解析 | 安定性・誤差伝播 | 勾配爆発・スケーリング |
| 確率微分方程式 | 拡散過程・逆拡散 | Diffusionモデル基礎 |
【学習ロードマップ】
- 中学:比例・一次関数・確率
- 高校:微分・ベクトル・行列・三角関数・指数対数
- 大学:線形代数 → 最適化 → 確率統計 → 情報理論 → フーリエ → 数値解析 → 拡散確率モデル
【代表AI要素対応】
- 言語生成:確率+線形代数+情報理論
- 画像生成:フーリエ+拡散過程
- 最適化・学習:微分+凸最適化+正則化
プロンプトエンジニアリングの極意
1. 原理:AIは「確率で考える」
生成AI(LLM: Large Language Model)は、入力文脈に基づき「次に来る単語の確率」を推定する確率関数です。
数学的には:
P(token_t | context) = softmax(W · h_t / T)
-
h_t: これまでの文脈(単語列)のベクトル表現 -
W: モデル内部の重み行列 -
T: 温度パラメータ(確率分布の鋭さを制御)
この分布からサンプリングして次の単語を生成する。
したがって、プロンプトとはこの確率分布の形状を間接的に変える入力ベクトルである。
つまり:
「AIが“何を連想し、どの方向に思考を進めるか”を決める装置」
2. 極意① 明確・具体・構造化
AIは確率的に曖昧さを平均化する。
曖昧な指示は「確率の和」で潰れてしまう。
したがってプロンプトは「明確に・具体的に・構造的に」設計する。
✕ 悪い例
生成AIについて教えて。
→ 「歴史」「仕組み」「倫理」など、確率的に分散。
結果:焦点がぼやけ、表現が平均的になる。
〇 良い例
あなたは高校生に授業するAI講師です。
目的:生成AIの仕組みを3段階(概要→原理→応用)で説明。
条件:専門語は避け、数式は1つ使う。
→ 指示が具体的なため、確率分布が特定方向に収束。
結果:一貫した構造・安定した表現を生成。
**数理的には「入力ベクトルの次元削減+方向固定」**に相当する。
3. 極意② 段階分解(Chain of Thought)
人間の推論も「定義→式→例→結論」という段階構造を持つ。
AIも同様に「思考手順」を明示すると推論の安定性が増す。
実践例
① 生成AIとは何か
② どのように動作するか(数式を1つ使う)
③ どのように応用されているか
LLM内部のAttention構造は「トークン間の重み付け」であるため、
段階を与えることで、Attentionの経路が分離し、
「文脈の飽和」や「思考の飛躍」を防げる。
これが「思考の鎖を作る=Chain of Thought(CoT)」の原理。
4. 極意③ 確率制御パラメータ(Temperature・Top-p・Top-k)
生成AIは「確率で文章を組み立てる」ため、
その分布を数値で制御することができる。
| モード | Temperature | Top-p | 出力傾向 |
|---|---|---|---|
| 正確・論理的 | 0.2〜0.4 | 0.8 | 教科書的・再現性が高い |
| 自然・柔軟 | 0.6〜0.8 | 0.9 | 会話・要約・教材向き |
| 創造・自由 | 1.0〜1.2 | 1.0 | 比喩・創作・発想向き |
例:同じ質問でも温度で人格が変わる
-
T=0.3 →
「生成AIは大量のデータを学習し、確率的に新しい文章を作る技術です。」 -
T=1.0 →
「生成AIは、人間の“創造の確率”を再現する人工の想像装置です。」
→ どちらも正しいが、温度で文体・表現の確率分布が変わる。
5. 極意④ 出力フォーマットを拘束する
AIは自由に出すと確率空間が広がり、再現性が下がる。
出力形式を固定すれば、探索空間が縮小し安定する。
出力形式:
1. 定義(1文)
2. 仕組み(数式を含む)
3. 応用(箇条書き3点)
→ 出力テンプレートを与えることで、AI内部の確率探索が「制約付き最適化」へ変わる。
これは条件付きエントロピーの削減に等しい。
6. 極意⑤ few-shot と meta-prompt
few-shot(例示学習)
いくつかの入出力例を与えると、モデル内部の条件付き確率が補正される。
例1:入力:猫とは? → 出力:哺乳類の一種で、人に親しまれている動物。
例2:入力:犬とは? → 出力:哺乳類の一種で、人間の伴侶として飼われる動物。
次の入力:生成AIとは?
→ LLMは確率的に「説明文の型」を再利用し、模倣的に安定した出力をする。
meta-prompt(思考方針指定)
あなたは常に「定義→原理→数式→応用→まとめ」の順に考えるAIです。
テーマ:生成AI
→ LLMのAttention初期化ベクトルを固定化するような効果。
出力分布の初期勾配方向を人間が定義することになる。
7 LLMのパラメータ
大規模言語モデル(LLM)は、確率分布の形・出力の一貫性・創造性を数値で制御できる。
以下は、プロンプトエンジニアリングで頻繁に調整される主要パラメータの一覧。
【主要パラメータ一覧】
| パラメータ名 | 典型範囲 | 効果・役割 |
|---|---|---|
| Temperature | 0.0〜2.0 | softmax出力の確率分布をスケーリング。低いほど決定的・高いほど創造的。 |
| Top-p(nucleus sampling) | 0.1〜1.0 | 累積確率p以内のトークンのみをサンプリング。小さい値で出力が安定。 |
| Top-k | 10〜100 | 確率上位k個のみを候補に残す。小さいほど保守的な出力。 |
| Max tokens | 128〜8192(モデル依存) | 生成する最大トークン数。文章の長さを制限。 |
| Presence penalty | −2.0〜+2.0 | 出現済みトークンを避ける度合い。高値で繰り返しが減る。 |
| Frequency penalty | −2.0〜+2.0 | 頻出語を抑制する度合い。高値で語彙多様性が増す。 |
| Stop sequence | 任意文字列 | 指定語や記号が出た時に出力を停止。構造化出力やJSON制御に使用。 |
| Seed | 整数値 | 乱数初期化値。固定すると同一プロンプトで再現可能。 |
【パラメータと出力傾向】
| 温度設定 | 出力傾向 | 主な用途 |
|---|---|---|
| T=0.2〜0.4 | 論理的・再現性が高い | 技術文書、教材、数式解説 |
| T=0.6〜0.8 | 自然で柔軟 | 対話、要約、翻訳 |
| T=1.0〜1.2 | 創造的・多様 | 詩、物語、発想補助 |
【Top-pとTop-kの関係】
-
Top-p は確率の“面積”で制限
→ 重要語だけを動的に選択 -
Top-k は候補数を“個数”で制限
→ 上位k語の中からランダムに選ぶ
→ 一般的に Top-p=0.9, Top-k=40 がバランス良い設定。
【ペナルティ設定の効果】
| パラメータ | 高値時の効果 | 低値時の効果 |
|---|---|---|
| Presence penalty | 繰り返しを強く抑制 | 一貫したトーンを維持 |
| Frequency penalty | 語彙の多様性が増す | 同義語の再利用が増える |
【Max tokensの運用】
| 用途 | 推奨値 | 備考 |
|---|---|---|
| 要約・短文生成 | 256〜512 | コンパクトに制限 |
| 一般説明文 | 512〜1024 | 標準的設定 |
| 技術記事・教材 | 1024〜2048 | 構造的出力用 |
| 長文論文・ストーリー | 2048〜4096 | モデル性能依存 |
【実践推奨セット】
| 目的 | Temperature | Top-p | Penalty群 | 備考 |
|---|---|---|---|---|
| 技術文書・論理説明 | 0.3 | 0.9 | α₁=0.2, α₂=0.1 | 再現性優先 |
| 教育・要約 | 0.6 | 0.9 | α₁=0.0, α₂=0.3 | 自然さ優先 |
| クリエイティブ生成 | 1.0 | 1.0 | α₁=0.5, α₂=0.8 | 創造性重視 |
生成AIでできること(汎用プロンプト集)
1. テキスト生成 / Text Generation
| 目的 | 汎用プロンプト例 |
|---|---|
| 要約 / Summarization | 要約して(短く / 詳しく / 英語で) |
| 翻訳 / Translation | 英語に翻訳して(専門用語を保持) |
| 言い換え / Rewriting | 専門的に / 高校生向けに / 論文調に言い換えて |
| 文書整形 / Formatting | Word / PowerPoint / Excel形式で出力して |
| 構造化 / Structuring | 章立てで整理して(第1章〜第4章) |
| 説明補足 / Clarification | 初心者にも分かるように詳しく説明して |
| 比較 / Comparison | AとBの違いを表でまとめて |
2. 教育・教材作成 / Education & Learning
| 目的 | 汎用プロンプト例 |
|---|---|
| カリキュラム設計 / Curriculum Design | ○○を学ぶためのカリキュラムを段階別に設計して |
| 講義ノート / Lecture Notes | ○○をQiita風の記事スタイルでまとめて |
| 練習問題作成 / Exercises | ○○分野の練習問題を10問作って(答えつき) |
| 例文生成 / Example Generation | ○○をテーマに例文を作って(英語+日本語) |
| 教材化 / Materialization | Wordに貼れる形式で教材を整形して |
| 学習表 / Learning Table | 概要・式・応用を3列の表にまとめて |
| スクリプト解説 / Code Explanation | コードに日本語と英語のコメントを追加して説明して |
3. 芸術・創作 / Creative Generation
| 目的 | 汎用プロンプト例 |
|---|---|
| 画像生成 / Image Generation | 写真を高画質のアニメ風に変換して |
| 3Dモデル設計 / 3D Modeling | 写実的な1/1スケールで再現して(リアルスタイル) |
| ストーリー生成 / Story Generation | ○○を題材に短編ストーリーを作って |
| 歌詞翻訳 / Lyrics Translation | 英語の歌詞を自然な日本語に翻訳して(感情を保って) |
| 対話スクリプト / Dialogue Script | 英語と日本語で対話形式の脚本を書いて |
| キャラクターデザイン / Character Prompt | ○○の特徴を持つキャラクター設定を作って |
| 世界観設計 / Worldbuilding | ○○の舞台設定・世界観を構築して(場所・文化・技術など) |
生成AIをPythonで作ろう ― 学習カリキュラム
第1章 生成AIの原理を理解しよう
到達目標
- 生成AIの基礎(確率・ベクトル・Attention)を数式で説明できる。
- ニューラルネットの入出力構造をPythonで理解・可視化できる。
理論解説
- 生成AIの基本構成
(1) Tokenizer(文字→整数)
(2) Embedding層(整数→ベクトル)
(3) モデル(線形結合+非線形変換)
(4) 出力(確率分布とサンプリング) - 確率生成の考え方
- 単語の出現確率 P(wᵢ|context)
- 尤度最大化 (Maximum Likelihood) - ニューラルネットの基本式
y = w*x + b - softmax関数と確率分布の正規化
実装テーマ
- 単語出現確率を辞書化して可視化
- 線形モデル y = w*x + b をNumPyで実装
- softmax(温度パラメータ付き)をプロット
演習課題
- softmax(β) の変化で出力確率を比較
- Embedding空間で単語間距離を算出
数学背景
- 線形代数(ベクトルと内積)
- 確率分布と正規化
- softmaxの指数変換と数値安定化
第2章 確率で文章を作ろう
到達目標
- 確率的生成とサンプリング手法を理解し、温度・Top-k/p操作を実装できる。
理論解説
- マルコフ連鎖による文字生成
P(xₙ | xₙ₋₁) の確率を利用 - Temperatureによる確率スケーリング
pᵢ = exp(log(pᵢ)/T) / Σ exp(log(pⱼ)/T) - Top-k, Top-pサンプリングによる創造性制御
実装テーマ
-
random.choices()を使った確率的文字生成 - 温度 T=0.2〜1.2 で文章比較
- Top-p (累積確率)とTop-k(上位k件)の違い
演習課題
- Tを動的に変化させた生成
- 固定語彙からランダム生成器を作成
数学背景
- 確率分布操作
- 指数関数・正規化
- ランダムサンプリング理論
第3章 ニューラルネットで学習させよう
到達目標
- 多層ニューラルネットの順伝播と誤差逆伝播を理解し、Pythonで実装できる。
理論解説
- 順伝播(Forward Propagation)
h₁ = f(W₁x + b₁), ŷ = f(W₂h₁ + b₂) - 活性化関数の役割
- ReLU, tanh, sigmoid の違い - 損失関数
L = -Σ y_true * log(y_pred) - 勾配降下法(Gradient Descent)
w ← w - η·∂L/∂w
実装テーマ
- NumPyでMLPを実装
- XOR分類を学習
- 損失関数の減少をグラフ化
演習課題
- 学習率 η の違いを可視化
- 初期値を変えて収束挙動を比較
数学背景
- 偏微分
- 行列積と勾配
- 学習曲線と最小化問題
第4章 ミニ生成モデルを作ろう
到達目標
- 時系列処理とRNNの再帰構造を理解し、文字列生成モデルを構築できる。
理論解説
- 時系列処理と状態遷移
hₜ = f(Wₕhₜ₋₁ + Wₓxₜ + b) - 勾配消失・爆発問題と対策
- 生成AIにおける系列モデリングの基礎
実装テーマ
- 簡易RNNをNumPyで構築
- 損失推移をmatplotlibで描画
- 学習済みモデルで文字列生成
演習課題
- 入力テキストを変更して生成比較
- hidden sizeの影響を観察
数学背景
- 再帰関数・線形代数
- 時系列データの処理理論
- 損失曲線の収束解析
第5章 AttentionとTransformerの入口
到達目標
- Self-AttentionとTransformerの構造・数式を理解し、数値実験で確認できる。
理論解説
- Attentionの定義
Attention(Q, K, V) = softmax(QKᵀ/√d)·V - 類似度(QKᵀ)の意味とスケーリング
- Encoder-Decoderの流れ
- Multi-Head Attentionの役割
実装テーマ
- NumPyでSelf-Attentionを実装
- 単語間重みを行列として描画
- Encoder→Decoderのフロー図生成
演習課題
- Attention weight の変化を確認
- 単語ベクトルの関連度を比較
数学背景
- ベクトル空間と内積
- 行列正規化・ソフトマックス
- 線形写像と重み平均
第6章 学習済みモデルを使ってみよう
到達目標
- LLM APIをPythonで操作し、プロンプトと出力を制御できる。
理論解説
- APIの仕組み(入力トークン→出力確率分布)
- TemperatureとTop-pの実践操作
- Few-shot Learning / Meta-prompt
実装テーマ
-
openai.ChatCompletion.create()を使った実験 - 同一質問で温度を変えて比較
- few-shotプロンプト実装
演習課題
- 出力文の多様性と一貫性の比較
- モデル間(GPT-3.5 vs GPT-4)で性能差分析
数学背景
- 確率重み付き平均
- 正規化分布とサンプリング理論
第7章 生成AIの数学と評価
到達目標
- 情報理論・確率・線形代数の統合的視点で生成AIを理解・評価できる。
理論解説
- 損失関数と情報量
交差エントロピー H(p,q) = -Σ p log q - KLダイバージェンス D_KL(p||q)
- Perplexity (困惑度) の解釈
- モデル評価の指標と可視化
実装テーマ
- KLダイバージェンスをPythonで計算
- Perplexityをデータセットで評価
- 損失曲線を時系列表示
演習課題
- モデルA/BのPerplexity比較
- 出力確率分布の視覚的分析
数学背景
- エントロピー・情報量
- ロジット変換と対数関数
- 統計的距離と尤度比
第8章 創造するAIへ
到達目標
- 生成AIを画像・音声・教育分野へ応用し、倫理・安全性の観点を理解する。
理論解説
- Diffusionモデルの原理
xₜ = √αₜx₀ + √(1−αₜ)ε - ノイズ除去と生成過程の逆拡散
- GAN・VAEとの比較
- 倫理・安全・バイアス制御
実装テーマ
- ノイズ除去シミュレーション
- GAN風サンプル生成
- 条件付き生成(prompt + constraint)
演習課題
- 自作データセットで学習・生成
- 出力の倫理的リスク評価
数学背景
- 確率過程(マルコフ連鎖・拡散方程式)
- ガウス分布と再パラメータ化
- 制約最適化問題
学習完了後のゴール
- LLMの確率・数理・構造を「Pythonで動かして理解」できる
- AttentionやDiffusionの基本式を手計算できる
- モデルの温度・確率操作を理論的に説明できる
- 自分の文章・データを使った生成実験ができる
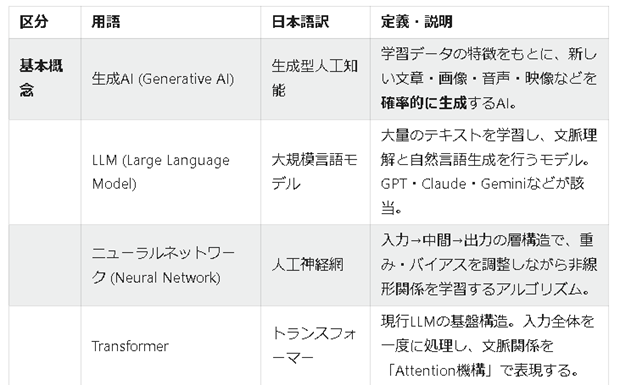
【生成AI 用語と定義一覧】
| 区分 | 用語 | 日本語訳 | 定義・説明 |
|---|---|---|---|
| 基本概念 | 生成AI (Generative AI) | 生成型人工知能 | 学習データの特徴をもとに、新しい文章・画像・音声・映像などを確率的に生成するAI。 |
| LLM (Large Language Model) | 大規模言語モデル | 大量のテキストを学習し、文脈理解と自然言語生成を行うモデル。GPT・Claude・Geminiなどが該当。 | |
| ニューラルネットワーク (Neural Network) | 人工神経網 | 入力→中間→出力の層構造で、重み・バイアスを調整しながら非線形関係を学習するアルゴリズム。 | |
| Transformer | トランスフォーマー | 現行LLMの基盤構造。入力全体を一度に処理し、文脈関係を「Attention機構」で表現する。 | |
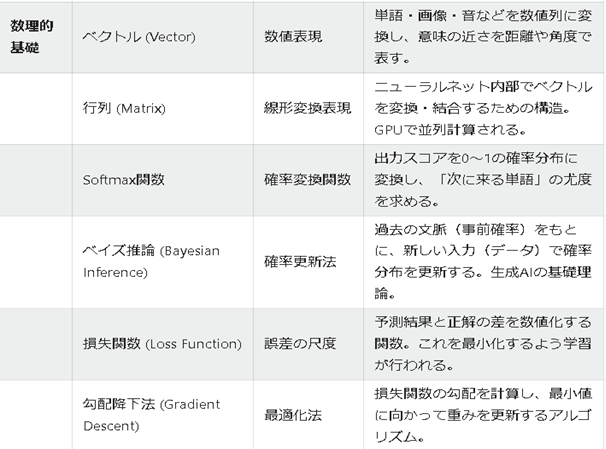
| 数理的基礎 | ベクトル (Vector) | 数値表現 | 単語・画像・音などを数値列に変換し、意味の近さを距離や角度で表す。 |
| 行列 (Matrix) | 線形変換表現 | ニューラルネット内部でベクトルを変換・結合するための構造。GPUで並列計算される。 | |
| Softmax関数 | 確率変換関数 | 出力スコアを0〜1の確率分布に変換し、「次に来る単語」の尤度を求める。 | |
| ベイズ推論 (Bayesian Inference) | 確率更新法 | 過去の文脈(事前確率)をもとに、新しい入力(データ)で確率分布を更新する。生成AIの基礎理論。 | |
| 損失関数 (Loss Function) | 誤差の尺度 | 予測結果と正解の差を数値化する関数。これを最小化するよう学習が行われる。 | |
| 勾配降下法 (Gradient Descent) | 最適化法 | 損失関数の勾配を計算し、最小値に向かって重みを更新するアルゴリズム。 | |
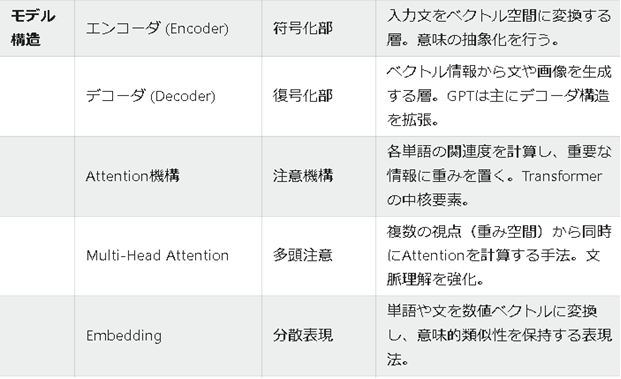
| モデル構造 | エンコーダ (Encoder) | 符号化部 | 入力文をベクトル空間に変換する層。意味の抽象化を行う。 |
| デコーダ (Decoder) | 復号化部 | ベクトル情報から文や画像を生成する層。GPTは主にデコーダ構造を拡張。 | |
| Attention機構 | 注意機構 | 各単語の関連度を計算し、重要な情報に重みを置く。Transformerの中核要素。 | |
| Multi-Head Attention | 多頭注意 | 複数の視点(重み空間)から同時にAttentionを計算する手法。文脈理解を強化。 | |
| Embedding | 分散表現 | 単語や文を数値ベクトルに変換し、意味的類似性を保持する表現法。 | |
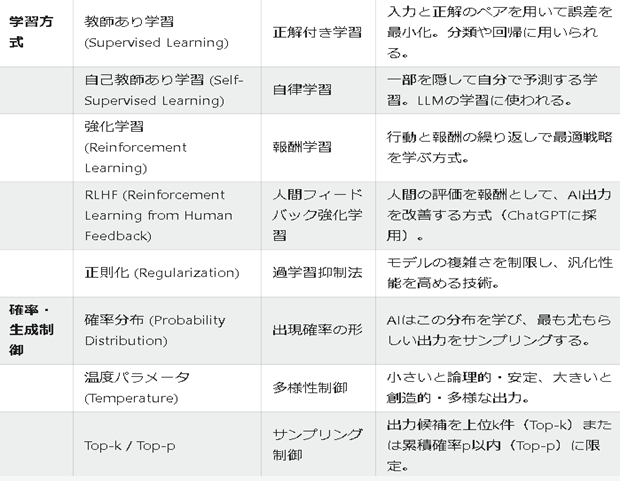
| 学習方式 | 教師あり学習 (Supervised Learning) | 正解付き学習 | 入力と正解のペアを用いて誤差を最小化。分類や回帰に用いられる。 |
| 自己教師あり学習 (Self-Supervised Learning) | 自律学習 | 一部を隠して自分で予測する学習。LLMの学習に使われる。 | |
| 強化学習 (Reinforcement Learning) | 報酬学習 | 行動と報酬の繰り返しで最適戦略を学ぶ方式。 | |
| RLHF (Reinforcement Learning from Human Feedback) | 人間フィードバック強化学習 | 人間の評価を報酬として、AI出力を改善する方式(ChatGPTに採用)。 | |
| 正則化 (Regularization) | 過学習抑制法 | モデルの複雑さを制限し、汎化性能を高める技術。 | |
| 確率・生成制御 | 確率分布 (Probability Distribution) | 出現確率の形 | AIはこの分布を学び、最も尤もらしい出力をサンプリングする。 |
| 温度パラメータ (Temperature) | 多様性制御 | 小さいと論理的・安定、大きいと創造的・多様な出力。 | |
| Top-k / Top-p | サンプリング制御 | 出力候補を上位k件(Top-k)または累積確率p以内(Top-p)に限定。 | |
| トークン (Token) | 言語単位 | モデルが処理する最小単位(単語・語片・文字)。 | |
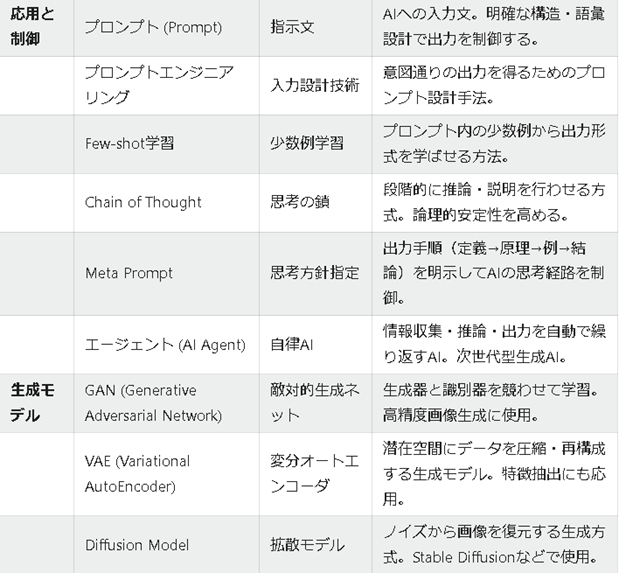
| 応用と制御 | プロンプト (Prompt) | 指示文 | AIへの入力文。明確な構造・語彙設計で出力を制御する。 |
| プロンプトエンジニアリング | 入力設計技術 | 意図通りの出力を得るためのプロンプト設計手法。 | |
| Few-shot学習 | 少数例学習 | プロンプト内の少数例から出力形式を学ばせる方法。 | |
| Chain of Thought | 思考の鎖 | 段階的に推論・説明を行わせる方式。論理的安定性を高める。 | |
| Meta Prompt | 思考方針指定 | 出力手順(定義→原理→例→結論)を明示してAIの思考経路を制御。 | |
| エージェント (AI Agent) | 自律AI | 情報収集・推論・出力を自動で繰り返すAI。次世代型生成AI。 | |
| 生成モデル | GAN (Generative Adversarial Network) | 敵対的生成ネット | 生成器と識別器を競わせて学習。高精度画像生成に使用。 |
| VAE (Variational AutoEncoder) | 変分オートエンコーダ | 潜在空間にデータを圧縮・再構成する生成モデル。特徴抽出にも応用。 | |
| Diffusion Model | 拡散モデル | ノイズから画像を復元する生成方式。Stable Diffusionなどで使用。 | |
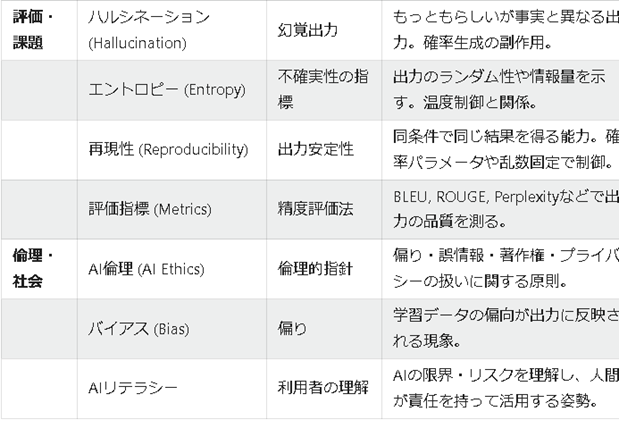
| 評価・課題 | ハルシネーション (Hallucination) | 幻覚出力 | もっともらしいが事実と異なる出力。確率生成の副作用。 |
| エントロピー (Entropy) | 不確実性の指標 | 出力のランダム性や情報量を示す。温度制御と関係。 | |
| 再現性 (Reproducibility) | 出力安定性 | 同条件で同じ結果を得る能力。確率パラメータや乱数固定で制御。 | |
| 評価指標 (Metrics) | 精度評価法 | BLEU, ROUGE, Perplexityなどで出力の品質を測る。 | |
| 倫理・社会 | AI倫理 (AI Ethics) | 倫理的指針 | 偏り・誤情報・著作権・プライバシーの扱いに関する原則。 |
| バイアス (Bias) | 偏り | 学習データの偏向が出力に反映される現象。 | |
| AIリテラシー | 利用者の理解 | AIの限界・リスクを理解し、人間が責任を持って活用する姿勢。 |