前回 学習データをTFRecordにした話 : TensorFlow将棋ソフト開発日誌 #12
目次 TensorFlow将棋ソフト開発日誌 目次
ソースはgithubにあります(俺が読めればいいというレベル)
目次
- モデルをYAMLからpythonソースの動的インポートにした
- Pythonの動的モジュールインポートを使用してネットワークモデルを読み込む
- 最近使っている勝敗予測モデル
- 学習してみた
- まとめ
モデルをYAMLからpythonソースの動的インポートにした
いままではニューラルネットワークのモデルをYAMLで記述していました(#4 参照)。
YAMLを使う利点
- ネットワークモデルとプログラムが分離でき複数のモデルをリポジトリに突っ込んでも違和感がない
- ネットワークモデルは手続きというよりは構造であるためデータ記述言語の方が相性が良い
YAMLを使う欠点
- 同じような構造を繰り返し書くのが面倒くさい
- YAMLはアンカーで記述を省略できるがマクロとしてはまだ弱い
- それでも他のマークアップ言語よりは便利だが・・・
- 新しいレイヤーを導入する度にパーサ側に対応するクラスを追加する必要がある
- イケてるフォーマット(Kerasのように直前の出力名を省略して入力にできるとか)を作るにはパーサを作る側のセンスが必要
ここのところHighwayNetなどを試していてYAMLでモデルを記述する欠点の方が目立ってきました。そのため別の形式でモデルを記述することにしました。
ちなみにYAMLを使うディープラーニングフレームワークとしてneonというのを見つけました。ただし基本的には保存ファイル形式で記述はコードでするようですが。
Pythonの動的モジュールインポートを使用してネットワークモデルを読み込む
ネットワークモデルの記述とプログラムを分離したい、つまりコマンドラインオプションなどで使用するモデルを動的に切り替えたい。ただし複雑なモデルでもストレスなくコーディングしたい。
これをサクッと達成するためにPythonの動的importを使用することにしました。モデルは普通にPythonコードで記述してプログラム実行時にファイル指定でimportします。こういうときにTensorFlowのチュートリアルで「モデルはモジュールにしてinference()、loss()、train()を提供するようにすると良いよ」というのが効いてきます。モジュールを差し替えてもインターフェイスが同一なので引数の型を気にせずに実行できます。
参考
学習プログラムでのモデルモジュールの動的import部分を載せておきます。YAMLパーサをごちゃごちゃするよりすこぶる簡単ですね。importしたファイルはinference()を提供している(ように書いている)のでそれを使ってグラフを作るだけです。
モデルは次の節で載せます。
if ns.model_py:
print('load external model file: {}'.format(ns.model_py))
model_module = im.machinery.SourceFileLoader('externalmodel', ns.model_py).load_module()
else:
model_module = im.import_module(DEFAULT_MODEL_MODULE)
最近使っている勝敗予測モデル
ここのところ実験に使用している勝敗予測モデルです。畳み込み層が13層、全結合が2層、畳み込み層が多いのでHighwayNetを導入しました(参考 : わかるLSTM ~ 最近の動向と共に)。
規模としては個人が趣味で書くモデルの大きさを越えているような気がする・・・。
castaneaというモジュールは自分が作ったオレオレ便利TensorFlowラッパーです。イニシャライズ、ノーマライズ、レイヤーなどで生TensorFlowだと使いにくかったり標準で実装されていないものなどをまとめてあります。大体雰囲気はつかんでもらえると思います。
import tensorflow as tf
import castanea as cas
import castanea.layers as cal
def inference(minibatch, reuse=False, var_device='/cpu:0'):
x = minibatch
hk = 3 # highway net kernel size
p1 = cal.LayerParameter(
rectifier=tf.nn.relu, var_device=var_device)
p2 = cal.LayerParameter(
rectifier=tf.nn.relu, var_device=var_device)
p3 = cal.LayerParameter(
rectifier=tf.nn.softmax, var_device=var_device)
with tf.variable_scope('inference', reuse=reuse):
x = cal.conv2d(x, 9, 9, 1080, parameter=p1)
y = cal.conv2d(x, 9, 9, 1080, parameter=p1)
x = cal.highway(y, x, hk, var_device=var_device)
y = cal.conv2d(x, 7, 7, 1080, parameter=p1)
x = cal.highway(y, x, hk, var_device=var_device)
y = cal.conv2d(x, 7, 7, 1080, parameter=p1)
x = cal.highway(y, x, hk, var_device=var_device)
x = cal.conv2d(x, 5, 5, 720, parameter=p1)
y = cal.conv2d(x, 5, 5, 720, parameter=p1)
x = cal.highway(y, x, hk, var_device=var_device)
y = cal.conv2d(x, 3, 3, 720, parameter=p1)
x = cal.highway(y, x, hk, var_device=var_device)
y = cal.conv2d(x, 3, 3, 720, parameter=p1)
x = cal.highway(y, x, hk, var_device=var_device)
x = cal.conv2d(x, 3, 3, 360, parameter=p1)
x = cal.conv2d(x, 3, 3, 180, parameter=p1)
x = cal.conv2d(x, 3, 3, 90, parameter=p1)
x = cal.conv2d(x, 3, 3, 90, strides=[1,2,2,1],
parameter=p1)
x = cal.conv2d(x, 3, 3, 90, strides=[1,2,2,1],
parameter=p1)
x = cal.linear(x, shape=[-1, 1024], parameter=p2)
x = cal.linear(x, shape=[-1, 2], parameter=p3)
return x
学習してみた
で、学習してみました。
条件
- 入力データは2chkifu約6万件の対戦
- 全件について「同一の盤面で勝敗が異なるもの」を除外
- 5000,000盤面を学習データ、836000をテストデータとした
- 盤面からどちらが勝つかを予測する
- 以前行っていた盤面の左右反転によるデータオーグメンテーションは今回は行っていない
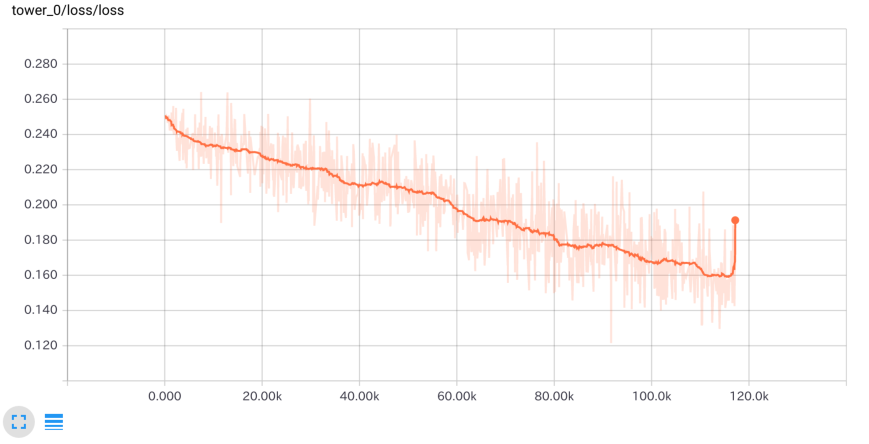
6エポック学習したロスの推移です。
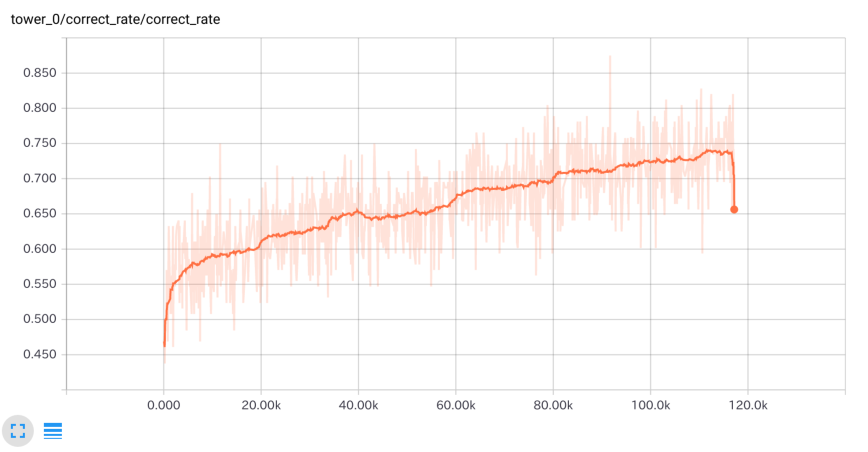
6エポック学習している時の学習サンプルに対する正答率の推移です。
テストサンプルに対する正答率が以下です。avgが全体の正答率の平均。minとmaxは256レコードで構成される各ミニバッチについて最低と最高の正答率です。
correct rate(100.000): avg 0.714, min 0.641, max 0.781, time 1.479 (sec per minibatch(256 samples))
correct rate(200.000): avg 0.715, min 0.641, max 0.785, time 1.441 (sec per minibatch(256 samples))
correct rate(300.000): avg 0.714, min 0.641, max 0.785, time 1.444 (sec per minibatch(256 samples))
correct rate(400.000): avg 0.714, min 0.641, max 0.785, time 1.447 (sec per minibatch(256 samples))
correct rate(500.000): avg 0.713, min 0.641, max 0.805, time 1.446 (sec per minibatch(256 samples))
correct rate(600.000): avg 0.713, min 0.641, max 0.805, time 1.448 (sec per minibatch(256 samples))
correct rate(700.000): avg 0.714, min 0.641, max 0.805, time 1.450 (sec per minibatch(256 samples))
correct rate(800.000): avg 0.713, min 0.641, max 0.805, time 1.447 (sec per minibatch(256 samples))
correct rate(900.000): avg 0.713, min 0.637, max 0.805, time 1.449 (sec per minibatch(256 samples))
correct rate(1000.000): avg 0.713, min 0.637, max 0.805, time 1.448 (sec per minibatch(256 samples))
correct rate(1100.000): avg 0.713, min 0.613, max 0.805, time 1.448 (sec per minibatch(256 samples))
correct rate(1200.000): avg 0.713, min 0.613, max 0.805, time 1.449 (sec per minibatch(256 samples))
correct rate(1300.000): avg 0.712, min 0.613, max 0.805, time 1.450 (sec per minibatch(256 samples))
correct rate(1400.000): avg 0.712, min 0.613, max 0.805, time 1.448 (sec per minibatch(256 samples))
correct rate(1500.000): avg 0.712, min 0.613, max 0.805, time 1.448 (sec per minibatch(256 samples))
correct rate(1600.000): avg 0.713, min 0.613, max 0.805, time 1.447 (sec per minibatch(256 samples))
correct rate(1700.000): avg 0.713, min 0.613, max 0.805, time 1.447 (sec per minibatch(256 samples))
correct rate(1800.000): avg 0.713, min 0.613, max 0.805, time 1.448 (sec per minibatch(256 samples))
correct rate(1900.000): avg 0.713, min 0.613, max 0.805, time 1.447 (sec per minibatch(256 samples))
correct rate(2000.000): avg 0.713, min 0.613, max 0.805, time 1.448 (sec per minibatch(256 samples))
correct rate(2100.000): avg 0.713, min 0.613, max 0.805, time 1.447 (sec per minibatch(256 samples))
correct rate(2200.000): avg 0.712, min 0.613, max 0.805, time 1.449 (sec per minibatch(256 samples))
correct rate(2300.000): avg 0.712, min 0.613, max 0.805, time 1.450 (sec per minibatch(256 samples))
correct rate(2400.000): avg 0.712, min 0.613, max 0.805, time 1.450 (sec per minibatch(256 samples))
correct rate(2500.000): avg 0.712, min 0.613, max 0.805, time 1.451 (sec per minibatch(256 samples))
correct rate(2600.000): avg 0.712, min 0.613, max 0.805, time 1.452 (sec per minibatch(256 samples))
correct rate(2700.000): avg 0.712, min 0.613, max 0.805, time 1.448 (sec per minibatch(256 samples))
correct rate(2800.000): avg 0.712, min 0.613, max 0.805, time 1.452 (sec per minibatch(256 samples))
correct rate(2900.000): avg 0.712, min 0.613, max 0.805, time 1.452 (sec per minibatch(256 samples))
correct rate(3000.000): avg 0.712, min 0.613, max 0.805, time 1.456 (sec per minibatch(256 samples))
correct rate(3100.000): avg 0.712, min 0.613, max 0.805, time 1.452 (sec per minibatch(256 samples))
correct rate(3200.000): avg 0.712, min 0.613, max 0.805, time 1.453 (sec per minibatch(256 samples))
W tensorflow/core/framework/op_kernel.cc:993] Out of range: RandomShuffleQueue '_1_input/shuffle_batch/random_shuffle_queue' is closed and has insufficient elements (requested 256, current size 4)
[[Node: input/shuffle_batch = QueueDequeueManyV2[component_types=[DT_FLOAT, DT_FLOAT], timeout_ms=-1, _device="/job:localhost/replica:0/task:0/cpu:0"](input/shuffle_batch/random_shuffle_queue, input/shuffle_batch/n)]]
sample exausted
correct rate: 0.7121574556031843
試験データについても学習データと乖離しない正答率が出ています。
まとめ
前回書いたようにしばらくDCGANやVAEで遊んでいました。あとはTensorFlowで学習してモデルファイルを小さくしてコマンドラインアプリを作るシンプルな流れのためのAPIの学習なんかもしていました。実は遊ぶ目的としてはごちゃごちゃになったコードを整理するために小さいタスクを書いてTensorFlowの習熟を高めるというものがありました。ぼちぼち発見があり将棋の方のコードも進むようになりました。
ここまででデータファイルの形式の整理、モデルファイルの形式の整理、新しいモデルの学習ができました。
次は前から言っている自己対戦プログラムですが一応動き始めています。このあとすぐに「自己対戦の初めの一歩」的な記事を書きます。