前回 TensorFlowによる将棋ソフトの開発日誌(ゆっけさんの場合) #4
目次 TensorFlow将棋ソフト開発日誌 目次
キャッチフレーズ「勘で作るディープラーニング」
学習なんてしていなかった・・・(今回の要点)
引き続き勝敗予測モデルに取り組んでいます。以下、今回お話すること。
- 前回(だいたい1週間前)、とりあえずのモデルを見せたり学習のロスのグラフを載せたりしていたけれど実は勾配消失していて学習なんてしていなかった
- バッチ学習を導入した
- 学習の勾配をTensorboardに表示するようにした
- 活性化関数としてtanh, ReLUを試した。バイアスを廃止した
- batch_normalizationを試したらうまくいった感じ
- その他
- 次回予定の作業
現在のモデルは付録として最後につけます。
試行錯誤中にちゃんとスクリーンショットなどで記録を取っていなかったため図が少ないわかりにくい報告になります。ご容赦ください。研究ライクに実験計画、条件記録、結果記録、報告のサイクルを回さないといけないかなぁ・・・めんどいからやらないけど。
勾配消失で学習していなかった話
前回の最後に学習のロスを提示しました。
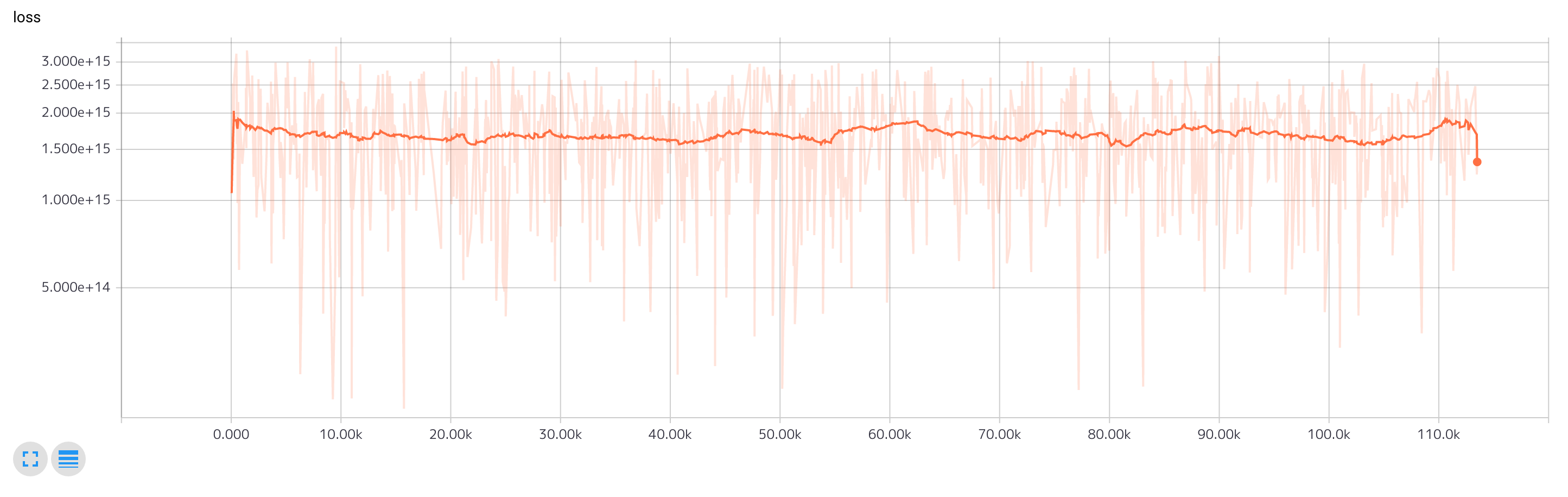
今週は平日会社に行っている間に自宅のマシンで前回のモデルの学習を行いうまくいっているかどうかを試していましたが何度やってもロスが収束しません。もともと収束しづらいモデルですが波打ってるようなグラフになり不自然です。
そこで学習中の各中間層で計算される勾配を可視化することにしました。
バッチ学習を導入した
前回は学習時に1サンプルずつ投入していましたがバッチ学習を導入しました。現在ミニバッチのサイズは100です。ただしバッチ学習を導入しただけでは勾配消失は改善されませんでした。
初めのうちは高次元入力から事前学習なしで2値分類をしようとすると勾配計算のための情報量が小さくうまくいかないのではないかと考えていましたが違ったようです。
Tensorboadで勾配を可視化する
やり方は簡単です。通常 optimizer.minimize() で生成している最適化オペレータを optimizer.compute_gradients() と optimizer.apply_gradients() に分けて間で得られる勾配を tf.histogram_summary() で出力するだけです。ただしどうも書き出しに時間がかかるようなのでデバッグ用と実際の学習用でログ出力の有無を切り替えられるようにしておいた方が良いと思います。
def create_node(self, nids, exclude_tags):
source_node = nids[self.source]
global_step = tf.get_variable(
'global_step', (),
initializer=tf.constant_initializer(0), trainable=False)
if self.takelog:
opt = tf.train.AdamOptimizer(self.val)
grads = opt.compute_gradients(source_node)
with tf.device('/cpu:0'):
for grad, var in grads:
if grad is not None:
tf.histogram_summary('grads/'+var.name, grad)
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step, name=self.name)
return nids, self.nid, apply_gradient_op
else:
return nids, self.nid, tf.train.AdamOptimizer(self.val).minimize(
source_node, global_step=global_step, name=self.name)
これで Tensorboard 上で以下のようなグラフが得られます。図は現在やっているモデルの勾配です。今週取り組んでいた作業途中のモデルで表示させたら出力が発散(?)しているせいか何も表示されない、あるいは勾配消失して出力がゼロ付近に集中してしまっていました。

活性化関数としてtanh, ReLUを試した
前回のモデルでは中間層の出力に活性化関数を適用していませんでした。いや、なんかいいかなぁ・・・って。はじめにtanh、次にReLUを試しましたがどちらもほとんど改善がありませんでした。
考察します。
tanhの場合。関数の形状から活性化前の出力値絶対値が大きくなると勾配が得にくくなると考えられます。なのでConv層の出力がtanhにおいて大きな勾配を得られるように重みの初期値を作る必要がありそうです。しかし各層ごとにそれを作るのが結構難しい(というかめんどくさい)感じです。
ReLUの場合。ReLUとmaxpoolを重ねていくと出力の値は爆発あるいは微小化していく傾向にあります。重みの初期値が不適切に大きいと各層は入力より大きな出力をしてそれが積み重なります。初期値が不適切に小さいと逆に出力がどんどん小さくなります。これも各層ごとに重みの適切な初期値を作れば(作ることができれば)良いのですが難しいです。
まとめるとtanhは出力の値は爆発しにくいが勾配を得にくく、ReLUは勾配は得やすいが出力の値が安定しない。どちらもConv層の重みの初期値を適切にすれば改善されるかもしれないが難しい。というような考えに至りました。
活性化後の出力が勾配を得やすい(入力の変化が出力に反映されやすい)形であり、かつ出力の値が爆発or微小化しにくい手段が必要です。
そこで batch normalization ですよ。
batch normalizationを導入した
実際のところあまり理解していません。「batch を normalize するんだから良い感じじゃね?」くらいの気分で使っています。
入力層と出力層以外の中間層で活性化関数に入力する前に tensorflow の tf.batch_normalize() を適用しました。これが良かったようです。
以下は現在デバッグ中のモデルのロスの変化です。収束は遅いものの単調な雰囲気の変化なので効果はあったかなと思います。

勾配の分布の推移も示します(1番目から4番目のConv層まで)。横軸がイテレーションの回数、縦軸は各ユニットの勾配の大きさのヒストグラムです。縦に広くなっている時に多くのユニットに勾配が発生してネットワークが更新されるという見方です。
うまくいっていなかった時は200イテレーション程度でゼロに収束してしまっていましたが batch normalization を導入したらイテレーションを増やしても微小ではあるものの入力層付近まで誤差が伝播しています。

batch normalization は必須かもなーという印象です。
バイアスを廃止した
いろんな資料で中間層の出力の計算はだいたい以下のような感じですね。
out = matmal(input, weight) + bias # 線形
out = conv2d(input, filters) + bias # コンボリューショナル
今回バイアスを全て取り除きました。直接の理由は勾配消失が発生している時にバイアスだけは誤差が伝播していてバイアスだけで学習し続けるという挙動があったためです。
入力ベクトルの各要素が -1 から 1 の範囲であり、出力層は 0 から 1 です。なのでバイアスはあるだけ邪魔なんじゃないかと考えました。
ただちょっと自信はないです。
事前学習について
重みの初期値が難しい初期値が難しいと書いてきましたがオートエンコーダによる事前学習でもしかしたら batch normalization なしで良い結果を得られるかもしれないと考えています。
ただし各層にオプティマイザを設定してロスを書いて層ごとにイテレーションを回してモデルを保存して学習済みの前層は重みを固定して、、、というのがとても面倒なので今のところ実施を考えていません。batch normalizationでもうまくいかなくなってきたら(層数が増えてきたら?)本腰を入れて考えます。
まとめ
今回の知見は以下のような感じ
- 自分でモデルを設計した時に何か学習が進まないと思ったら勾配消失を疑う
- 学習中の各層の勾配はtensorflowでは容易に可視化できるのでサボらない
- 活性化関数は必要だがtanh系にしろReLU系にしろ重みの初期値がとても重要
- ただし重みの初期値を適切に決めるのは難しい
- batch normalizationで出力を正規化するといい感じになる
- 勾配消失が発生している状況で1サンプルの学習からバッチ学習にするだけでは改善は見られない
あとは学習データの読み込みが(データ変換を計算量ガン無視で書いていたので)遅かったので読み込みメソッドのリファクタリングをしてたりもしてました。
今後の課題とか予定とか
batch normalization is GODというくらい救われました。これでモデルをいろいろいじる(フィルタを増やしたりinceptionを導入したり層を増やしたりする)ことができます。
が、その前に学習の下回りを改善していきます。
- 学習時のデータの読み込みが同期的なのでどうしてもGPUの使用率を100%付近にできていません。tensorflowの仕組みを使って非同期読み込みを行い並列性を高めてGPUの使用率を向上させます。
- バッチ学習の導入などに伴い以前は表示していた学習中の正答率が表示できなくなっているので復活させます。
- 現在、対局開始から16手までは学習させていません。最序盤は定番の手が繰り返されかつ勝敗がわからないデータだからです。ただ16手というのが少なすぎて実は30手くらいまで無視しないといけないのかなと思案中。ここら辺は将棋の素人なのでよくわからない。実験しながら決めていきます。
- 現在、先手だけを学習しています。これを後手まで拡張します。ただし通常の棋譜のように後手を図の上にするのではなく後手から見た棋譜に直します。理由は入力空間を小さくするためです。自分の入力設計だと単に入力ベクトルに-1をかけてもダメで先手と後手でチャネルの位置が変わるので変換コードを書く必要があります。
- データオーグメンテーションとして棋譜の左右反転を入れます。これは要素の位置を入れ替えればオーケー。
快適に学習実験を繰り返せるようにしていきます。
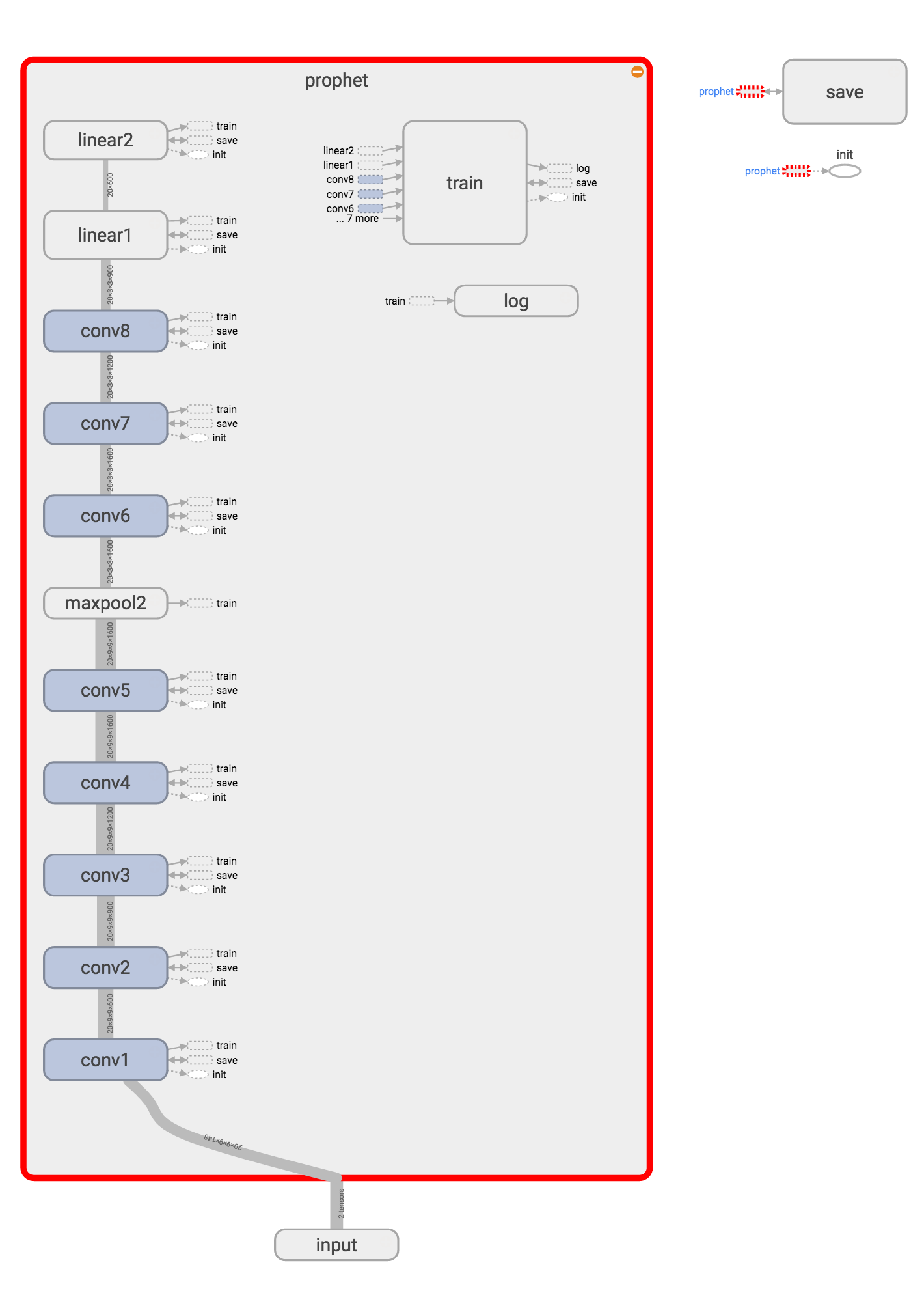
付録・現状のモデル
現在のモデルです。maxpoolで勾配の消失が発生していたので減らしましたがbatch normalizationで勾配消失が解消したためまた増やすかもしれません。
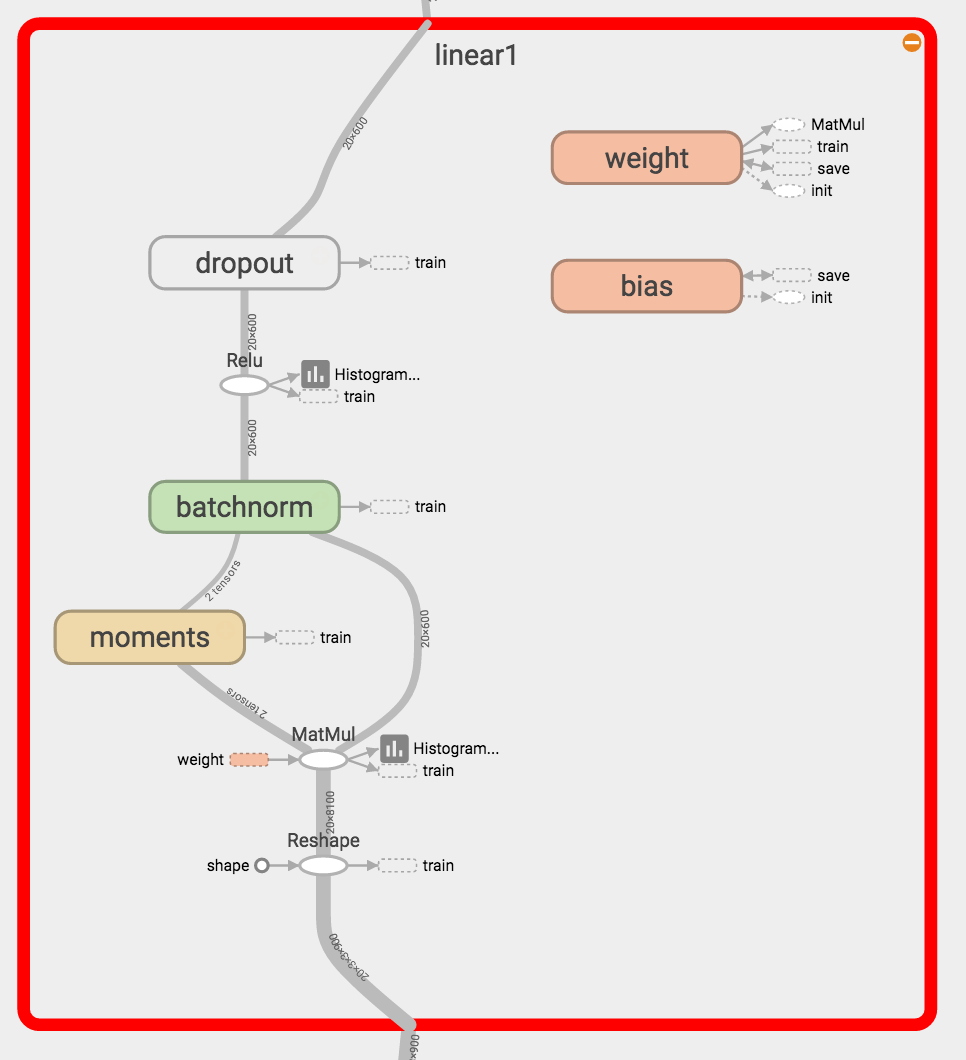
conv2層です。ReLU及びbatch normalizationを導入しています。またバイアスを廃止しています。他のconv層も同様です。
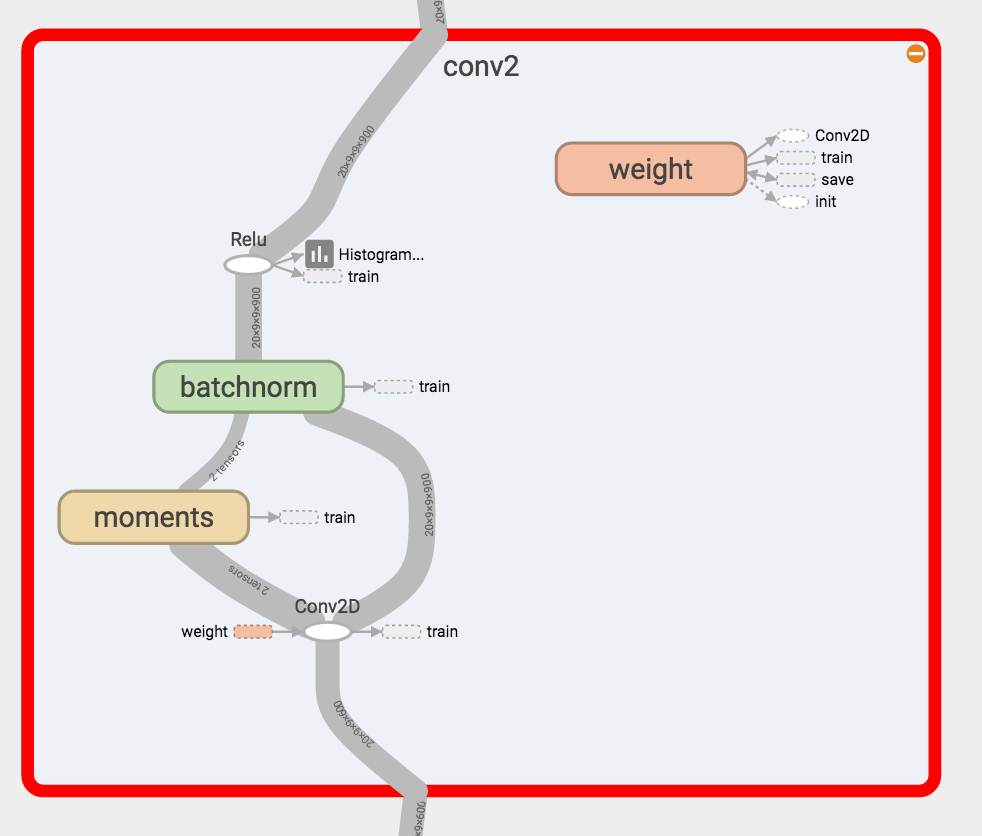
Linear1層です。こちらもReLU及びbatch normalizationを導入しています。最後の2値の出力は線形結合+softmaxになってます(単純なので割愛)。