背景
ぐるなびAPIにてjson形式でデータ取得した際に、dictionaryの中にlistがあってその中にdictionaryが・・・と、キー構造把握がめんどいなと思いました。
概要
dictionaryを渡して、キーとそのデータ型をツリー構造で表示できるようにします(下図例参照)
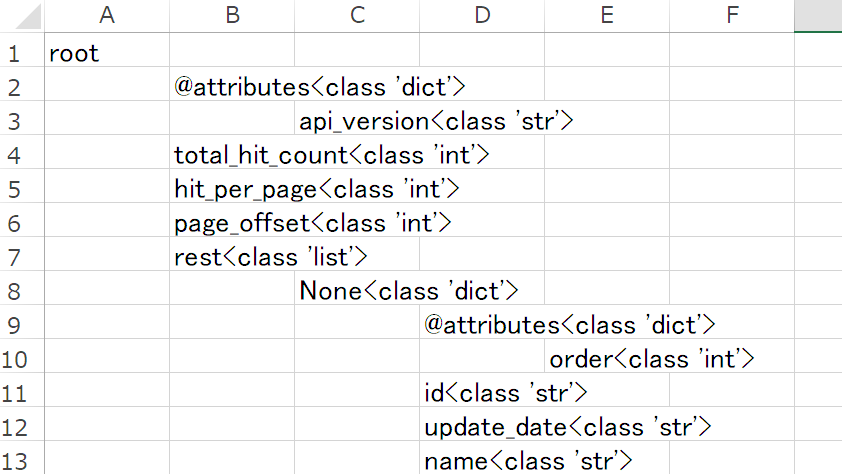
※dictionaryとlistを「キーを有する子を持ちうるもの」として検出・展開していく構成です。それ以外の型で子を持つものには対応していません
詳細
解析対象のdictionaryを用意する
ここでは、ぐるなびAPIでの取得例を記載
# ぐるなびAPIにより取得
# input -----------------------------------
url = 'https://api.gnavi.co.jp/RestSearchAPI/v3/'
keyid = 【あなたのkeyid】
name_kana = 'コーヒー'
address = '東京都世田谷区奥沢'
# main ----------------------------------
import requests
import json
params = {}
params['keyid'] = keyid
params['name_kana'] = name_kana
params['address'] = address
result_api = requests.get(url, params)
result_api = result_api.json() # this is dictionary
ここでは「result_api」がdictionary型データです(内容例は下図)。
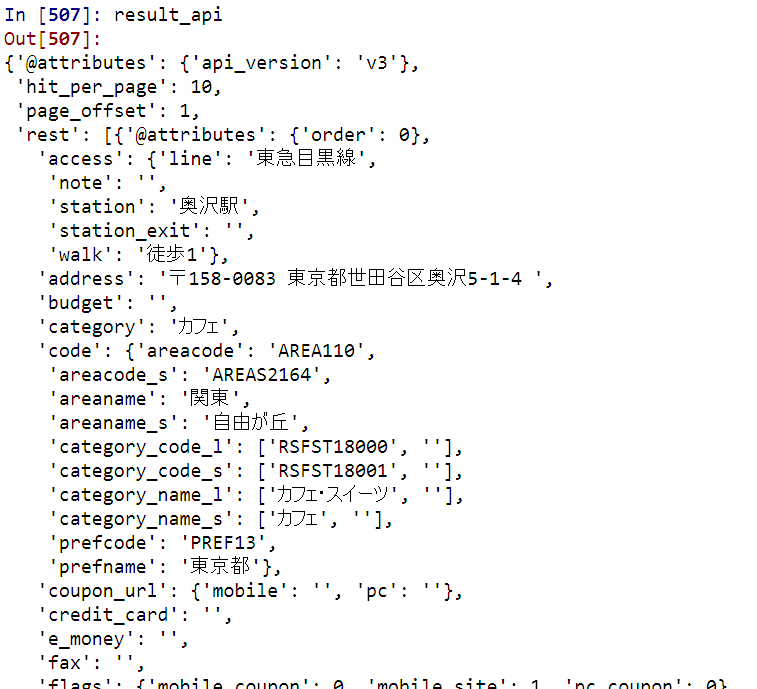
これを解析対象として、引き続き処理します。
(9/9更新:雑に関数化しました)
関数部分
def understand_dictionary_structure(target_dict,
max_depth,
linefeed_code,
output_path
):
import numpy as np
import pandas as pd
import sys
print('sys.getsizeof(target_dict):', sys.getsizeof(target_dict))
print('target_dict.keys():', target_dict.keys())
values_list = [target_dict]
## get parent - child relation -----------------------------
def set_to_df(df, k, v, from_id, this_id):
row = df.shape[0]
df.loc[row, 'depth'] = depth
df.loc[row, 'key'] = k
df.loc[row, 'type'] = str(type(v))
df.loc[row, 'from_id'] = from_id
df.loc[row, 'this_id'] = this_id
df = pd.DataFrame()
from_id_list = []
from_id = 0
this_id = 0
from_id_list.append(from_id)
for depth in range(max_depth):
print('depth:{}, rest:{}'
.format(depth, len(values_list))
)
values_list_have_next_depth = []
from_id_list_next_depth = []
for value, from_id in zip(values_list, from_id_list):
if (isinstance(value, dict)):
for k ,v in value.items():
this_id += 1
set_to_df(df, k, v, from_id, this_id)
# 各要素を追加
values_list_have_next_depth.append(v)
from_id_list_next_depth.append(this_id)
elif (isinstance(value, list)):
k = None
for v in value:
this_id += 1
set_to_df(df, k, v, from_id, this_id)
# 各要素を追加
values_list_have_next_depth.append(v)
from_id_list_next_depth.append(this_id)
values_list = values_list_have_next_depth
from_id_list = from_id_list_next_depth
if len(values_list) == 0:
print('break at end of depth:', depth)
break
print('df.shape:', df.shape)
## sort -----------------------------
while_loop_id = 0
while True:
id_processed = []
from_id = 0
df2 = pd.DataFrame(columns=df.columns)
i_processed = []
re_order_cnt = 0
for i, v in df.iterrows():
if i in i_processed:
continue
df2_row_to_write = df2.shape[0]
df2.loc[df2_row_to_write, :] = v
this_id = v['this_id']
dfex = df.query('from_id==@this_id')
if dfex.shape[0] > 0: # have children
if dfex.index[0] > i + 1: # childen are not at next row
for iex, vex in dfex.iterrows():
df2_row_to_write = df2.shape[0]
df2.loc[df2_row_to_write, :] = vex
i_processed.append(iex)
re_order_cnt += 1
i_processed.append(i)
df = df2.reset_index(drop=True)
print(while_loop_id, re_order_cnt)
if re_order_cnt == 0:
print('re_order_cnt == 0')
break
else:
while_loop_id += 1
## write(show) -----------------------------
with open(output_path, mode='w') as f:
str_to_wite = 'root'
f.write(str_to_wite + linefeed_code)
# print(str_to_wite)
for i, v in df.iterrows():
suffix = '\t' * int(v['depth'] + 1)
if (v['key']==None) & ('int' in v['type'] or 'str' in v['type']):
pass
else:
str_to_wite = '{}{}{}'.format(suffix, v['key'], v['type'])
f.write(str_to_wite + linefeed_code)
#print(str_to_wite)
# エクセルに貼り付けて確認する想定
# windows想定
# さくっと見たい場合はprint文でもまあまあ見れる
メイン部分
import copy
target_dict = copy.deepcopy(result_api) # 一応バックアップ
max_depth = 10
linefeed_code = '\n'
output_path = 'visualize_dictionary.tsv'
#from func.myfunc import understand_dictionary_structure
understand_dictionary_structure(target_dict,
max_depth,
linefeed_code,
output_path
)
できたtsvをメモ帳で開いてコピーしてエクセルに貼り付けるとこんな感じ(再掲):
やりたいことは出来ました。
が、思った以上にコーディングに手間取ってやりたいこと(ぐるなびAPIで遊ぶ)の時間がなくなってしまった・・・。脳トレになったと考えよう・・。
おわり