やりたいこと
AWSでデータを蓄積して、SQLチックにデータの検索がしたい。
でもRDSとかお高そうだし色々準備めんどくさいしやりたくない。
ということで、Athenaを使って楽してSQLっぽく検索できるようにしたい。
折角だしデータ蓄積(S3へのデータ保存)もFirehose使って楽してやりたい。
主な登場人物
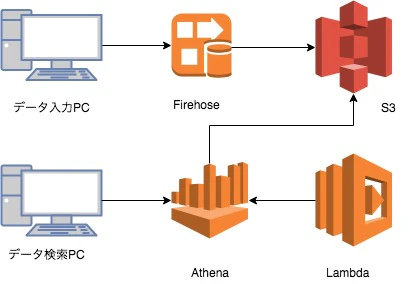
Firehose
JSONデータをよしなにフォルダ分けしてS3に保存してくれる子
S3
シンプルストレージサービス。もう名前が説明だよねこれ
Athena
S3に入ってるJSONとかのデータをSQLチックに検索できる
Lambda
みんな大好きなコンピューティングサービス
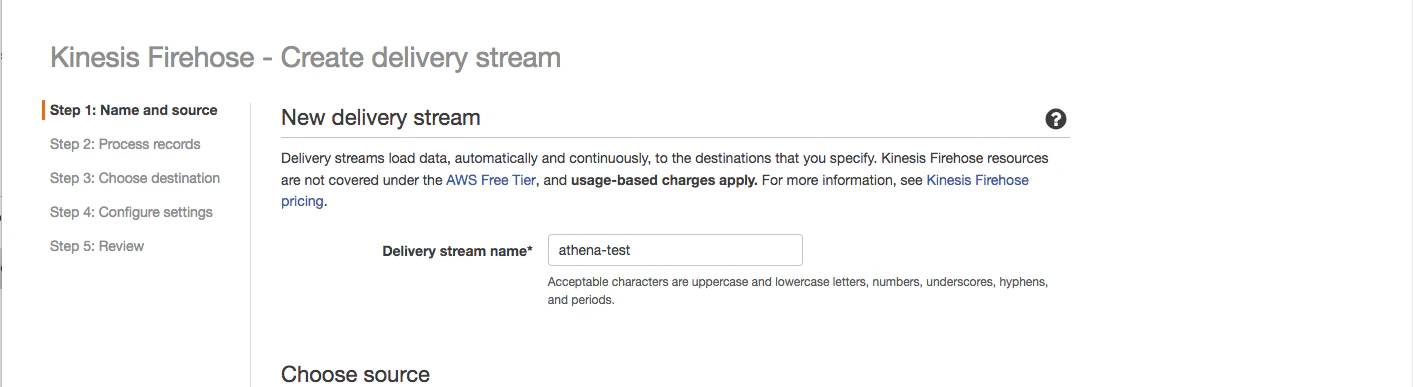
Firehoseの作成
多分コンソールから作るのが一番早くて楽です。
Firehoseの名前を入力して
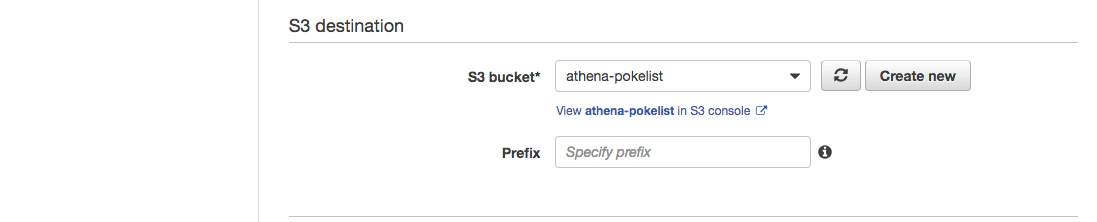
予めデータを蓄積するS3バケットを作ってから、コンソールでkinesisFirehoseを選び、以下の通りに作成します
予め作ったS3バケットを選択して
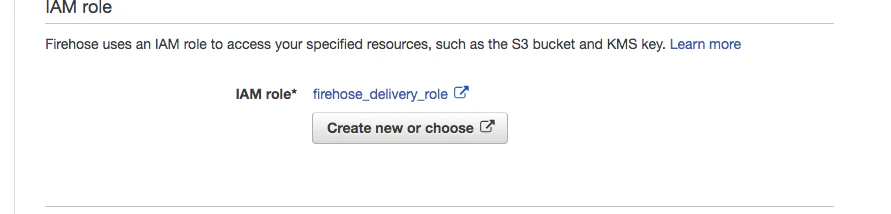
IAMRoleを自動生成でよしなに作ってもらって
最後にCreateを押して、終わり。
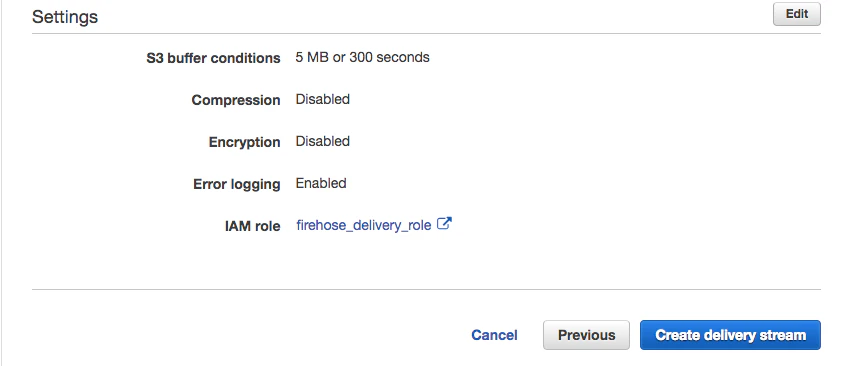
これでFirehoseは作成されます。上記の入力項目は初期値のままで問題ありません。
Firehoseにデータを渡す
今回はAWSCLIで送ってみた。もちろんSDKを使って各種言語からも可能。
aws firehose put-record --delivery-stream-name athena-test --record '{"Data":"{\"Name\":\"Tyranitar\",\"CP\":3670,\"No\":248,\"GetDay\":\"2018/09/11\"}\n"}'
ポイントとして最後に必ず改行コードを入れること。
これがないとAthenaで検索時に出てこないことがある。
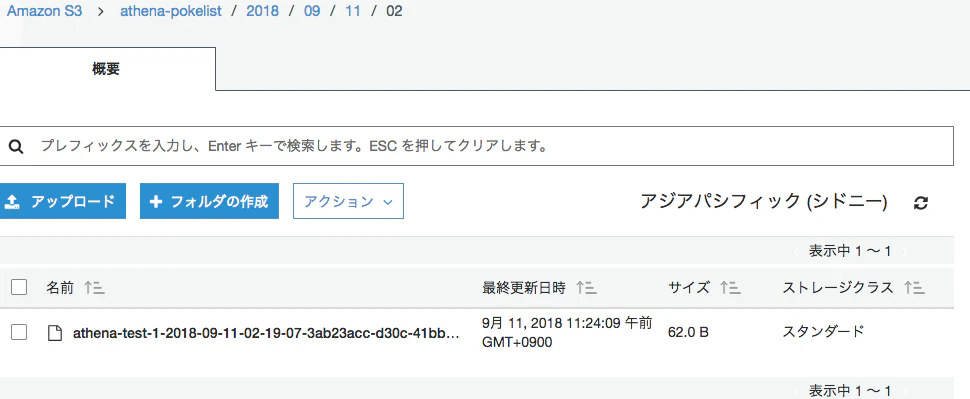
S3にはこんな感じに保存される。フォルダも年月日時で自動生成される。
ただしフォルダの年月日時は、UTC時間に保存されてしまうのでそこは注意が必要。
また、S3にファイルができるまで5分くらいかかる。
どうも短期間で複数Firehoseからデータを送信すると1つのファイルにしようとするらしく、
その兼ね合いですぐには出力せずちょっと待ってから出力するっぽい。
Athenaの作成
こっちもコンソールから作成するのが簡単だと思います
Athenaを開いてテーブルの作成→手動を選んで
データベースを新しく作成、テーブル名とかは適当に
入力データセットの場所はFirehoseのS3の保存先を指定する
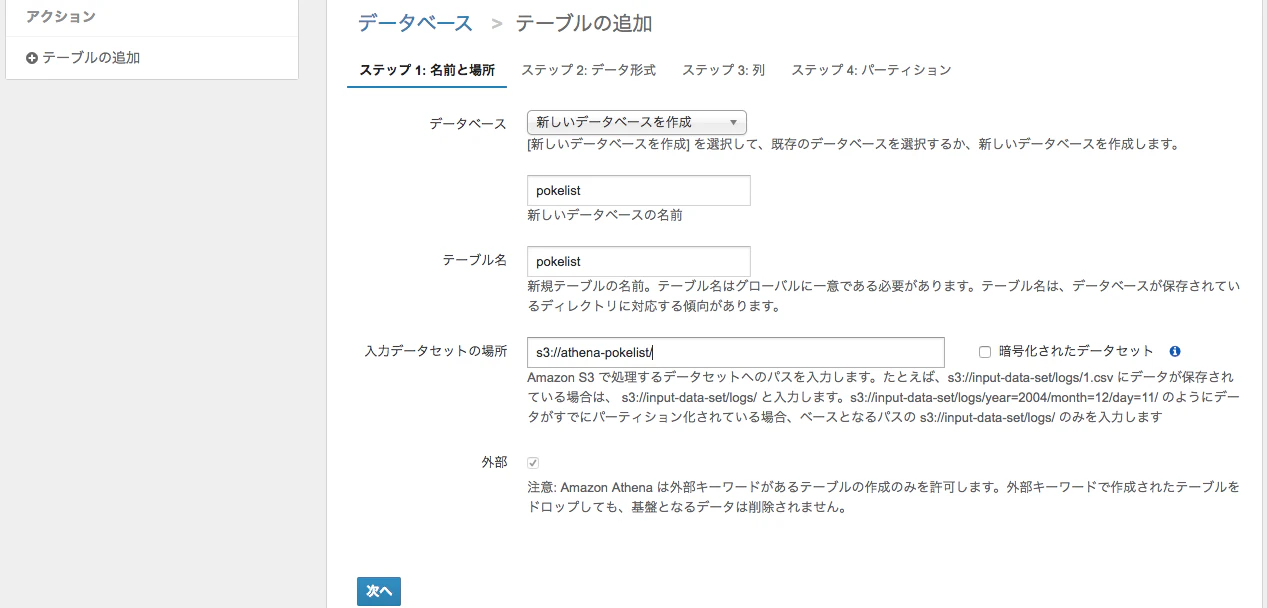
形式はJSONを選択
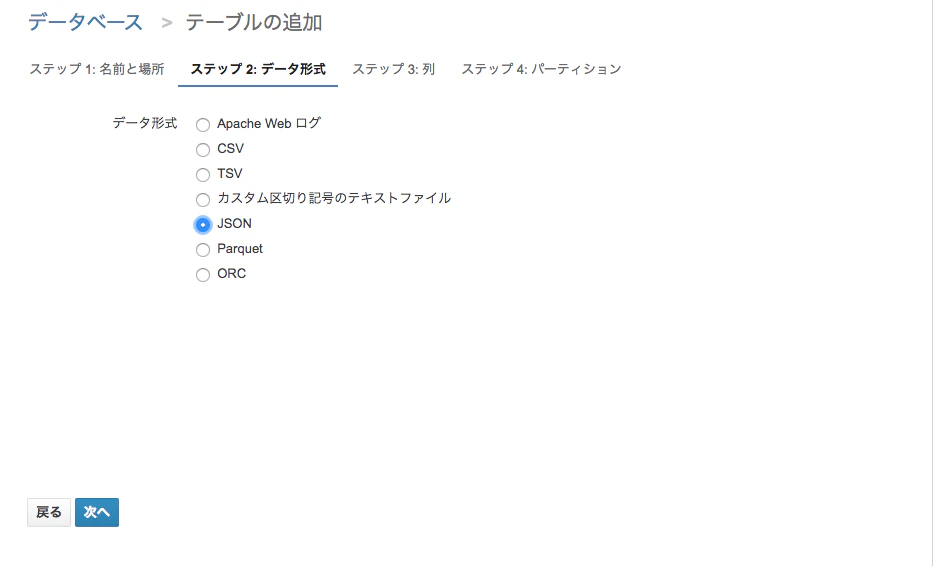
列の設定はFirehoseで送ったJSONの内容を設定
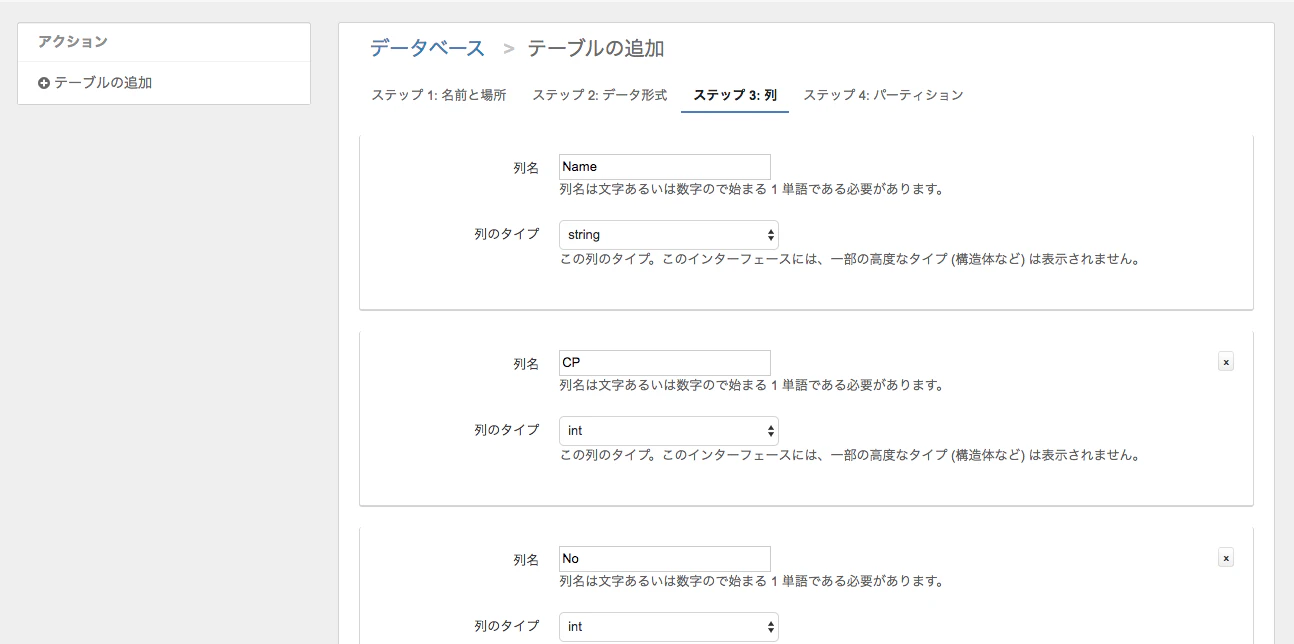
最後にパーテションを列名dtにして作成
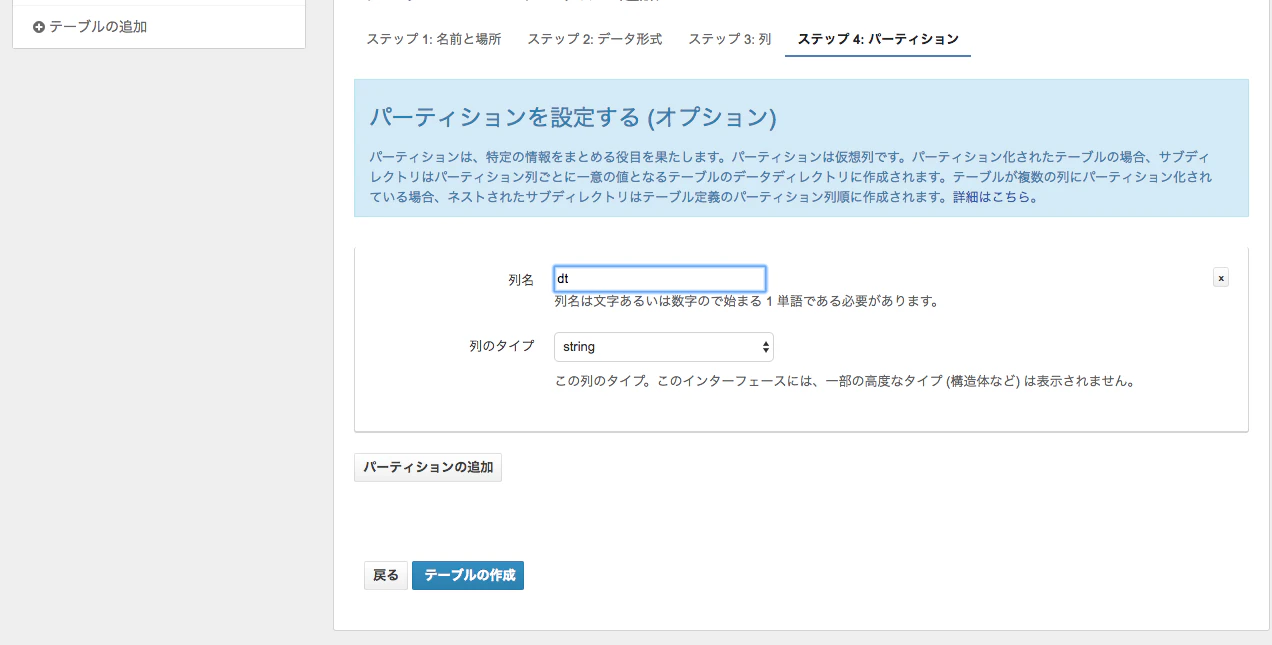
あとはテーブル作成を押せばAthenaのDBとテーブルが作成されます。
では早速SQLライクに表示...しようとするとなぜか0件。なんでや!
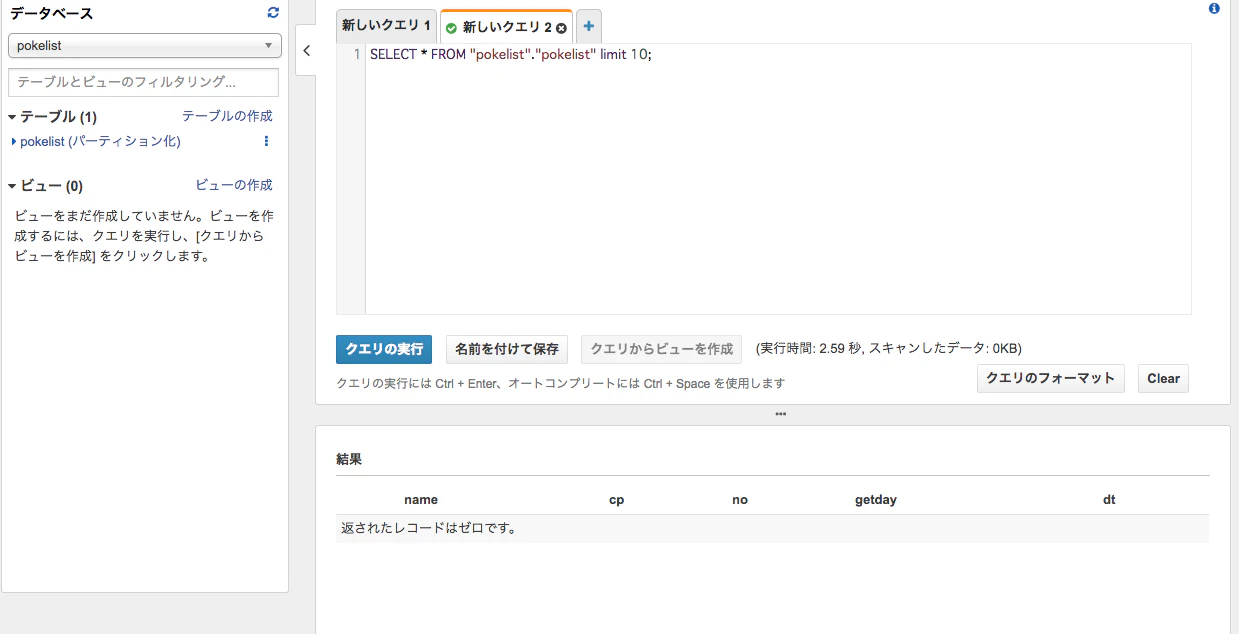
原因はパーテションを設定していないからです。
ということでパーテションを設定してみましょう。
Athenaのパーテション設定
そもそもAthenaのパーテションって何やねんって話ですが、
簡単に言えばS3のフォルダごとにパーテションとして値を設定することができます。
設定方法は下記のようなクエリを投げてあげれば設定できます。
ALTER TABLE <テーブル名> ADD PARTITION (<パーテションの名前>='<設定値>') location 's3://<S3バケット名>/<フォルダ名>';
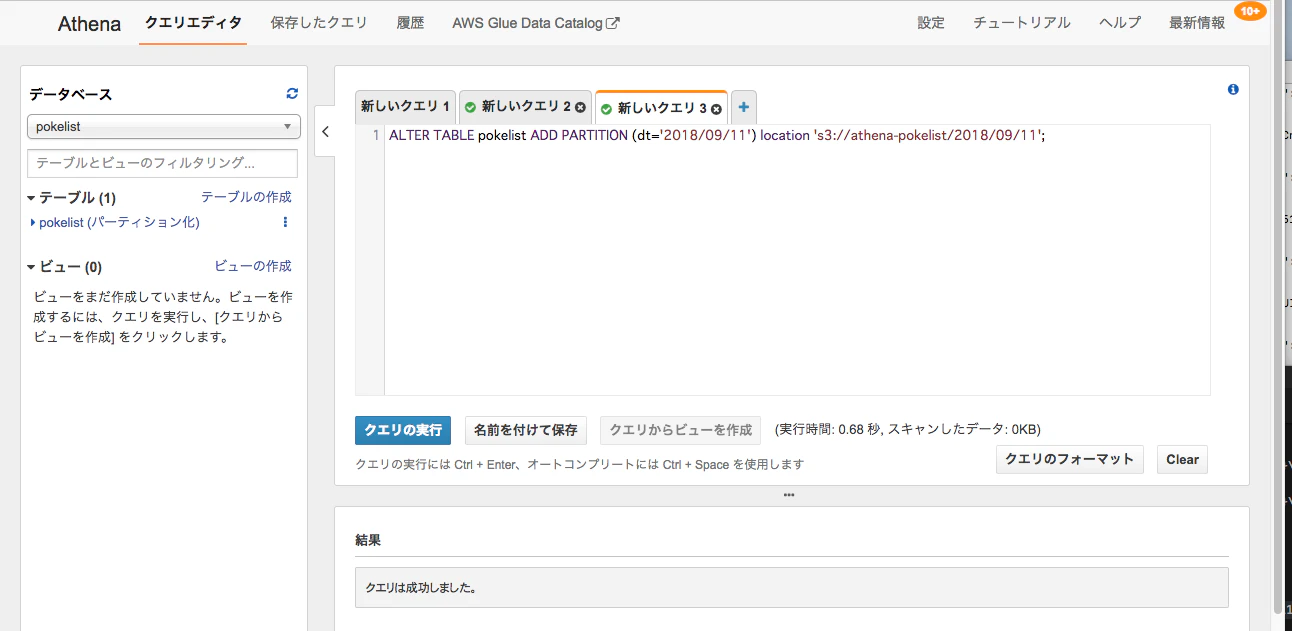
実際にコンソールからやってみると、こんな感じになります。
問題なければ「クエリが成功しました」と表示されます。
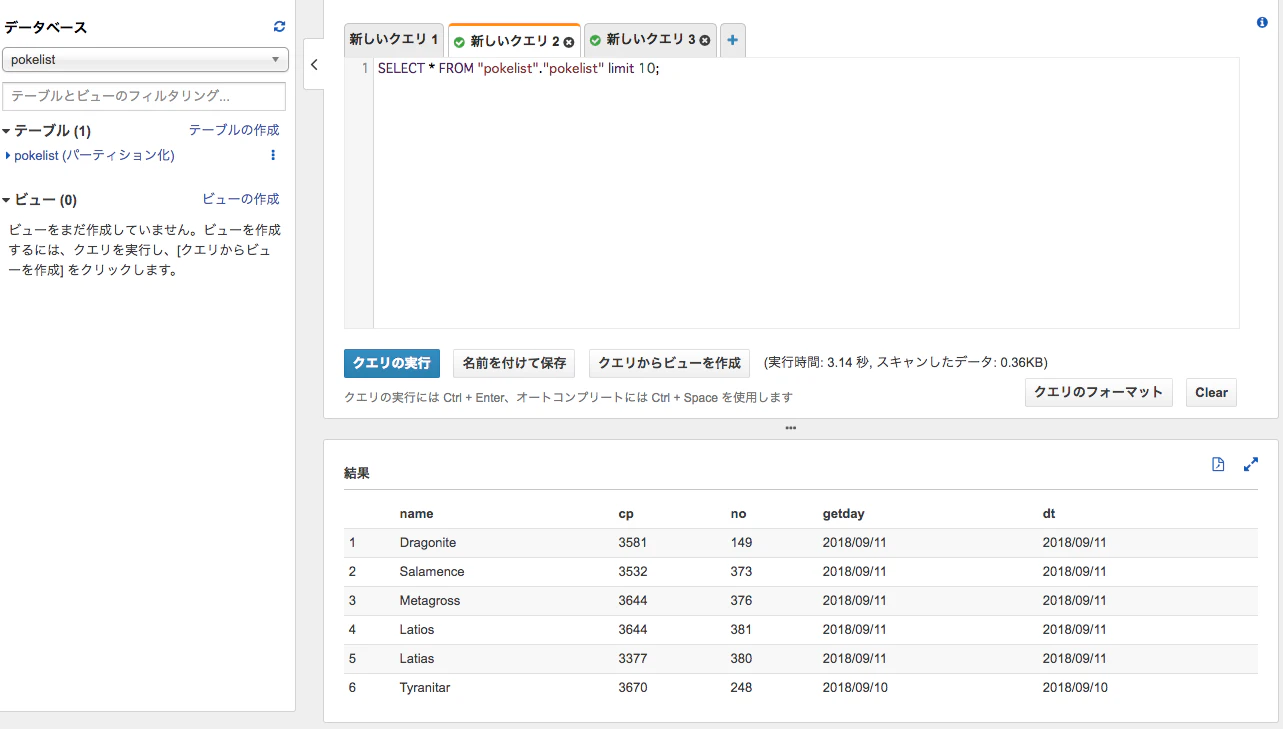
他のフォルダも同様にパーテションを設定した後に再度検索してみると
今度はちゃんと検索結果が表示されました。
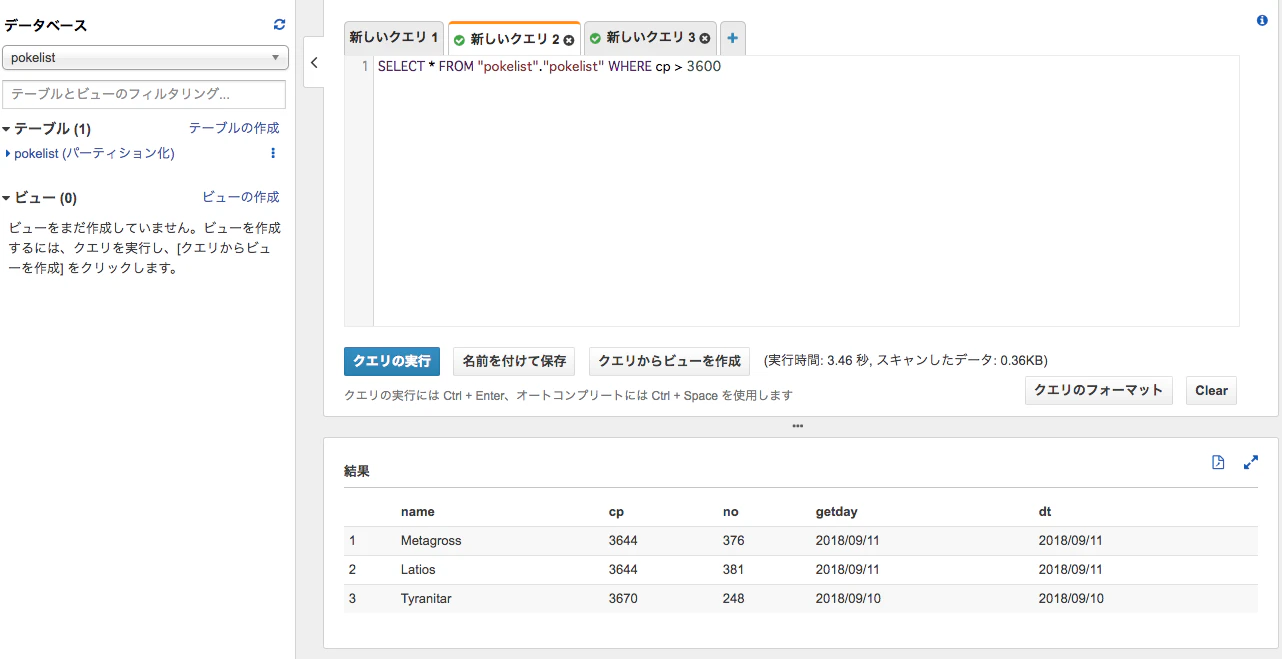
当然、SQLチックに検索もできます。
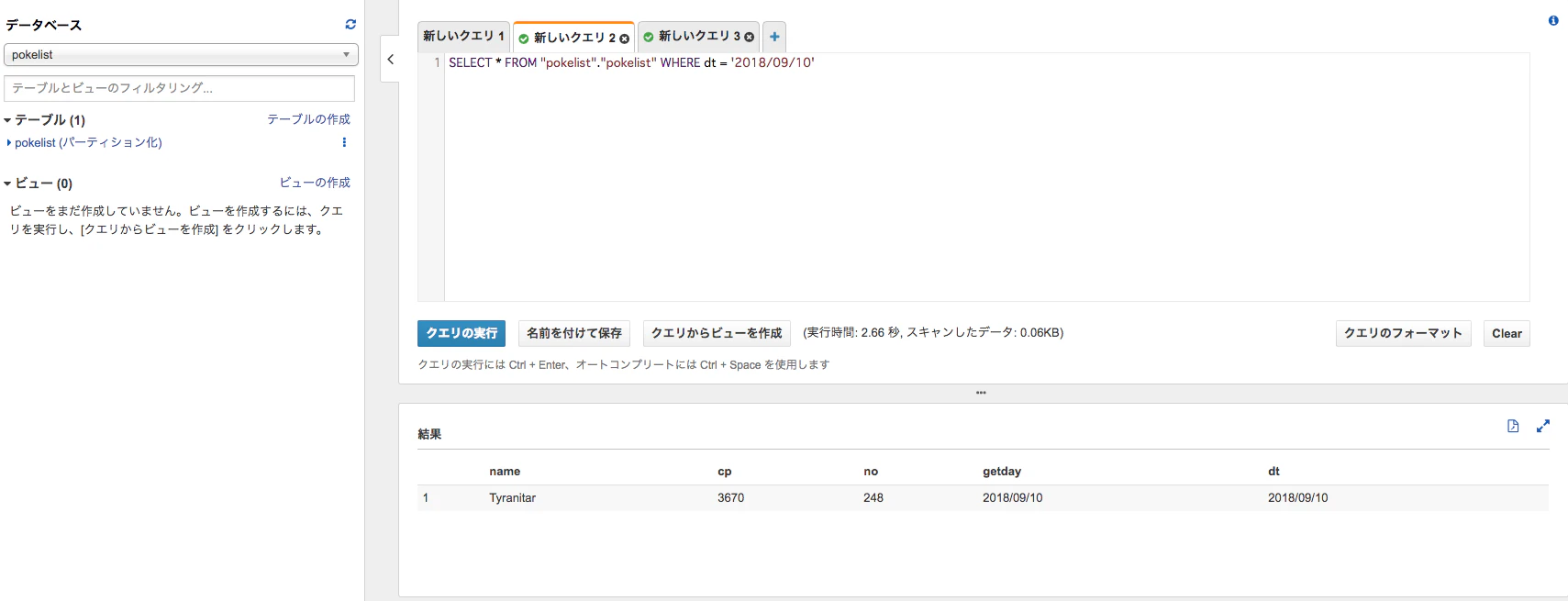
また、パーテション(画面だとdt)でも検索することができます。
なんでパーテションを設定しないといけないかと言えば、
パーテションで検索するとAthenaの費用と検索時間を小さくすることができます。
というのもAthenaの内部の動きとしては
該当バケットを全件取得→SQLにあわせて内容をフィルタリング
となっており、バケットのデータが増えれば増えるほど費用も時間もかかってしまいます。
ですが、パーテションで検索することにより
該当バケットの該当パーテションの内容のみ取得→SQLにあわせて内容をフィルタリング
となるため、効率的に検索することができるようになります。
パーテションの自動化
パーテションはフォルダごとに毎回SQLで設定してやる必要があります。めんどくさいですね。
一応自動設定となるフォルダ分けとかもありますが、なんとFirehoseから作成した場合は無理。
サービス連携ちゃんとやってくれよ!
仕方ないのでLambdaで自動生成するようにしましょう。下記はサンプル。なんとなくnode.jsで書きました。
OutputLocationはAthenaの検索結果を保存するバケットを設定します。
コンソールからAthenaを検索した場合、すでに自動で生成されているはずです。
テーブル名やS3バケット名とかはよしなに変更としてください。
const AWS = require('aws-sdk');
const athena = new AWS.Athena({apiVersion: '2017-05-18'});
const moment = require('moment')
exports.handler = (event, context, callback) => {
const today = moment().format('YYYY/MM/DD');
const params = {
QueryString: "ALTER TABLE pokelist ADD PARTITION (dt='" + today + "') location 's3://athena-pokelist/" + today + "'",
ResultConfiguration: {
OutputLocation: "s3://aws-athena-query-results-795622185554-ap-southeast-2/"
}
};
athena.startQueryExecution(params, function(err, data) {
console.log(data);
});
};
上記Lambdaを1日1回適当なタイミングで動かして、パーテション毎日生成するようにしましょう。
時間ごとにパーテション分けしたい場合は、1時間に1回となります。
ただしここでの日付は例のごとくUTCであることに注意しましょう。
FirehoseやAthenaの良い点まとめ
・ Firehoseがフォルダを日時で自動生成した上でJSONファイルを作成してくれる
・ RDSの構築とかなくAthenaで簡単にSQLライクなことができる
・ パーテションを設定すればAthenaの検索を高速化できる
FirehoseやAthenaの問題点まとめ
・ Firehoseがデータ蓄積するのにタイムラグ(5分程度)がある
・ Firehoseのフォルダ自動作成が問答無用でUTC
・ Firehoseのフォルダ構成だとAthenaのパーテションを手動設定する必要がある
問題点がFirehoseばかりだしそれならS3に直接JSON保存すればいいじゃないかと言われるとその通りだが、
それはそれで実装がめんどくさいのも事実(パーテションしやすいようにフォルダ作って保存とかしないといけない)。
この辺りはなんとも言えないところ。
全体まとめ
RDS使わずにSQLっぽいことができるのはすごい素敵。
ただしそれなりに問題点もあるので適材適所で使い分けたほうがよさそう。
例えば、リアルタイムにデータ蓄積や検索をしたい場合は素直にdynamoDB使ったほうが実装的にもタイムラグ的にも良さげ。
後FirehoseがUTC限定なこと。これのせいで使い勝手がすこぶるよろしくない。