Redshiftについての構成や注意している点について書きたいと思います。Redshiftの説明については、公式資料にお任せする事にして割愛します。簡単に言うと、大容量のデータを高速に検索できる、お値段もちょっと高めのサービスです。
目的
問い合わせ対応で必要になるので、ユーザーのデータ遷移や画面遷移を記録するために利用しています。また、ユーザーの動向やランキングスコアの推移調査等のプランニング目的でも利用しています。
構成
ゲームサーバーからのデータ転送
特にひねりはありませんが、以下のような構成になっています。
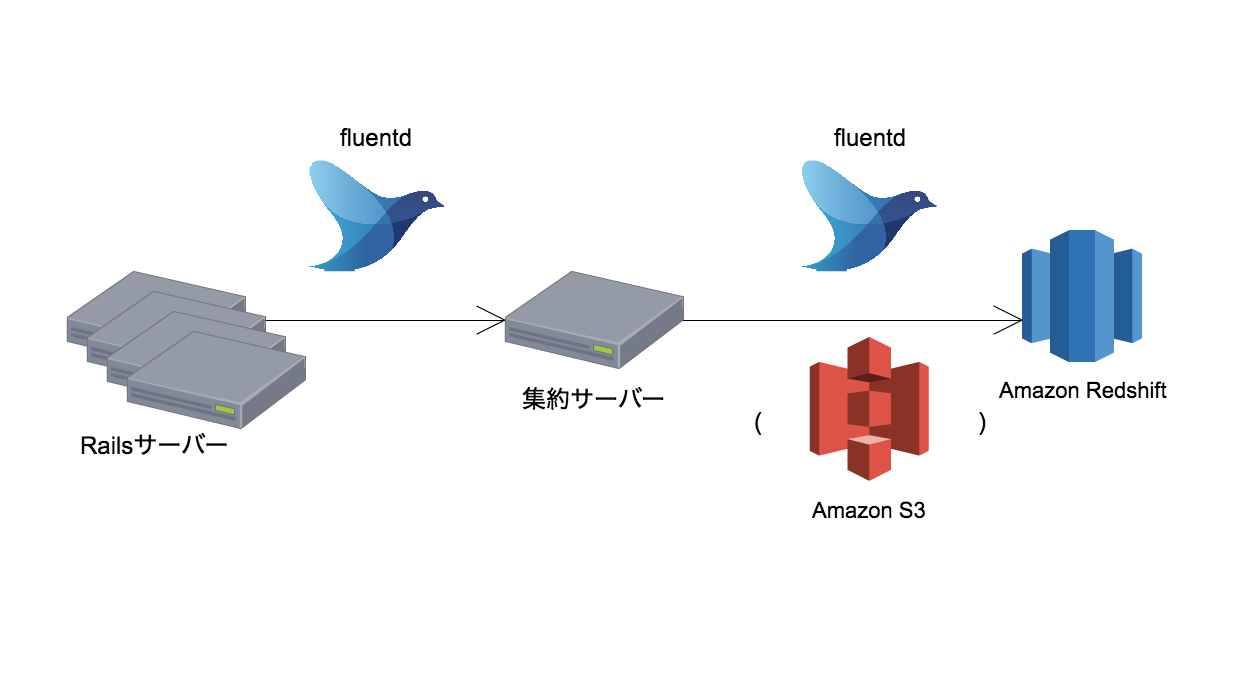
一旦集約サーバーに転送しているのは、Amazon S3へのアップロードを管理したいためです。例えば、複数のRailsサーバーが個別にS3へアップロードすると、名前が重複して上書きしてしまうことがあります。また、Railsサーバーの台数が多くなってくると、個々のサーバーの転送タイミング次第でRedshiftへの接続過多で接続エラーとなる事があります。一旦集約サーバーに集めることで、まとまった量のデータを効率的に転送できるようになります。
Redshiftへの転送にはfluent-plugin-redshiftを利用しています。
問い合わせ対応での利用
問い合わせ対応では非エンジニアのサポートチームが利用するため、ブラウザから検索できるようにしています。
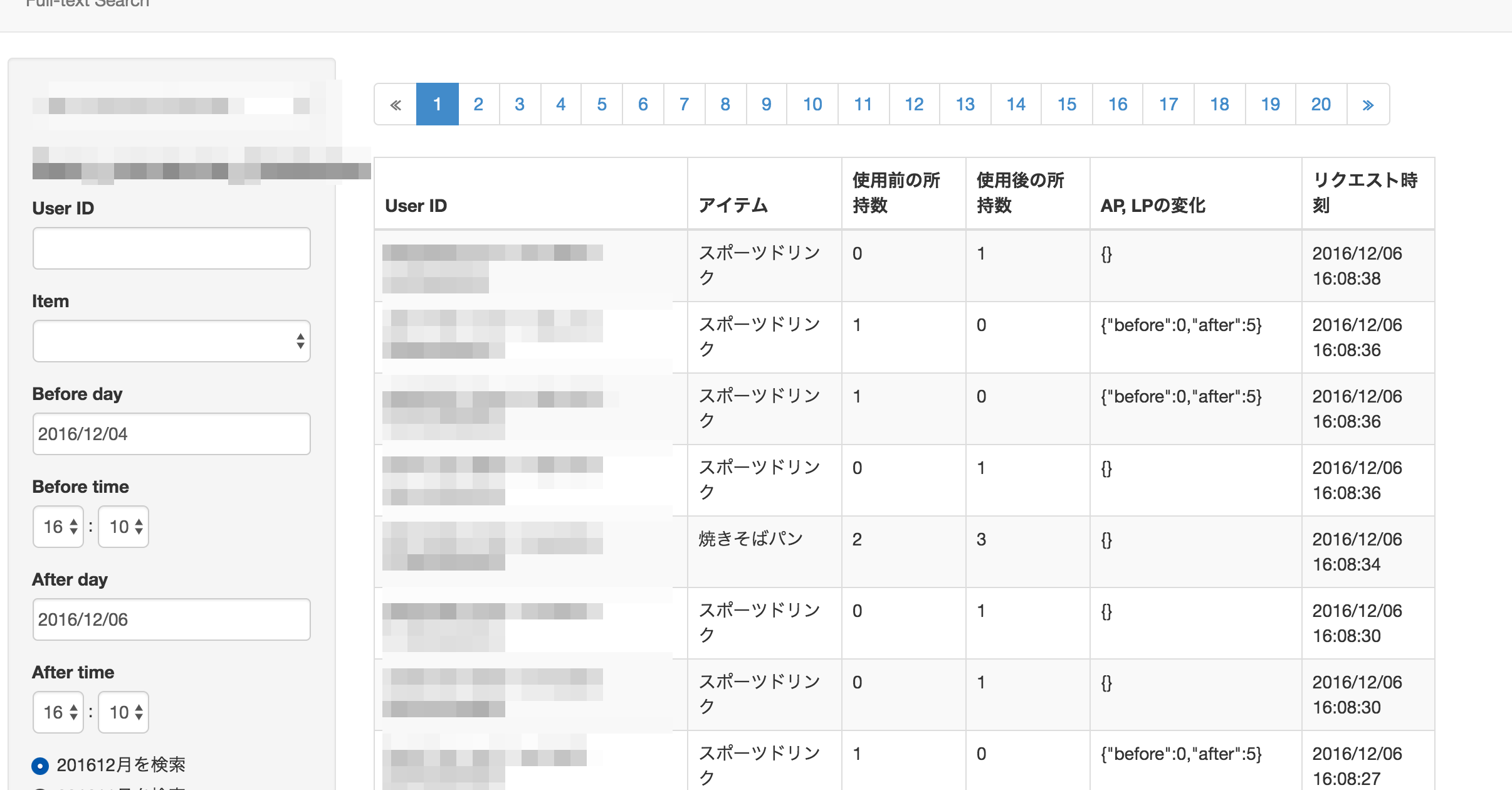
resqueを使ってRedshiftに問い合わせて、その結果を表示するようにしています。最近はRedshift側のチューニングで高速になっているので、100GBクラスのデータでもだいたい5秒以内には結果が返って来ます。
どんなログを取得しているか
- 全リクエストのURLとパラメータのログ(Apacheのaccess.logのようなもの)
- 値の変化のログ(APを消費/回復していくらになった、スコアが上昇した、ジュエルを獲得した、等)
- 解放のログ(ボイスを解放した、ロードのマスを解放した、等)
注意点
基本的なものも含まれますが、運用していく上で気をつけている点です。
sortkeyは適切に設定する
sortkeyはデータ量が増えてくると、顕著にクエリ速度に影響してきます。検索画面からの検索では、sortkeyが設定してある列を必須としています。
テーブルの権限付与を忘れずに
権限漏れだとエラー扱いでそのままデータは紛失します。確認にはテーブル権限と所有者の一覧取得クエリが役に立ちます。
テーブルがVACUUMできない場合の対処法
テーブルが大きすぎると(500GBクラス)、VACUUMしようとすると黙って途中で停止している事があります。そういう状況でも、一度S3にUNLOADしてから別のテーブルにCOPYする事はできます(し、そちらのほうが高速です)。
列圧縮を有効にする
fluent-plugin-redshiftのredshift_copy_optionsに COMPUPDATE ON オプションを付けています。これをしておくと、テーブルの容量を幾分抑える事ができます。
初回投入データの量が足りないと、列の圧縮は適切に設定されないので注意してください。公式資料では10万行程度が必要と記載があります(一応3万行でもできましたが、保証対象外です)。
テーブル作成・列追加は忘れずに
COPYする対象のテーブルが無い場合はエラーとならず、データはそのまま捨てられます。また、列が無くてもよしなに動いてくれてしまう事があり、列追加が漏れていてもエラー無くデータは捨てられてしまう事があります。レビューが終わった段階で支障がなければテーブルを作成/列を追加してしまうか、何らかのタグ付けする等して忘れないよう対策しておくと良いです。
UNLOADする時は必ず ESCAPE
大抵の場合、 ESCAPE オプションが無いと取ったデータは復帰できません(COPYできません)。
テーブル定義は保存しておく
UNLOADしたデータをCOPYで戻す際は、列の順番がUNLOAD時点と同じテーブル構造でないと入らないため、現状の列の順序は記録しておいたほうが良いです(最悪、データを見れば順序は推測はできますが…)
DB容量はSQLクエリを打って確認
DB容量は下記のようなクエリを打って確認します。
select sum(used), sum(capacity),
(sum(used)-sum(tossed))/sum(capacity::numeric) *100 as pctused
from stv_partitions;
AWSコンソールにある Clusters > Performance から見えるディスク使用量は実際のDB容量とは異なるのか、DB容量の参考にはならないようです。
参考までに、容量オーバーの兆候としては、 stl_load_errors にこんな感じのエラーが出始めます。
error: Out of Memory code: 1004 context: node: 1 query
完全に容量いっぱいになると DISK FULL と大量のエラーが出ます。また、fluentdからの転送が滞るので、転送元のサーバーのディスク容量が顕著な増加傾向を示します。テーブル毎の容量はこちらのクエリで計測できますので、容量オーバーしそうな時の対応で利用しています。
大きなテーブルに列の追加・削除を行うなら、テーブルを作りなおしたほうが良い
400GB程度のテーブルに列を追加・削除した事がありますが、テーブルを作り直してデータを移行するだけで、テーブルサイズが30%程度小さくなりました(VACUUM済みの移行前のテーブル容量と比較)。
文字列カラムの最長値はきちんと計測する
配列やハッシュはJSONにして保存する事がありますが、512とか1024とか2048とか、何となく切りの良い文字列長で設定してしまって溢れる事があります。最長値をきちんと測って設定する事をお勧めします。例えば、あんスタの場合、以下のようなデータがあり、最長で280文字でしたが、何となく256文字で設定していて欠損していました。
{"1":4,"2":4,"3":2,"4":2,"5":2,"10":2,"11":2,"12":2,"13":2,"21":2,"22":2,"23":2,"24":2,"31":2,"33":2,"27":2,"30":2,"32":2,"40":2,"41":2,"25":2,"26":2,"29":2,"28":2,"16":2,"17":2,"18":2,"19":2,"20":2,"37":2,"14":2,"15":2,"39":2,"38":2,"8":2,"9":2,"6":4,"7":4,"34":4,"35":3,"36":2}
欠損しているデータがあると、検索時にjson_extract_path_textという便利関数が使えなくなります。