背景
以前投稿した記事
JavaScriptで2次元配列を1次元配列に変換する今風なやり方 reduce + スプレッド演算子(...) しかも速い!!
で hoo-chan さんにコメントを頂きました。
2次元配列を1次元配列に変換するのは、concat+スプレッド演算子でできることがわかり、reduceは必要ないことがわかりました。また、古典的for文の2重ループが遅いことが分かりました。
そして、hoo-chanさんから興味深いコメントを頂きましたので、検証してみました。
- Firefoxなど他のブラウザでどうか?
- アルゴリズムの評価としては「かかった時間」そのものより、配列のサイズを10, 100, 1000, ...とした時の「かかる時間の増え方」がどれくらいなのか?
問題
L × Lの2次元配列dataを1次元配列listにする下記3つの方法について, 配列の大きさLを変化させたとき, Chrome, Edge, Firefoxで実行に要する時間を計測比較する.
方法1: for文の2重ループ
var list = []
for(var i=0;i<L;i++){
for(var i=0;i<L;i++){
list.push(data[i][j]);
}
}
方法2: concat + スプレッド演算子
const list = [].concat(...data);
検証方法
-
ブラウザのversion
- Chrome : 64.0.3282.140
- Edge : 41.16299.15.0
- Firefox : 58.0.2
時間の計測方法
各方法において、100回の試行を実行する前後でperformance.now()を用いて現在時刻を計測し、それらの差分を100で割ることで、100回の平均時間を計測する。配列のサイズ
対数グラフの横軸に合うように対数的にL × Lの2次元配列を用意
2次元配列の要素は全て0
2 × 2 ~ 10 x 10 ~ 100 x 100 ~ 1000 x 1000 ~ 3000 x 3000
結果
一番速いのはChromeの方法2: concat +スプレッド演算子
一番遅いのはEdgeの方法1: for文の2重ループ
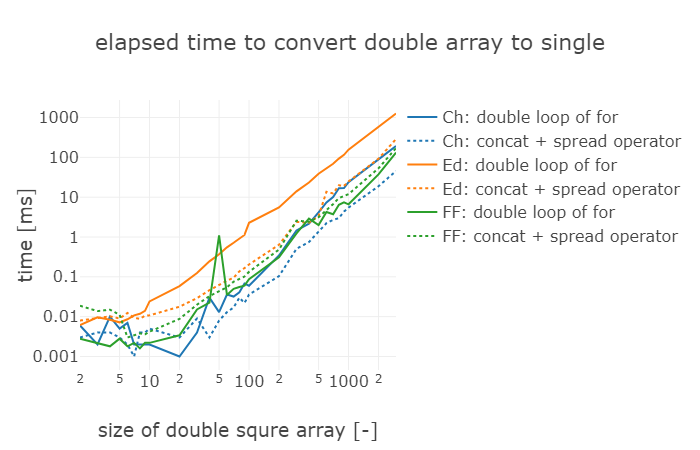
ブラウザの速度順位
1位:Chrome
2位:Firefox
3位:Edge
アルゴリズムの速度順位
1位:方法2:concat + スプレッド演算子
2位:方法1:for文の2重ループ
ただし、Firefoxでは 方法2:concat+スプレッド演算子 よりも 方法1:for文の2重ループ の方が速かった。そして、Firefoxの方法1はChromeの方法1よりもわずかに速かった。
考察
L × Lの2次元配列の要素数はLの2乗で増加する。よって要素を単純にひとつづつ処理するアルゴリズムの場合、両対数グラフの傾きが2になる。一方、Lに比例するアルゴリズムの場合は両対数グラフの傾きは1になる。
方法1について
for文の2重ループは要素をひとつづつ処理するので、Lの2乗に比例して実行時間がかかるはずである。実際、結果のグラフを見ると、いずれのブラウザもそうなっている。
例:Lを100から1000に10倍にすると, Edgeでは5から500へと100倍になっている。
方法2:concat+スプレッド演算子
中のアルゴリズムがどうなっているかはわからないが、結果をみると 方法1:for文の2重ループと同じ傾きである。よって、Lの2乗に比例するアルゴリズムだと分かる。ただし、ChromeとEdgeで方法1よりも速かったのは、1処理当たりの実行を早くする工夫がなされていると考えられる。スプレッド演算子による配列の展開やconcatによるまとめてコピーするのを速める工夫がされているのだろう。
両対数グラフで実行速度をプロットしたとき、アルゴリズムの違いが傾きの違いになるが、定数倍の違いは差分として出てくるので、ひとつの処理当たりの実行速度が速いほど、下にスライドする。
今回のケースでは、Chromeの処理速度が最も速く、Edgeが最も遅い傾向にあった。
同じ方法でも約10倍(縦軸一目盛り分)の差があった。
感想
これがGoogleの力なのか...すげぇ
Firefoxはfor文に熱い思いを込めているのかなぁ。
でもfor文もういらない気がしてきた。
Edgeの実行速度の線形性は美しい(遅いけど)。
他のアルゴリズムでテストしたらどうなるんだろう。
みんな、どのブラウザ使っているのかなぁ。
テストコード
jsnoteにてテスト実施
下記リンク先でrunボタンを押すと方法1~3で実行速度の計測が行われます。
ご自身の環境でテストを実施してみてください。

コンソールに実行速度が出ます。
計算が終わったらdrawエリアに結果が出ます。
exportボタンを押すとjson形式結果がダウンロードされます。
お気に入りの描画ソフトで描画してみてください。
const num = Array.from(Array(9),(k,i)=>i+1);
const exp = Array.from(Array(4),(k,i)=>10**i);
const list = [].concat(...Array.from(exp, k=>num.map(l=>k*l)));
const sampleSizeList = list.slice(1,30);
console.log(sampleSizeList)
const setData = sampleSize => {
const start = performance.now();
const data = Array.from(Array(sampleSize), k=>Array.from(Array(sampleSize),l=>0));
const end = performance.now();
const elapsedTime = (end-start);
console.log(`set ${sampleSize} : ${elapsedTime}`);
return data;
};
const method1 = data => {
const start = performance.now();
const list = [];
for(let i=0;i<data.length;i=i+1){
for(let j=0;j<data[i].length;j=j+1){
list.push(data[i][j]);
}
}
const end = performance.now();
const elapsedTime = end-start;
return elapsedTime;
};
const method2 = data =>{
const start = performance.now();
const list =[].concat(...data);
const end = performance.now();
const elapsedTime = end-start;
return elapsedTime;
};
const speedTest = (data, method) =>{
const elapsedTime = method(data);
console.log(`size ${data.length} : ${elapsedTime} ms`);
return elapsedTime;
};
const go = ()=>{
console.log("set test data");
const data = sampleSizeList.map(k=>setData(k));
console.log("start speed test");
const times = data.reduce((p1,c1) =>{
const N =100;
const time = Array.from(Array(N)).reduce((p2,c2)=>{
p2.m1 += speedTest(c1, method1 );
p2.m2 += speedTest(c1, method2 );
return p2;
},{m1:0, m2:0});
time.m1 /= N;
time.m2 /= N;
p1.method1.push(time.m1);
p1.method2.push(time.m2);
return p1;
},{method1:[], method2:[]});
console.log("end speed test");
const result = {
test: "convert double squre array to single array",
sampleSize: sampleSizeList,
method1: times.method1,
method2: times.method2,
};
return result;
};
const result =go();
あとがき
本記事を最初に投稿したとき、方法3として
方法3: push + スプレッド演算子
const list =[];
Array.prototype.push.apply(list, ...data);
というのを載せました。この方法3はLに比例するアルゴリズム(O(N))であり、最速と思いました。しかし、この方法は意図したとおりに一次元配列を作らないことをhoo-chanさんに指摘していただきました。事前確認したつもりだったのですが、ミスりました。反省です。
そしてこの反省からより深い理解にたどり着きました。
本問題においてO(N)のアルゴリズムは存在しないということです。
もともと方法3を試したのは、サイズLに比例するO(N)のアルゴリズムなのではないかと思ったからです。直感的に2次元配列を1次元にするのなんて、O(N)のアルゴリズムでできるはずと思ってしまったのです。
2次元配列のことをC言語に戻って考えてみました。
C言語で2次元配列を動的に確保する場合, 主に2通りの方法があります。
tondolさんのブログを引用させていただきます。(tondolさんは4つ紹介されています。)
(1) matrix1
matrix1.cint **matrix; int i, j, n, m; n = 100, m = 100; matrix = malloc(sizeof(int *) * n); for (i=0;i<n;i++) { matrix[i] = malloc(sizeof(int) * m); }
(2) matrix2
matrix2.cint **matrix, *base_matrix; int i, j, n, m; n = 100, m = 100; matrix = malloc(sizeof(int *) * n); base_matrix = malloc(sizeof(int) * n * m); for (i=0;i<n;i++) { matrix[i] = base_matrix + i * m; }
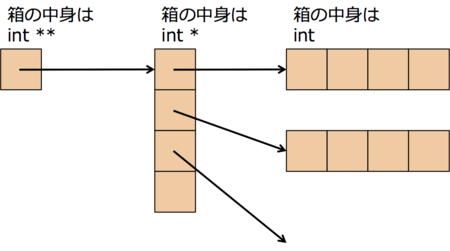
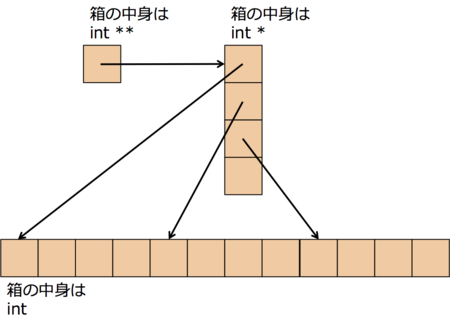
javascriptはどちらの方法で2次元配列を確保しているのでしょうか。
javascriptの代入の自由度の高さから考えて明らかに(1)matrix1です。
ということは、Lの長さの配列がL個ある2次元配列を1列に並べようとしたら、一つずつ持ってきて並べるしかないのです。O(N^2)なのです。麻雀パイを積むようにセット移動はできないのです。コンピュータはひとつづつしか処理してくれません。
もし(2)matrix2で2次元配列を確保できるとすると1次元配列にするには、先頭アドレスを取得すればいいだけです。それはもう一瞬です。O(1)です。でも、それは自分自身を取得しているだけなので、コピーしようと思ったら結局O(N^2)です。
結局いづれにせよ計算量はLの2乗に比例してしまうのです。
方法3の結果がO(N)の計算速度を返したときに、そのおかしさに気づくべきでした。ありえないと。
方法1&方法2以外の書き方をいくつか試してみましたが、方法2が一番早かったです。
2次元配列を1次元配列に変換する最速は[].concat[...data]でFAです。
Firefoxの場合はfor文でループ回してもいいかも...
でも書き手は読み手のブラウザを選べない...