または私は如何にして数学的手法を止めて力ずくで文字列差分を取得するようになったか
序
二つの文字列の差分を抽出したかったんです。
最終的な目的はさておき、まぁやるならうーさんのアルゴリズムを使うことになるんだろう、位に軽く考えていました。
結果—
うーさん、良く分からないよ…
予習
あっちこっち解説サイト(限る日本語)探して読み漁るもイマイチ腑に落ちない。
いや、えー、全体的な流れは大丈夫、きっと分かってる筈。
何がやりたいのかイマイチぴんと来ない。すっごい細かい処の説明に終始していて、それらがどいう風に繋がっているのか伝わって来ない。
それらを最初にきちんと説明して下さいよー、うーさん。
あ、うーさんは説明してくれているのかも知れない。
私、英語不自由な身なので、そこに当たれていないだけ。日本語解説してくれている人たちはそんな事は充分すぎるほど分かってるんで説明する必要性を感じていないのかも知れない。
うん、きっとそうに違いない…
尚これ以降、多分に感覚的な説明が中心になります
数学的・論理的に厳密な話がお好きな方はごめんなさい
確認
取り敢えず最初に、うーさんの方法の目的をおさらいしておこう。
文字列1に対して、「1文字削除」「1文字挿入」を繰り返して、文字列2に変形する方法を計算する。
ルールは以下の通り。
- 下図の「S」の左上(0,0)から「G」の右下(12,10)まで進む
- 但し、格子の線に沿って、
- 右に進む、か
- 下に進む、か
- (格子に対角線が引かれている場合は)対角線を右下に向かって進む、か
の何れかの方向にしか進めない
- 対角線に沿って進む場合のコストを「0(ゼロ)」 格子一マス分進むコストを「1」 として、一番コストの掛からないルートを探してね
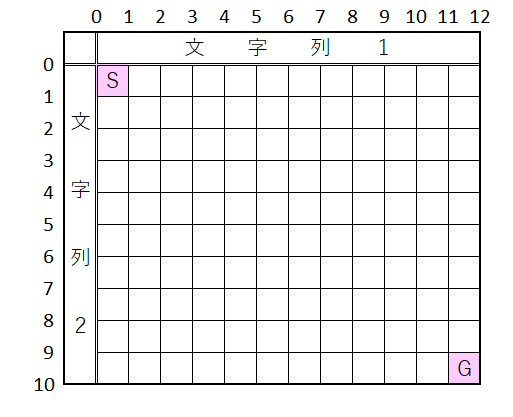
と云う問題ですね。
そこで、うーさんは考えた…
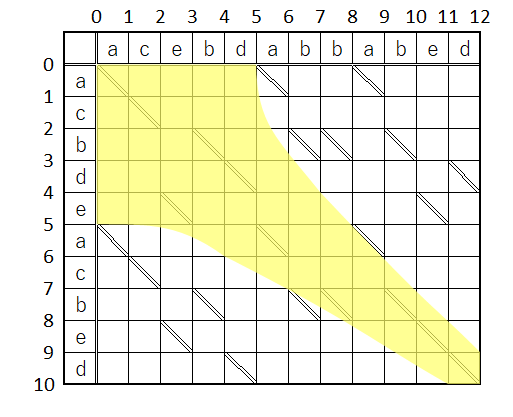
文字列1は文字列2よりDelta文字だけ長いから少なくとも「1文字削除」をDelta回は行う必要があるのは明らか。
逆の表現をすると、コストDeltaで進むためには、以下の図の黄色いマスの格子辺・対角線(ごめん、破線はDelta説明用の補助線として引いただけで、対角線じゃないんです)からはみ出さずに進めた場合だけである。(はみ出さなかったからと云って、コストDeltaで進めるとは限らないけどね)
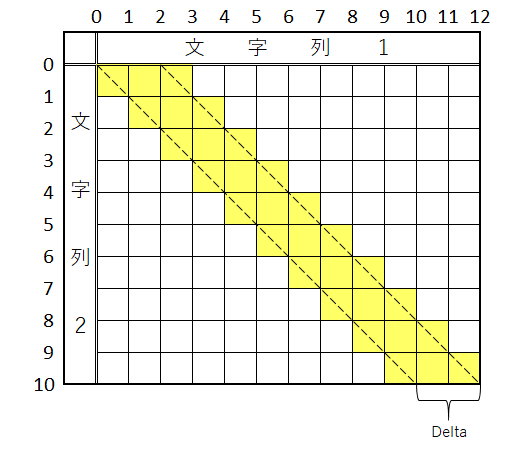
そこで、最小コストはいくつであるかを以下の手順で探っていこう!
と云うのがうーさんの方法である(筈なのである)。
- まず最初に、黄色い枠内だけを可動範囲としてスタート地点(0,0)を出発、コスト
Deltaで進める範囲を探る - もし最小コスト
DeltaでGoalに辿り着けなかった場合は、この黄色の領域を拡張する(緑のマスを拡張しました)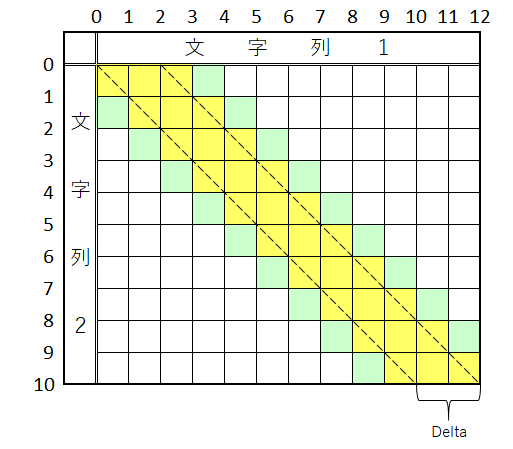
- そしたらこの色付き部分を可動範囲として、コスト
Delta + 2で進める範囲を探る
なんで+2するかって?
う~ん… 取り敢えず、上下に可動範囲を一マスづつ拡張したから、程度で納得して下さい - それでもGoalに辿り着けなかった場合は、更に上下に一マスずつ拡張してコストもゆるくしてGoalを目指す、ってのを繰り返すうちにGoalに辿り着く最小コストにぶち当たる筈(と云うか必ずGoalに辿り着ける最小コストが存在する)
上記がうーさんの論理構成じゃないかと理解した。
そして可動範囲を絞りながら、そこに許されたコストで進める範囲を上手い事判定するナイスな方法が存在する! と云うのがうーさんアルゴリズムの肝。
で、そのナイスな方法ってのは先達の皆さんが解説して下さっている。
例えばこちら。
その方法の解説に関してはそちらにお任せしよう。
実は、私が今分かっている所はここまで。
という事が分かったよ。(ナイスな方法ってのが充分理解できていない事も含めて)
ふー
自習
致し方ないので、うーさんのアルゴリズムを実装。各種状態をトレースして確認作業をしていこう。
以降、例としては基本的にうーさんの論文にある文字列を使う。
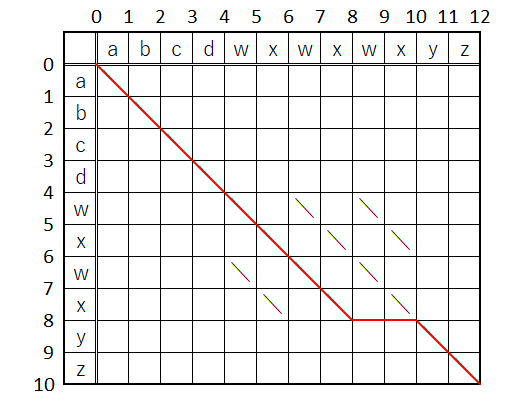
これね↓(この表の作成法に関しては前述のサイトなどを参照して下さい)
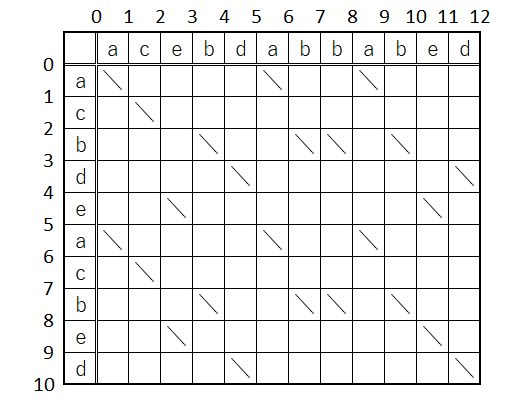
で、こんな感じのコードでテストをしたと思ってね。
※ VArrayについては別稿を参照のこと。(これがやりたかったのだよ)
string strX = "acebdabbabed";
string strY = "acbswacbed";
int delta = strX.Length - strY.Length;
VArray<int> fp = new VArray<int>(-(strY.Length + 1), strX.Length + 1);
for(int i = fp.LBound; i <= fp.UBound; i++)
fp[i] = -1;
for(int p = 0; ; p++) {
for(int k = -p; k < delta; k++)
fp[k] = Snake(k, Math.Max(fp[k - 1] + 1, fp[k + 1]));
for(int k = delta + p; k > delta; k--)
fp[k] = Snake(k, Math.Max(fp[k - 1] + 1, fp[k + 1]));
fp[delta] = Snake(delta, Math.Max(fp[delta - 1] + 1, fp[delta + 1]));
if(fp[delta] == strX.Length)
break;
}
int Snake(int k, int x) {
int y = x - k;
while(x < strX.Length && y < strY.Length && strX[x] == strY[y]) {
x++;
y++;
}
return x;
}
おー、ここで思い出した。
うーさんの論文では、縦軸を
x・横軸をyで表すと云う変態グラフが使われているんですが、何とも取っ付き難いので本稿では一般的な数学グラフと同じyを縦軸・xを横軸になる様に表現しておりま…あれ? 数学グラフでもないぞ…
Windowsディスプレイの座標系だ
fp[]の値が気になるところなので、そこを中心に攻めてみる。
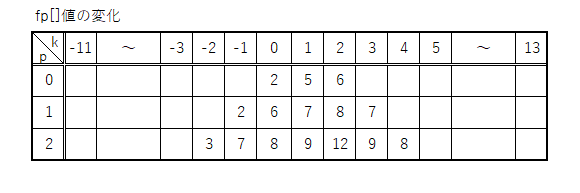
で、こっちから法則性を検証してみるという事で。
ふむふむ、あぁ~、なるほど。
ここで、例の図が出てくる訳ね。
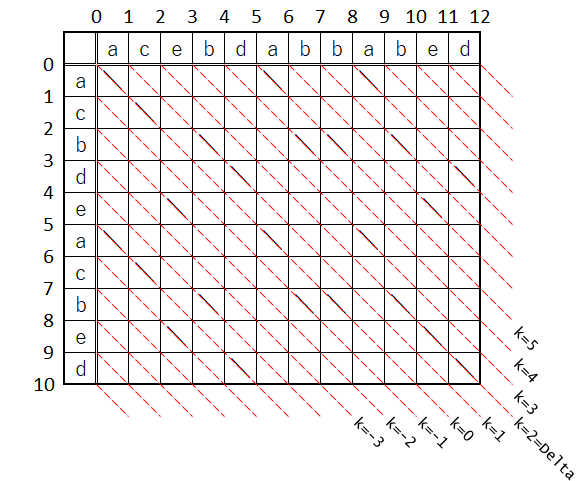
fp[]はこの赤破線群に対応している訳だ。そしてその中身は「最遠点」って言われてるxの値だな。ただここでは最遠点が何であるかは置いとこう。いずれ明らかにするつもりで…
そう云う事でkの値はこのラインの識別子で、取り敢えずpの方は「寄り道レベル」とでも名前を付けちゃって、k=0のラインを「スタートライン」、k=Deltaのラインを「ゴールライン」、全体を纏めて「Kライン」と呼ぶ事にしよう。
もう一つ、最初に(0,0)位置に赤丸を置いて、これを「カレントポジション」って名前を付けましょうか。
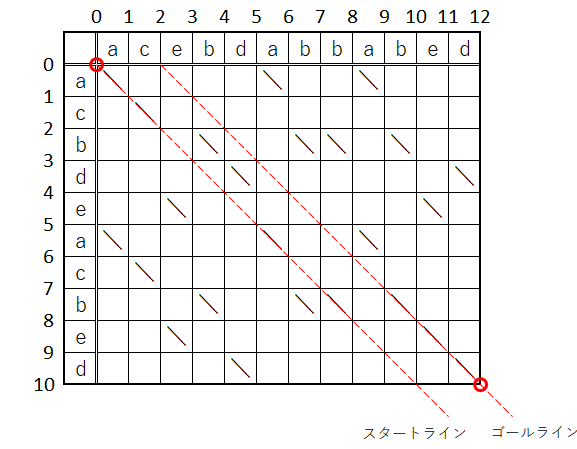
そこで、既出のルールを改めてここにマッピングすると、やりたい事は次の様になるかな。
- 「スタートライン」上の
(0,0)位置にある「カレントポジション」を、許容コスト内で「ゴールライン」の先端位置(12,10)まで持って行きたい - 許容コスト内でゴールに着けなかった場合は「寄り道レベル」を上げながら上記を繰り返す
一応確認までにここで再掲するが、カレントポジションの移動方向についての制約が存在する事と、寄り道レベルに応じて許容されるコストに上限がある事を忘れてはいけない。
なので、ゴール判定ってのが次の式で表される。
if (fp[Delta]==文字列1.Length) ゴール!
つまり—
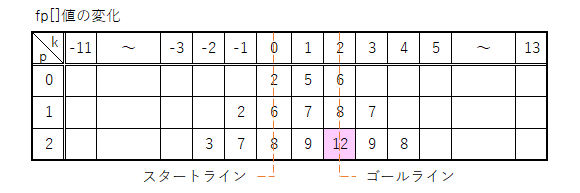
fp[]表を寄り道レベル毎に評価を繰り返して、最終的にゴールライン上にあるfp[Delta]の値が文字列1.Lengthになった時が終着点って事になる。
で、最遠点の意味が分かった。各寄り道レベルにおける許容コストで進めるx方向の最大値だ!
って、何だそのままじゃん。
さて、ここからが正念場。
fp[]の値はどうやって導かれるか、だ。
上手く説明できるかな…
寄り道レベルpにおけるfp[n]の値は、寄り道レベルp-1におけるfp[n-1]とfp[n+1]の値から導かれる—
ってのが、うーさんの云いたい事だ。
何故ならば、k=nのライン上にカレントポジションを移動させるという事は、取り敢えず隣のKラインから移ってくるしか方法はないからね。(対角線に関しては後述するので、ここでは対角線はない状態だけを考えてください)
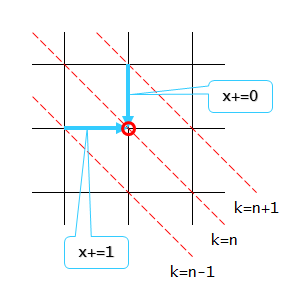
カレントポジションの移動制限と考え合わせると、k=n-1ラインから移ってきたときにはx方向には1マス分進めるが、k=n+1ラインから移ってきた場合にはx方向への進展はない。
また、k=nラインへの移動が行われるパターンが二つ存在する(k=n ± 1)けど、k=nの評価としてはそのうちのより値の大きい方を採用すれば良い、と云うのは特に問題ないよね。
ところで、fp[n]ラインを評価した結果、その位置に対角線があったらどうなるだろう?
「そりゃぁ思わず脚踏み外して滑り落ちていくよねー」って云うのがうーさんのSnake関数だ。(私的にはSlopeとかSliderとかそういう名前にしたい所だな)
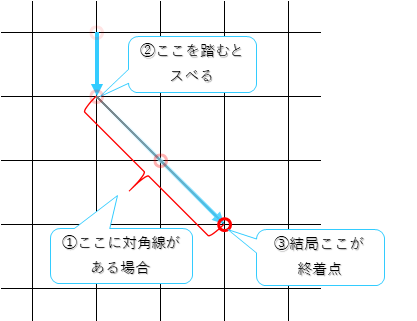
結果、落ちるところまで落ちた先のx値が最終的な評価結果になるって訳。
上での結果を文章に起こすと—
寄り道レベル
pにおけるfp[n]は、寄り道レベルp-1におけるfp[n-1] + 1とfp[n+1]のうち、大きい方の値をSnake関数で評価した結果となる
さて、ここから最後の仕上げ。
各々の寄り道レベルにおけるfp[]値を、「具体的に」どうやって算出していくかだ。
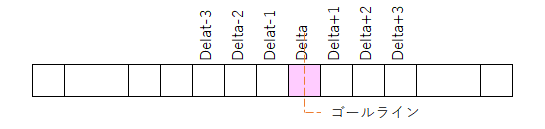
計算のゴールを再確認しておこう。
ゴールライン上の
fp[Delta]の値が文字列1.Lengthの値に等しくなったとき
つまり、下の図のピンク色の所を計算で求めよう!
ってのが目的だな。
で、前述したように、fp[Delta]の値はfp[Delta ± 1]から導かれる。
こういう事(下図)。
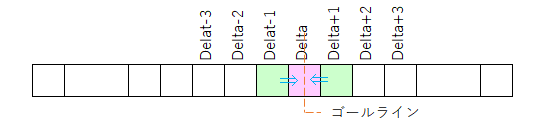
ちゅー事は、fp[Delta]の値を求める前には、まずはfp[Delta - 1]の値が判明していなくてはならない。
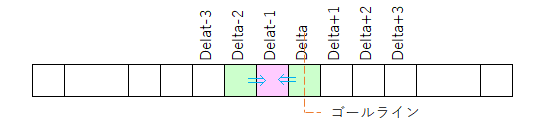
で、fp[Delta - 1]の値を求める前にはfp[Delta -2]の値が確定していなくてはならない。fp[Delta - 2]の値が(以下繰り返し)…
結局、こういう事。
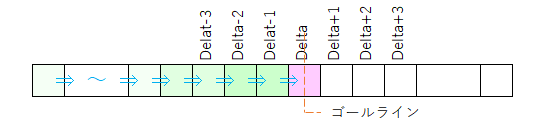
だから、fp[-p]からfp[Delta - 1]までfp[]値を確定させていく。つまりゴールラインに向かってfp[]値を確定させていく訳ですね。
ゴールラインの右側も同様にゴールラインに向かって確定させていけばいいので、fp[Delta+p]から始めてfp[Delta + 1]までfp[]値を確定させていく。
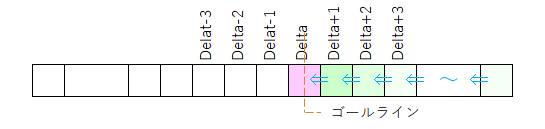
そこまで行って最後のダメ押し、fp[Delta ± 1]の値を使ってfp[Delta]の値を決定すれば、寄り道レベルpにおけるfp[]値が全て確定する。
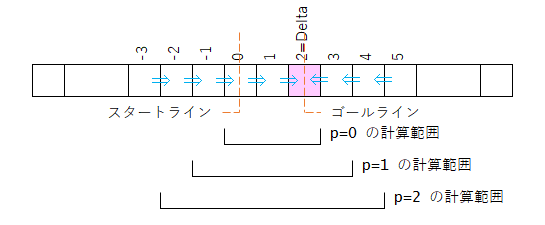
この一連のfp[]値決定プロセスを繰り返して、fp[Delta]の値が文字列1.LengthになればComplete、繰り返した回数が「寄り道レベルp」って事だ。
ふー、長かったけど達成感![]()
憂鬱のタネ
よしっ、じゃぁ早速文字列の差分を計算してみよう!
って、あれ?
今まで解き明かしてきた方法で分かったのは、寄り道レベルだけだぞ。
上の例では寄り道レベルp=2だったので、文字列変換をするのにp * 2 + Delta = 6 回の1文字削除・1文字挿入が必要になるよー、ってのが判明しただけ。
うん、識者の方々も変換手順を実装するには、それ用のコードが必要だと仰っておられる。ルート探索に一番メモリが必要だとも言っている。
うーん…
と云うのが、第一のタネ。
ま、それはちょこっと横に置いといて、力技でルート探索しましたよ。ただ余りにも力技過ぎて恥ずかしいのでソース掲載は控えたい。
で、ルートを結んで出てきたのが下図。
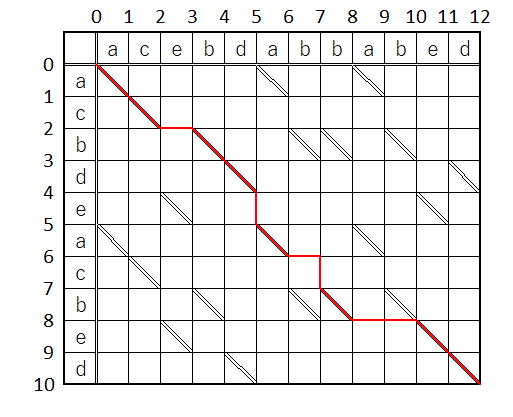
違和感満載…
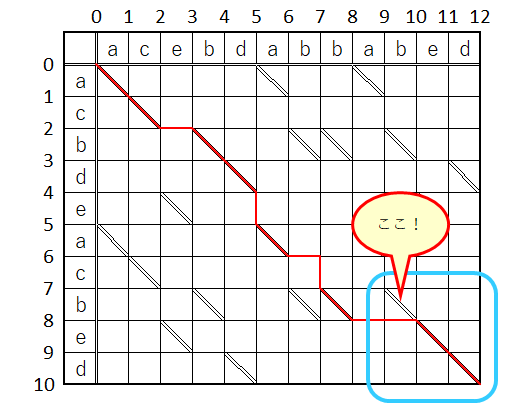
なんで、最後の3文字セットを採用しないかなぁ…
人間の感覚には合わないよね。
所詮、LCSを求めるための数学的アルゴリズムであって、自然なルートを探索するアルゴリズムではない…
んだろうなと激しく思った。
と云うのが、第二のタネ。
そんじゃ、うーさんアルゴリズムを改良して、上記悩みを解決しよう!
って意気込んではみたものの、それ無理ですから。
結局、うーさんのSnake関数の呪いですね。だって坂道踏んだら必ず滑りこけてしまうんだもん。その先にもっと良い手があるかも知れない、何てTry&Errorしてたら、折角の綺麗なアルゴリズムが台無しになってしまう。
早い話が、うーさんのアルゴリズムはLCS求める以外には使い出がない、って事になるんですかねぇ…
全探索をする訳でもなく最小の手数だけで答えを探索しているからね。
綺麗なアルゴリズムなんだけどなー
対策
そこで、私は考えた…
これは虱潰すしかないな。(安直)
しかし、虱潰すっても効率の良い潰し方がある筈。
うむうむ、折角うーさんが良い表を作ってくれてるし、あれを利用しない手はないよ。
方針としては、うーさんのアルゴリズムでは思わぬ伏兵であった「スライダー」。あの一覧を作って、その総当たりって事で如何でしょう?
対象としては、マス一辺ずつ相手にするより遥かに少ないよね。
しかも、連続する対角線はそれを1スライダーとして扱う、となると横入りはなくなるので、人間っぽいルートが常に提示される筈。
つまり、抜き出したスライダー全てに対して総当たりを行って、例えば下図の様な順番でスライダーが選ばれたとしたらその間を横・縦のマス移動で補完することにより、全体のルートを確定させるという寸法だ。
でも、これだけではまだ効率が悪い。ここでうーさんのアイディアをパクっ参考にさせて頂いて、更に探索対象を絞っていこう。勿論ここで採用すべき考え方は「寄り道レベル」だ。
つまり、寄り道レベルp=0なら、この黄色い範囲のスライダーのみ対象とする。
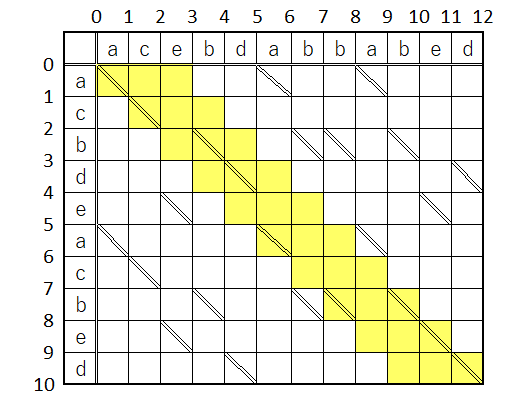
寄り道レベルp=1ならば、上下に一マスずつ拡張したこの色付きの部分に含まれるスライダーのみ対象とする…
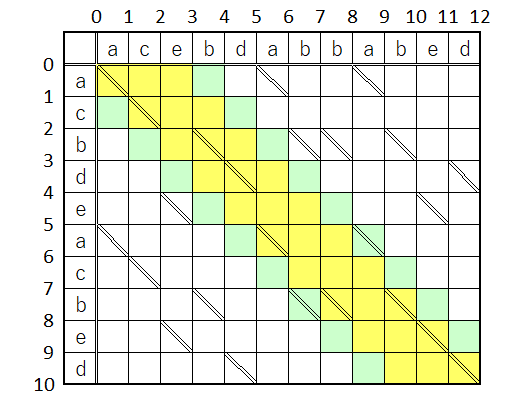
ってな感じでね。
見るからに対象が絞られる感満載でしょ?
でもまだまだ。
進行方向に向かって、90度の範囲にあるスライダーだけを対象にすれば事足りる。
これに先の寄り道レベルが組み合わされる訳で、ぐぐっと対象が絞られる。
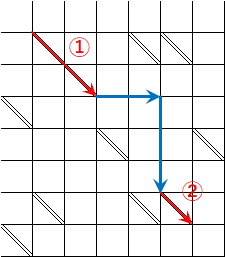
もう一つ言うと、それぞれのスライダーが選ばれる毎に許容されるコストが消費されるので、コストが底を尽きたタイミングで探索を中断する事も有効な対策であるし、残りコストから許容コストを動的に絞る事も可能だ。
あー、感覚的過ぎる…
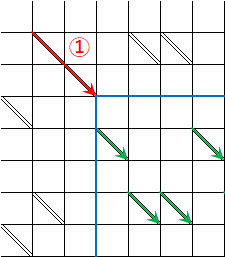
つまり、寄り道レベルp=0の場合許容されるコストはDeltaだけだから、下図の①の様にいきなりコストDeltaを使い切ってしまった場合は、青線で示されるように、ゴールに向かって滑り落ちていくルートしか残されていない。この(①のコストを使い切った)時点で黄色い許容範囲は青い線上に収束してしまう、と言える訳だ。
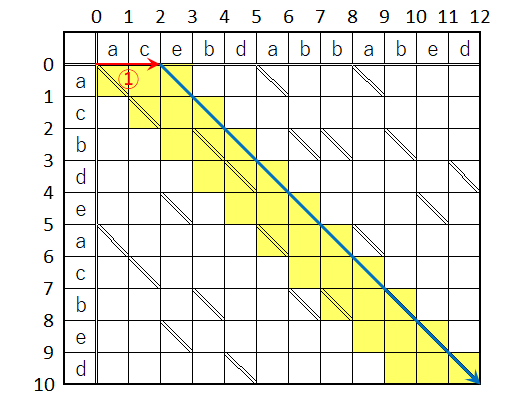
この手順の全体的なイメージを表現すると、下図の様に探索範囲が狭められていく筈(なんだろう)。
ところでこれ以上話を進める前に、横入りナシと云う制限を設けても横入りアリよりコストが掛かるケースが存在しない事を保証しなければならない。そこをここで確認しておこう。
とか言いながら実は、こんな文字列だったら…
今更だけど、横入りしないと最小コストでゴールできないなぁ…
これは困った。
「最小コスト」ってのと「イイ感じの手順」ってのが両立しないぞ。
方針
ま、それはそれとして色々出揃ったので、今後の方針を纏めてみよう。
「最小コスト」と「イイ感じ」が両立しないのであれば、解法も二階層にならざるを得ない。
色んな二階層があると思うんですが—
んんんー、今回は次の手法で行きましょう。
- 寄り道レベルが最小のルート全てを求める(横入りアリ)
- 「イイ感じ度」を数値化、其々のルートを評価して一番イイ感じのルートを一つ選び出す
ナイスっ!
全ルートを求めるのは、スライダーの総当たり作戦で。
イイ感じ度は以下の様にして図れば良いかな。
- SES上の要素長さの自乗和を計算、でかい方が勝ち
SES上では連続する文字削除・文字挿入が其々一纏めに表現されているとする - ま、それでも同率首位ってのはあるだろうから、そこは先着順ででも
実装
まずはメイン部分から。
こんな感じで書くと結果が表示されると云う寸法。
using System;
using System.Collections.Generic;
using System.Linq;
class Program {
static void Main(string[] args) {
foreach(StringDiff diff in GetDifference("acebdabbabed", "acbdeacbed").OrderByDescending(s => s.Similarity)) {
Console.WriteLine("---{0:0.00000}---", diff.Similarity);
foreach(string info in diff.Items)
Console.WriteLine(info);
Console.WriteLine();
}
}
}
うーさんのサンプル文字列の比較では、以下の4パターンが導き出された。
何れも6文字分の寄り道をしているので、寄り道レベルは2って事で先の例と一致。
類似度に関しては絶対値だと良く分からないので、相対比較ができるように0.0~1.0の範囲での評価結果を得られるように調整してみた。(適当ですけど)
先で気になった点に関して云えば、期待通り3文字削除の方が評価結果が高いという事に落ち着いて一先ずは意図した通りの動きをしているんだろうなぁ、という感想。
気に入った点は、比較対象と被比較対象の文字列の長さの制約がない処。ま、総当たりで探索しているからね、当たり前っちゃ当たり前。
---0.43125---
ac
- e
bd
- abb
+ e
a
+ c
bed
---0.43125---
ac
- e
bd
+ e
a
- bba
+ c
bed
---0.41042---
ac
- e
bd
+ e
a
+ c
b
- bab
ed
---0.33542---
ac
- e
bd
+ e
a
- b
+ c
b
- ab
ed
それでは、以下細かい処へ…
class Program {
:(既出のMain())
// globalな変数(う~ん)
static List<Slider> SliderList = new List<Slider>();
static Stack<Slider> stack = new Stack<Slider>();
/// <summary>
/// 文字列の差分情報を1セットずつ返す
/// </summary>
/// <param name="strX">比較対象文字列1</param>
/// <param name="strY">比較対象文字列2</param>
/// <returns>文字列差分情報</returns>
static IEnumerable<StringDiff> GetDifference(string strX, string strY) {
int delta = Math.Abs(strX.Length - strY.Length);
int minlen = Math.Min(strX.Length, strY.Length);
//************************
// Sliderを洗い出す
//************************
SliderList = new List<Slider>();
SliderList.Add(new Slider(Location.Origin, Location.Origin));
for(int y = 0; y < strY.Length; y++) {
for(int x = 0; x < strX.Length; x++) {
if(strX[x] != strY[y]) continue;
if(x != 0 && y != 0 && strX[x - 1] == strY[y - 1]) continue;
int dx = x;
int dy = y;
Location sLoc = new Location(dx, dy);
while(dx < strX.Length && dy < strY.Length && strX[dx] == strY[dy]) { dx++; dy++; }
Location eLoc = new Location(dx, dy);
SliderList.Add(new Slider(sLoc, eLoc));
}
}
SliderList.Reverse();
//************************
// 総当たりを仕掛ける
//************************
Location Goal = new Location(strX.Length, strY.Length);
for(int p = 0; p <= minlen; p++) {
foreach(Slider slider in GetSlider(new Slider(Goal, Goal), delta + p * 2)) {
StringDiff Diff = new StringDiff();
Location last = new Location();
foreach(Slider curr in stack) {
int del = curr.StartLoc.x - last.x;
int add = curr.StartLoc.y - last.y;
int sty = curr.EndLoc.x - curr.StartLoc.x;
if(last.x > curr.StartLoc.x || last.y > curr.StartLoc.y) {
if((last.x - last.y) < (curr.StartLoc.x - curr.StartLoc.y)) {
del = (curr.StartLoc.x - curr.StartLoc.y) - (last.x - last.y);
add = 0;
sty = curr.EndLoc.x - last.x - del;
} else {
del = 0;
add = (last.x - last.y) - (curr.StartLoc.x - curr.StartLoc.y);
sty = curr.EndLoc.y - last.y - add;
}
}
if(del != 0) Diff.DeleteString(strX.Substring(last.x, del));
if(add != 0) Diff.InsertString(strY.Substring(last.y, add));
if(sty != 0) Diff.AsItIsString(strX.Substring(curr.EndLoc.x - sty, sty));
last = curr.EndLoc;
}
p = minlen;
yield return Diff;
}
}
}
/// <summary>
/// 次に進めるスライダを洗い出す
/// 候補スライダを返す度にルートスタックを更新する
/// </summary>
/// <param name="slider">カレントスライダ</param>
/// <param name="distance">ゴールまでに残された距離</param>
/// <returns>次に進んでも良いスライダ</returns>
static IEnumerable<Slider> GetSlider(Slider slider, int distance) {
if(distance < 0)
yield break;
stack.Push(slider);
if(slider.EndLoc.IsOrigin)
yield return slider;
int delta = Math.Abs(strX.Length - strY.Length);
foreach(Slider locs in SliderList)
if(!slider.Equals(locs) && slider.EndLoc.x >= locs.EndLoc.x && slider.EndLoc.y >= locs.EndLoc.y)
if(slider.StartLoc.Equals(slider.EndLoc) || (slider.EndLoc.x != locs.EndLoc.x && slider.EndLoc.y != locs.EndLoc.y))
if((locs.StartLoc.x + (distance - Math.Ceiling(delta / 2F)) >= locs.StartLoc.y) && (locs.StartLoc.x - (distance + Math.Ceiling(delta / 2F)) <= locs.StartLoc.y))
foreach(Slider slope in GetSlider(locs, distance - slider.StartLoc.Distance(locs.EndLoc)))
yield return slope;
stack.Pop();
}
}
サポートクラス
public class Location {
public Location() : this(0, 0) {
}
public Location(int x, int y) {
this.x = x;
this.y = y;
}
public int x;
public int y;
public static readonly Location Origin = new Location();
public bool IsOrigin { get { return this.Equals(Origin); } }
public int Distance(Location loc) {
if(loc.x < this.x && loc.y < this.y)
return Math.Abs(this.x - loc.x) + Math.Abs(this.y - loc.y);
else
return Math.Abs((this.x - this.y) - (loc.x - loc.y));
}
}
public class Slider {
public Slider(Location sLoc, Location eLoc) {
this.StartLoc = sLoc;
this.EndLoc = eLoc;
}
public Location StartLoc { get; private set; }
public Location EndLoc { get; private set; }
}
public class StringDiff {
List<string> Operation;
public StringDiff() {
this.Clear();
}
public void Clear() {
Operation = new List<string>();
}
public void DeleteString(string Substring) {
Operation.Add("- " + Substring);
}
public void InsertString(string Substring) {
Operation.Add("+ " + Substring);
}
public void AsItIsString(string Substring) {
Operation.Add(" " + Substring);
}
public IEnumerable<string> Items {
get {
foreach(string item in Operation)
yield return item;
}
}
public double Similarity {
get {
double rdel = Ratio("- ") * 0.9;
int cdel = Math.Sign(rdel);
double radd = Ratio("+ ") * 0.9;
int cadd = Math.Sign(radd);
double rsty = Ratio(" ") * 1.0;
int csty = Math.Sign(rsty);
return (rdel + radd + rsty) / (cdel + cadd + 1);
}
}
double Ratio(string type) {
double len = Operation.Where(s => s.StartsWith(type)).Sum(s => s.Length - 2);
double sum = Operation.Where(s => s.StartsWith(type)).Sum(s => Math.Pow(s.Length - 2, 2));
return len == 0 ? 0 : sum / Math.Pow(len, 2);
}
}
尚、類似度最大の候補を一つだけ受け取ればよい場合は、Main()を以下の様にすれば良い。
static void Main(string[] args) {
StringDiff diff = GetDifference(strX, strY).OrderByDescending(s => s.Similarity).Take(1).ToArray()[0];
Console.WriteLine("---{0:0.00000}---", diff.Similarity);
foreach(string info in diff.Items)
Console.WriteLine(info);
Console.WriteLine();
}
結
ん~~~
やっぱり力ずくはイマイチ美しさが足りないかなぁ…
そして、色んな意味で分かり難くて申し訳ない。
タイトルに関していえば、ただ単に「う」を一杯使ってみたい衝動に抗えなかったのです…