(ベンチマークテストに関して,追記しました.)
先日,Coursera, Machine Learning コース (by Stanford University, Prof. Andrew Ng) のプログラミング課題(Matlab)をPythonに移植しながら楽しむ方法についてQiitaに投稿させていただいた.その後コースの受講も進んだが,Week 10から楽しみにしてきたプログラミング課題が無いことを知った.(全11週の内,Program AssignmentがあるのはWeek 1からWeek 9までです.因みにQuizは,Week 10, 11でもあります.)
Week 10は,"Large Scale Machine Learning"ということで,Stochastic Gradient Descent (SGD,確率的勾配降下法) やOnline Learningについての講義で興味深かったが,プログラミング課題がない,ならば自習してしまおうということで,PythonによるSGDの実装を行った.(SGDの実装と一緒に,Deep Learning Framework, "Theano"についても勉強してしまおうという試みである.)また,SGD実装後に行ったベンチマークテストで少し興味深い結果(tips)を得たので紹介する.
Video講義の概略 (Week 10)
Videoでは通常の勾配降下法(Batch Gradient Descent) と対比させて確率的勾配降下法(Stochastic Gradient Descent)について説明されている.
Batch Gradient Descent
コスト関数:
J_{train}(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_{\theta} (x^{(i)})
- y^{(i)} ) ^2
このコスト関数を最小化するために以下の反復計算を行う.
Repeat {
{\theta}_j := {\theta}_j - \alpha \frac{1}{m} \sum_{i=1}^{m}(h_{\theta} (x^{(i)}
-y^{(i)} ) x_j^{(i)}
\\ \ \ \ \ \ \ \ \ \ (\textbf{for every } j=0, ..., n)
}
Stochastic Gradient Descent
1. Randomly shuffle (reorder) training examples
訓練用データをランダムシャッフルする.
2. 以下,訓練データを1つずつ 参照して $ \theta $を更新する.
Repeat {
for\ i:= 1,...,m {\ \ \ \ \ \ \{\\
{\theta}_j := {\theta}_j - \alpha (h_{\theta} (x^{(i)}) - y^{(i)}) x_j^{(i)}
\\\ \ \ (\textbf{for every } j=0, ...,n)
\\\ \ \ \}
\ \ }
}
講義では1つずつ訓練データを参照してパラメータを更新するやり方をまず初めに説明し,その後に(Batch Gradient DescentとStochastic G.D.の間のやり方として)Mini-Batch Gradient Descentがあるとの説明があった.
通常の勾配降下法の実装(ロジスティック回帰)
コードの確認に使うデータであるが,UCI Machine Learning Repositoryから"Adult"データセットを選んでみた.これは米国 Census databeseから抽出されたもので機械学習でも人気があるデータのようである.
39, State-gov, 77516, Bachelors, 13, Never-married, Adm-clerical, Not-in-family, White, Male, 2174, 0, 40, United-States, <=50K
50, Self-emp-not-inc, 83311, Bachelors, 13, Married-civ-spouse, Exec-managerial, Husband, White, Male, 0, 0, 13, United-States, <=50K
38, Private, 215646, HS-grad, 9, Divorced, Handlers-cleaners, Not-in-family, White, Male, 0, 0, 40, United-States, <=50K
53, Private, 234721, 11th, 7, Married-civ-spouse, Handlers-cleaners, Husband, Black, Male, 0, 0, 40, United-States, <=50K
28, Private, 338409, Bachelors, 13, Married-civ-spouse, Prof-specialty, Wife, Black, Female, 0, 0, 40, Cuba, <=50K
年齢,学歴,職業タイプ,結婚歴などが並ぶが,各行の一番後ろにあるのが,収入クラス "<=50K" or ">50K" のラベルである.これが分類に使う被説明変数になる.
回帰に使う説明変数(feature)として何を選ぶか悩ましいところだが,今回は,1つだけ,学校在籍年数を選んでみた.学歴のやや分解能が高いものと考えられるが,これが収入とリンクすることは世界共通と思われる.
Coursera Machine Learningのこれまでの課題のやり方に従い,コスト関数とその偏微分係数(gradient)を算定する関数を定義するところから始める.
import numpy as np
import pandas as pd
import timeit
import theano
import theano.tensor as T
def load_data():
(略)
return xtr, ytr, xte, yte
def compute_cost(w, b, x, y):
p_1 = 1 / (1 + T.exp(-T.dot(x, w) -b)) # same as sigmoid(T.dot(x,w)+b)
income_class = lambda predictor: T.gt(predictor, 0.5) # 0.5 is threshold
prediction = income_class(p_1)
xent = -y * T.log(p_1) - (1-y) * T.log(1- p_1)
cost = xent.mean() + 0.01 * (w ** 2).sum() # regularization
return cost, prediction
def compute_grad(cost, w, b):
gw, gb = T.grad(cost, [w, b])
return gw, gb
フレームワーク"Theano"の特徴で,(慣れないと分かりにくいが)慣れればとても簡潔にステートメントをまとめられるようだ.(特にgradientの算定は1行で済む.)
これらの関数を使ってメインの処理を行う.
xtr, ytr, xte, yte = load_data()
# Declare Theano symbolic variables
xtr_shape = xtr.shape
if len(xtr_shape) == 2:
w_len = xtr_shape[1]
else:
w_len = 1
x = T.matrix('x') # for xmat
y = T.vector('y') # for ymat, labels
w = theano.shared(np.zeros(w_len), name='w') # w, b <- all zero
b = theano.shared(0., name='b')
print ' Initial model: '
wi = w.get_value()
bi = w.get_value()
print 'w : [%12.4f], b : [%12.4f]' % (wi[0], bi)
cost, prediction = compute_cost(w, b, x, y) # ... Cost-J
gw, gb = compute_grad(cost, w, b) # ... Gradients
# Compile
train = theano.function(
inputs=[x,y],
outputs=[cost, prediction],
updates=((w, w - 0.1 * gw), (b, b - 0.1 * gb)),
allow_input_downcast=True)
predict = theano.function(inputs=[x], outputs=prediction,
allow_input_downcast=True)
# Train (Optimization)
start_time = timeit.default_timer()
training_steps = 10000
xtr= xtr.reshape(len(xtr), 1) # shape: (m,) to (m,1)
for i in range(training_steps):
cost_j, pred = train(xtr, ytr)
以上,コスト関数を最小化するパラメータ(w, b)を勾配降下法(Batch Gradient Descent)により求めた.収束判定は行っておらず,所定回数のパラメータ更新にて解を求めている.
Stochastic Gradient Descentの実装
さて本題のStochastic Gradient Descent (確率的勾配降下法)の実装である.Couseraの講義では,学習に使うデータを1組ずつスキャンする(pure) Stochastic Gradient Descent と小さいサイズの2~100組ずつデータをスキャンするMini- Batch Stochastic Gradient Descentの説明があったが,ここでは,Mini-Batchの方を選ぶ.
SGDでは,前処理として訓練用データのランダムシャッフルを行う.また,処理の高速化のため,データをTheanoの共有変数(shared variable)に入れることとした.
def setup_data(xmat, ymat):
# store the data into 'shared' variables to be accessible by Theano
def shared_dataset(xm, ym, borrow=True):
shared_x = theano.shared(np.asarray(xm, dtype=theano.config.floatX),
borrow=borrow)
shared_y = theano.shared(np.asarray(ym, dtype=theano.config.floatX),
borrow=borrow)
#
return shared_x, shared_y
def data_shuffle(xm, ym, siz):
idv = np.arange(siz)
idv0 = np.array(idv) # copy numbers
np.random.shuffle(idv)
xm[idv0] = xm[idv]
ym[idv0] = ym[idv]
return xm, ym
total_len = ymat.shape[0]
n_features = np.size(xmat) / total_len
# Random Shuffle
xmat, ymat = data_shuffle(xmat, ymat, total_len)
train_len = int(total_len * 0.7)
test_len = total_len - train_len
xtr, ytr = shared_dataset((xmat[:train_len]).reshape(train_len, n_features),
ymat[:train_len])
xte, yte = shared_dataset((xmat[train_len:]).reshape(test_len, n_features),
ymat[train_len:])
rval = [(xtr, ytr), (xte, yte)]
return rval
データセットの格納先が共有変数に移ったことで,theano.functionの記述が変更される.引数をinputs で直接与えるのではなく,givens のキーワードで間接的に与えなければならない.
データを(共有変数でない)Theano変数で入力(再録)
# Compile
train = theano.function(
inputs=[x,y],
outputs=[cost, prediction],
updates=((w, w - 0.1 * gw), (b, b - 0.1 * gb)),
allow_input_downcast=True)
predict = theano.function(inputs=[x], outputs=prediction,
allow_input_downcast=True)
データを共有変数から入力(SGD version)
# Compile
batch_size = 10
train_model = theano.function(
inputs=[index, learning_rate],
outputs=[cost, prediction],
updates=((w, w - learning_rate * gw), (b, b - learning_rate * gb)),
givens=[(x, xtr[index * batch_size:(index + 1) * batch_size]),
(y, ytr[index * batch_size:(index + 1) * batch_size])],
allow_input_downcast=True
)
predict = theano.function(
inputs=[],
outputs=prediction,
givens=[(x, xte)],
allow_input_downcast=True
)
上記定義したTheano関数を使って,反復計算を行う.
# Train (Optimization)
start_time = timeit.default_timer()
n_epochs = 20
epoch = 0
lrate_base = 0.03
lrate_coef = 20
n_train_batches = int(ytr.get_value().shape[0] / batch_size)
while (epoch < n_epochs):
epoch += 1
for mini_batch_index in range(n_train_batches):
l_rate = lrate_base * lrate_coef / (epoch + lrate_coef)
cost_j, pred = train_model(mini_batch_index, l_rate)
print 'epoch[%3d] : cost =%f ' % (epoch, cost_j)
実行結果.
Initial model:
w : [ 0.0000], b : [ 0.0000]
epoch[ 1] : cost =0.503755
epoch[ 2] : cost =0.510341
epoch[ 3] : cost =0.518218
epoch[ 4] : cost =0.524344
epoch[ 5] : cost =0.528745
epoch[ 6] : cost =0.531842
epoch[ 7] : cost =0.534014
epoch[ 8] : cost =0.535539
epoch[ 9] : cost =0.536614
epoch[ 10] : cost =0.537375
epoch[ 11] : cost =0.537913
epoch[ 12] : cost =0.538294
epoch[ 13] : cost =0.538563
epoch[ 14] : cost =0.538751
epoch[ 15] : cost =0.538880
epoch[ 16] : cost =0.538966
epoch[ 17] : cost =0.539021
epoch[ 18] : cost =0.539053
epoch[ 19] : cost =0.539067
epoch[ 20] : cost =0.539069
Final model:
w : [ 0.3680], b : [ -4.9370]
Elapsed time: 26.565 [s]
accuracy = 0.7868
計算におけるパラメータの変化をプロットしてみた.
Fig. Epochごとのplot
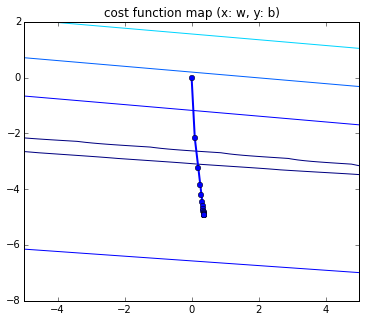
Fig. Mini-Batchごとのplot
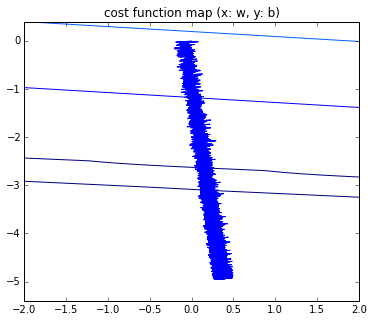
分解能を上げると,確率的勾配降下法(SGD)の特徴である動きが観測できる.
ロジスティック回帰の独立変数(feature)を増やす
せっかくデータセット"Adult"が多くの独立変数(feature)を持っているので,featureを増やして計算を行うことにした.Codeとしては,訓練用データ x の入力処理を変えるだけである.使った Featureは,以下の通り.
- 教育年数(学歴,日本で高校まで教育受けたとすると12年になる.)(最初の回帰モデルでも使用)
- 世帯における役割(夫,妻,子持ち,独身,等)(この回帰モデルで追加.)
- 1週間あたりの労働時間 (この回帰モデルで追加.)
多少,分類の精度(accuracy)が上がるかと期待したが,残念ながら最初の回帰モデルから精度は良くならなかった.(今回は,プログラムの実装が目的なので,データ分析結果について考察はしていない.)
計算時間に関するベンチマークの結果は,次の通りになった.
計算時間の比較
| Optimize method | Model feature number | CPU / GPU | epoch number | mini-batch size | time [s] |
|---|---|---|---|---|---|
| Batch Gradient Descent | 1 | CPU | 10,000 | - | 76.75 |
| Batch Gradient Descent | 1 | GPU | 10,000 | - | 91.14 |
| Stochastic Gradient Descent | 1 | CPU | 20 | 10 | 1.76 |
| Stochastic Gradient Descent | 1 | GPU | 20 | 10 | 23.87 |
| Stochastic Gradient Descent | 3 | CPU | 20 | 10 | 4.51 |
| Stochastic Gradient Descent | 3 | GPU | 20 | 10 | 88.38 |
! どの計算でも収束判定は行っていない.所定のループ回数の計算を実施.
! Batch Gradient Descentでは,収束解を得るために10,000回程度の計算が必要であった.(学習率 learning rate=0.1)
GPU計算のところを見なければ,Batch G.D. vs. SGDで大幅な計算時間の短縮である.SGDの高い計算効率を確認できた.
GPU計算におけるMini-Batch sizeの影響
さて問題は「GPUの計算効率の悪さ」である.計算時間は,学習(train)の前にタイマーセット,完了後にタイマー値を取得で行っているので,この学習部分に原因があることは間違いない.通常,疑われるのが,GPU計算部分にCPU計算(特にnumpyの処理)が混在することである.このことを念頭に,コードを詳細に見てまわったが,原因となる箇所を見つけられなかった.(実際,お手本となるTheano Tutorial, Deep Learning 0.1 documentationのコードを参照しているので,単純な間違いは入らないと思われる.)
その後,思い当たったのが,Theano Functionをコールする際のオーバーヘッドである.Mini-Batch sizeを変えて(大きくして)計算時間を計測してみた.
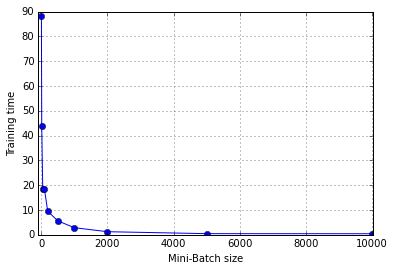
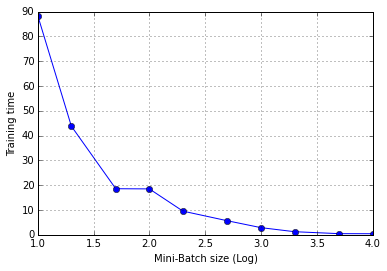
横軸にMini-Batch size,縦軸にTraining timeをとってプロットしている.左がLinear-Linear,右がLog-Linearのスケールである.Mini-Batch sizeに比例してLoop回数が減ることを考慮する必要があるが,上の結果は「指数関数的に」計算時間が減っており,Training function callの影響が大きいと考えられる.
Courseraの講義の中では,「Mini-Batch sizeは,プロセッサの並列計算(vectorization)を意識して決めなさい,2~100ぐらいが実用的です」との説明であった.また,「クラス分類のケースでは,仕分け先のクラス数(今回は2分類なので 2,MNISTの手書き数字分類なら10)に合わせて決めるのが適当,のような提案もあるようだ.しかしながら,今回の結果からは,「GPU計算においてはMini-Batchのサイズをある程度大きく設定した方がよい」ということになる.
今回は,ロジスティック回帰なので,ニューラルネットと比べると1バッチあたりの計算量がかなり少ない.ニューラルネット等,もう少し規模の大きい計算でのMini-Batch sizeの影響は,後日調べたいと思う.またFunction callのオーバーヘッドは,メモリ間のデータ転送に起因するのでHardwareにより状況が異なると考えられる.(やはりLaptop PCでは無理があるのしょうか?)
(本記事のプログラミング環境は,次の通りです,python 2.7.8, theano 0.7.0, CUDA Driver /Runtime 7.5 / 7.0 )
参考文献 (web site)
- Cousera, Machine Learning (特にWeek 10)
- Theano Tutorial http://deeplearning.net/software/theano/tutorial/
- Theano, Deep Learning Tutorials http://deeplearning.net/tutorial/
- UCI Machine Learning Repository, Adult http://archive.ics.uci.edu/ml/datasets/Adult
- [Qiita] 今一度Theanoの基本を学ぶ http://qiita.com/TomokIshii/items/1f483e9d4bfeb05ae231 (今回のことでTheanoについてあれこれ調べたので,このリンク先記事も更新したいと思います.)
(追記) Theano GPU計算でMini-Batchサイズに着目してベンチマーク
上の記事にて,「確率的勾配降下法をMini-Batchで行う場合,Mini-Batch sizeの影響を受けるようだ」と書いたが,これについてコメントをいただいたので,条件を増やしてベンチマークテストをしてみた.
ベンチマークで用いた問題 - Adult Dataset
本記事と同様,UCI Machine Learningリポジトリから"Adult"を選び使用した."Adult" データは,米国住民の「家族構成」「学歴」等から年収 US$50k以下,US$50kを越える,を分類する問題である.今回は分類コードを2つ用いた.
ロジスティック回帰による分類. "Adult"データセットに含まれる14特徴量の内,3つを選択して回帰モデルを作成.また,ファイル 'adult.data' のデータを 70% / 30% に分割してそれぞれTrainデータ,Testデータに用いる.(前回,データセットに含まれるテスト用のファイル 'adult.test' の存在に気が付かず,上記のような操作をしていました.)
Multi-layer Perceptron(MLP)モデルによる分類."Adult"データセットに含まれる14特徴量の内,11を選択し,MLPネットモデルに入力する.MLPの構成は,隠れ層1(ユニット数22) + 隠れ層2(ユニット数20)+ 出力層(ユニット数1)とした.ファイル'adult.data'をTrainデータ,'adult.test'をTestデータに用いた.インスタンス数は Train-32561, Test-16281.
またオプティマイザは,Mini-Batchでデータを供給しながらパラメータを調整する確率的勾配降下法(Stochastic Gradient Descent)を用いた.
計算のプロセス
訓練データを1セットとし,これを所定のMini-Batchサイズに分割後,分類器に入力している.1セット全部を入力する計算ステップをepochと呼び,収束判定を行わず,決められたepoch数(今回はepoch=50)の計算を実施した.以下,その部分のコードである.
#############################################
batch_size = 100
#############################################
# Compile
train_model = theano.function(
inputs=[index],
outputs=[cost, accur],
updates=one_update,
givens=[(x, trXs[index * batch_size:(index + 1) * batch_size]),
(y_, trYs[index * batch_size:(index + 1) * batch_size])],
allow_input_downcast=True
)
accuracy = theano.function(
inputs=[],
outputs=accur,
givens=[(x, teXs), (y_, teYs)],
allow_input_downcast=True
)
# Train (Optimization)
start_time = timeit.default_timer()
n_epochs = 50
epoch = 0
n_train_batches = int(trY.shape[0] / batch_size)
while (epoch < n_epochs):
epoch += 1
for mini_batch_index in range(n_train_batches):
cost_j, accur = train_model(mini_batch_index)
print('epoch[%3d] : cost =%8.4f' % (epoch, cost_j))
elapsed_time = timeit.default_timer() - start_time
print('Elapsed time: %10.3f [s]' % elapsed_time)
last_accur = accuracy()
print('Accuracy = %10.3f ' % last_accur)
一つ注意点としては,1 epoch におけるMini-Batchの回数を
# Mini-Batch回数 = Trainデータのインスタンス数 / Mini-Batchサイズ
n_train_batches = int(trY.shape[0] / batch_size)
としていて,余剰を切り捨てていることがある.これはMini-Batchサイズが大きくなると相対的に影響が大きくなり,例えば,インスタンス数 32,561 Mini-Batchサイズ 10000 のケースでは,30,000 のインスタンスは参照するが,2561 を読み飛ばす状況となる.
ベンチマークテスト結果
計算機環境は,以下の通り.
1. Laptop PC (GPU付),OS:Windows 10, Python 2.7.11, Theano 0.7.0
2. Desktop PC (GPU付),OS:Linux,Ubuntu 14.04LTS,Python 2.7.11, Theano 0.7.0
テスト結果 (raw data)
(単位は,秒 [s] )
| batch_siz | Laptop_LR_fastc | Laptop_MLP_fastc | Laptop_LR_fastr | Laptop_MLP_fastr | Desktop_LR_fastr | Desktop_MLP_fastr |
|---|---|---|---|---|---|---|
| 10 | 113.3 | 1546.6 | 108.8 | 362.7 | 15.3 | 57.4 |
| 20 | 56.9 | 758.6 | 55.5 | 176.1 | 8.0 | 28.5 |
| 50 | 22.6 | 321.6 | 22.2 | 91.4 | 3.2 | 16.6 |
| 100 | 11.6 | 159.8 | 11.5 | 47.0 | 3.1 | 8.6 |
| 200 | 6.2 | 77.0 | 5.9 | 23.8 | 1.6 | 4.5 |
| 500 | 4.4 | 30.6 | 4.3 | 7.9 | 1.0 | 1.8 |
| 1000 | 2.2 | 15.4 | 2.3 | 4.6 | 0.5 | 1.2 |
| 2000 | 1.2 | 9.3 | 1.3 | 3.5 | 0.3 | 0.9 |
| 5000 | 0.4 | 4.6 | 0.5 | 1.9 | 0.2 | 0.6 |
| 10000 | 0.3 | 4.0 | 0.4 | 1.6 | 0.1 | 0.5 |
各カラムの説明:
- batch_siz :Mini-Batchサイズ
- Laptop_LR_fastc : Laptop PCでのロジスティック回帰,theano.config.Mode=fast_compile
- Laptop_MLP_fastc : Laptop PCでのMLPモデル分類,theano.config.Mode=fast_compile
- Laptop_LR_fastr : Laptop PCでのロジスティック回帰,theano.config.Mode=fast_run
- Laptop_MLP_fastr : Desktop PCでのMLPモデル分類,theano.config.Mode=fast_run
- Desktop_LR_fastr : Desktop PCでのロジスティック回帰,theano.config.Mode=fast_run
- Desktop_MLP_fastr : Desktop PCでのMLPモデル分類,theano.config.Mode=fast_run
'theano.config.Mode' は,'fast_run' で最適化レベルが上がり実行速度がup,'fast_compile' は最適化は一部実施(コンパイル時間短縮)のオプション.
次にプロットを参照しながら詳細を見ていく.
Fig. Logistic Regression vs. MLP model
(Laptop_LR_fastr vs. Laptop_MLP_fastr)
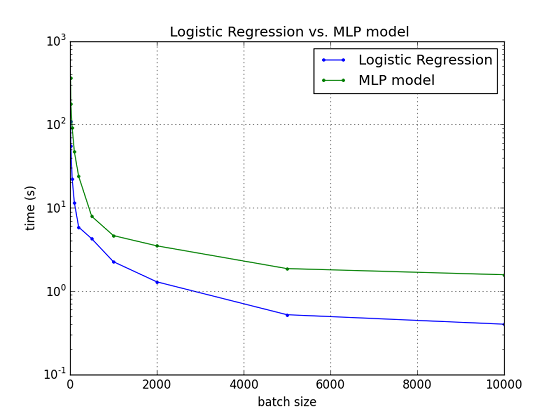
横軸にMini-Batchサイズ,縦軸に学習部分の所要時間.まず,分類コードの違い,ロジスティック回帰とMLPモデルによる分類の比較であるが,目論見通り,MLPモデルで計算量が増えた影響で計算時間も3~4倍程度,長くなっている.また,Mini-Batchサイズの影響は,両者で傾向は同じで,Mini-Batchサイズが増えるにつれ,計算時間が低減していることが分かる.
Fig. Theano mode FAST_COMPILE vs. FAST_RUN (Logistic Regression)
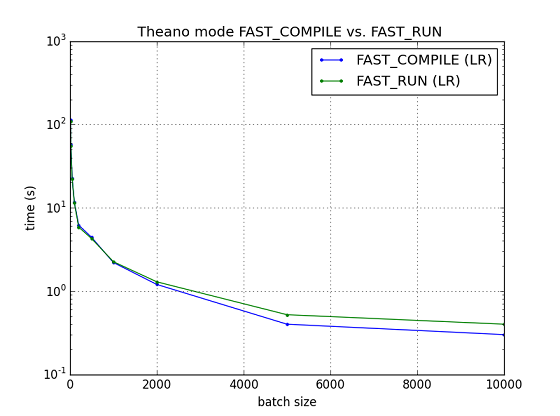
CUDA関係の最適化をあまり行わないモードFAST_COMPILEと最適化をよりしっかり行うモードFAST_RUNの比較であるが,上図の通り,ロジスティック回帰同士の比較ではそれほど差が出ていない.
Fig. Theano mode FAST_COMPILE vs. FAST_RUN (MLP classification)
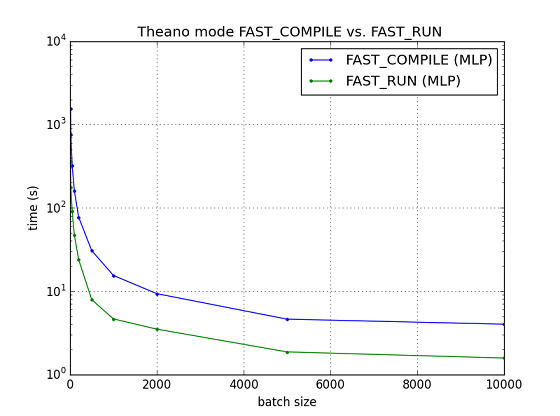
一方で,計算量の多いMLPモデルの分類では最適化を進めたFAST_RUNではその効果が出てきて計算時間の低減につながっている.
FIG. Laptop PC vs. Desktop PC (MLP classification)
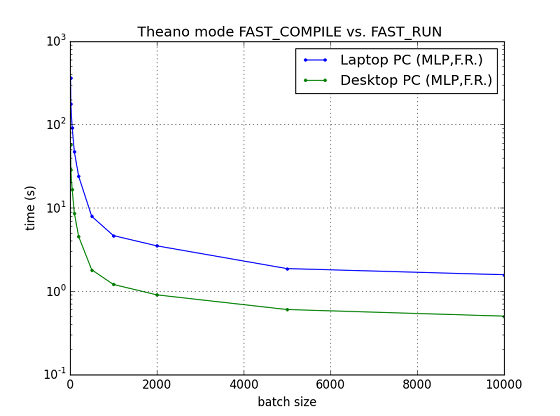
これは,単純にハードウェアの性能の差が出た結果と考えられる.(両者ともTheano modeはFAST_RUNです.またOSの差は詳しく見ていませんが影響は小さいでしょう.)
考察
上記の通り,どの条件下でもMini-Batchサイズを大きくするにつれ,学習の計算時間が大幅に減っていく傾向が観測されている.原因は,Mini-Batchサイズが小さく刻まれると学習のwhileループにおける関数train_model()の呼び出し回数が増え,この関数callにおけるオーバーヘッドの影響が大きく出ていると考えられる.(より詳しく調査する場合,プロファイラを用いる必要があるかと思います.一応,標準プロファイラのCprofileで状況をみたのですが,Theanoコード内に入った部分で時間を食っているところまでは把握できたのですが,その先は技量不足もあり,詳細についてはあきらめました.)
今回のテストでは,(前述の通り,データフィード時に発生するデータ「切り捨て」の問題はありますが),概略,フィードするデータ量は同じ条件としている.本来,学習時においては,いかに早く分類器の精度を高めていくかがポイントであるので,Mini-Batchごとに計算パラメータ(学習率や,オプティマイザのパラメータ等)を調整する作戦がとられることが多い.この件と今回,観測されたGPU計算の関数call時に発生するオーバーヘッドをそれぞれ考慮して,Mini-Batchのサイズを適切に設定することが効率的な学習を実現する上で大切と考えられる.