Qiita初投稿
- 投稿テストも兼ねて統計学の基礎中の基礎であるt値とp値についてまとめてみました。
- 自分は統計初心者で、まだまだ理解が及んでないとこも多々あります!もし認識違いあればコメント頂けると幸いです。
- 途中、説明を飛ばしてて雑な部分が多々ありますが、ご容赦ください。
- Pythonコードに関しても多少冗長なとこあるかもですがお許しください。
t分布について
t値、p値の意味について考える前にまず前提知識としてt分布について考えてみます。t分布は統計学の様々な場面で導入されるのですが、ここでは以下の例を取り上げて考えていきたいと思います(統計検定2級とかで出てきそう)
t分布は正規分布する母集団の母平均と母分散が未知である時、母平均を推定する問題に利用される。(あくまでも母集団の分布は正規分布である事が条件です。)
また、母平均の推定は勿論ですが、その検定にもt分布(t値)は使われます。
因みに、母分散未知の場合、母平均の推定を行う場合は、代わりにサンプルの不偏分散を使って推定を行います。
t分布の例
ある正規母集団からサンプルサイズ $n$ を抽出した時の確率変数 $X$ の平均 $\overline{X}$ は自由度 $n-1$ のt分布に従う。
と書いても良く分からないと思うので、実際にt分布をプロットしてみようと思います。因みにt分布はその自由度によって、分布の様子が変わってきます。Pythonで確認してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
%matplotlib inline
# -6 から 6 の区間で100列の一次元配列を作成
x = np.linspace(-6, 6, 100)
# サブプロットを用意
fig, ax = plt.subplots(1, 1)
# 自由度(1, 3, 30)の3つのt分布をプロット
deg_of_freedom = [1, 3, 30]
for k in deg_of_freedom:
ax.plot(x, stats.t.pdf(x, k), label=r'$k=%i$' % k)
plt.xlim(-6, 6)
plt.ylim(0, 0.4)
plt.legend()
plt.show()
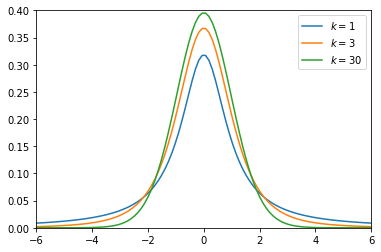
上記を見てわかる通り、自由度が大きくなるに連れて、分布がシャープになっています。
これはつまり、サンプルサイズ $n$ が大きいほど、サンプル平均の分布は元の母集団の平均値に寄ったシャープな分布をすると言えることが分かります。つまり、データ数が大きいほどより平均値の予測にブレが出なくなってくるとも言え、なんとなく直感的に分かりやすい結果になるかと思います。(統計検定では自由度が30以上のt分布は近似的に標準正規分布とみなす。って感じで解く問題が多いです。)
ここで、自由度1のt分布と正規分布を重ねてみます。
# サブプロット(箱)を用意
fig, ax = plt.subplots(1, 1)
# 自由度1のt分布をプロット
ax.plot(x, stats.t.pdf(x, 1), label='$k=1$')
# 平均0 標準偏差1の正規分布(標準正規分布)をプロット
ax.plot(x, stats.norm.pdf(x, loc=0, scale=1), label='STD')
plt.xlim(-6, 6)
plt.ylim(0, 0.4)
plt.legend()
plt.show()
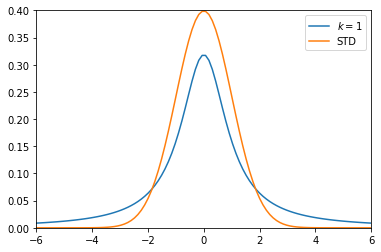
上記の結果から、t分布は標準正規分布よりも、分布が広がっていることが分かります。
感覚的に考えても、母分散が既知の場合に、母平均推定に使われる標準正規分布より、母分散未知の場合に、母平均推定に使われるt分布の方が、その予測精度が落ちてしますのは合点がいくかと思います。
t値について
ここで再び先ほどの例ですが
ある正規母集団からサンプルサイズ $n$ を抽出した時の確率変数 $X$ の平均 $\overline{X}$ は自由度 $n-1$ のt分布に従う。
と言った場合、その時の不偏分散を $s^2$ とすると、その分布のt値は以下の式で与えられます。
$$t = \frac{\overline{X} - \mu}{\frac{s}{\sqrt{n}}} ・・・①$$
上の式をみてわかる通り、tの信頼区間を設定して、更に$\mu$ についてまとめると以下の良く見る式になって、母平均の区間推定ができます。
$$ \overline{X} - t\frac{s}{\sqrt{n}} \leq \mu \leq \overline{X} + t\frac{s}{\sqrt{n}} ・・・②$$
こんな簡単な計算で母平均を推測出来てしまうなんて、統計学おそるべしです。。。
この時の $t$ の値は自由度や、信頼区間に寄って大きく異なるため、求める精度との相談で決めていくことになります。
p値について
上の推定では $\mu$ の値を予測することが目的でしたが、今度は逆に $\mu$ の値をある値と仮定して、その仮定が最もらしいか調べてみると言った処理を行います。これがいわゆる検定です。(厳密な表現ではないかも知れませんので悪しからず)
今、式①より、サンプル平均 $\overline{X}$、母平均 $\mu$(仮定した値)、サンプル数 $n$、不偏分散 $s^2$、自由度 $n-1$が定まっているので、後は信頼区間さえ決めてあげれば、自ずとt値は定まります。
ここで、先ほどPythonで記述した自由度3のt分布をみた時に、以下の緑色部分が5%部分(滅多に起こらない)になります。
# サブプロット(箱)を用意
fig, ax = plt.subplots(1, 1)
# y=0の関数を作成(後で範囲の塗り潰しに使う)
y = 0
# 自由度1のt分布の両側95%点
t = stats.t.ppf(1-(1-0.95)/2, 3)
# 自由度3のt分布をプロット
ax.plot(x, stats.t.pdf(x, 3), label='$k=3$')
# 範囲の塗り潰し
ax.fill_between(x, stats.t.pdf(x, 3), y, where=x < -t, facecolor='lime', alpha=0.5)
ax.fill_between(x, stats.t.pdf(x, 3), y, where=x > t, facecolor='lime', alpha=0.5)
plt.xlim(-6, 6)
plt.ylim(0, 0.4)
plt.legend()
plt.show()
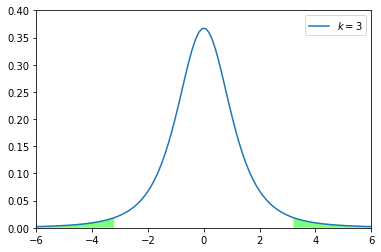
つまり、母平均をある値に仮定した時、取りうるt値は95%の確率で上図の白抜き部分 $-3.18\leq t \leq3.18$ に収まっていることが分かります。逆に出てきたサンプルサイズが予想より大きかったり、小さかったりするとそのt値は緑色の範囲内に入ってしまい、前提の仮定が崩れる(帰無仮説が棄却される)ことになります。
尚、この時に取りうる確率のことをp値と言います。
つまり上の例のように有意水準を5%とした際に、p値が5%以上であれば帰無仮説を棄却せず、逆に5%未満であれば帰無仮説を棄却し、対立仮説を採用することになります。
今回のブログで学んだこと
- t検定のおさらい
- matplotlibで指定したグラフの範囲を塗り潰せるようになった
追記(2021/09/27)
プロ野球データの可視化サイト を作りました。まだまだクオリティは低いですが、今後少しずつバージョンアップさせていく予定です。野球好きの方は是非遊びに来てください⚾️