AMD GPUでCUDAコードが動くやつ(ROCm)がありますがHIPに移植して真面目にC++コードを書く機会は全くなかった(やらなかったが正しい!)のですが最近機運が高まりつつありますので簡単なベクトル和をCUDAで用意してAMD GPUで動かすまでをやってみます
https://buildmedia.readthedocs.org/media/pdf/rocm-documentation/latest/rocm-documentation.pdf
https://github.com/ROCm-Developer-Tools/HIPIFY
統合的なDocument群はこのあたりをご参照ください
2020/10追記
https://qiita.com/syoyo/items/240a1b08cb72f1ea6fbe
どうもROCm HIPの仕様が色々変わってきてるらしいので必要に応じて読み替えないとダメかもしれません
(手元に即使える機材がないので未検証)
必要な環境要件について
ROCm(RadeonOpenCompute)の対応CPUやGPU、OSについて(2019/10/7更新)
私が書いたものですがそれなりにちゃんと書いたつもりなので参照してもらって大丈夫なはずですが・・
バージョンによってコロコロ変わるので公式情報をちゃんと参照する事が大事です.
検証環境
Linux kernel Linux rocm 5.0.0-32-generic
OS ubuntu 18.04.3
CPU Xeon E5-2603 v4
MB MSI x99-A
GPU 0 AMD RadeonⅦ
GPU 1 NVIDIA GeForce GTX1080Ti
ROCm vesion 2.9.6
CUDA V10.1.243
NVIDIA Driver Version: 430.26
NVCC V10.1.243
HIP version: 2.8.19361-cbe6b65
HCC clang version 10.0.0
環境構築について
ROCmの環境構築については各種色々な情報が出てるので省略します
https://github.com/RadeonOpenCompute/ROCm#installing-from-amd-rocm-repositories
公式のインストールガイドでも十分わかりやすいです
説明
CUDA(.cu)を直接compileするのではなくhipifyを使ってCUDA互換言語HIPに移植して動かすというのが正しいです.
HIPは非常にCUDAに酷似した言語でCUDAの機能各種をAMDでも動くように書き換えたというのが正しいぐらいです
ただい問題もありせいぜいCUDA8.0ぐらいまでしかサポートしてないのでCUDA9~10.2をフル活用したようなコードでは厳しいという点も注意が必要です.
CUDAもHIPも勉強中なんですがせっかくならDocumentに残しておけば興味持ってくれたお友達がROCmを切り開いてくれるかなと期待して書きます
https://github.com/ROCm-Developer-Tools/HIP/tree/roc-2.9.0
CUDAをご存知の方なら公式のHIPコードのサンプルを見ればわかると思いますが相当CUDAライクなコードになっています.
hipMalloc(&A_d, Nbytes));
hipMalloc(&C_d, Nbytes));
hipMemcpy(A_d, A_h, Nbytes, hipMemcpyHostToDevice);
const unsigned blocks = 512;
const unsigned threadsPerBlock = 256;
hipLaunchKernel(vector_square, /* compute kernel*/
dim3(blocks), dim3(threadsPerBlock), 0/*dynamic shared*/, 0/*stream*/, /* launch config*/
C_d, A_d, N); /* arguments to the compute kernel */
hipMemcpy(C_h, C_d, Nbytes, hipMemcpyDeviceToHost);
極端な話 cuMemcpyなんかcuをhipに書き換えたぐらいしか違いがありません.
ここまでするならCUDA直接compileできるようにしろおい
ただしカーネル実行部はCUDAの<<< >>>からhipLaunchKernelに変わっておりちょっと多機能になっているようです.
MyKernel<<<dim3(gridDim), dim3(gridDim), 0, 0>>> (a,b,c,n);
// Alternatively, kernel can be launched by
// hipLaunchKernel(MyKernel, dim3(gridDim), dim3(groupDim), 0/*dynamicShared*/, 0/*stream), a, b, c, n);
こっちのほうが関数って感じがしてとっつきやすいですね
まだ本気で仕様を調べてないので違いはまだ良くわかってないですが互換のあるものだと思えば良さそうです.
https://github.com/ROCm-Developer-Tools/HIP/blob/roc-2.9.0/docs/markdown/hip_kernel_language.md
最近HIP-LANGの解説が追加されたので詳細はこちらを御覧ください.
元になったCUDAコード
#include<stdio.h>
#include <cuda_runtime.h>
__global__ void
vectorAdd(float *A,float *B , float *C,int N){
int i = blockDim.x * blockIdx.x + threadIdx.x;//カーネル内で一次元でメモリアクセスをしている
if(i < N){
C[i] = A[i]+B[i];
}
}
int main (void){
int N=5;
size_t size = N * sizeof(float);
//cudaError_t err = cudaSuccess;
srand((int)time(NULL));
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
float *d_A=NULL;
float *d_B=NULL;
float *d_C=NULL;
cudaMalloc((void**)&d_A,size);
cudaMalloc((void**)&d_B,size);
cudaMalloc((void**)&d_C,size);
for(int i = 0 ;i < N;i++){
h_A[i]=1;
h_B[i]=2;
}
cudaMemcpy(d_A,h_A,size,cudaMemcpyHostToDevice);
cudaMemcpy(d_B,h_B,size,cudaMemcpyHostToDevice);
int thread_Per_block = 256;
int block_Per_Grid = (N + thread_Per_block -1)/thread_Per_block;
//printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
vectorAdd <<< block_Per_Grid , thread_Per_block >>> (d_A, d_B, d_C, N);
cudaMemcpy(h_C,d_C,size,cudaMemcpyDeviceToHost);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
for (int i = 0; i < N; ++i)
{
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5)
{
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
printf("%f \n",h_C[i]);
}
free(h_A);
free(h_B);
free(h_C);
return 0;
}
ベクトル長5のベクトルを単純に足し算しているだけです
nvcc ./test.cu -o cuda.o
./cuda.o
3.000000
3.000000
3.000000
3.000000
3.000000
1+2=3ですねw
AMD GPUでも動くhipコードに変換する
hipify-perl test.cu > hip.cpp
これでHIPに簡易的に変換できます。
ただしこれはあくまでも簡易的なPerlscriptであり真面目に変換する場合は
https://qiita.com/syoyo/items/03348e5c55a93e69714e
Ubuntu 18.04 + apt clang 8.0.1 で hipify-clang をビルドする
などをする必要があります.
hipifyの使い方は私もまだ研究中なので今後わかってきたら再度まとめたいとおもっています.
#include "hip/hip_runtime.h"
#include<stdio.h>
#include <hip/hip_runtime.h>
__global__ void
vectorAdd(float *A,float *B , float *C,int N){
int i = blockDim.x * blockIdx.x + threadIdx.x;
if(i < N){
C[i] = A[i]+B[i];
}
}
int main (void){
int N=5;
size_t size = N * sizeof(float);
//hipError_t err = hipSuccess;
srand((int)time(NULL));
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
float *d_A=NULL;
float *d_B=NULL;
float *d_C=NULL;
hipMalloc((void**)&d_A,size);
hipMalloc((void**)&d_B,size);
hipMalloc((void**)&d_C,size);
for(int i = 0 ;i < N;i++){
h_A[i]=1;
h_B[i]=2;
}
hipMemcpy(d_A,h_A,size,hipMemcpyHostToDevice);
hipMemcpy(d_B,h_B,size,hipMemcpyHostToDevice);
int thread_Per_block = 256;
int block_Per_Grid = (N + thread_Per_block -1)/thread_Per_block;
//printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
hipLaunchKernelGGL(vectorAdd, dim3(block_Per_Grid ), dim3(thread_Per_block ), 0, 0, d_A, d_B, d_C, N);
hipMemcpy(h_C,d_C,size,hipMemcpyDeviceToHost);
hipFree(d_A);
hipFree(d_B);
hipFree(d_C);
for (int i = 0; i < N; ++i)
{
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5)
{
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
printf("%f \n",h_C[i]);
}
free(h_A);
free(h_B);
free(h_C);
return 0;
}
以上のようなコードが出力されます.
しかしこのコードには問題点があり
一行目の#include "hip/hip_runtime.h"はだめなので
#include <hip/hip_runtime.h>のみにする必要があります.
hipcc でこれをひとまずcompileしてみます.
hipify-perl test.cu > hip.cpp
hipcc ./hip.cpp -o hip.o
time ./hip.o
3.000000
3.000000
3.000000
3.000000
3.000000
real 0m0.936s
user 0m0.236s
sys 0m0.656s
一応compile&Runできることが確認できました.
謎に時間がかかっているようなのでおっかけてみたいと思います
試しにrocprofで実行を追ってみたいと思います
https://github.com/ROCm-Developer-Tools/rocprofiler
nvprofのAMD版みたいな子です
https://qiita.com/Hiroki11x/items/3737e4e267c1035a4b55#nvprof%E3%81%A7profile%E3%82%92%E3%81%A8%E3%82%8B
export ROCPROFILER_TRACE=1
rocprof --hsa-trace -d ./ ./hip.o #毎回出力される.jsonの中身は上書きされるので毎回読み込むこと
rocprof --hip-trace -d ./ ./hip.o
rocprof --hsa-trace -o hsa -d ./ ./hip.o
これをするとresults.hip_stats.csv results.json results.hsa_hip_stats.csv results.hsa_stats.csvが出力されます.
chrome://tracing でresults.jsonは読めます
.csvでも見ることが出来ますので必要に合わせたステータスを読むこむと良さそう
肝心の解析ですが
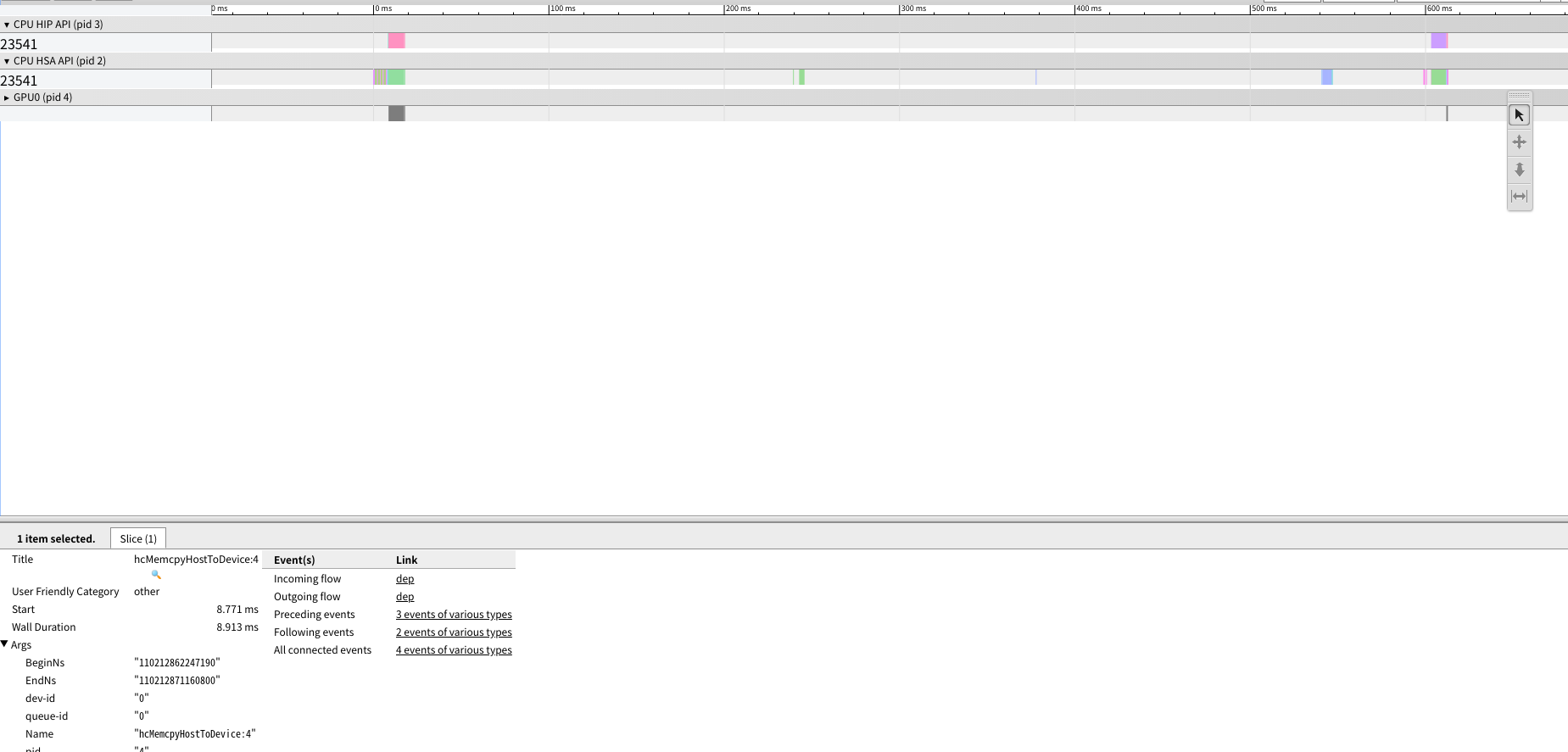
hipmemcpyからカーネル実行までのタイムラグがでかいと言うことがわかりました
ただし一般的に初回に実行されるカーネルは実行ラグが大きいのはCUDAも同じなのでちゃんと計測するときはウォームアップカーネルを走らせる必要があります.
for文でカーネルを10回実行したときの実行結果ですが別に実行時間が10倍になるわけではないです.
$ time ./hip.o
3.000000
3.000000
3.000000
3.000000
3.000000
real 0m0.919s
user 0m0.245s
sys 0m0.634s
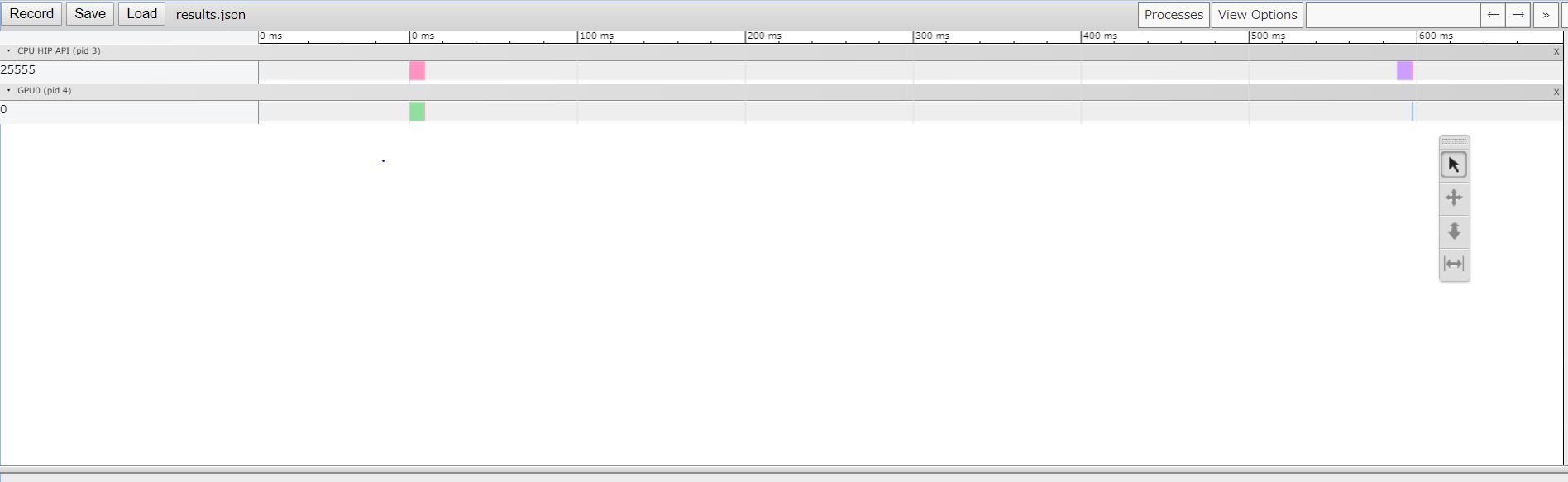
カーネル実行回数を増やしても特に変わったことはない.
まとめ
私なりに調べながら動かしてる段階なので正しいアプローチであるとは言い切れません
またまだシンプルなコードでしか検証してなくてLLVMバックエンドで動くhipily-llvmを使ってしっかりやっているわけではないので正当なアプローチではなく簡易的なアプローチであるのは間違いないです.
あくまでも動くよ!ってデモ的なやつだと思ってくれると嬉しいです.
世間には優秀なGPUプログラマがいっぱい居ると聞いてるので皆さんがAMDなGPUでもコードを動かしてみようかなと思うきっかけになれば幸いです.
参考
CQ出版社トランジスタ技術9月号 p98 GPUADD main.cu