合成音声Wavegrowの動作確認を行いましたのでその環境構築と結果についてのメモ。
環境構築
minicondaでpython3.6環境が構築済みと仮定します
https://qiita.com/T_keigo_wwk/items/1817b6488526778aa8f2
minicondaによるpython開発環境をubuntuで速攻立ち上げする
※condaとpipの混声環境はあまりよくないが現状問題はないのでpipで入れてます
pip install Librosa
pip install tqdm
pip install tensorflow-rocm==1.14.1
今回はtensorflow-rocm==1.14.1を使います、それ以外では動きませんでした。
git clone https://github.com/b04901014/waveglow-tensorflow.git
https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
からデーターセットをダウンロードしてwaveglow内に解答
./src/hpara.pyを以下のように書き換える
import argparse
import librosa
import numpy as np
parser = argparse.ArgumentParser(description='Tensorflow Implementation of WaveGlow')
##Training Parameters##
#Sizes
parser.add_argument('--batch_size', dest='batch_size', type=int, default=4, help='Batch Size')
parser.add_argument('--mel_time_step', dest='mel_time_step', type=int, default=64, help='Time Step of Inputs')
#Optimizer
parser.add_argument('--lr', dest='lr', type=float, default=1e-4, help='Initial Learning Rate')
parser.add_argument('--lr_decay_rate', dest='lr_decay_rate', type=float, default=0.5, help='Decay rate of exponential learning rate decay')
parser.add_argument('--lr_decay_steps', dest='lr_decay_steps', type=int, default=300000, help='Decay steps of exponential learning rate decay')
#Epoch Settings
parser.add_argument('--epoch', dest='epoch', type=int, default=500, help='Number of Epochs')
parser.add_argument('--display_step', dest='display_step', type=int, default=100, help='Batch to Output Training Details')
parser.add_argument('--saving_epoch', dest='saving_epoch', type=int, default=2, help='Epoch to Save Model')
parser.add_argument('--sample_epoch', dest='sample_epoch', type=int, default=1, help='Epoch to Sample')
parser.add_argument('--sample_num', dest='sample_num', type=int, default=5, help='Number of Audios per Sample')
parser.add_argument('--valsplit', dest='valsplit', type=float, default=0.9, help='Portion for training examples, others for validation')
parser.add_argument('--num_proc', dest='num_proc', type=int, default=None, help='Number of process to spawn for data loader')
#GPU
parser.add_argument('--gpu_fraction', dest='gpu_fraction', type=float, default=0.85, help='Fraction of GPU Memory to use')
#parser.add_argument('--use_fp16', dest='use_fp16', default=False, action='store_false', help='True if use float16 for tensorcore acceleration')
#parser.add_argument('--fp16_scale', dest='fp16_scale', type=float, default=128, help='Scaling factor for fp16 computation')
#Normalization
parser.add_argument('--use_weight_norm', dest='use_weight_norm', default=False, action='store_true', help='Use Weight Normalization or not')
##Inference##
parser.add_argument('--do_infer', dest='is_training', default=True, action='store_false', help='Default to training mode, do inference if --do_infer is specified')
parser.add_argument('--infer_mel_dir', dest='infer_mel_dir', default='/home/rocm5/waveglow-tensorflow/training_mels', help='Path to inference numpy files of mel spectrogram')
parser.add_argument('--infer_path', dest='infer_path', default='/home/rocm5/waveglow-tensorflow/inference', help='Path to output inference wavs')
##Sampling##
parser.add_argument('--truncate_sample', dest='truncate_sample', default=False, action='store_true', help='Truncate the infer input mels to truncate_step due to GPU memory consideration or not')
parser.add_argument('--truncate_step', dest='truncate_step', type=float, default=384, help='Truncate the infer input mels to truncate_step due to GPU memory consideration')
##Input Path##
parser.add_argument('--metadata_dir', dest='metadata_dir', default='/home/rocm5/waveglow-tensorflow/LJSpeech-1.1/metadata.csv', help='Path to metadata.csv')
parser.add_argument('--dataset_dir', dest='dataset_dir', default='/home/rocm5/waveglow-tensorflow/LJSpeech-1.1/wavs', help='Path to audio file for preprocessing dataset')
parser.add_argument('--mel_dir', dest='mel_dir', default='/home/rocm5/waveglow-tensorflow/training_mels', help='Path to input mel spectrogram (Output directory for processing dataset)')
parser.add_argument('--wav_dir', dest='wav_dir', default='/home/rocm5/waveglow-tensorflow/training_wavs', help='Path to input audio file for training (Output directory for processing dataset)')
##Output Path##
parser.add_argument('--saving_path', dest='saving_path', default='../model', help='Path to save model if specified')
parser.add_argument('--loading_path', dest='loading_path', default='../model', help='Path to load model if specified')
parser.add_argument('--sampling_path', dest='sampling_path', default='../samples', help='Path to save samples if specified')
parser.add_argument('--summary_dir', dest='summary_dir', default='../summary', help='Path to save summaries')
##Audio Processing Params##
#STFT
parser.add_argument('--num_freq', dest='num_freq', type=int, default=513, help=docker,ROCm環境はすでに構築済みと仮定します
この前に書いたやつと内容はそれほど変わりません
環境構築'Number of frequency bins for STFT')
parser.add_argument('--hop_length', dest='hop_length', type=int, default=256, help='Hop length for STFT')
parser.add_argument('--window_size', dest='window_size', type=int, default=1024, help='Window size for STFT')
#Mels
parser.add_argument('--n_mel', dest='n_mel', type=int, default=80, help='Channel Size of Inputs')
parser.add_argument('--fmin', dest='fmin', type=int, default=0, help='Minimum Frequency of Mel Banks')
parser.add_argument('--fmax', dest='fmax', type=int, default=7600, help='Maximum Frequency of Mel Banks')
#Silence
parser.add_argument('--trim_hop_length', dest='trim_hop_length', type=int, default=256, help='Hop length for trimming silence')
parser.add_argument('--trim_window_size', dest='trim_window_size', type=int, default=1024, help='Window size for trimming silence')
parser.add_argument('--trim_inner_scilence', dest='trim_inner_scilence', default=False, action='store_true', help='Specify to trim the inner slience')
#Preprocessing
parser.add_argument('--sample_rate', dest='sample_rate', type=int, default=22050, help='Sample Rate of Input Audios')
parser.add_argument('--trim_top_db', dest='trim_top_db', type=float, default=10, help='Top dB for trimming scilence')
parser.add_argument('--clip_to_value', dest='clip_to_value', type=float, default=4.0, help='Max/Min value of mel spectrogram')
parser.add_argument('--ref_db', dest='ref_db', type=float, default=45, help='Value to subtract to normalize mel spectrogram')
parser.add_argument('--scale_db', dest='scale_db', type=float, default=15, help='Value to divide to normalize mel spectrogram')
##Flow Network##
parser.add_argument('--n_flows', dest='n_flows', type=int, default=12, help='Number of flow layers in network')
parser.add_argument('--squeeze_size', dest='squeeze_size', type=int, default=8, help='Number of channels of input wavs')
parser.add_argument('--early_output_size', dest='early_output_size', type=int, default=2, help='Number of channels per early output')
parser.add_argument('--early_output_every', dest='early_output_every', type=int, default=4, help='Number of flows per early output')
parser.add_argument('--sigma', dest='sigma', type=float, default=1.0, help='Stddev for the gaussian prior during training')
parser.add_argument('--infer_sigma', dest='infer_sigma', type=float, default=0.6, help='Stddev for the gaussian prior during inference')
##WaveNet##
parser.add_argument('--wavnet_channels', dest='wavnet_channels', type=int, default=512, help='Number of WaveNet channels')
parser.add_argument('--wavenet_layers', dest='wavenet_layers', type=int, default=8, help='Number of layers of WaveNet')
parser.add_argument('--wavenet_filter_size', dest='wavenet_filter_size', type=int, default=3, help='Filter length of WaveNet')
args = parser.parse_args()
##The model Structure Hyperparams, NOT CHANGEABLE from command line##
##Params dependent of other params##
args.n_fft = (args.num_freq - 1) * 2
args.melbasis = librosa.filters.mel(args.sample_rate, args.n_fft, n_mels=args.n_mel, fmin=args.fmin, fmax=args.fmax)
args.step_per_mel = args.hop_length
args.wav_time_step = args.mel_time_step * args.step_per_mel
if args.n_flows % args.early_output_every == 0:
args.output_remain = args.squeeze_size - (args.n_flows // args.early_output_every - 1) * args.early_output_size
else:
args.output_remain = args.squeeze_size - (args.n_flows // args.early_output_every) * args.early_output_size
assert args.mel_time_step % args.squeeze_size == 0
assert args.step_per_mel % args.squeeze_size == 0
assert args.n_flows % (args.squeeze_size // args.early_output_size) == 0
print ("Time Segments of audio for training: %d" %args.wav_time_step)
python ./src/datasets/procaudio.py
これで学習環境の立ち上げがおおよそ完了します
python ./src/main.py --use_weight_norm --truncate_sample
これで学習が開始されます
hpara.pyで--epochをハードコーディングしてあるので必要に応じて書き換えるか--epoch Nでオプションをつけてやると
学習時間を調整できます。
今回は1epochあたりの学習時間さえわかればいいので無視します。
学習に掛かった時間
おおよそですが1epochあたり
RX570 16GB 途中でエラーで中断
RadeonⅦ (rocm-smiでパワーリミットをレベル1にまでしていた)8時間弱
VegaFE (TDP100w制限あり)7時間半
ぐらいでした
GTX1080Tiでのテスト
pip install tensorflow-gpu=1.12.0
sudo docker run --runtime=nvidia -i -t -v /home/rocm/waveglow-tensorflow:/home/rocm/waveglow-tensorflow --rm tensorflow/tensorflow:1.12.3-gpu-py3 /bin/bash
CUDA9.0+TF1.12の組み合わせでないと動かない点に留意が必要です。
pipで入れられない場合は上記の環境においてGPUコンテナを起動するなどの処置を推奨します。
VRAMサイズが足りないので
hpara.pyの
parser.add_argument('--batch_size', dest='batch_size', type=int, default=4, help='Batch Size')
を
parser.add_argument('--batch_size', dest='batch_size', type=int, default=2, help='Batch Size')
のように変更してバッチサイズを小さくして測定した結果
1epochあたり2時間1分でした
同サイズのバッチサイズで比較した結果RadeonⅦは4時間59分だったので2倍ぐらいかかっていることになります。
※この測定に関してはRadeonⅦ、1080Ti共に定格パワーで測定をおこないました。
まとめ
GPUの性能的にはRadeonⅦと1080Tiは大差ないはずですがMIOpenの最適化の問題などから性能差が出てしまっている。
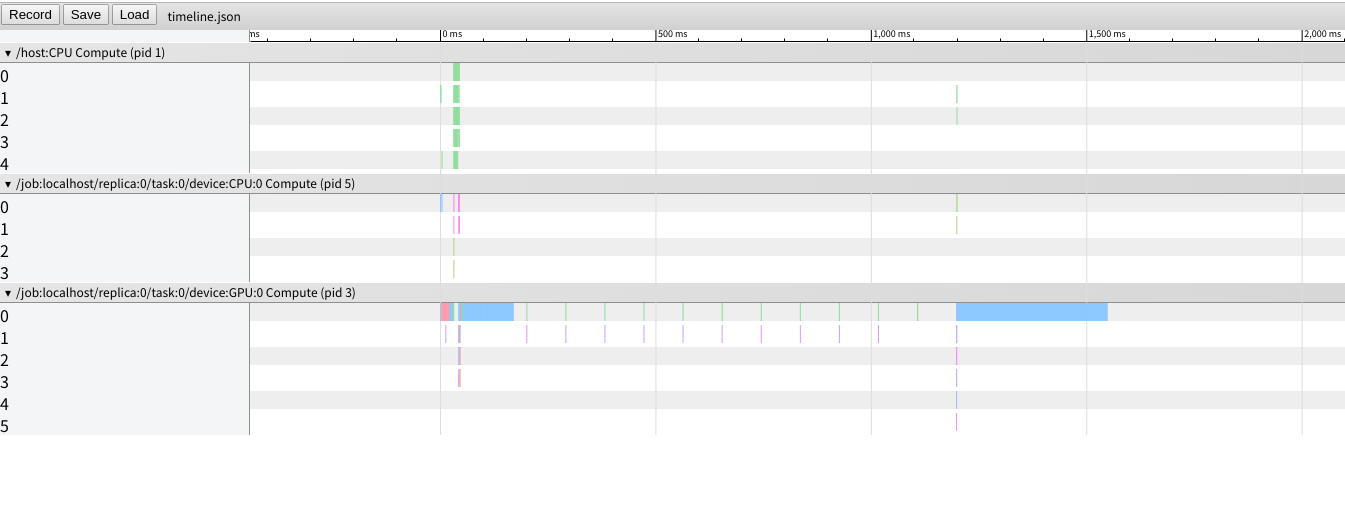
追加 WavegrowがROCmで遅い問題
/src/model.pyをtensorflow timelineで読み込んでくれるように書き直しました
def train(self):
self.data_generator = multiproc_reader(500)
self.validation_data_generator = multiproc_reader_val(args.sample_num * 5)
self.lr = tf.train.exponential_decay(args.lr,
self.global_step,
args.lr_decay_steps,
args.lr_decay_rate)
self.optimizer = tf.train.AdamOptimizer(learning_rate=self.lr)
self.grad = self.optimizer.compute_gradients(self.loss, var_list=self.t_vars)
self.op = self.optimizer.apply_gradients(self.grad, global_step=self.global_step)
varset = list(set(tf.global_variables()) | set(tf.local_variables()))
self.saver = tf.train.Saver(var_list=varset, max_to_keep=3)
num_batch = self.data_generator.n_examples // args.batch_size
do_initialzie = True
if args.loading_path:
if self.load():
start_epoch = self.global_step.eval() // num_batch
do_initialzie = False
else:
print ("Error Loading Model! Training From Initial State...")
if do_initialzie:
init_op = tf.global_variables_initializer()
start_epoch = 0
self.sess.run(init_op)
self.writer = tf.summary.FileWriter(args.summary_dir, None)
with tf.name_scope("summaries"):
self.s_logdet_loss = tf.summary.scalar('logdet_loss', self.logdet_loss)
self.s_logs_loss = tf.summary.scalar('logs_loss', self.logs_loss)
self.s_prior_loss = tf.summary.scalar('prior_loss', self.prior_loss)
self.s_loss = tf.summary.scalar('total_loss', self.loss)
self.merged = tf.summary.merge([self.s_logdet_loss, self.s_logs_loss, self.s_prior_loss, self.s_loss])
self.procs = self.data_generator.start_enqueue()
self.val_procs = self.validation_data_generator.start_enqueue()
self.procs += self.val_procs
self.sample(0)
try:
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
for epoch in range(start_epoch, args.epoch):
clr = self.sess.run(self.lr)
print ("Current learning rate: %.6e" %clr)
loss_names = ["Total Loss",
"LogS Loss",
"LogDet Loss",
"Prior Loss"]
buffers = buff(loss_names)
for batch in tqdm(range(num_batch)):
input_data = self.data_generator.dequeue()
feed_dict = {a: b for a, b in zip(self.placeholders, input_data)}
_, loss, logs_loss, logdet_loss, prior_loss, summary, step = self.sess.run([self.op,
self.loss,
self.logs_loss,
self.logdet_loss,
self.prior_loss,
self.merged,
self.global_step],
feed_dict=feed_dict,
options=run_options,
run_metadata=run_metadata)
self.gate_add_summary(summary, step)
buffers.put([loss, logs_loss, logdet_loss, prior_loss], [0, 1, 2, 3])
if (batch + 1) % args.display_step == 0:
buffers.printout([epoch + 1, batch + 1, num_batch])
if batch == 20:
step_stats = run_metadata.step_stats
tl = timeline.Timeline(step_stats)
ctf = tl.generate_chrome_trace_format(show_memory=False,
show_dataflow=True)
with open("timeline.json", "w") as f:
f.write(ctf)
if (epoch + 1) % args.saving_epoch == 0 and args.saving_path:
try :
self.save(epoch + 1)
except:
print ("Failed saving model, maybe no space left...")
traceback.print_exc()
if (epoch + 1) % args.sample_epoch == 0 and args.sampling_path:
self.sample(epoch + 1)
except KeyboardInterrupt:
print ("KeyboardInterrupt")
except:
traceback.print_exc()
finally:
for x in self.procs:
x.terminate()
出力する.json名を変えたい時は with openの部分を任意の名前にリネームした
chrome://tracing
上記のURLでJSONを確認できます