はじめに
「つくりながら学ぶ!深層強化学習」という参考書を片手にPythonの強化学習用の迷路作ってたら、
いつの間にかBlenderの3D描画を触っていたというお話。
備忘録を兼ねて、自分用に残しておきます。
とりあえず出来上がったのがこちら。
| 強化学習前 | 強化学習後 |
|---|---|
 |
 |
強化学習前後で青い物体が迷路の左上から右下に到達するステップ数が激減しています。
(強化学習前の物体がワープしているように見えますがフレームレートのせいです)
使用環境
・windows10
・Blender2.8
・Python2.7(Blender内蔵)
迷路の作成
今回は5×5の迷路を作成し、左上から右下に移動すればゴールとしています。
まずは床と壁からざっくり作ります。
import bpy
import math
#reset objects
bpy.ops.object.select_all(action='SELECT')
bpy.ops.object.delete(True)
#field add
bpy.ops.mesh.primitive_plane_add(size=7,location=(0,0,0))
for i in range(-3,4):
bpy.ops.mesh.primitive_cube_add(size=1,location=(3,i,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(i,3,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(-3,i,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(i,-3,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(-1,-2,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(-1,-1,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(-1,1,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(0,1,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(1,1,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(1,0,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(1,-1,0.5))
bpy.ops.mesh.primitive_cube_add(size=1,location=(2,-1,0.5))
#lamp add
bpy.ops.object.light_add(type='SUN',location=(0.0,0.0,5.0))
#camera add
bpy.ops.object.camera_add(location=(0,-10,10))
bpy.data.objects['Camera'].rotation_euler = (math.pi*1/4, 0, 0)
プログラム実行以前に生成されていたブロックを削除してから、思い思いの場所にブロックを配置します。
そしてアニメーション撮影用に光源とカメラを置くわけなんですが、bpy.ops.object.light_addが結構曲者でして、Blender2.7以前だと光源設置にはbpy.ops.object.lamp_addが使われています。
(参考にしたサイトが尽くlamp_addだったのでハマりました・・・)
フィールドはもう少しスマートに書けそうな気がしましたが、まずは完成第一ということで後回し。
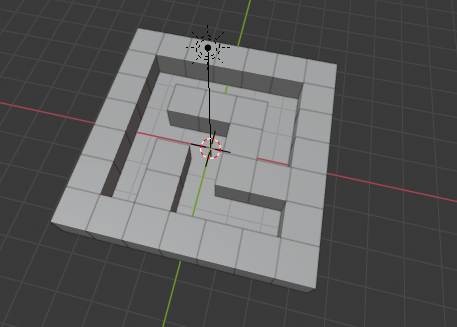
↓出来上がりがこちら。中心から生えているのは光源です。
エージェント(移動物体)と強化学習(方策勾配法)の実装
迷路が出来たら今度はエージェントの作成です。
今回は方策勾配法で学習を行います。
目的を達成(今回だと迷路をゴール)したときの記録を元に選択する行動の確率を補正していくイメージでしょうか。
迷路は5×5でスタート地点がS0、その右がS1、S2と続き、S0の下がS6、その下がS11、ゴール地点がS24となっています。
theta_0にはそれぞれの位置でエージェントが選択可能な行動(↑、→、↓、←方向への進行)を1(進行可能)またはnp.nan(進行不可)で定義しています。
S24はゴール地点なので定義不要です。
theta_0 = np.array([[np.nan, 1, 1, np.nan], #S0
[np.nan, 1, np.nan, 1],
[np.nan, 1, np.nan, 1],
[np.nan, 1, np.nan, 1],
[np.nan, np.nan, 1, 1],
[1, np.nan, 1, np.nan], #S5
[np.nan, np.nan, np.nan, np.nan],
[np.nan, np.nan, np.nan, np.nan],
[np.nan, np.nan, np.nan, np.nan],
[1, np.nan, 1, np.nan],
[1, 1, 1, np.nan], #S10
[np.nan, 1, np.nan, 1],
[np.nan, np.nan, 1, 1],
[np.nan, np.nan, np.nan, np.nan],
[1, np.nan, np.nan, np.nan],
[1, np.nan, 1, np.nan], #S15
[np.nan, np.nan, np.nan, np.nan],
[1, np.nan, 1, np.nan],
[np.nan, np.nan, np.nan, np.nan],
[np.nan, np.nan, np.nan, np.nan],
[1, np.nan, np.nan, np.nan], #S20
[np.nan, np.nan, np.nan, np.nan],
[1, 1, np.nan, np.nan],
[np.nan, 1, np.nan, 1]
])
で、エージェントがどの方向に進行するかなんですが、先ほど定義したtheta_0から進行方向をランダムで決めます。
theta_0が[np.nan, 1, 1, np.nan]だったら右か下に50%の確率で進行します。
def softmax_convert_info_pi_from_theta(theta):
beta = 1.0
[m, n] = theta.shape
pi = np.zeros((m, n))
exp_theta = np.exp(beta * theta)
for i in range(0, m):
pi[i, :] = exp_theta[i, :] / np.nansum(exp_theta[i, :])
pi = np.nan_to_num(pi)
return pi
pi_0 = softmax_convert_info_pi_from_theta(theta_0)
次に現在地と進行方向の情報。
進行方向の選択確率と現在地を引数として渡すと、次に進む方向と位置情報を返します。
def get_action_and_next_s(pi, s):
direction = ["up", "right", "down", "left" ]
next_direction = np.random.choice(direction, p=pi[s, :])
if next_direction == "up":
action = 0
s_next = s -5
elif next_direction == "right":
action = 1
s_next = s + 1
elif next_direction == "down":
action = 2
s_next = s + 5
elif next_direction == "left":
action = 3
s_next = s - 1
return [action, s_next]
エージェントがどういった経路でゴールまで向かったかの履歴を記録します。
ここの履歴は、ゴール時の評価と経路の描画に使用します。
迷路の規模を変更する場合、while文のbreak条件をゴール地点にしてあげないとエラーを吐きます・・・
def goal_maze_ret_s_a(pi):
s = 0
s_a_history = [[0, np.nan]]
while 1:
[action, next_s] = get_action_and_next_s(pi, s)
s_a_history[-1][1] = action
s_a_history.append([next_s, np.nan])
if next_s == 24:
break
else:
s = next_s
return s_a_history
s_a_histories = goal_maze_ret_s_a(pi_0)
以上までがあれば、とりあえずスタートからゴールにまで辿り着けるようにはなります。
以下の関数を設定してあげることでゴールまでの最短距離を模索するようになります。
ステップ数はスタート地点の情報を引くためにlen(s_a_history)から1を引いています。
ゴールまでの経路に係数を掛けて、進行確率を補正するのですが、ステップ数が多いほど補正倍率(delta_thetaの値)が小さくなるので、その結果が重視されないことになります。
def update_theta(theta, pi, s_a_history):
eta = 0.1
t = len(s_a_history) - 1
[m, n] = theta.shape
delta_theta = theta.copy()
for i in range(0, m):
for j in range(0, n):
if not(np.isnan(theta[i, j])):
sa_i = [SA for SA in s_a_history if SA[0] == i]
sa_ij = [SA for SA in s_a_history if SA == [i, j]]
n_i = len(sa_i)
n_ij = len(sa_ij)
delta_theta[i, j] = (n_ij - pi[i, j] * n_i)/t
new_theta = theta + eta * delta_theta
return new_theta
updataをwhile文で繰り返し、進行確率の更新値が10^-3以下になったところで集計を終了しています。
stop_epsilonの値を変更することで精度を変えることが出来ます。
new_theta = update_theta(theta_0, pi_0, s_a_histories)
pi = softmax_convert_info_pi_from_theta(new_theta)
print(pi)
stop_epsilon = 10**-3
theta = theta_0
pi = pi_0
is_continue = True
count = 1
n = 1
while is_continue:
s_a_histories = goal_maze_ret_s_a(pi)
new_theta = update_theta(theta, pi, s_a_histories)
new_pi = softmax_convert_info_pi_from_theta(new_theta)
print(np.sum(np.abs(new_pi-pi)))
print(str(n) + "回目に迷路にかかったステップ数は" + str(len(s_a_histories) - 1) + "です")
n = n + 1
if np.sum(np.abs(new_pi - pi)) < stop_epsilon:
is_continue = False
else:
theta = new_theta
pi = new_pi
np.set_printoptions(precision=3, suppress=True)
print(pi)
と、ざっくり説明もどきをしましたが、こちらに詳しい解説がありますので、
興味のある方は読んでいただければと思います。
3D描画
迷路作ったし、ついでに3Dにしよう!ってことで挑戦してみましたが情報が少なくて結構苦労しました。
エージェントのブロックを生成して、選択状態にして、位置が変わるごとにframe_setして・・・
ちなみにframe_setの記述もBlender2.8で変更されています。ご注意を
この時に生成したブロックが36番目のCubeオブジェクトだったので、bpy.data.objects[]の中身が"Cube.036"になっています。
ここもスマートな選択方法が全く分かりませんでした・・・
いや、そもそも色とかのパラメータ変更するのもめんどくさすぎるんですががががががが
あと、flame_endの数値大きくしすぎると膨大な時間がかかるのでご利用は計画的に。
今回は最短が8ステップということが分かっていたので、frame_endを50に設定しています。
bpy.ops.mesh.primitive_cube_add(size=blocksize,location=(-2,2,0.5))
obj = bpy.data.objects["Cube.036"]
obj.select_set(True)
mat = bpy.data.materials.new('Cube')
mat.diffuse_color = (0, 0, 1, 1)
obj.data.materials.append(mat)
def animation():
'''
動画の撮影を開始
'''
bpy.context.scene.render.resolution_x = 800
bpy.context.scene.render.resolution_y = 600
bpy.context.scene.render.resolution_percentage = 100
bpy.context.scene.camera = bpy.data.objects["Camera"]
bpy.context.scene.render.image_settings.file_format = 'AVI_JPEG'
bpy.data.scenes["Scene"].render.filepath = "C:/tmp/move.avi"
bpy.context.scene.frame_start = 0
bpy.context.scene.frame_end = 50
bpy.ops.render.render(animation=True)
bpy.context.scene.frame_set(0)
obj.keyframe_insert(data_path='location')
bpy.context.scene.frame_set(10)
for i in range(0,len(s_a_histories)):
state = s_a_histories[i][0]
x = (state % 5) - 2
y = 2 - (state // 5)
obj.location = (x, y, 0.5)
obj.keyframe_insert(data_path='location')
bpy.context.scene.frame_set(i * 5 + 10)
animation()
まとめ
参考書読んで、その通り実行していればやりたいことは分かるし、実装も出来ました。
しかし、実際にやりたいことに応用利かせるとなるともっと数を経験するか、理論を身に付ける必要があると感じました。
ただ、理論身に付けているうちに強化学習の勉強するのが嫌になってそうな気がしなくもない・・・
Blenderに関してはバージョンが更新されるにつれて記述の仕方を結構変えていってるようで、参考にしたサンプルだと動かないとか平然と起きていました。
Blender2.8以降のバージョンを使うなら公式の英語と戦いながら学ぶしかなさそうです。