CycleGANは、ペアになっていない画像グループ間でのスタイル変換を可能にしたGANの一種で、「ウマ↔シマウマ」の画像変換などでよく知られています。

CycleGANのポータルページ には、有志による様々な画像グループ間変換の実験結果が掲載されています。「ラーメン↔顔写真」変換とか、なんでやってみようと思ったんでしょうね。そのセンスに脱帽です。
さて、このCycleGANの応用例に、今回は私もひとつ新しいネタを加えてみようと思います。
今回私が題材にするのは、有名なシマリスの兄弟「チップとデール」です。二人は顔立ちがよく似ており、CycleGANの実験対象としてはぴったりです。

CycleGANとは?
CycleGAN(Cycle-Consistent Generative Adversarial Network)は、2017年に発表された、ペアになっていない画像同士の変換(いわゆる「スタイル変換」)を可能にする深層学習モデルです。
(論文)
CycleGANが登場する以前の画像変換モデル(たとえばPix2Pixなど)では、入力画像とその変換後の正解画像が1対1で対応した“ペア画像”が必要でした。
しかし、CycleGANではこの“ペア”がなくても、別々の画像グループの特徴を学習し、それらの間でスタイル変換が可能になります。
CycleGANについて詳しく知りたい方は、こちらの記事がとても分かりやすくおすすめです:
チップとデールについて
チップとデールは、ディズニー作品に登場するシマリスの兄弟です。ぱっと見では違いが分かりにくいですが、「まぶた」、「鼻」、「前歯」に明確な違いがあります。
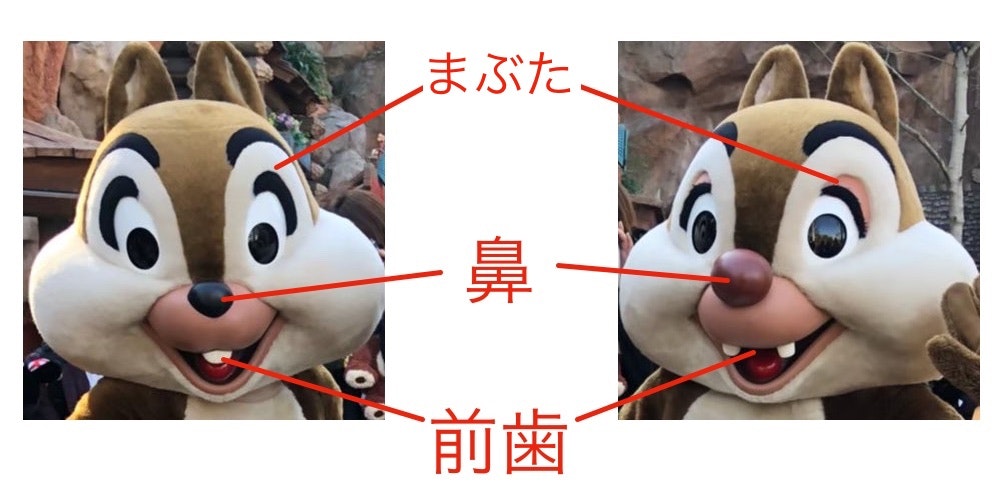
実は数年前に「画像認識でチップとデールを分類できるか」を試した記事を書いていました。
今回はここからさらに課題を発展させ、CycleGANによるチップとデールの相互変換を試してみます。
データセット
| データの種別 | 枚数 |
|---|---|
| 訓練用データ |
|
| 検証用データ |
|
訓練用データは、あらゆる角度や状況で撮影されたチップ / デールそれぞれの画像を200枚ずつインターネットから収集し、顔の部分を正方形にトリミングしておいたものです。私が撮影したものではないのでこの記事には掲載しませんが、モデルの訓練のみに使っています。
検証用データは、私が実際にディズニーパークで撮影したものや、SNS上で親切な方々から提供してもらったチップ / デールの写真。事前に顔の部分を正方形にトリミングしています。
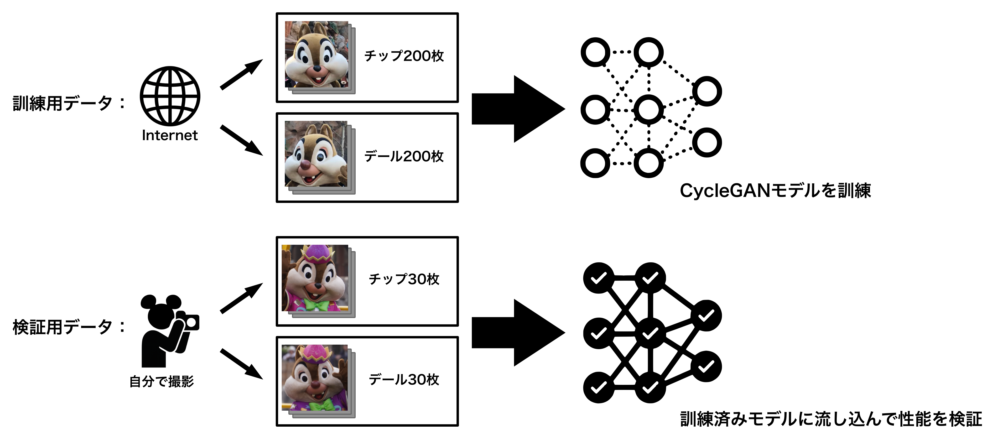
インターネットから収集した画像を検証用データに使うわけにはいきません。なぜなら、後で検証結果として変換画像を掲載することができないからです。その代わり、私がチップとデールに遭遇するたびに撮影した彼らの写真を検証用データとして使います。
ちなみに機械学習あるあるですが、全体的な作業時間のうち、データセット収集&前処理にほとんどの時間を費やしました。
ソースコード
CycleGANの公式はPyTorchによる実装を提供していますが、私は個人的にTenroflowが好きだったので、今回はコミュニティによって開発されたこちらのリポジトリを使用させていただきました。Tensorflow2対応です。
モデルについて
CycleGANでは、2つの画像変換モデル(Generator)と、2つの画像識別モデル(Discriminator)の、計4つのモデルを競わせるように、同時に訓練していくことになります。
具体的に今回のタスクでは、
- Generator1: チップ→デール変換モデル
- Generator2: デール→チップ変換モデル
- Discriminator1: 「本物のチップ」と「Generator1が生成した偽物のチップ」を見分ける識別モデル
- Discriminator2: 「本物のデール」と「Generator2が生成した偽物のデール」を見分ける識別モデル
の4つのモデルをそれぞれ用意します。
具体的なモデルの構成は、本記事の冒頭に貼った論文かリポジトリを参照ください。
パラメータ
CycleGANには複数の調整可能なパラメータがありますが、今回私が採用した具体的なパラメータは以下のとおりです。
| パラメータ | 設定値 |
|---|---|
| 入力画像サイズ | 256 x 256 |
| バッチサイズ | 1 |
| エポック数 | 300 |
| 学習率 | 0.0002 |
| 学習率減衰 | あり。200 エポックから線形減衰開始。 |
| Adamのβ₁ | 0.5 |
| 敵対的損失のモード | LSGAN |
| Cycle一貫性損失のWeight | 10.0 |
| Identity損失のWeight | 0.5 |
| 画像履歴バッファのpoolサイズ | 50 |
基本的にはCycleGANの論文で採用されていた値をそのまま使用しましたが、Identity損失のWeightはデフォルトの0ではなく0.5にしました。理由は後ほど説明します。
学習のようすとLossの推移
200エポックの学習フェーズにおける、CycleGANのLoss(損失)の推移は以下のとおりでした。TensorBoardのスクショそのまま載せてます。
Discriminator Loss(識別損失)
「本物の画像」と「生成された画像」を区別するタスクの損失。
| Lossの種類 | 推移 |
|---|---|
| チップ識別タスクのLoss | 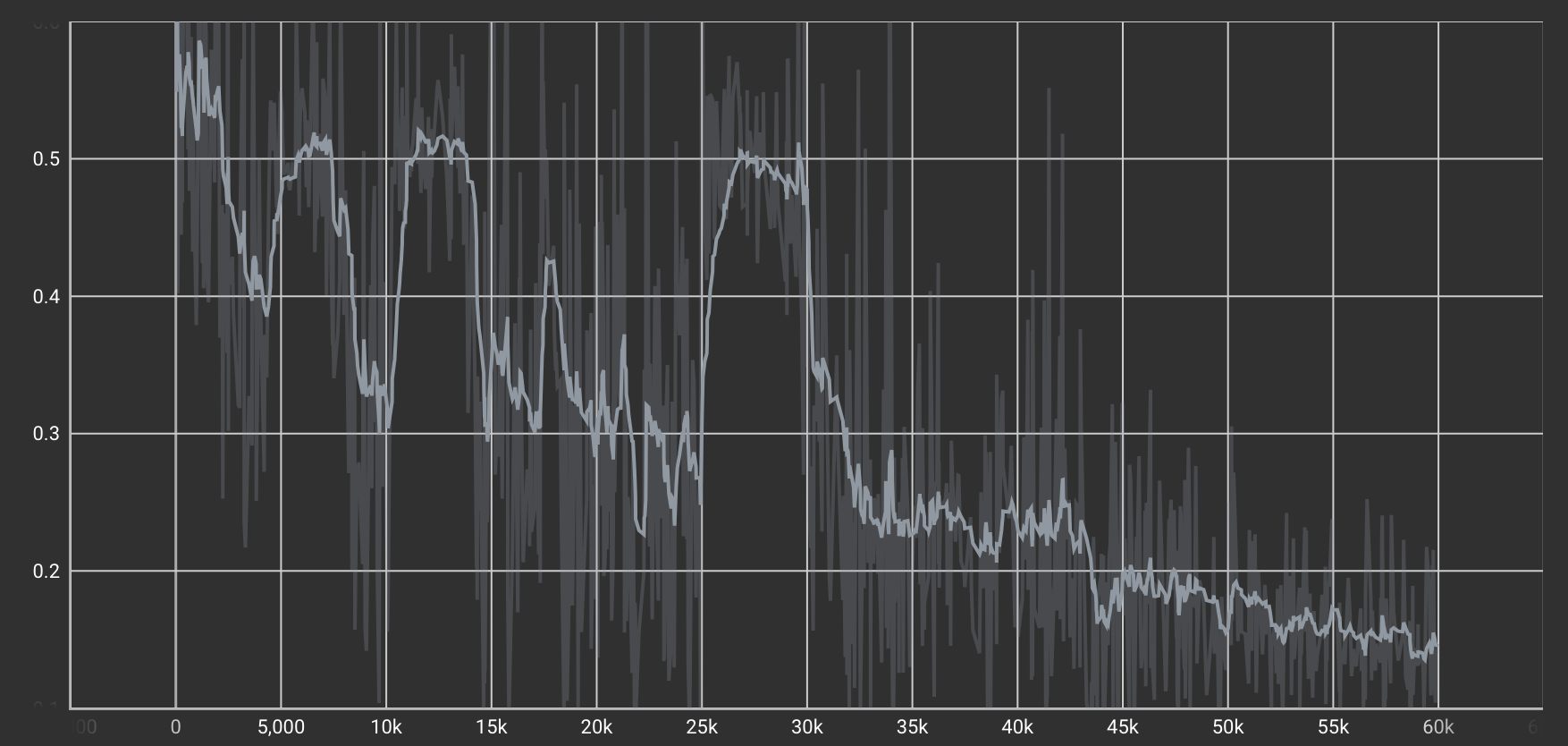 |
| デール識別タスクのLoss | 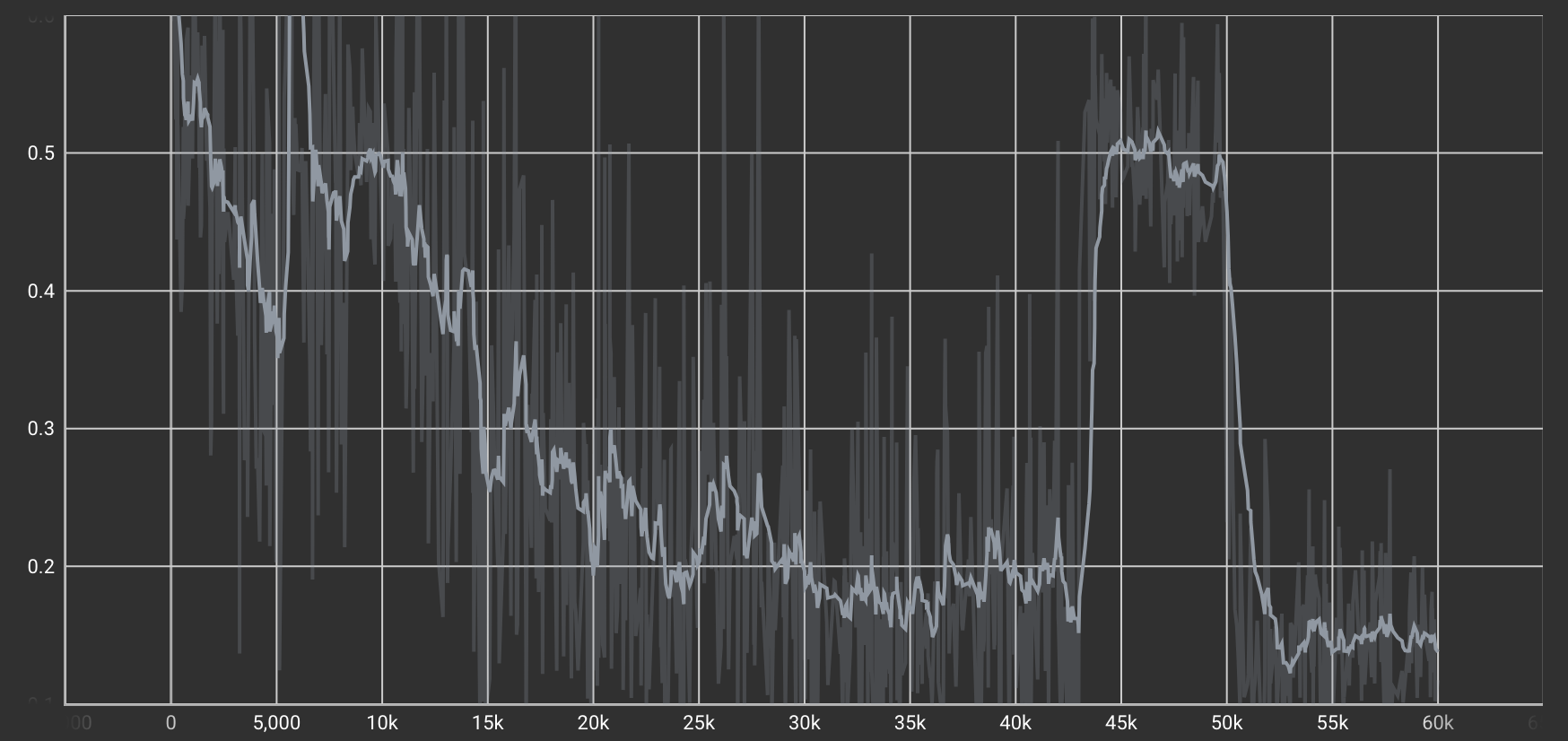 |
全体的にLossは右肩下がりで減少しており、CycleGAN特有の“ガクガクした”変動も見られます。これは、DiscriminatorとGeneratorが競い合いながら学習を進めるため、複数回にわたってLossが増減を繰り返すことによるものです。
Generator Loss(生成損失)
Generatorが「本物っぽい」画像を生成するための損失。Discriminatorを騙せるような画像を作るほど、この値は下がります。
| Lossの種類 | 推移 |
|---|---|
| デール→チップ変換タスクのLoss | 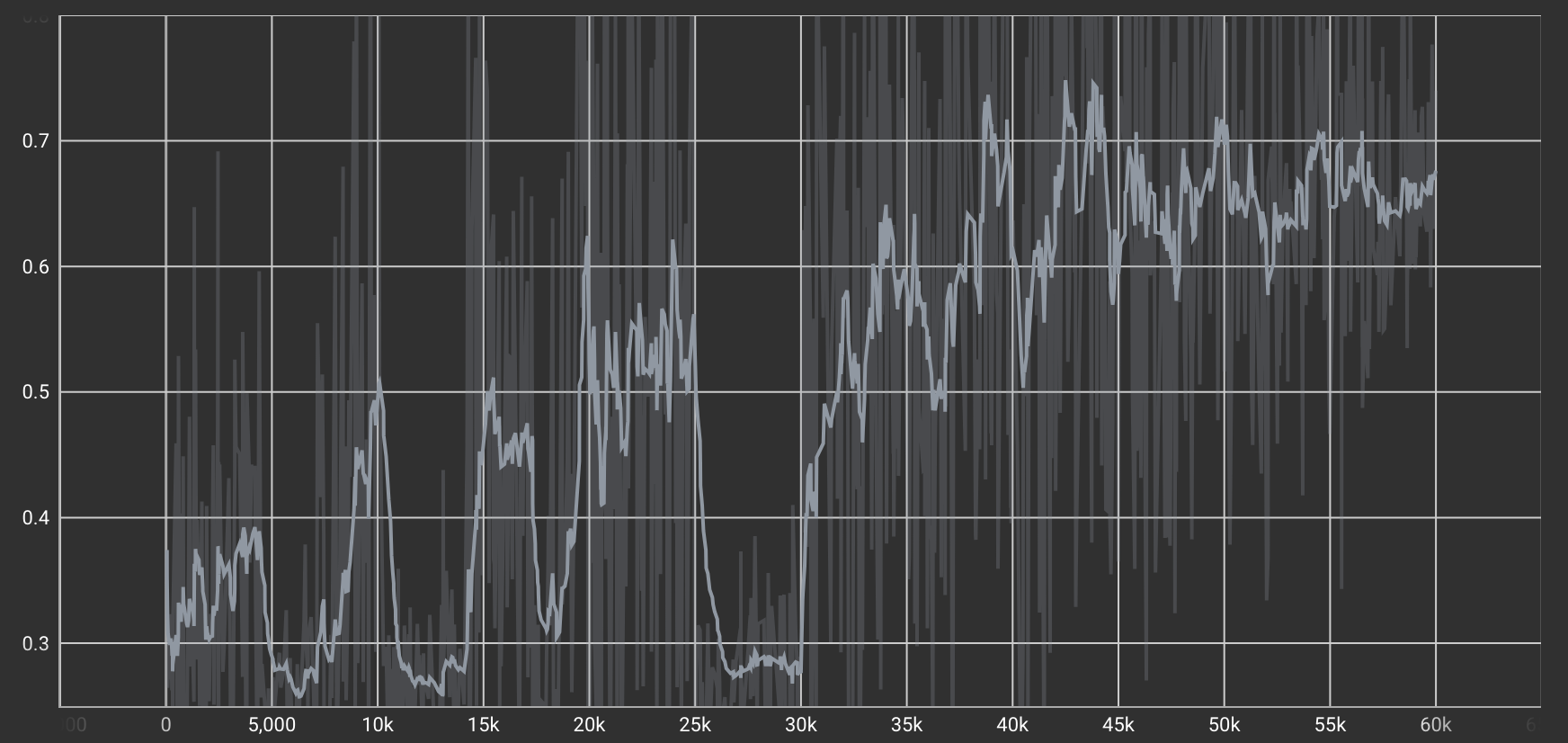 |
| チップ→デール変換タスクのLoss | 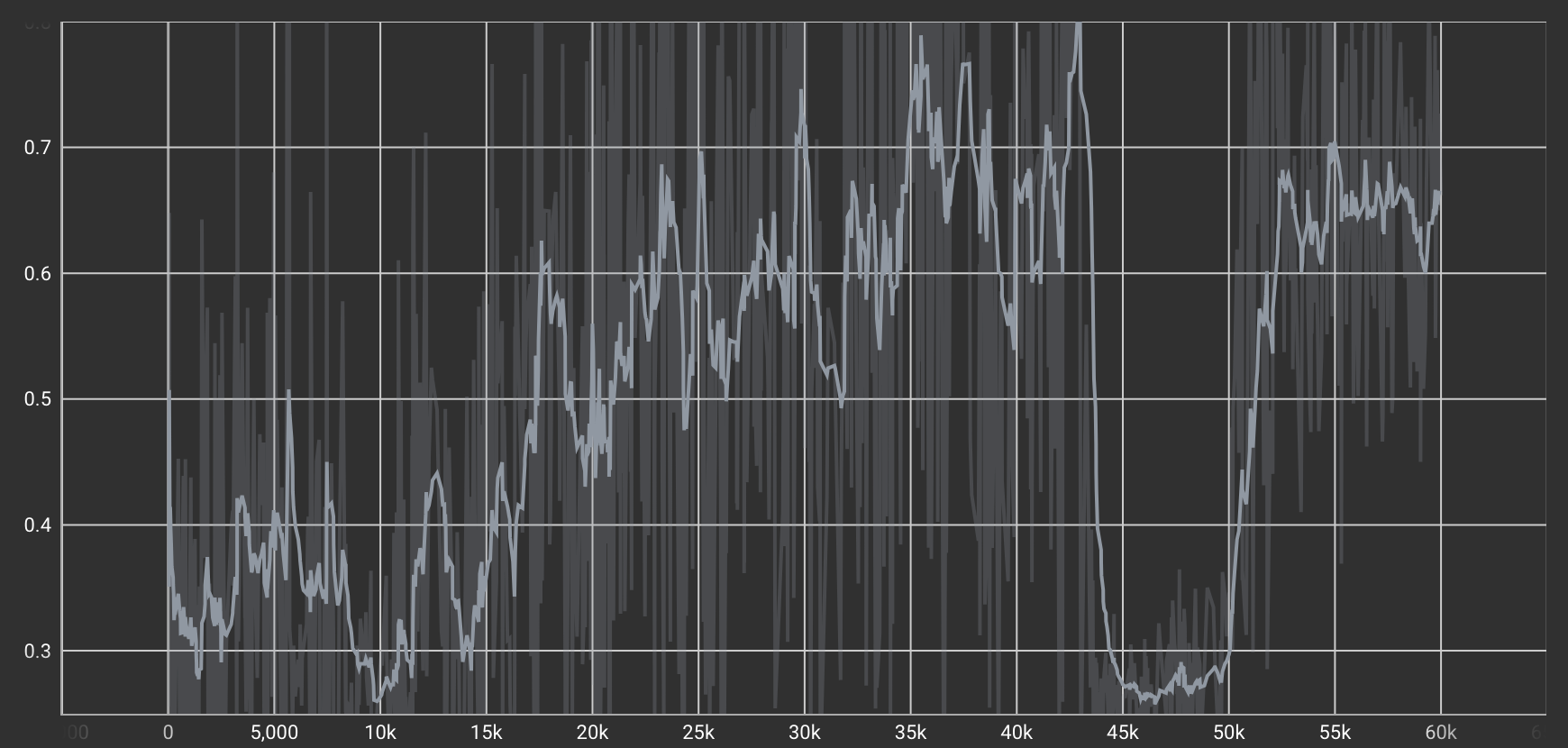 |
こちらも、CycleGAN特有の“ガクガクした”変動が見られます。これはDiscriminatorと同様の理由で、二つのモデルが競い合いながら学習を進めるためです。
Discriminatorが全体的に右肩下がりでLossが減少していた一方で、Generatorは全体的にやや右肩上がりでLossが増加しているように見えます。つまり、Discriminatorの判定が徐々に鋭くなり、Generatorが“本物らしく見せる”ためにより難しいタスクを課されていることが推測されます。これは、Generatorのタスクの難易度がDiscriminatorのタスクよりも高いと言えるかもしれません。
Cycle Consistency Loss(Cycle一貫性損失)
二つの変換モデルを使って「A→B→A'」と往復させたときに、元のAと戻ってきたA'の差を測る損失。
| Lossの種類 | 推移 |
|---|---|
| チップ→デール→チップ変換タスクのLoss | 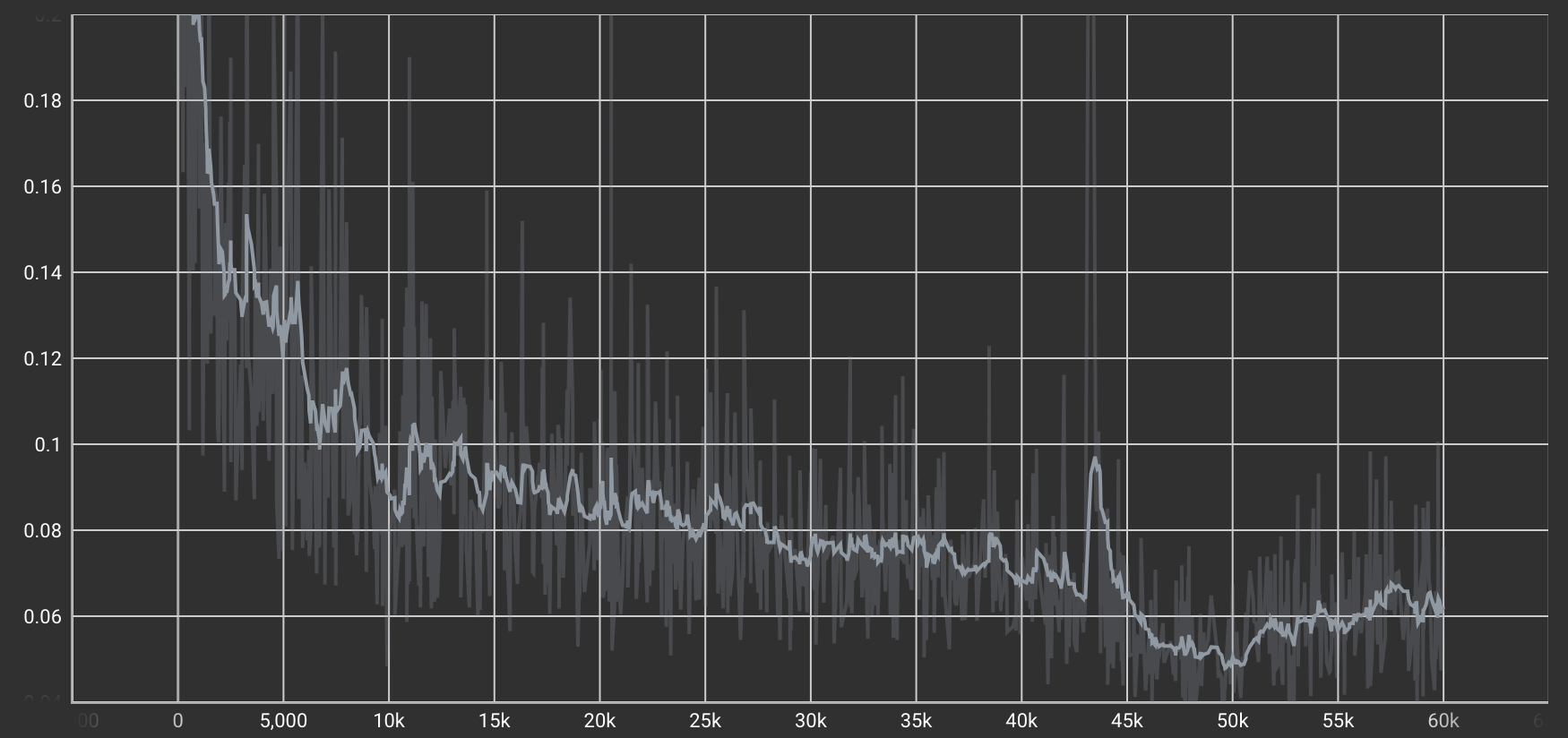 |
| デール→チップ→デール変換タスクのLoss | 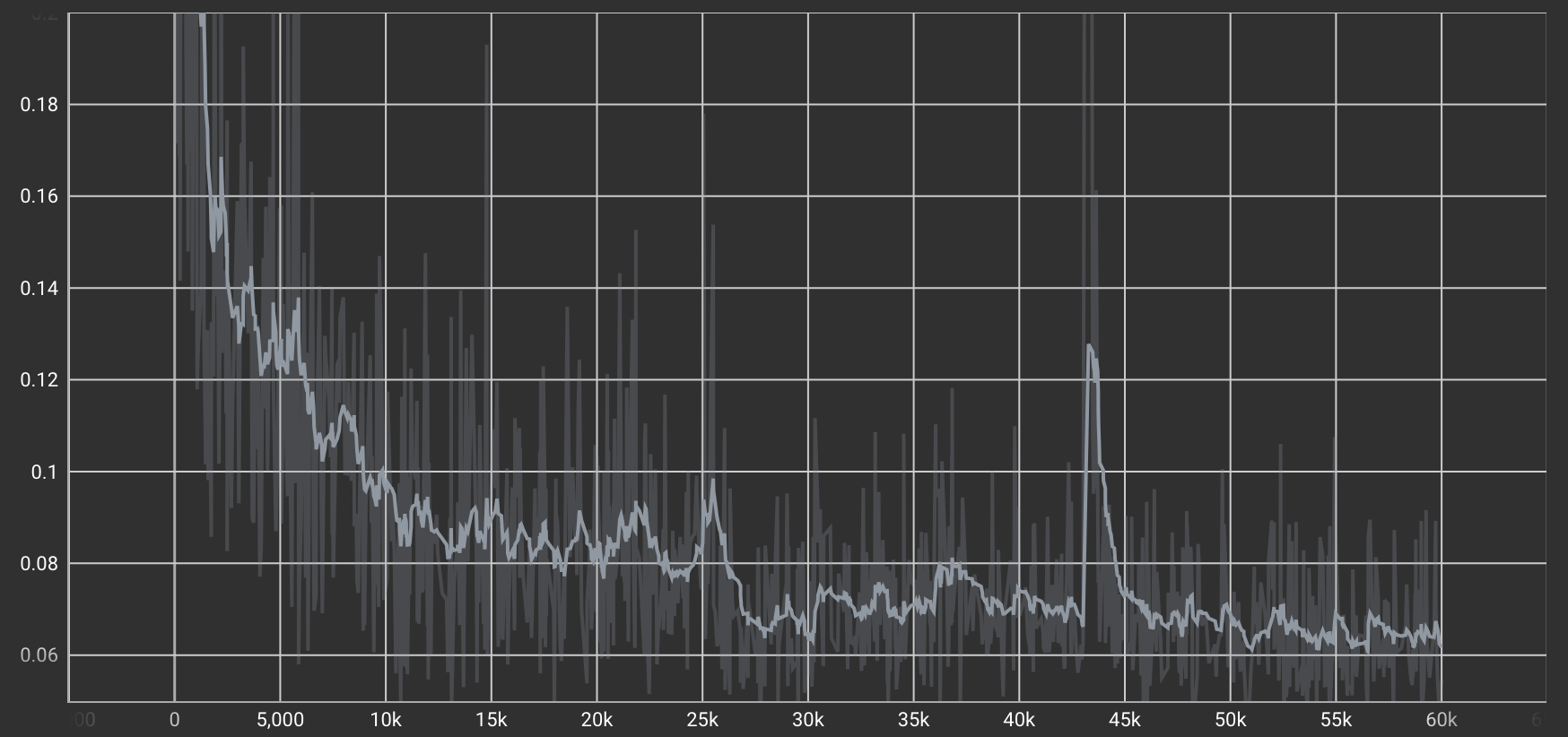 |
100エポックを過ぎたあたりからLossの減少が安定しています。これは、Cycle Consistency(往復変換による整合性)の再現性が高まり、元のスタイルに近い形で復元できるようになってきたことを示しています。モデルが“変換しすぎずに元の特徴を保てる”ようになってきたと考えられます。
Identity Loss(同一性損失)
「B→A'」変換モデルにあえて「A」を入力したとき、元のAと出力されたA'の差を測る損失
| Lossの種類 | 推移 |
|---|---|
| チップ→チップ変換タスクのIdentity Loss | 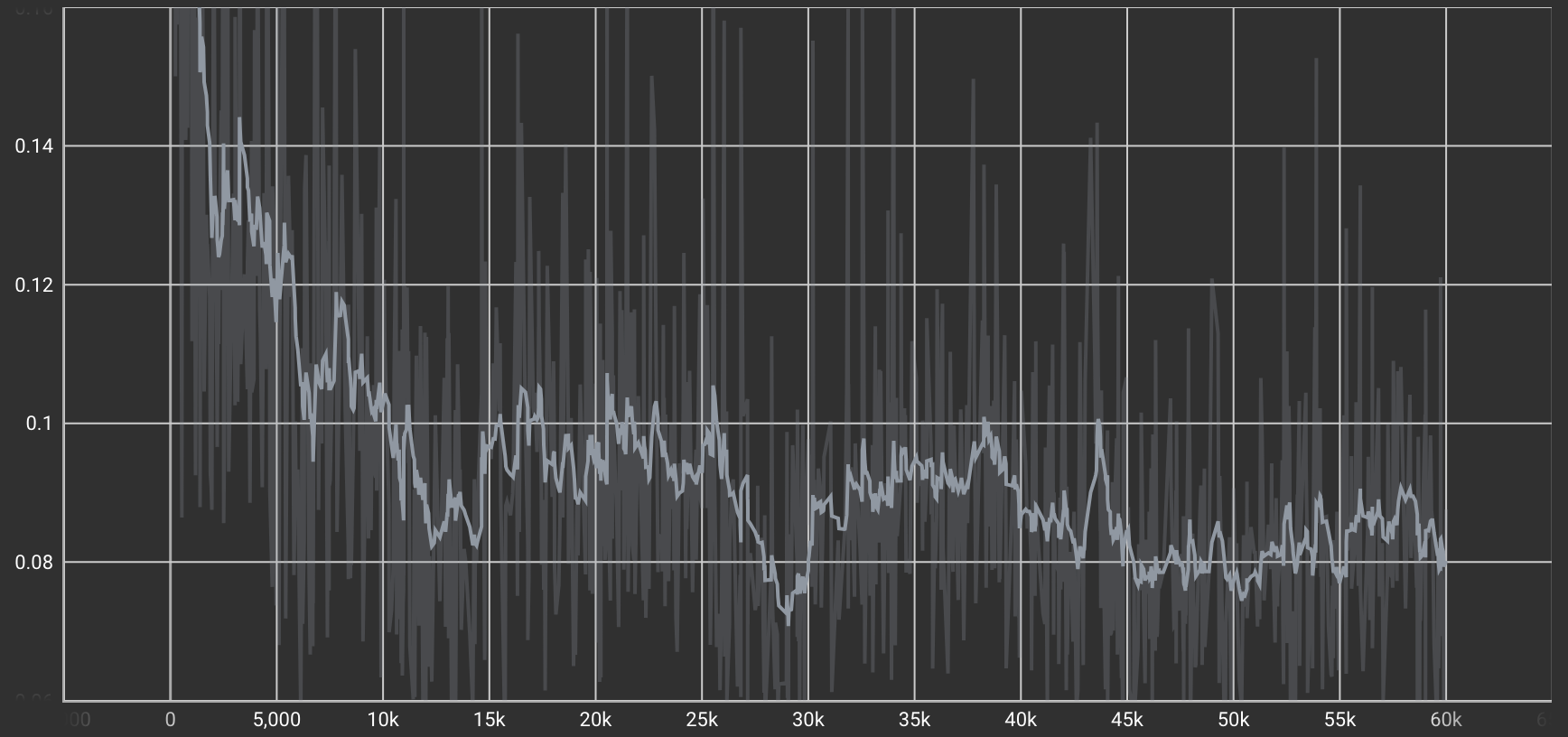 |
| デール→デール変換タスクのIdentity Loss | 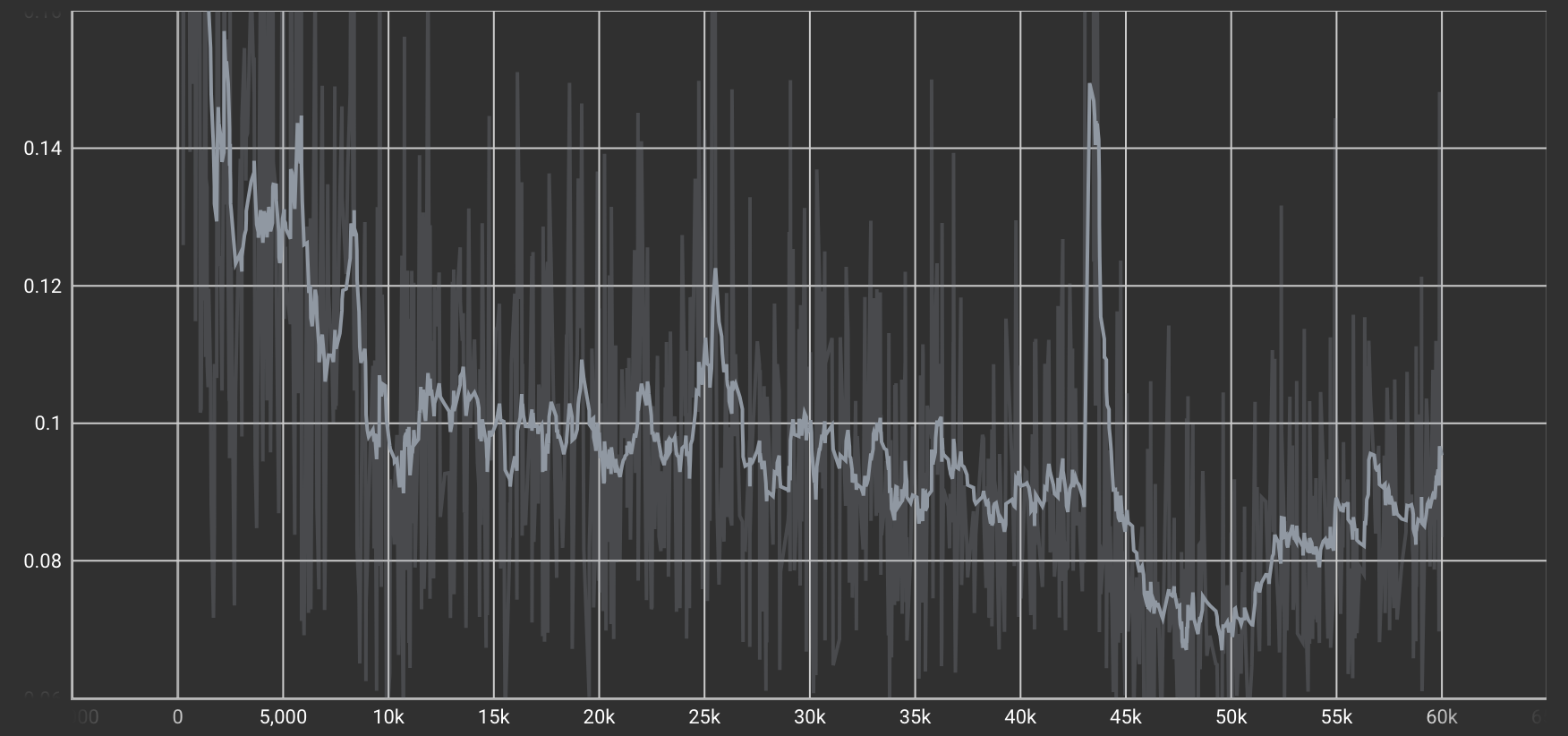 |
こちらもCycle Consistency Lossと同様に途中からLossの減少が安定しており、良い感じですね。Identity Lossが一定の効果を発揮していることが期待できます。
学習済みモデルをテストしてみる
それではお待ちかね、検証用データ(チップ30枚、デール30枚)を学習済みモデルに入力し、変換結果を見てみましょう。(ズームしてご覧ください。)
【チップ→デール変換】

【デール→チップ変換】

両方向の変換共に、多くの画像で違和感なく画像変換が成功しており、「まぶた」、「鼻」、「前歯」の3点がしっかり変換されています。
一方で、「まぶた」、「鼻」、「前歯」のうちの一部しか変換されていなかったり、全く変換されていない画像も存在し、これは「うまくいかなかった例」としてまとめています。これらの画像はチップやデールの顔が正面ではなく横や斜めを向いていたり、光加減が特殊な画像にその傾向があります。
ただこれは正直なところデータセット不足に依るところが大きいでしょう。今回は学習データが200枚ずつで、これはCycleGANのデータセットとしてはかなり少ないです。もしデータセットが十分に多く、正面以外にも横顔や斜めのアングルの画像もあれば、CycleGANは十分な性能を発揮していたでしょう。
学習の進行を観察
CycleGANの面白いところは、GeneratorとDiscriminatorが交互に競争していきながら学習していく点です。
DiscriminatorとGeneratorのLossグラフを比較してみると、まるで対称図のように、片方のLossが増減したタイミングで、もう片方のLossは逆方向に変動していることがわかります。
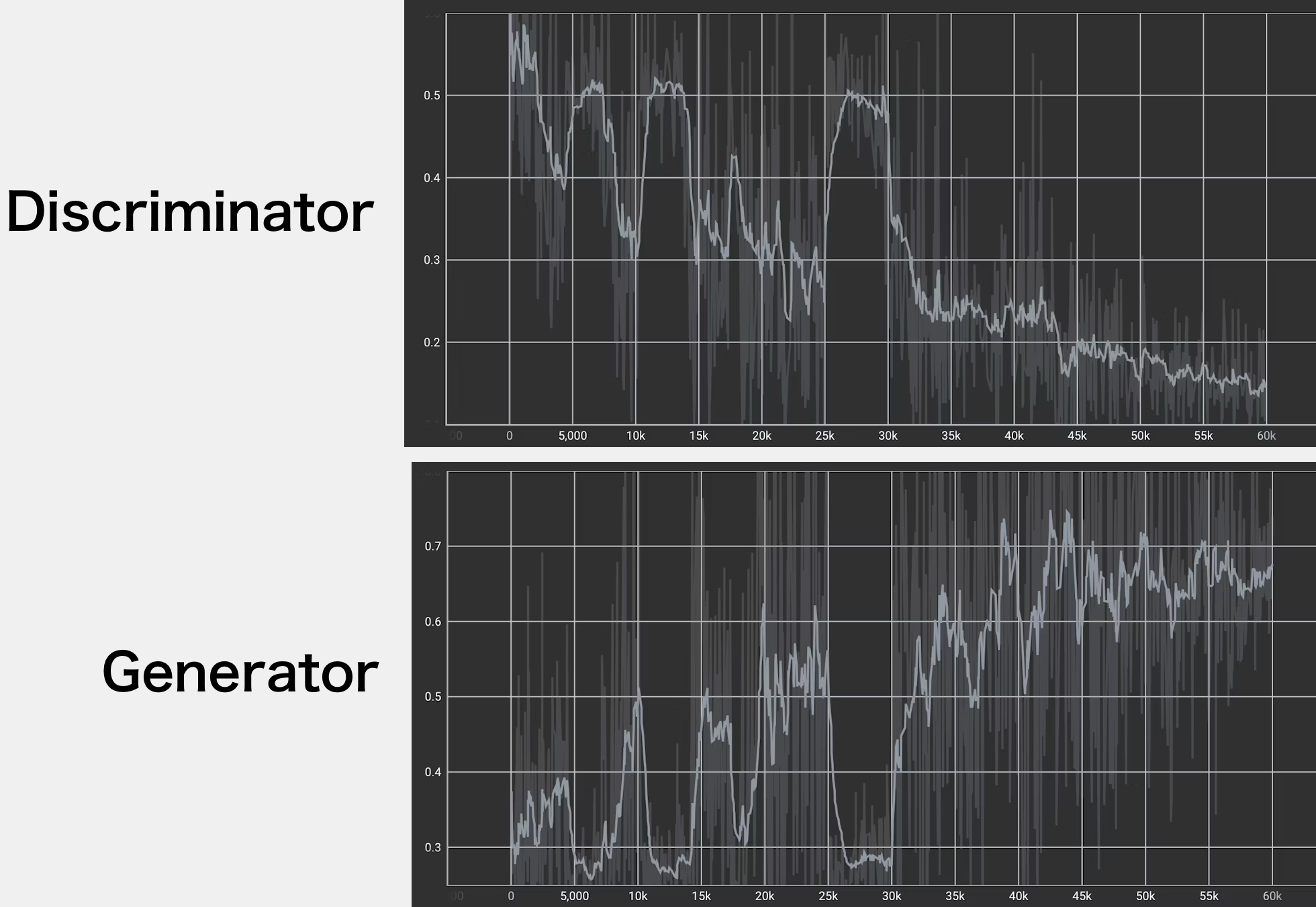
これは、GeneratorがDiscriminatorを一時的に出し抜いて新たな特徴を生成し、それに対してDiscriminatorがまた対抗する──というせめぎ合いの結果です。
もっと言うと、DiscriminatorのLossが跳ね上がるタイミング(GeneratorのLossが大きく下がるタイミング)は、Generatorが新たな特徴を生成し始めたタイミングであり、その時点ではまだDiscriminatorが新たな特徴に対応しきれていないため、DiscriminatorのLossが増えるのです。
実際に今回の学習過程を観察してみると、最初のDiscriminatorのLossの"山"のタイミングで、Generatorが「まぶた」の変換を始めていたことがわかりました。その後でも、DiscriminatorのLossの"山"ができるタイミングでは、Generatorが「鼻」や「前歯」を重点的に変換し始めていたことも確認できました。
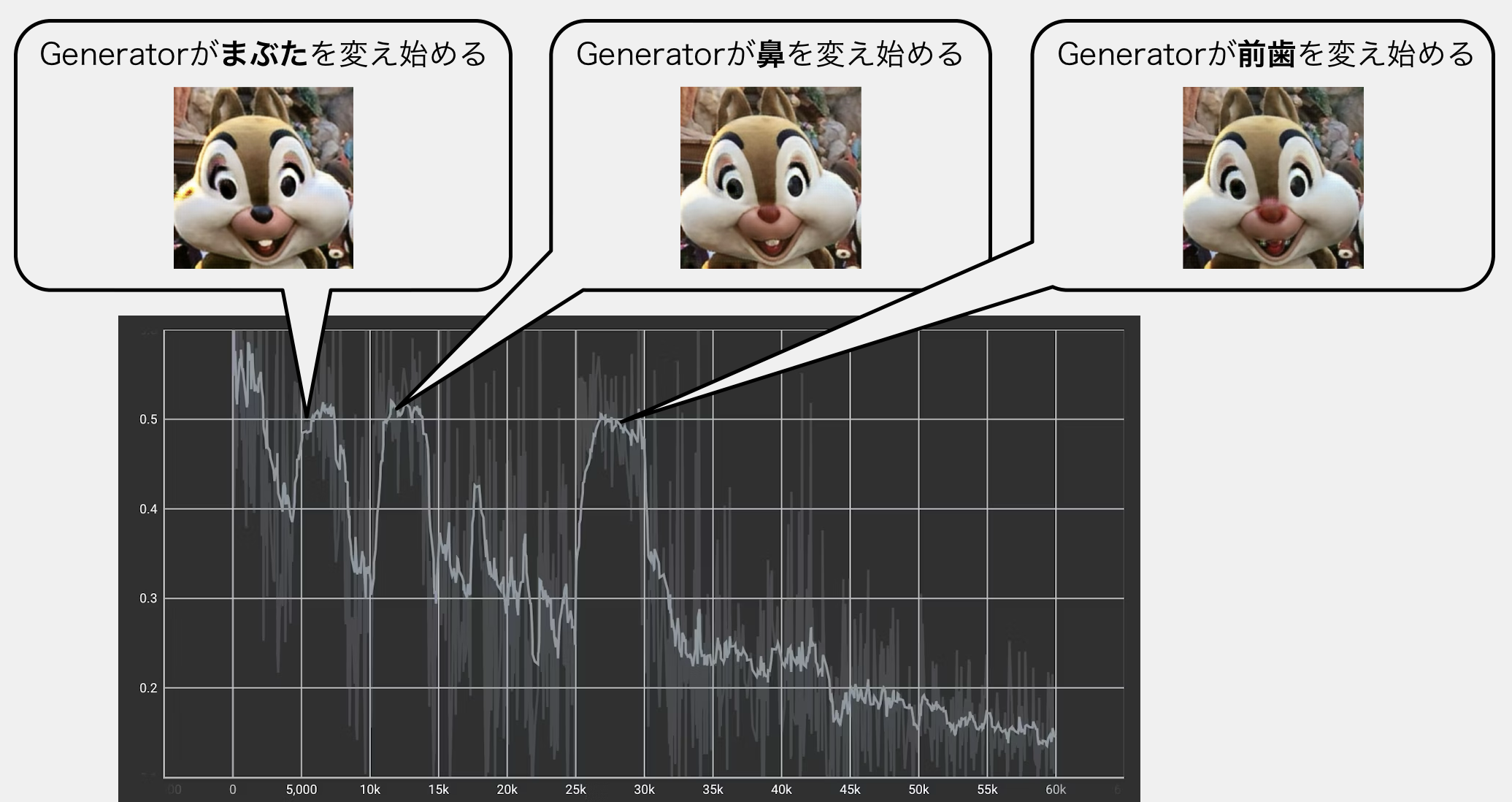
このように、GeneratorはDiscriminatorの対応に合わせて、少しずつ重要な部位に手を加えていくように変換の精度を上げていきます。CycleGANのLossのギザギザは、まさにこのせめぎ合いの証と言えるでしょう。
Identity Lossの効果
CycleGANのLossの一つである「Identity Loss(同一性損失)」はオプショナルですが、今回はありにしていました。これには明確に理由があり、Generatorがチップとデールの顔以外の色味を勝手に変化させることを防ぐためです。
Identity LossありのケースとなしのケースでCycleGANを学習させたとき、それぞれどう結果が異なるのか比較を行いました。
| Identity Lossあり | Identity Lossなし |
|---|---|
 |
 |
このように、Identity Lossを有効にすることで、本来変えてほしい部分(今回は「まぶた」「鼻」「前歯」)以外の特徴、たとえば背景の色味などが不自然に変化することを防ぐことができます。
CycleGANの提唱論文によると、Identity Lossはオプショナルであり、画像の色やスタイルを保つケースに有効だと説明されています。Identity Lossは、「B→A'」変換モデルに「B」ではなく、あえて「A」を入力したとき、元のAと出力されたA'の差を小さくするためのLossです。つまり、できるだけ変化を加えないようにGeneratorを制約することができるのです。
以前の記事で、このCycleGANの効果については考察を行なっているので、気になる方はぜひご覧ください。
おまけ:ミッキーの新旧フェイス変換
最後におまけなんですが、同じ要領でミッキーの新フェイス↔旧フェイスの変換もCycleGANで実行しました。
どういうことなのか説明すると、ディズニーパークに登場するミッキーのフェイスは2016〜2019年で変更が行われているのです。元々はイケメンっぽい顔立ちでしたが、今はカワイイ寄りの顔立ちになりました。今ではファンの方々もすっかり慣れたようですが、変更当時は、慣れ親しまれた旧フェイスを惜しむ声も多くありました。この旧フェイスと新フェイスの相互変換も試してみようというわけです。
私が自分で撮影したミッキーは新フェイスだけなので、ここでは新→旧の変換結果だけお見せしますね。幻の「顔が変わった後の衣装を着た旧フェイスミッキー」がこちらです。

やっぱ旧フェイス、イケメンですね〜。ファンタジースプリングスのスーツがよく似合う。