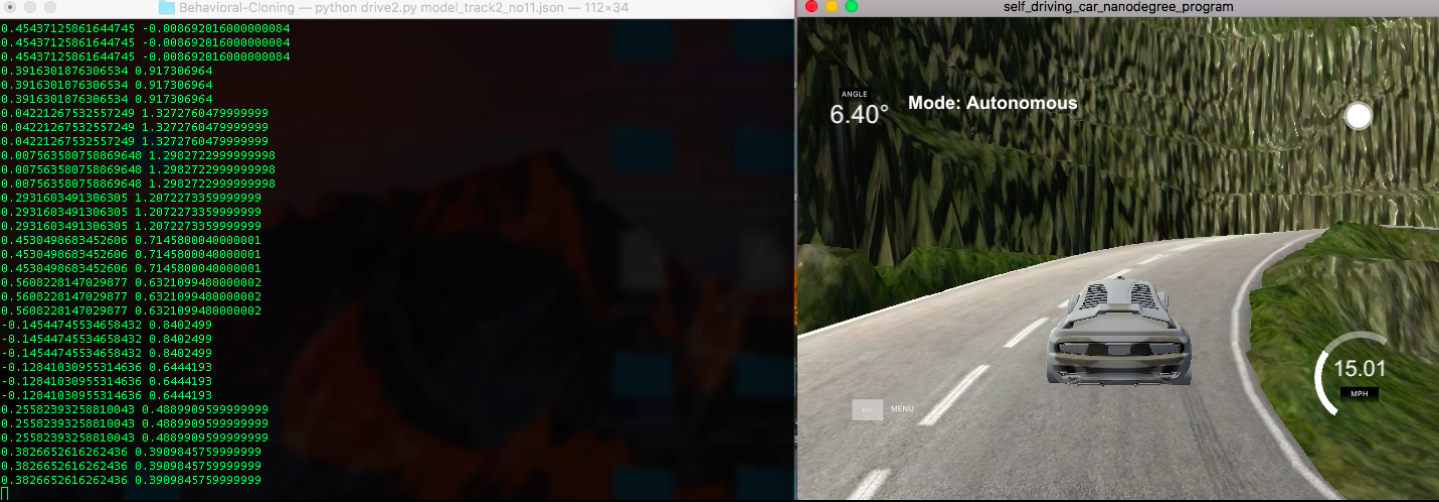
概要
以前紹介したUdacityの自動運転コースのプロジェクトのうちの一つであり,Deep Learningを用いてシミュレータ上で自動車を自動運転するプロジェクトについて説明したいと思います.
用いたシミュレータはここから入手できます.
(本記事で用いたコードはここのmodel.pyにあります.また,1から実装したい方はスターターコードがこちらにあります)
シミュレータ
シミュレータには簡単なコースと難しいコースの2種類があり.今回は主に簡単なコースについて説明することにします.シミュレータにはトレーニングモードと自動運転モードがあり,トレーニングモードを選択し,記録ボタンを押すと,車の左,中央,右から撮られた3種類の画像が保存される.またその画像の他に,保存された画像へのpath,ハンドル量(-1.0~1.0),アクセル量(0~1.0),ブレーキ量(-1.0~0),スピード(0~30.0)がcsv形式で保存される.画像情報を基にハンドル量をDeep Learningを用いて予測し,自動車を自動運転することを考えます.

Fig.1 出力される画像の例
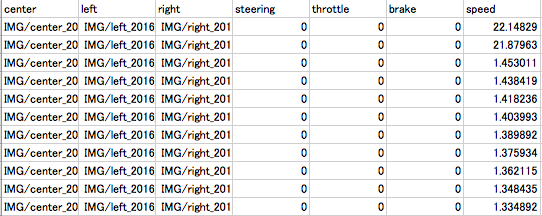
Fig.2 出力されるデータ構造の例
入力データと出力データ
画像を基にハンドル量を予測するために,CNN(Convolutional Neural Network)を用います.入力にシミュレータにより撮られた画像を用い,出力にはその画像から予測されるハンドル量を出力するようにCNNのトレーニングを行います.
アプローチ
左右の画像情報について
入力に用いる画像は左,前方,右の3種類の画像があるが,csvファイルで出力されるハンドル量は中央に対応している.そのため,左,右の画像を用いるために次のようにハンドル量の補正を行った(走行データを大量に集めれば,中央の画像のみで学習を進めることができるが,少ないデータ量で自動運転することを目的とする.)
・左の画像に対しては,ハンドル量を+0.25(右向きにハンドル量を追加)
・右の画像に対しては,ハンドル量を-0.25(左向きにハンドル量を追加)
このように補正をすることで左右の画像を用いることとした(-0.25,+0.25の数値は試行錯誤により求めた).
画像の反転
限られたデータ量で最大限の結果を得るためには,データを拡張する必要がある.その手法の1つに画像を左右反転する方法がある.シミュレータから出力される画像とハンドル量は紐付けされているので,画像を反転した際には,ハンドル量も反転する必要がある.(Fig.3)

Fig.3 画像とハンドル量の反転
def transpose_image(img,steering):
img = cv2.flip(img,1)
return img,-1.0*steering
輝度変化
Deep Learningではモデルの汎化能力を獲得する必要がある.そのため,得られた画像に対してランダムに明るさを変化させる.このようにすることで,様々な路面の明るさに対しても対応することが可能となる.

Fig.4 輝度をランダムに変化
def augment_brightness(img):
img = cv2.cvtColor(np.asarray(img),cv2.COLOR_RGB2HSV)
random_bright = 0.25+np.random.uniform()
img[:,:,2] = img[:,:,2]*random_bright
img = cv2.cvtColor(img,cv2.COLOR_HSV2RGB)
return img
画像のトリミング
CNNを用いて回帰,分類問題を解く際には入力の画像が適切である必要がある.シミュレータにより出力された画像の上部には木や空が写っていたり,下部には車体の一部が見える.これらは不必要な情報であるため,取り除く必要がある.そこで画像の上部から40ピクセル,下部から25ピクセルを切り取った.また,画像サイズを縦66ピクセル,横200ピクセルになるようにサイズの変更を行った.

Fig.5 画像のトリミング
def roi(img):
img =img[40:img.shape[0]-25,:]
return cv2.resize(img,(200,66), interpolation=cv2.INTER_AREA)
ジェネレータの作成
シミュレータにより保存される画像のサイズは3x66x200であり,MNISTの3x32x32と比べてデータ量が大きく,数万枚の画像をメモリに載せることは現実的ではないため,ジェネレータを用いて逐次処理する.
以下のようにジェネレータを作成する.
def image_generator(driving_log):
#データの読み込み
driving_log = driving_log.sample(frac=1).reset_index(drop=True)
for index, row in driving_log.iterrows():
#Select Left,Center,Right image
sel_lcr = np.random.randint(3)
if sel_lcr==0: #左の画像を読み込む
fname = os.path.basename(row['left'])
steering = np.float32(row['steering']) + 0.25
img = load_img('IMG/'+fname)
img =np.array(img)
elif sel_lcr==1: #中央の画像を読み込む
fname = os.path.basename(row['center'])
steering = np.float32(row['steering'])
img = load_img('IMG/'+fname)
img =np.array(img)
else: #右の画像を読み込む
fname = os.path.basename(row['right'])
steering = np.float32(row['steering']) - 0.25
img = load_img('IMG/'+fname)
img =np.array(img)
#Crop and Resize the image
img = roi(img)
#Normalize the image
img = normalization(img)
#Add Random Brightness
aug_bright = np.random.randint(3)
#1/3の確率で画像の輝度を変化させる
if aug_bright ==0:
img = augment_brightness(img)
else:
pass
#Change the color space
img = cv2.cvtColor(np.asarray(img),cv2.COLOR_RGB2YUV)
#Random Flip
trans = np.random.randint(2)
#1/2の確率で画像を反転させる
if trans ==0:
img,steering = transpose_image(img,steering)
else:
pass
#Reshape the image
img = np.reshape(img,(3,66,200))
yield img, steering
以上により作成されたジェネレータをバッチサイズ毎にまとめて処理する.
def batch_generator(driving_log, batch_size=32, *args, **kwargs):
num_rows = len(driving_log.index)
train_images = np.zeros((batch_size, 3, 66, 200))
train_steering = np.zeros(batch_size)
ctr = None
while True:
for j in range(batch_size):
# Reset generator if over bounds
if ctr is None or ctr >= num_rows:
ctr = 0
images = image_generator(driving_log, *args, **kwargs)
train_images[j], train_steering[j] = next(images)
ctr += 1
yield train_images, train_steering
ハンドル角の分布について
入手したハンドル角の分布をFig.6に示す.
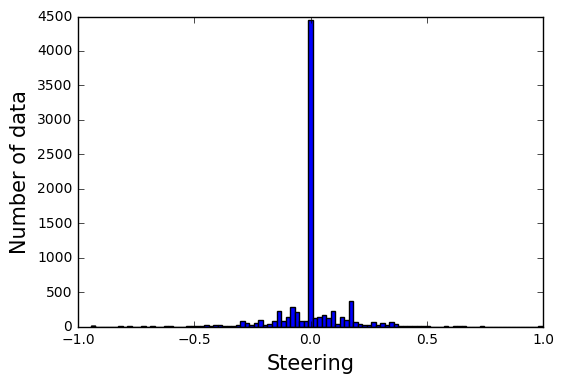
Fig.6 ハンドル角の分布
走行したコースは直線が多く,コーナーがあまりないため,ハンドル角0のデータが多く見られる.このデータ分布をそのまま用いると,コーナーに近づいた時にも真っ直ぐ走行してしまう可能性がある.そのため,ハンドル角0のデータを75%カットした.得られた分布の80%をトレーニングデータ残りの20%を検証データをして扱った.
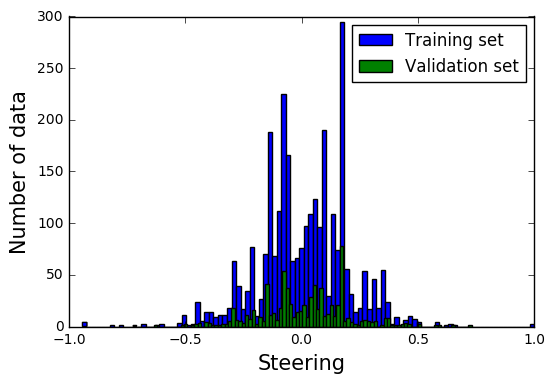
Fig.7 新たなデータ分布
CNNモデルの構造
入力画像を基にハンドル角を予測するためのCNNモデルを構築する必要があるが,NVIDIAが自動運転車を走行させる際に用いられたCNNモデルと同じモデルを用いることにする.
モデルの構造をFig.8に示す.
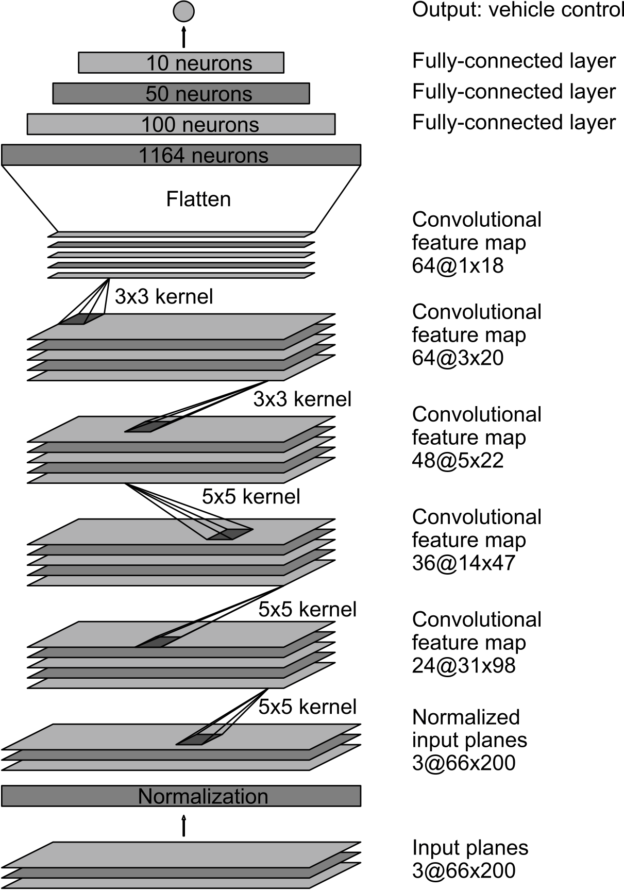
Fig.8 NVIDIA model(Image quoted from here)
この構造を用いて,モデルをトレーニングする.トレーニングのエポック数は2とし,各エポック毎にトレーニングデータ28000枚,検証データ2800枚の画像を学習させるものとする.
#Nvidia Model
model = Sequential()
model.add(Convolution2D(24, 5, 5, subsample=(2,2), activation='relu', name='Conv1',input_shape=(3,66,200)))
model.add(Convolution2D(36, 5, 5, subsample=(2,2), activation='relu', name='Conv2'))
model.add(Convolution2D(48, 5, 5, subsample=(2,2), activation='relu', name='Conv3'))
model.add(Convolution2D(64, 3, 3, activation='relu', name='Conv4'))
model.add(Convolution2D(64, 3, 3, activation='relu', name='Conv5'))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(100, activation='relu', name='FC1'))
model.add(Dense(50, activation='relu', name='FC2'))
model.add(Dense(10, activation='relu', name='FC3'))
model.add(Dense(1, name='output'))
model.summary()
opt = Adam(lr=0.0001)
model.compile(optimizer=opt, loss='mse', metrics=[])
model_json = model.to_json()
model_name = 'model'
h = model.fit_generator(train_data, validation_data = val_data,
samples_per_epoch = 28000,
nb_val_samples = 2800,
nb_epoch=2, verbose=1)
結果
以上の結果がこちらから見ることができます.
おまけ
難しいコースの結果はこちらから見ることができます.