この記事でわかること
GUIで簡単にIBM DB2をMicrosoft Fabricにミラーリングする方法(CData Syncを利用)
はじめに
みなさんは Microsoft Fabric の 「ミラーリング機能」 を使ったことはありますか?
個人的にこの機能は Fabric の中でも特に便利だと感じています。
- 設定が非常にシンプルで、数クリックで接続可能
- 同期するだけなら追加のコストはかからない(ミラーされたデータに対するクエリ(SQL / Power BI / Spark)はCUがかかる)
- ミラーリングストレージコストは一定量無料(例:F64なら64TBまで)
- ニアリアルタイムでデータが同期されるため、最データをすぐにFabricでの分析に活用できる
2025/9時点でミラーリングのサポート対象は以下の画像の通りになります。
ただし、現状の Fabric ネイティブミラーリング機能では、Db2が対象外となっています。業務で IBM DB2 を利用している方は多いと思うので、「そこが対応していないのはちょっと残念…」と思った方もいるのではないでしょうか。
▽DB2のミラーリングはまだ来ていない

ではどうすればよいか?
そこで登場するのが 「オープンミラーリング」 です。
Open mirroring partner ecosystemの記事にあるように
パートナー製品を利用することで、ネイティブには対応していないサービスであっても Fabric にミラーリングすることができます。
今回はその中から CData Sync を利用し、実際に DB2 → Fabric へのミラーリングを試してみました。
Fabric を業務で活用している方や、Salesforce のデータ分析を効率化したい方の参考になればと思います。
▽参考
ファブリックのミラーリングとは
▽FSKUによって無料のミラーリングストレージが変わります(例:F64だと64TBまで)
Microsoft Fabric の価格
▽関連記事
準備するもの(前提)
- CData sync 無料トライアル(今回はクラウド版を使用しました!)
- Fabricの環境(試用版でも可)
- IBM Db2の環境
- 今回は Db2 SaaS on IBM Cloud Liteプラン(無料版)を使用しています
- Db2無料プランの準備方法及びサンプルデータの配置まではこちら
Db2のOpenMirroring設定手順
DB2事前準備
接続資格情報の作成
外部サービスとつなぐためには接続資格情報が必要になります。
Db2インスタンスの[サービス資格情報]タブから[資格情報の作成]をクリックします。
作られた情報は後ほど、CData Syncとの接続に使用します。
Db2側のテーブルの確認
今回は quateテーブル を連携対象とします。
▽Db2の画面(全365レコード)

Fabric 事前準備
ミラー化データベースを作成
Fabric のワークスペースに移動し、
[新しい項目] → [ミラー化されたデータベース] を選択して新規作成します。

作成後に表示される OneLake URL は後で使うのでコピーしておきましょう。
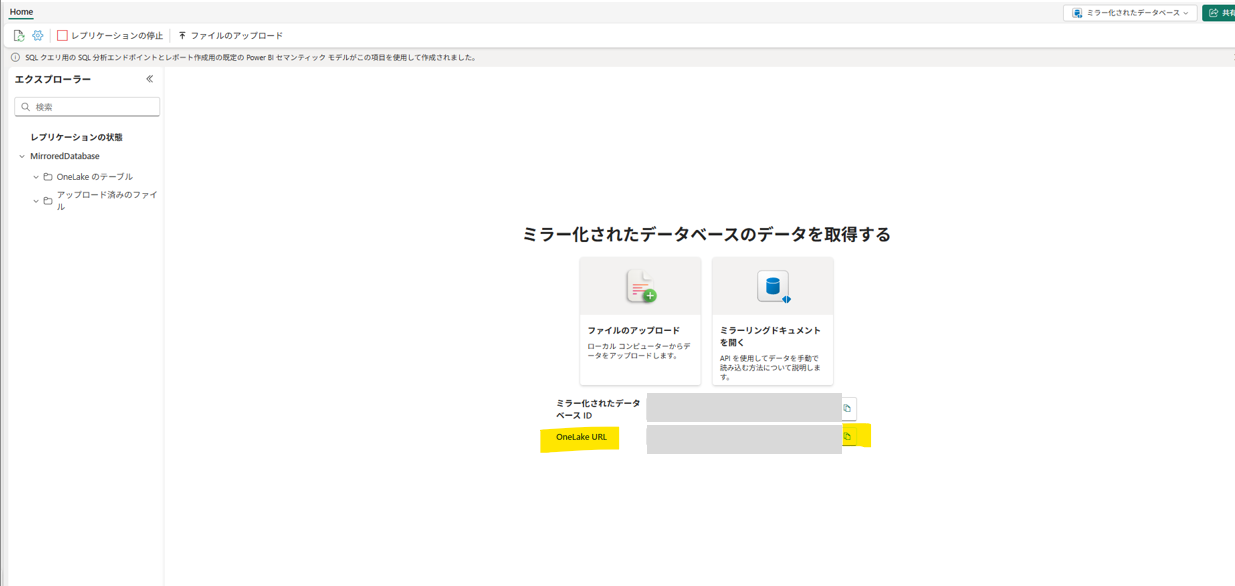
すでに利用中のミラー化されたデータベースを使う場合は、
[レプリケーションの状態]から [ランディングゾーン] のURLをメモしておきます。

CDataで設定
トライアル申し込み後、初期パスワードを変更して CData Sync を開きます。
(私の場合は申し込みから利用可能になるまで約1日かかりました)
OneLake Mirroringの接続の作成
[Connections]のメニューに移動し[Add Connection]をクリックします
(※初回の場合は画面の見え方が違うと思います)

宛先となるミラー化されたデータベースとの接続を作成します。
[Destinations] で [OneLake] を検索し、[Microsoft OneLake Mirroring] を選択します。

必要な情報を入力してください。
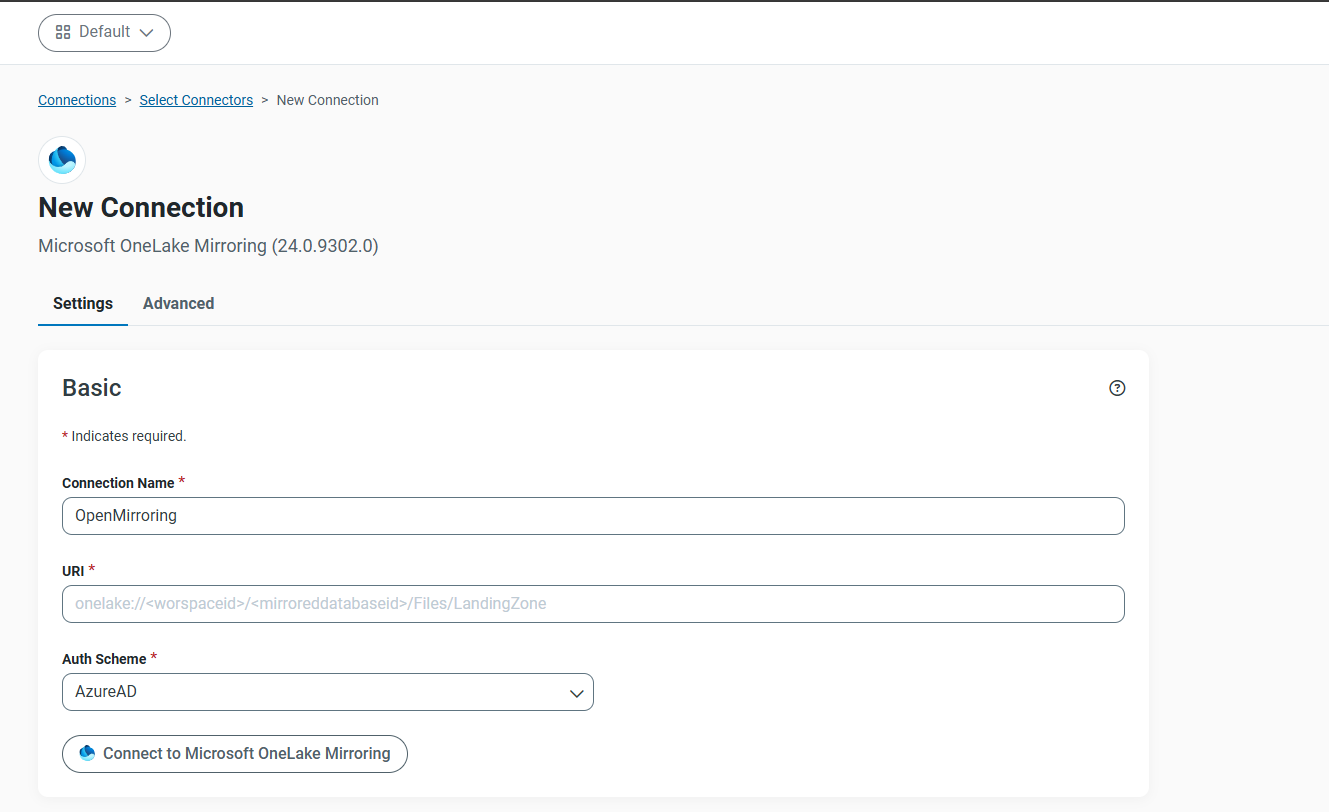
注意点(よくある間違い)
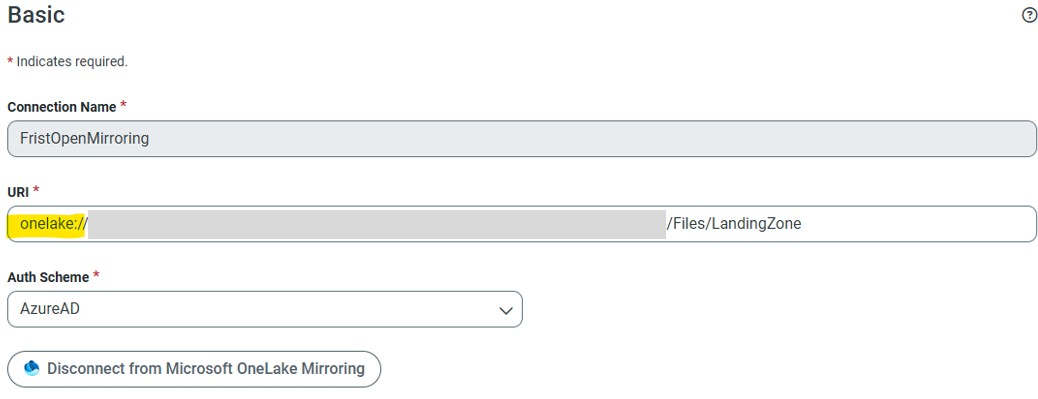
URI にはコピーしておいた OneLake URI(ランディングゾーン)を入力します。
ただし、そのまま貼り付けるのではなく、
https://onelake.dfs.fabric.microsoft.com/
の部分を
onelake:// に置き換えてください
今回は認証に Azure AD(Entra ID)を使用します
入力後、[Connect to Microsoft OneLake Mirroring]をクリックすると別ウインドウでEntra認証が求められますので、認証をすすめてください。
その後、元の画面に戻り、
[Create & Test] を押して接続が正しく作成されたことを確認してください。
Db2の接続の作成
次にソースとなる Db2 の接続を作成します。
[Connections] → [Add Connection] をクリック。
[Sources] で [Db2] を検索し、[Db2] を選択します。
(Db2クラウド版だけでなくオンプレ版もこのコネクタだと予想しています。)
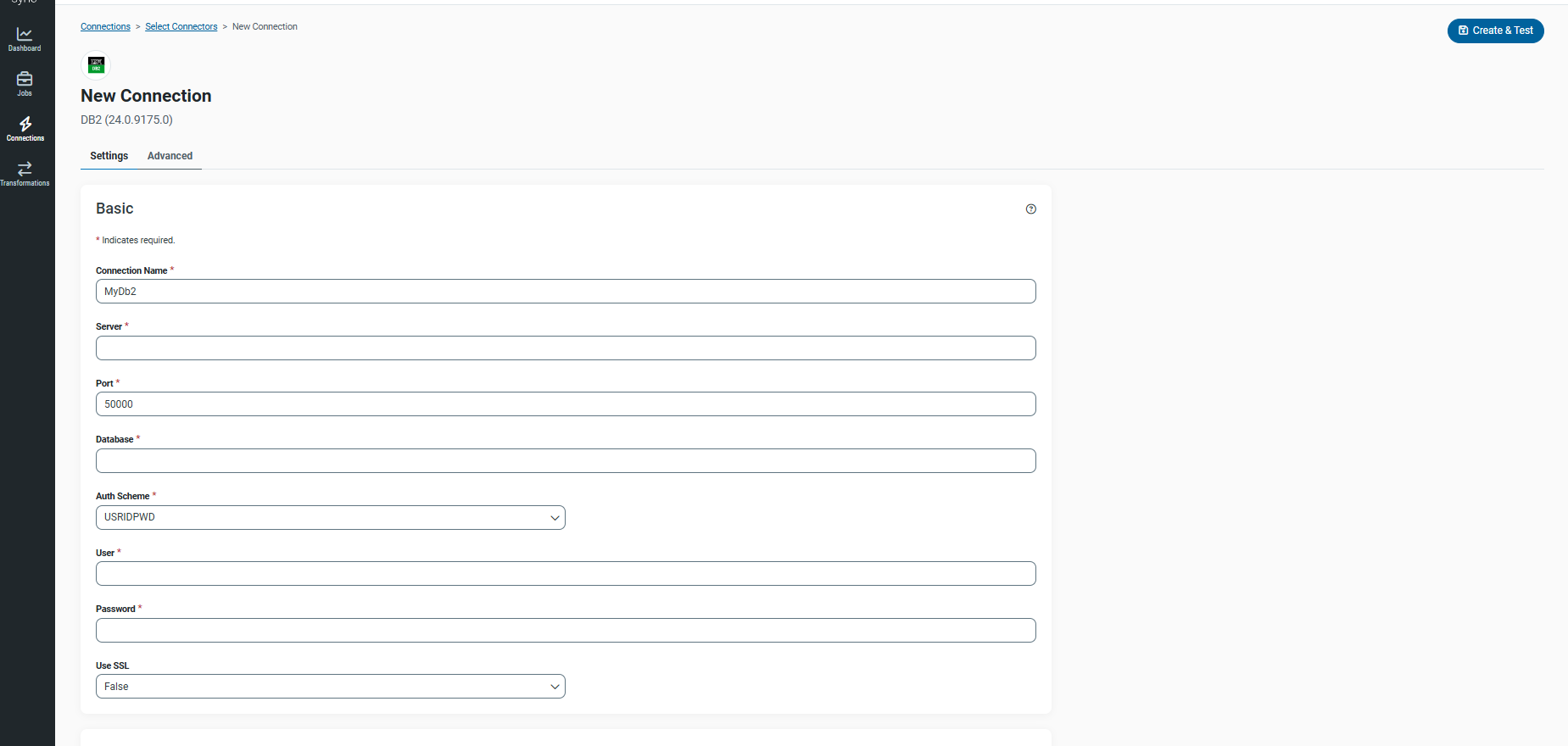
先ほどの資格情報の値を参考に必要な情報を入力してください。
- Server → hostname の値
- Port → port の値
- Database → db の値
- User → username の値
- Password → password の値
- Use SSL → True に設定
認証方式は複数ありますが、今回はデモのためシンプルな USRIDPWD を選びます。

入力が終わったら
接続を作成します。
接続に成功したら画面右上の[Create&Test]を押し、これでDb2との接続の設定は以上になります。
ここまでで以下のように2つの Connection が作成されます。

CData Syncでジョブの作成
いよいよジョブを作成してデータを同期します。
[Jobs]のメニューから[Add Job]>[Add New Job]をクリックします。
(※初回の場合は画面の見え方が違うと思います)

任意のジョブ名を入力し、ソースに Db2、シンクに OneLake Mirroring を指定します。
typeは好きな方を選んでください。
Destination Schema はdboしか選べませんが、入力が必須なのでdboで進めてください。
[Add Job] をクリックするとジョブが作成されます。

Jobの画面に遷移後
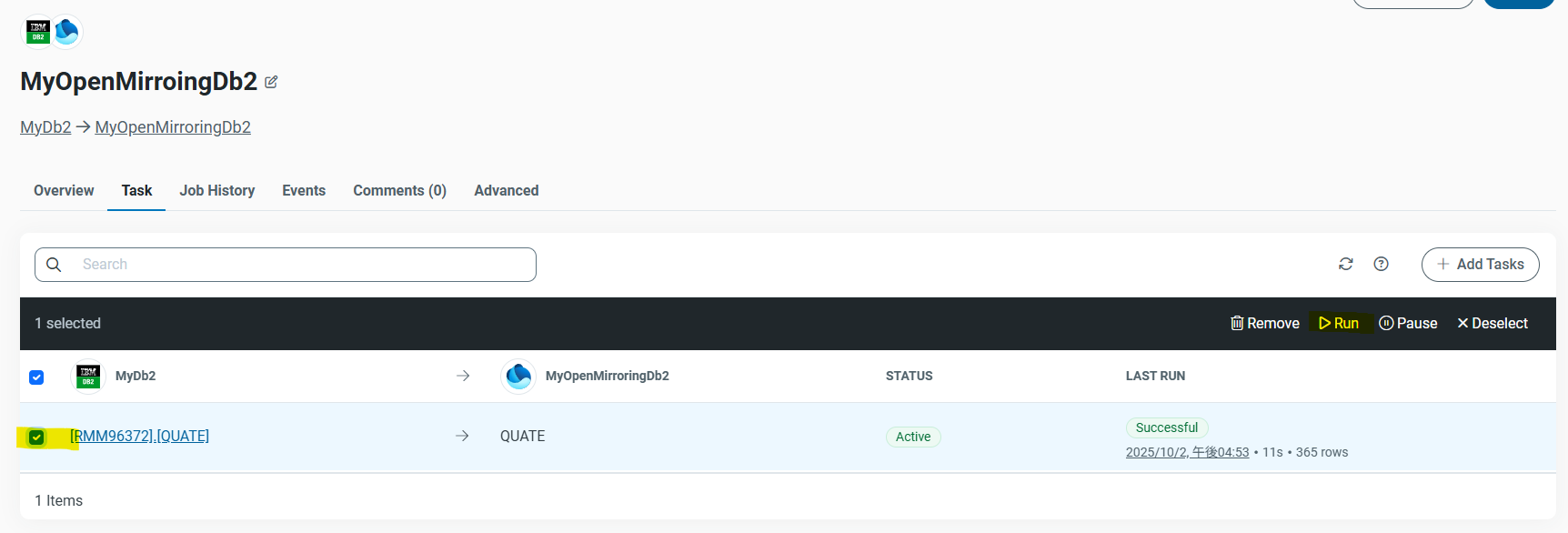
[Task]のタブに移動し、[Add Tasks]をクリックします。

Db2 のテーブル一覧が表示されます。
今回は RMM96372スキーマに配置したQUOTE テーブルを選択して [Add Tasks] をクリックします。
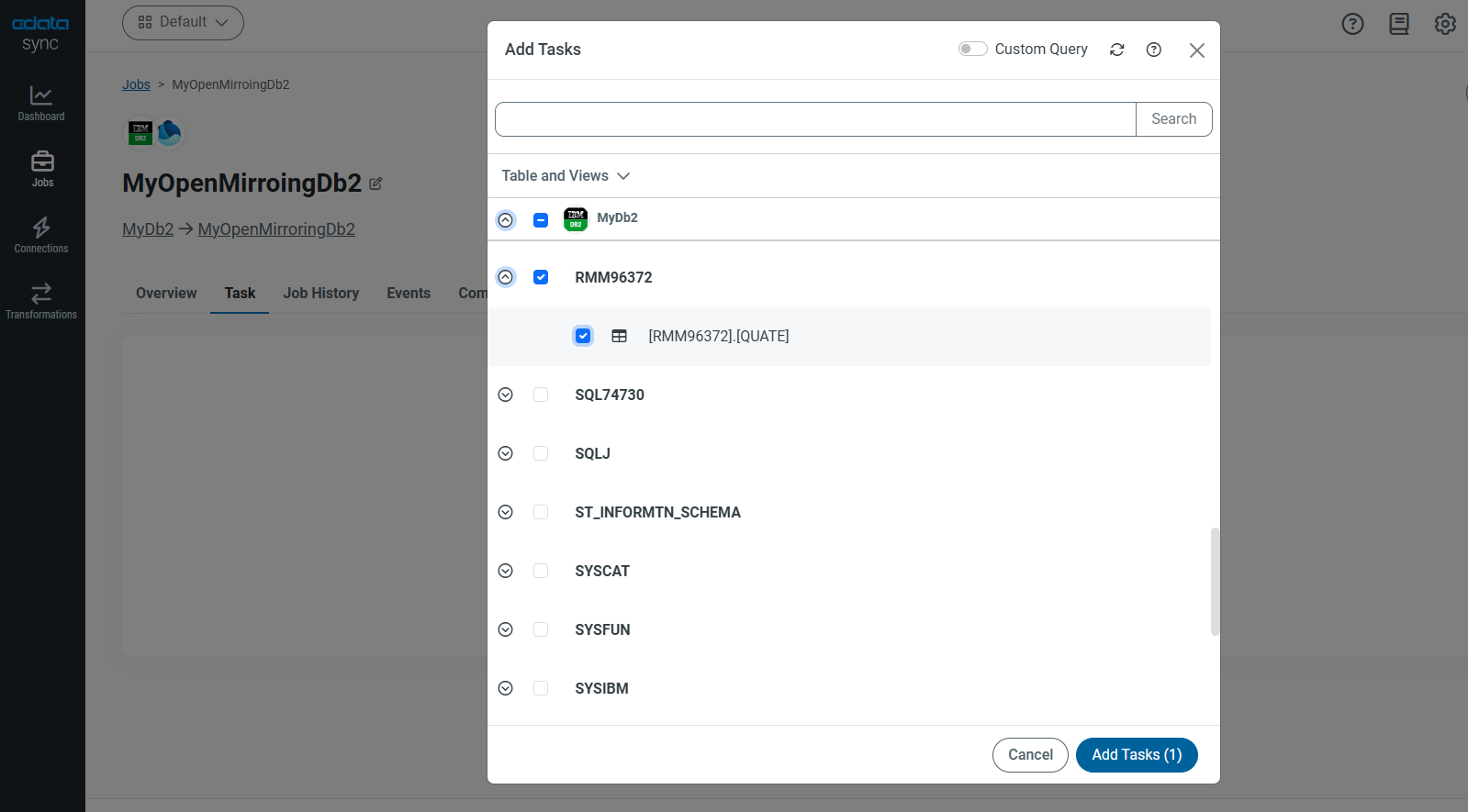
その後、[QUOTE]にチェックをいれ、[Run]をクリックします。
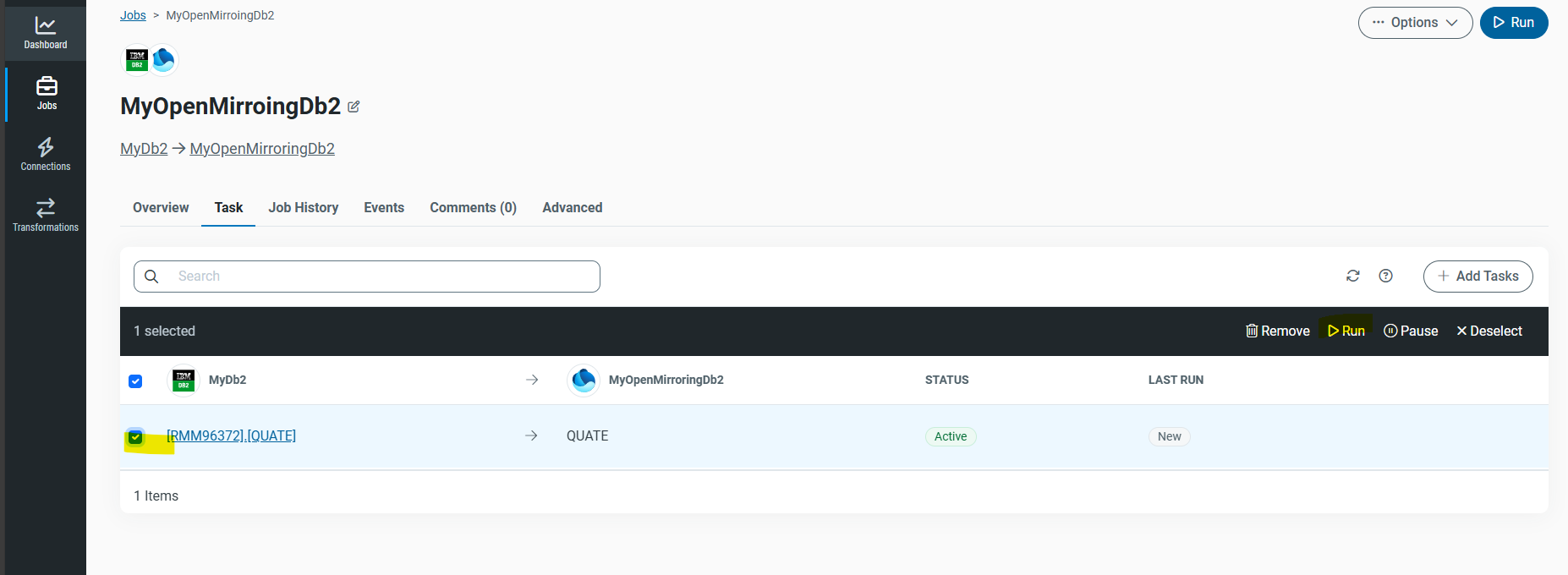
実行が完了すると [Overview] のステータスが Successful になります。
行数(365件)が表示されていれば同期成功です。

ちなみに、[Overview]の Scheduleからジョブ実行のスケジュール設定ができます。

▽CData Syncのジョブ画面で設定できることはこちら
ここまでで[jobs]の画面に1つのJobが追加されます。

Fabricで同期結果を確認
Fabric のミラー化されたデータベースに戻ると、QUOTE テーブルが同期されています。

今回は約1分でFabricへミラーリングされました
▽CData Sync の Job History

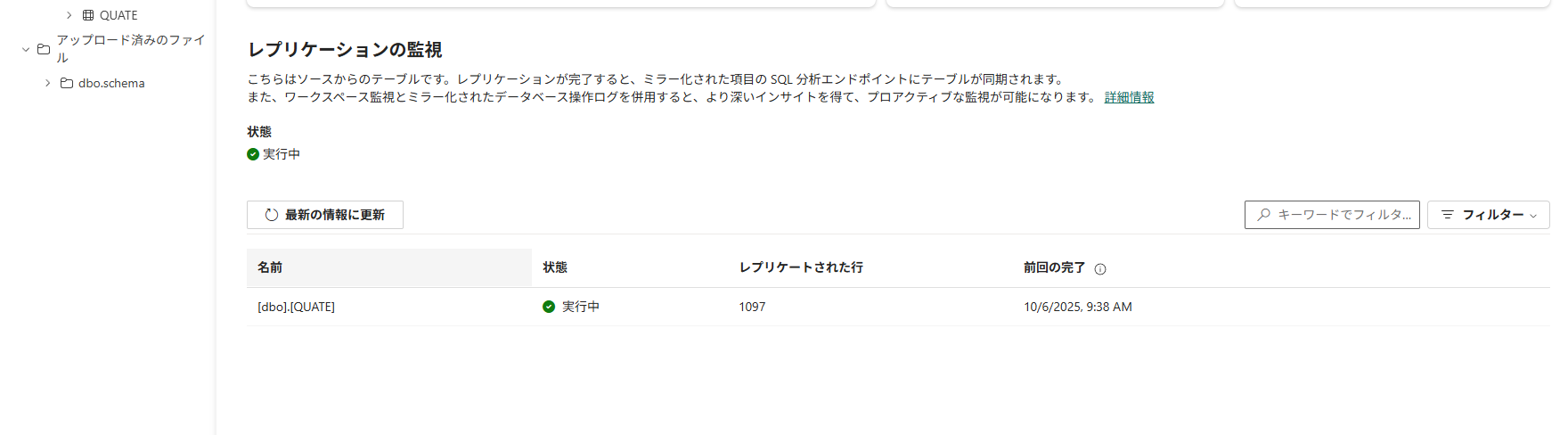
▽Fabricのレプリケーションの監視

レプリケーションの遅延について
ファイル領域への反映はすぐに行われましたが、テーブル領域への反映には少し時間がかかりました。
反映が確認できない場合は、しばらく待ってから再度確認してください。
DB2からデータを追加してみる
DB2 から SQLを使用し、QUOTE テーブルに行を一行追加します。

CData Syncに戻ります。
今回はジョブを手動実行します。
追加行が含まれて連携されましたが、
デフォルトだと差分更新がうまくいっていないのでここは日付列等を設けて今後調整する必要があります。
参考:SalesforceをFabricにミラーリングするパターンだとデフォルトで差分連携がうまくいっています

INSERTの反映をFabricのミラー化されたデータベースで確認
Fabric 側のミラー化データベースに戻り、しばらく待つと変更内容が反映されました。
成功!すごい!簡単!

こちらも約1分でミラーリングされたことを確認しています。
おまけ:CData Syncの価格
最後に少しだけおまけとして、CData Sync の料金について触れておきます。
公式サイトによると、5コネクション・1億レコード/月 のプランであれば、年間128万円ほどで導入できるようです。
(念のため言っておきますが、私はCDataの回し者ではありません…!笑)

一見すると「高いのでは?」と思う方もいるかもしれませんが、
もし自前でAPI連携やETL基盤をゼロから構築しようとすれば、それなりの工数が必要になります。
人件費やメンテナンスコストを考慮すると、むしろこの価格で多様なSaaSやDBと接続できるのはコストパフォーマンスが高いと感じます。
特に、Db2以外にも数百種類のコネクタが用意されているため、「あのサービスのデータをFabricで使いたい」 という場面で強力な選択肢になると考えています。
おわりに
今回は Open Mirroring と CData Sync を利用し、IBM Db2 のデータを Microsoft Fabric にミラーリングする方法を紹介しました。
実際に試してみて感じたのは、CData Sync を使うことで設定が非常にシンプルになり、数クリックでレプリケーションを構成できる点です。複雑な仕組みを開発する必要はなく、短時間で Db2 のデータを Fabric に集約できる のは大きな利点だと思います。
現状でも Fabric のパイプラインを利用して Db2 のデータを取り込むことは可能ですが、その場合はバッチ処理でありリアルタイム性に欠けます。今回の方法では ニアリアルタイムで同期できる ため、より即時性のあるデータ活用が可能になります。
また、ミラーリングを利用することで レプリケーション分のストレージコストが追加で発生しない 点も非常に魅力的です。
もちろん、将来的に Fabric が Db2 のネイティブミラーリングに対応することも期待されます。
ただ、その場合でも CData Sync は Db2 以外の多様な SaaS やデータソースに対応しているため、Fabric がまだ対応していないサービス をミラーリングする手段として引き続き有効であると考えられます。
Youtubeもやっているので見ていただけると嬉しいです!
FabricやDatabricksについて学べる勉強会を毎月開催しています!
次回イベント欄から直近のMicrosoft Data Analytics Day(Online) 勉強会ページ移動後、申し込み可能です!