はじめに
こんにちは。皆さん、機械学習エンジニアのAIが好きなオタクです。今日はMNISTをやってみたいと思います。ちなみにAnaconda JupyterではなくGoogleのColaboratoryという機械学習の学習ツールで行きたいと思います。
kerasとは
そもそもkerasが何かを軽く見てみます。
Keras Documentation
Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです。 Kerasは,迅速な実験を可能にすることに重点を置いて開発されました. アイデアから結果に到達するまでのリードタイムをできるだけ小さくすることが,良い研究をするための鍵になります。
Pythonの使い方さえ分かれば今回kerasの使い方もすぐ理解できると思います。
MNISTとは
28x28ピクセル、白黒画像の 手書き数字 のデータセット。各ピクセルは0(白)~255(黒)の値をとる。6万枚の学習用画像と1万枚のテスト画像が入っている。
Colaboratoryに接続
ネットで検索してリンクをクリックするとこちらのページに入ります。
Hello, Colaboratory
次に左上のファイルをクリックしPython3の新しいノートブックをクリックして新しいスクリプトを生成します。
するとこういう画面が出ます。
ここで筆者が驚いたのはこの環境をGPU設定が可能です。すごくないですか???GPU環境ですよ!しかも無料です!早速設定してみましょう
ランタイムのランタイムのタイプ変更をクリックします。
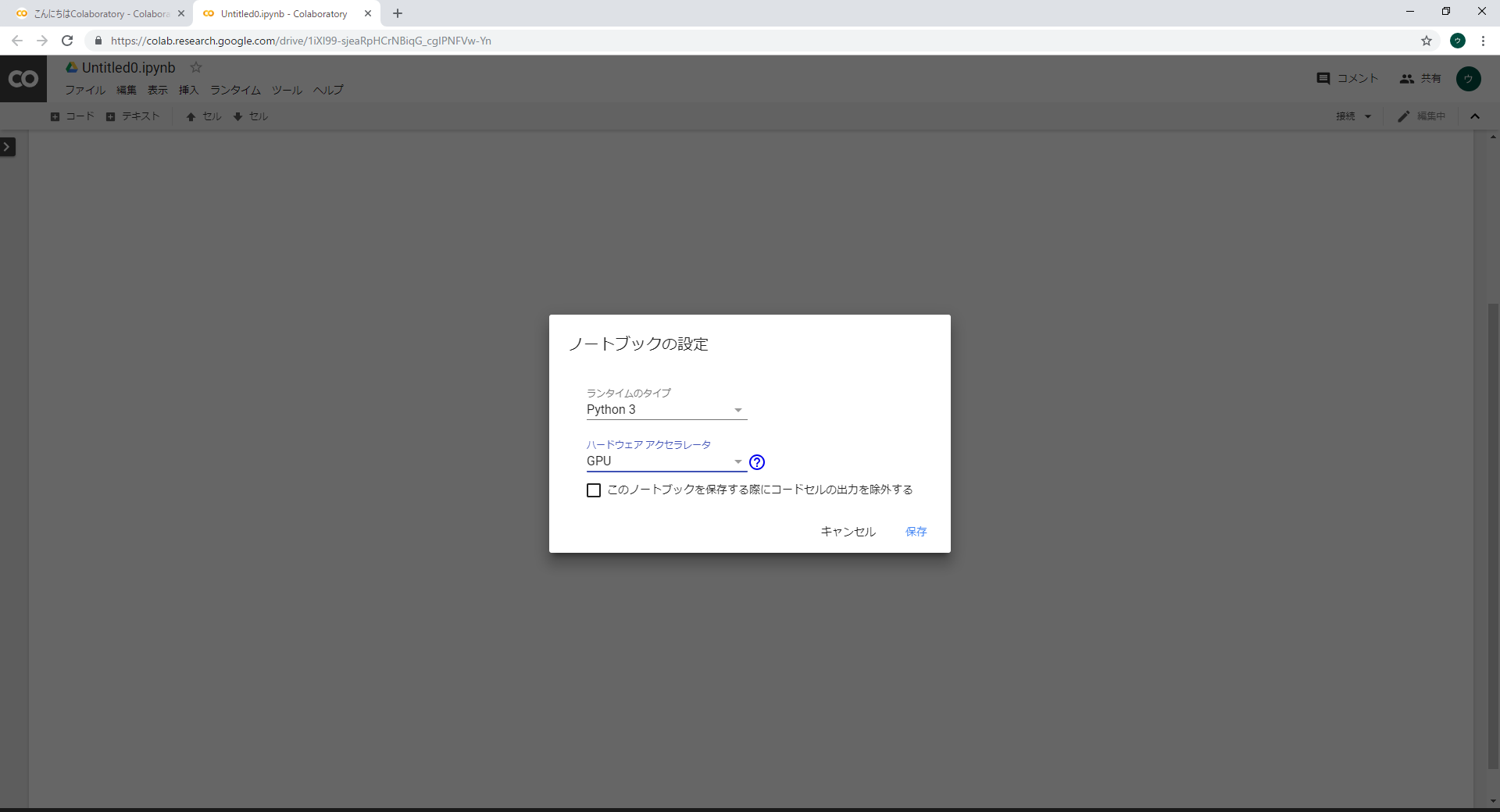
こういう画面が表示されハードウェアアクセラレータの項目をGPUに変更するだけで準備オッケーです。
コードの流れ
今回のMNISTは現在筆者が学習しているAI Academyこちらのサイトを参考にして学習してます。他のサイトよりわかりやすいしクイズもあって自分がちゃんと理解できたのかもチェックができます。
まず、kerasのライブラリと変数を定義します。
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10 # 0~9までの手書き文字
epochs = 12 # 訓練データを何回繰り返して学習させるのか
img_rows, img_cols = 28, 28
MNISTのデータをネットワークからダウンロードし学習とテスト用に整形します。
# 学習データとテストデータに分割したデータ
(x_train, y_train), (x_test, y_test) = mnist.load_data()
Kerasのbackendを使ってパターンを作ります。
# backendがTensorflowとTheanoで配列のshapeが異なるために2パターン記述
if K.image_data_format() == 'channels_first':
# 1次元配列に変換
x_train = x_train.reshape(s_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
# 1次元配列に変換
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
keras Documentationこっちの説明だとK.image_data_format()はこういうものです。
画像におけるデフォルトのフォーマット規則('channels_first' か 'channels_last')を返します。
上記のchannels_first, channels_lastによって指定する引数の順序が異なるらしいです。
次はMNISTのデータを加工します。
# 入力データ[0, 1]の範囲に正規化
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 255で割ったものを新たに変数とする
x_train /= 255
x_test /= 255
print('x_train shape : ', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
ラベルをバイナリ化します。
# ラベルをバイナリベクトルとして扱う
# Kerasはレベルを数値ではなく、0or1を要素に持つベクトルで扱うため
"""
例えば、サンプルに対するターゲットが「5」の場合次のような形になります。
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
"""
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
次は学習に必要なネットワークの構築です。
# CNNネットワークの構築
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
# 損失関数,最適化関数,評価指標を指定してモデルをコンパイル
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
簡単にDropoutについて説明を見ます。
訓練時の更新においてランダムに入力ユニットを0とする割合であり,過学習の防止に役立ちます。
つまり学習の際に過学習を予防するため0.25=25%の入力が破棄されているのがわかります。
ネットワークの上で学習を行います。
# モデルの学習
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
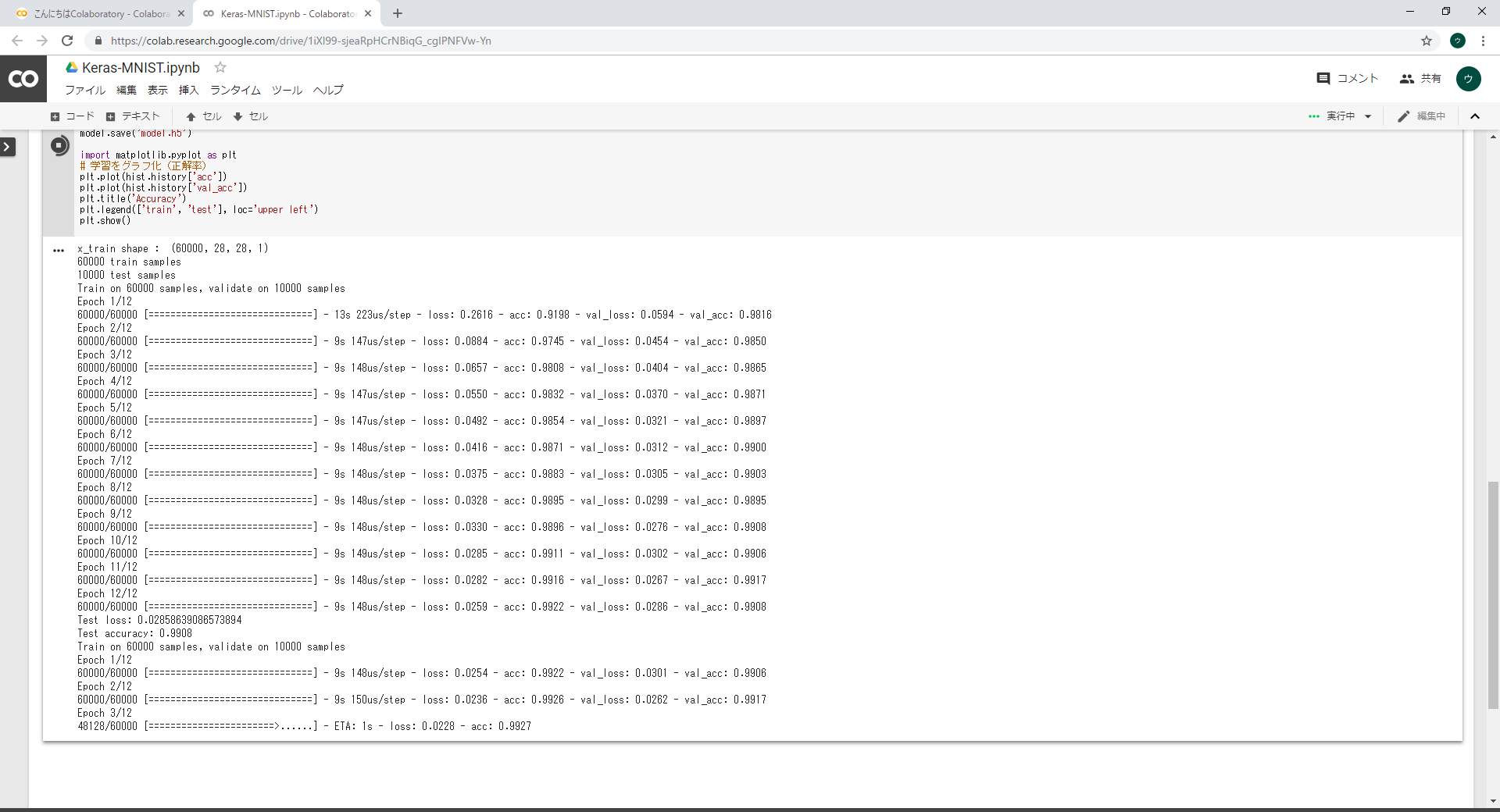
学習したモデルの精度を見てみましょう
# モデルの評価
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
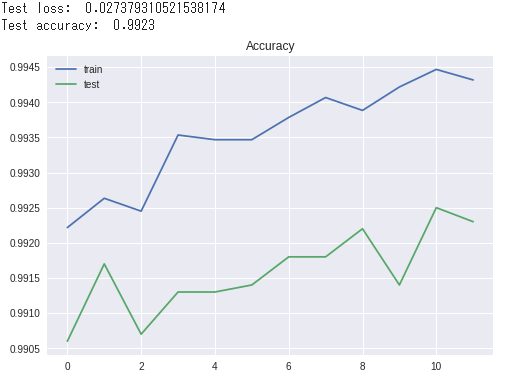
最後に結果を確認します。
import matplotlib.pyplot as plt
# 学習をグラフ化(正解率)
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
まとめに
今回はColaboratoryというツールでやってみました。JupyterのようにAnacondaや各ライブラリーのインストールも要らないしすぐ使えるところがすごくいいですね。