実装したCNNを利用し、MNISTでの精度を確認してみます。
プログラムは、「ディープラーニングを実装から学ぶ(8)実装変更」、「ディープラーニングを実装から学ぶ(9-1)CNNの実装」を利用します。
1層の畳み込み+マックスプーリング
まずは、CNNの1層をためしてみます。
パディングなし
パディングなしで、フィルタサイズを3~15(奇数)、フィルタ数を1~10まで変更して試してみます。
まずは、データをロードし、3次元にreshapeします。
# データ読み込み
x_train, t_train, x_test, t_test = load_mnist('c:\\mnist\\')
data_normalizer = create_data_normalizer(min_max)
nx_train, data_normalizer_stats = train_data_normalize(data_normalizer, x_train)
nx_test = test_data_normalize(data_normalizer, x_test)
# 3次元にreshape
nx_train = nx_train.reshape(nx_train.shape[0], 28, 28, 1)
nx_test = nx_test.reshape(nx_test.shape[0], 28, 28, 1)
モデル
モデルは、以下のようにしました。
畳み込み、マックスプーリング、全結合の順です。全結合の中間層は、今まで試していた、100ノード、50ノードの2層です。活性化関数は、ReLUです。
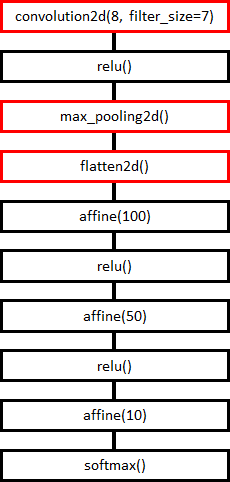
学習
ハイパーパラメータです。
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
時間がかかるため、エポック数は、30にしました。30エポック学習後に、モデルを保存しておきます。
learn_info = {}
# フィルタ数、フィルタサイズを変更しながら実行
for d in range(1,11):
for filter_size in range(1,16,2):
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size)
print(name)
model = create_model((28,28,1))
model = add_layer(model, "conv1", convolution2d, d, filter_size=filter_size)
model = add_layer(model, "reluc1", relu)
model = add_layer(model, "pooling1", max_pooling2d)
model = add_layer(model, "flatten", flatten2d)
model = add_layer(model, "affine1", affine, 100)
model = add_layer(model, "relua1", relu)
model = add_layer(model, "affine2", affine, 50)
model = add_layer(model, "relua2", relu)
model = add_layer(model, "affine3", affine, 10)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
optimizer = create_optimizer(SGD)
epoch = 30
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch, optimizer=optimizer)
save_model(model, "cnn_model/model_"+name+".mdl")
実は、これ、動かすと1日では終わりませんでした。本当は、もっとフィルタ数を増やしたかったのですが時間がかかり過ぎるため断念しました。
結果
テストデータの正解率(%)の最大です。横がフィルタ数、縦がフィルタサイズです。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 97.27 | 97.29 | 97.44 | 97.53 | 97.46 | 97.38 | 97.38 | 97.58 | 97.53 | 97.44 |
| 3 | 97.70 | 98.12 | 98.23 | 98.54 | 98.58 | 98.63 | 98.67 | 98.73 | 98.74 | 98.70 |
| 5 | 97.89 | 98.38 | 98.58 | 98.73 | 98.96 | 98.93 | 98.90 | 98.98 | 98.96 | 99.00 |
| 7 | 97.83 | 98.49 | 98.64 | 98.73 | 98.84 | 99.04 | 98.96 | 98.92 | 98.95 | 98.94 |
| 9 | 97.68 | 98.33 | 98.63 | 98.75 | 98.81 | 98.88 | 98.94 | 99.10 | 98.99 | 98.94 |
| 11 | 97.56 | 98.18 | 98.61 | 98.81 | 98.85 | 98.93 | 98.97 | 98.97 | 99.08 | 98.92 |
| 13 | 97.12 | 98.01 | 98.39 | 98.71 | 98.66 | 98.65 | 98.77 | 98.82 | 98.87 | 98.97 |
| 15 | 96.92 | 97.75 | 98.15 | 98.39 | 98.56 | 98.43 | 98.79 | 98.61 | 98.91 | 98.63 |
グラフ化してみます。
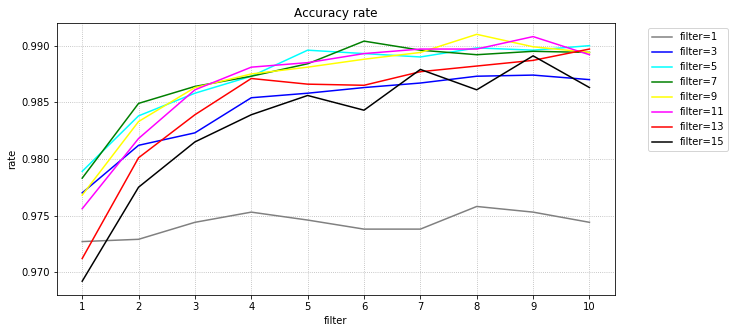
フィルタサイズは、5~11程度が良さそうです。小さいと特徴が捉えられないのか、大きいと畳み込み後のサイズが小さくなりすぎることが問題のようです。
フィルタ数は、2で、ただのニューラルネットワーク時の精度を大幅に上回りました。フィルタ数が8を超えるとおおむね99%前後になりました。
sameパディング
次に、パディングを追加してみましょう。元の画像サイズから減らないようにパディングを行います。元のサイズと同じになるようにパディングを行うことをsameパディングと呼ぶようです。
畳み込み後のサイズは、画像サイズ+パディングサイズ$ \times $2-フィルタサイズ+1 でした。元の画像サイズと同じにするためには、以下としました。
パディングサイズ$ \times $2-フィルタサイズ+1 = 0
パディングサイズ = (フィルタサイズ -1)/2
モデル
モデルは、パディングなしの場合と同じです。
学習
ハイパーパラメータもパディングなしの場合と同じです。
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
learn_info = {}
# フィルタ数、フィルタサイズ、パディングを変更しながら実行
for d in range(1,11):
for filter_size, padding in [[3,1],[5,2],[7,3],[9,4],[11,5],[13,6],[15,7]]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding)
print(name)
model = create_model((28,28,1))
model = add_layer(model, "conv1", convolution2d, d, filter_size=filter_size, padding=padding)
model = add_layer(model, "reluc1", relu)
model = add_layer(model, "pooling1", max_pooling2d)
model = add_layer(model, "flatten", flatten2d)
model = add_layer(model, "affine1", affine, 100)
model = add_layer(model, "relua1", relu)
model = add_layer(model, "affine2", affine, 50)
model = add_layer(model, "relua2", relu)
model = add_layer(model, "affine3", affine, 10)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
optimizer = create_optimizer(SGD)
epoch = 30
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch, optimizer=optimizer)
save_model(model, "cnn_model/model_"+name+".mdl")
こちらは、パディングなしの場合より時間がかかります。
結果
テストデータの正解率(%)の最大です。横がフィルタ数、縦がフィルタサイズです。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 97.87 | 98.23 | 98.43 | 98.45 | 98.66 | 98.55 | 98.60 | 98.74 | 98.65 | 98.69 |
| 5 | 97.94 | 98.50 | 98.47 | 98.85 | 98.86 | 98.92 | 98.86 | 99.01 | 98.98 | 98.82 |
| 7 | 97.81 | 98.50 | 98.78 | 98.93 | 98.88 | 98.96 | 99.04 | 99.09 | 99.10 | 98.95 |
| 9 | 98.08 | 98.50 | 98.69 | 98.85 | 98.96 | 99.07 | 99.02 | 99.06 | 99.04 | 99.07 |
| 11 | 97.95 | 98.64 | 98.73 | 98.96 | 99.03 | 98.90 | 98.94 | 98.93 | 99.12 | 99.12 |
| 13 | 98.19 | 98.71 | 98.78 | 98.88 | 98.97 | 98.82 | 99.04 | 98.97 | 98.98 | 98.95 |
| 15 | 98.01 | 98.70 | 98.66 | 98.83 | 98.96 | 98.96 | 99.04 | 99.04 | 99.03 | 99.00 |
グラフ化してみます。
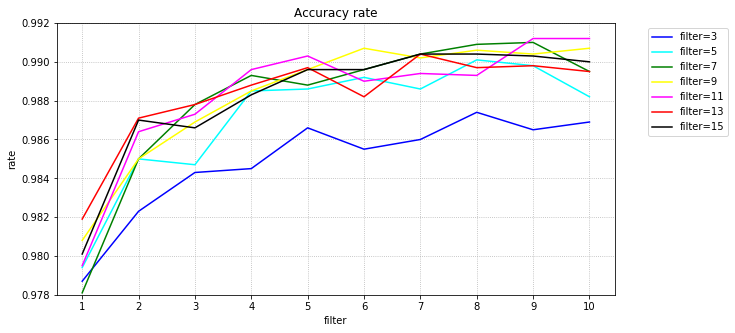
フィルタサイズが7以上であれば、そんなに差がありません。
重みの確認
学習後の重み(フィルタ)がどのように変化したか表示してみます。
パディングなし
フィルタ数10、フィルターサイズ3~15の場合です。
import matplotlib.pyplot as plt
d=10
for filter_size in range(3,16,2):
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(model["layer"]["conv1"]["weights"]["W"][i].reshape(filter_size,filter_size), 'gray')
plt.axis('off')
plt.show()
CNN d=10 filter_size=3
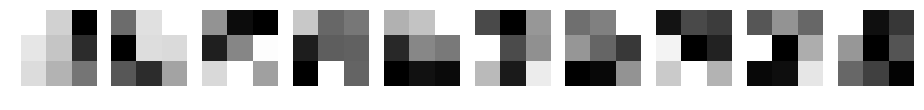
CNN d=10 filter_size=5
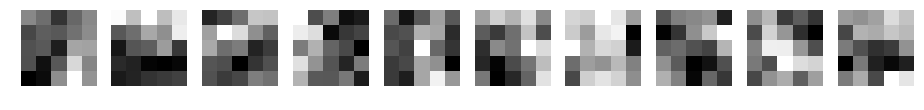
CNN d=10 filter_size=7
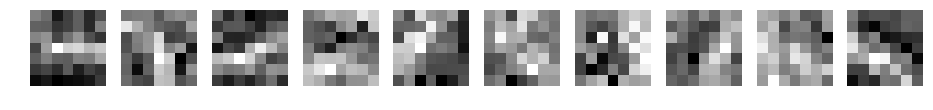
CNN d=10 filter_size=9
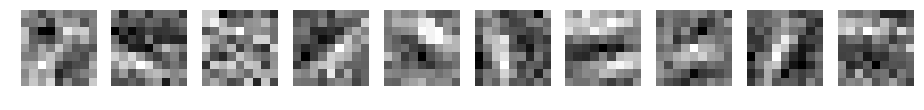
CNN d=10 filter_size=11
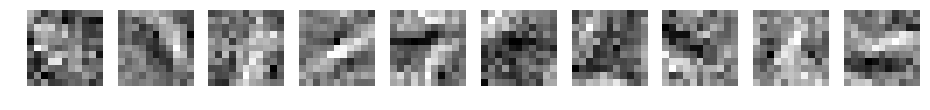
CNN d=10 filter_size=13
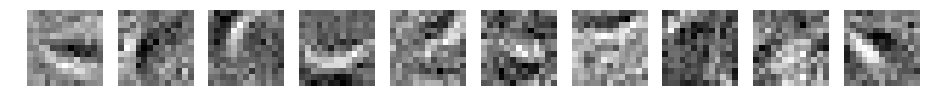
CNN d=10 filter_size=15
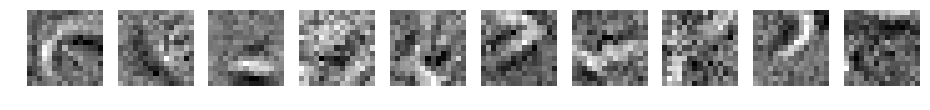
何か見えてきましたか?
sameパディング
sameパディングの場合です。
import matplotlib.pyplot as plt
d=10
for filter_size, padding in [[3,1],[5,2],[7,3],[9,4],[11,5],[13,6],[15,7]]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(model["layer"]["conv1"]["weights"]["W"][i].reshape(filter_size,filter_size), 'gray')
plt.axis('off')
plt.show()
CNN d=10 filter_size=3 padding=1
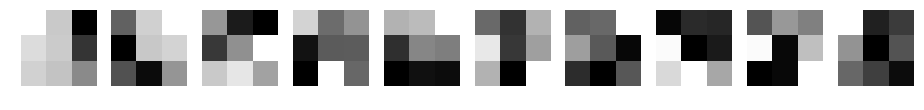
CNN d=10 filter_size=5 padding=2
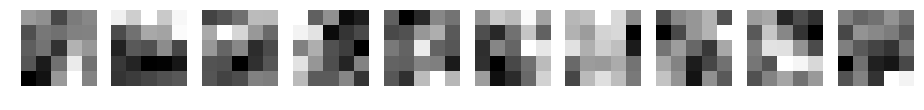
CNN d=10 filter_size=7 padding=3
CNN d=10 filter_size=9 padding=4
CNN d=10 filter_size=11 padding=5
CNN d=10 filter_size=13 padding=6
CNN d=10 filter_size=15 padding=7
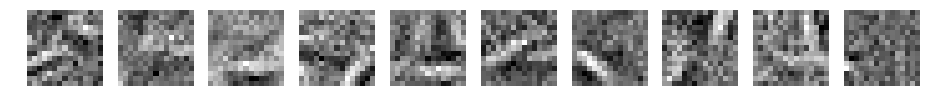
パディングなしの場合と同じような重みになりました。重みの初期値が同じため、同じような結果になったと考えます。
畳み込み後のデータ確認
次に畳み込み後のデータがどのように変化するか確認してみましょう。
テストデータの一番最初のデータで確認してみます。
元のデータは、以下です。
import matplotlib.pyplot as plt
plt.figure(figsize=(2, 4))
plt.imshow(x_test[0].reshape(28,28), 'gray')
plt.axis('off')
plt.show()

パディングなし
畳み込み後のデータを表示してみます。
d=10
for filter_size in range(1,16,2):
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
y_test, _, us = predict(model, nx_test[0:1], t_test[0:1])
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(us["conv1"]["z"][0,:,:,i], 'gray')
plt.axis('off')
plt.show()
CNN d=10 filter_size=1
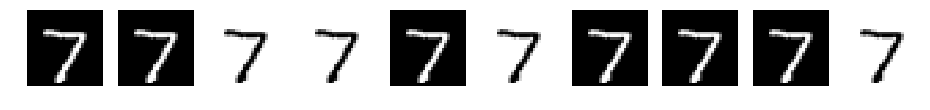
CNN d=10 filter_size=3
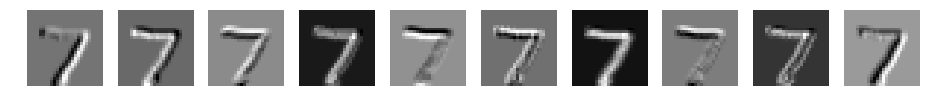
CNN d=10 filter_size=5
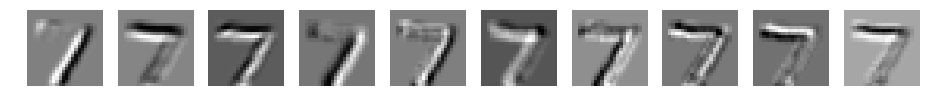
CNN d=10 filter_size=7
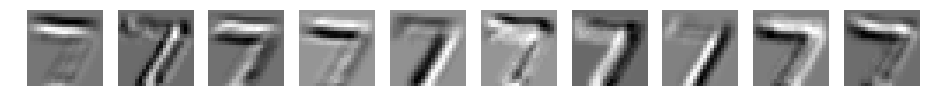
CNN d=10 filter_size=9

CNN d=10 filter_size=11
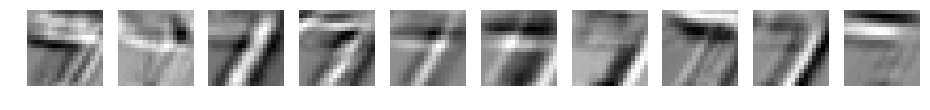
CNN d=10 filter_size=13
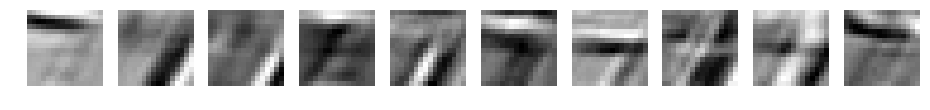
CNN d=10 filter_size=15
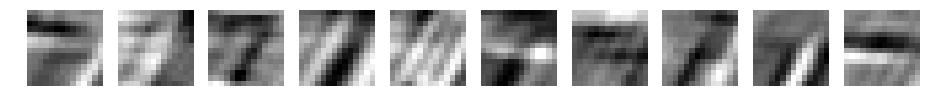
元データの7が浮き上がってきてますね。ただ、フィルタサイズが大きくなるごとにぼやけてきています。
色を0以上、以下で変更してみます。0以上が赤、0以下が青です。
d=10
for filter_size in range(1,16,2):
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
y_test, _, us = predict(model, nx_test[0:1], t_test[0:1])
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(us["conv1"]["z"][0,:,:,i], 'bwr' , vmin = -3, vmax = 3)
plt.axis('off')
plt.show()
CNN d=10 filter_size=1

CNN d=10 filter_size=3

CNN d=10 filter_size=5

CNN d=10 filter_size=7

CNN d=10 filter_size=9

CNN d=10 filter_size=11

CNN d=10 filter_size=13

CNN d=10 filter_size=15

畳み込み後について確認しましたが、その後の活性化関数(ReLU)の後、マックスプーリング後についても確認してみましょう。
d=10
for filter_size in range(1,16,2):
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
y_test, _, us = predict(model, nx_test[0:1], t_test[0:1])
# データの表示
for layer in ["conv1", "reluc1", "pooling1"]:
print(layer)
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(us[layer]["z"][0,:,:,i], 'gray')
plt.axis('off')
plt.show()
ここでは、fileter_size=7の場合を掲載します。
CNN d=10 filter_size=7
conv1
reluc1
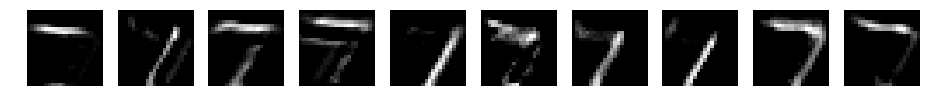
pooling1
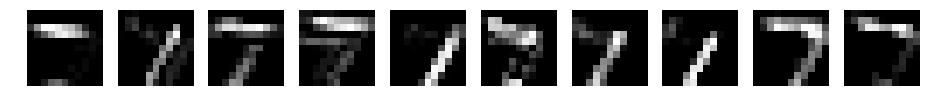
赤青で表示してみます。
d=10
for filter_size in range(1,16,2):
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
y_test, _, us = predict(model, nx_test[0:1], t_test[0:1])
# データの表示
for layer in ["conv1", "reluc1", "pooling1"]:
print(layer)
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(us[layer]["z"][0,:,:,i], 'bwr' , vmin = -3, vmax = 3)
plt.axis('off')
plt.show()
CNN d=10 filter_size=7
conv1
reluc1

pooling1
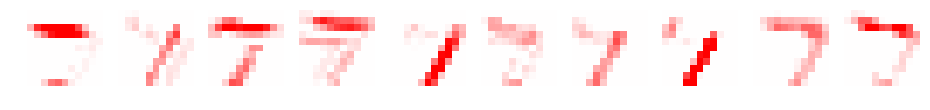
ReLUは、0以上をそのまま通す関数でした。ReLU後は、畳み込み後のデータの赤色の部分のみとなります。マックスプーリングで、解像度を半分にしたようなデータとなります。
フィルタによって、縦や横が強調されるようです。例えば、1番目、4番目、10番目は横が、2番目、5番目、8番目は、縦が強調されているように見えます。
ちなみに2番目のデータについても確認してみました。

CNN d=10 filter_size=7
conv1

reluc1

pooling1

やはり、フィルタによって強調される部分が異なります。
sameパディング
sameパディングについても同様に確認してみます。
d=10
for filter_size, padding in [[3,1],[5,2],[7,3],[9,4],[11,5],[13,6],[15,7]]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
y_test, _, us = predict(model, nx_test[0:1], t_test[0:1])
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(us["conv1"]["z"][0,:,:,i], 'gray')
plt.axis('off')
plt.show()
CNN d=10 filter_size=3 padding=1
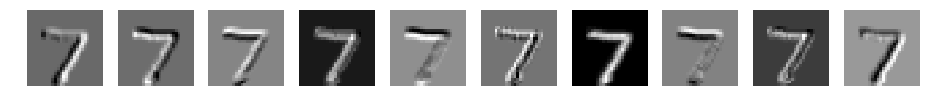
CNN d=10 filter_size=5 padding=2
CNN d=10 filter_size=7 padding=3
CNN d=10 filter_size=9 padding=4
CNN d=10 filter_size=11 padding=5

CNN d=10 filter_size=13 padding=6

CNN d=10 filter_size=15 padding=7

パディングなしの場合と同様に、フィルタサイズが大きくなるごとに、ぼやけたイメージとなりました。
赤青表示です。
d=10
for filter_size, padding in [[3,1],[5,2],[7,3],[9,4],[11,5],[13,6],[15,7]]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
y_test, _, us = predict(model, nx_test[0:1], t_test[0:1])
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(us["conv1"]["z"][0,:,:,i], 'bwr' , vmin = -3, vmax = 3)
plt.axis('off')
plt.show()
CNN d=10 filter_size=3 padding=1

CNN d=10 filter_size=5 padding=2

CNN d=10 filter_size=7 padding=3

CNN d=10 filter_size=9 padding=4

CNN d=10 filter_size=11 padding=5

CNN d=10 filter_size=13 padding=6

CNN d=10 filter_size=15 padding=7

活性化関数(ReLU)後、畳み込み後のデータも確認します。
d=10
for filter_size, padding in [[3,1],[5,2],[7,3],[9,4],[11,5],[13,6],[15,7]]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
y_test, _, us = predict(model, nx_test[0:1], t_test[0:1])
# データの表示
for layer in ["conv1", "reluc1", "pooling1"]:
print(layer)
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(us[layer]["z"][0,:,:,i], 'gray')
plt.axis('off')
plt.show()
CNN d=10 filter_size=7 padding=3
conv1
reluc1
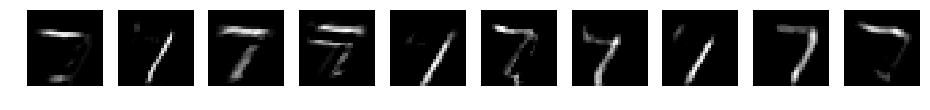
pooling1
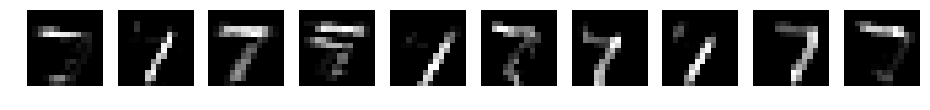
赤青表示です。
d=10
for filter_size, padding in [[3,1],[5,2],[7,3],[9,4],[11,5],[13,6],[15,7]]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding)
print(name)
model = load_model("cnn_model/model_"+name+".mdl")
y_test, _, us = predict(model, nx_test[0:1], t_test[0:1])
# データの表示
for layer in ["conv1", "reluc1", "pooling1"]:
print(layer)
plt.figure(figsize=(16, 8))
for i in range(d):
plt.subplot(1, d, i+1)
plt.imshow(us["conv1"]["z"][0,:,:,i], 'bwr' , vmin = -3, vmax = 3)
plt.axis('off')
plt.show()
CNN d=10 filter_size=7 padding=3
conv1
reluc1

pooling1
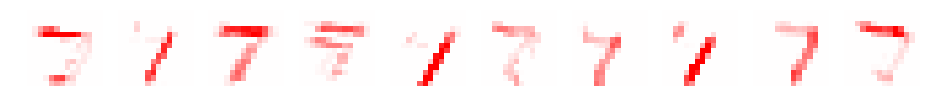
やはり、フィルタごとにいろいろなパーツが強調されているように見えます。
畳み込み層
畳み込みのパラメータを変更して確認します。
フィルタ数
フィルタ数は、10まで確認しましたが、もっとフィルタ数を増やすと精度が向上するか試してみます。時間がかかるので、フィルタ数20まで、フィルタサイズは7の場合について確認します。
パディングなし
以下のハイパーパラメータで実行します。
フィルタサイズ: 7
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
for d in range(1,21):
for filter_size in [7]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size)
print(name)
model = create_model((28,28,1))
model = add_layer(model, "conv1", convolution2d, d, filter_size=filter_size)
model = add_layer(model, "reluc1", relu)
model = add_layer(model, "pooling1", max_pooling2d)
model = add_layer(model, "flatten", flatten2d)
model = add_layer(model, "affine1", affine, 100)
model = add_layer(model, "relua1", relu)
model = add_layer(model, "affine2", affine, 50)
model = add_layer(model, "relua2", relu)
model = add_layer(model, "affine3", affine, 10)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
epoch = 30
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
save_model(model, "cnn_model/model_"+name+".mdl")
テストデータの正解率(%)、入力データ、畳み込み後、マックスプーリング後、flatten後のそれぞれの型、所要時間を表にします。
テストデータの正解率は、30エポック後および30エポック中の最大の正解率を表示しています。所要時間は、他にプログラムが動いている状態で確認したため参考値として見てください。
フィルタ数が20までの結果を表にします。
| フィルタ数 | 正解率 | 最大 | input | conv1 | pooling1 | flatten | 所要時間 |
|---|---|---|---|---|---|---|---|
| 1 | 97.76 | 97.83 | (28, 28, 1) | (22, 22, 1) | (11, 11, 1) | 121 | 20 分 11 秒 |
| 2 | 98.40 | 98.49 | (28, 28, 1) | (22, 22, 2) | (11, 11, 2) | 242 | 26 分 54 秒 |
| 3 | 98.53 | 98.64 | (28, 28, 1) | (22, 22, 3) | (11, 11, 3) | 363 | 28 分 54 秒 |
| 4 | 98.65 | 98.73 | (28, 28, 1) | (22, 22, 4) | (11, 11, 4) | 484 | 31 分 24 秒 |
| 5 | 98.76 | 98.84 | (28, 28, 1) | (22, 22, 5) | (11, 11, 5) | 605 | 35 分 23 秒 |
| 6 | 99.01 | 99.04 | (28, 28, 1) | (22, 22, 6) | (11, 11, 6) | 726 | 38 分 19 秒 |
| 7 | 98.96 | 98.96 | (28, 28, 1) | (22, 22, 7) | (11, 11, 7) | 847 | 41 分 58 秒 |
| 8 | 98.92 | 98.92 | (28, 28, 1) | (22, 22, 8) | (11, 11, 8) | 968 | 43 分 41 秒 |
| 9 | 98.95 | 98.95 | (28, 28, 1) | (22, 22, 9) | (11, 11, 9) | 1089 | 48 分 17 秒 |
| 10 | 98.93 | 98.94 | (28, 28, 1) | (22, 22, 10) | (11, 11, 10) | 1210 | 51 分 56 秒 |
| 11 | 99.00 | 99.05 | (28, 28, 1) | (22, 22, 11) | (11, 11, 11) | 1331 | 56 分 8 秒 |
| 12 | 99.01 | 99.06 | (28, 28, 1) | (22, 22, 12) | (11, 11, 12) | 1452 | 57 分 45 秒 |
| 13 | 99.13 | 99.17 | (28, 28, 1) | (22, 22, 13) | (11, 11, 13) | 1573 | 61 分 25 秒 |
| 14 | 98.95 | 99.04 | (28, 28, 1) | (22, 22, 14) | (11, 11, 14) | 1694 | 64 分 11 秒 |
| 15 | 98.94 | 99.08 | (28, 28, 1) | (22, 22, 15) | (11, 11, 15) | 1815 | 67 分 50 秒 |
| 16 | 99.10 | 99.18 | (28, 28, 1) | (22, 22, 16) | (11, 11, 16) | 1936 | 69 分 11 秒 |
| 17 | 99.17 | 99.18 | (28, 28, 1) | (22, 22, 17) | (11, 11, 17) | 2057 | 77 分 11 秒 |
| 18 | 99.11 | 99.14 | (28, 28, 1) | (22, 22, 18) | (11, 11, 18) | 2178 | 79 分 51 秒 |
| 19 | 99.11 | 99.11 | (28, 28, 1) | (22, 22, 19) | (11, 11, 19) | 2299 | 83 分 37 秒 |
| 20 | 99.07 | 99.11 | (28, 28, 1) | (22, 22, 20) | (11, 11, 20) | 2420 | 85 分 23 秒 |
正解率の最大をグラフ化します。
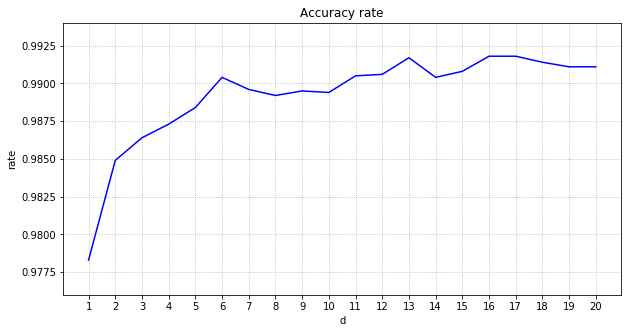
11エポック以降は、テスト正解率は、すべて99%を超えました。ただ、20以上フィルタ数を増やしてもあまり精度の向上は見込めないようです。
所要時間は、フィルタ数に比例して増えていきます。
sameパディング
以下のハイパーパラメータで実行します。
フィルタサイズ: 7
パディング: 3
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
for d in range(1,21):
for filter_size, padding in [[7,3]]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding)
print(name)
model = create_model((28,28,1))
model = add_layer(model, "conv1", convolution2d, d, filter_size=filter_size, padding=padding)
model = add_layer(model, "reluc1", relu)
model = add_layer(model, "pooling1", max_pooling2d)
model = add_layer(model, "flatten", flatten2d)
model = add_layer(model, "affine1", affine, 100)
model = add_layer(model, "relua1", relu)
model = add_layer(model, "affine2", affine, 50)
model = add_layer(model, "relua2", relu)
model = add_layer(model, "affine3", affine, 10)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
epoch = 30
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
save_model(model, "cnn_model/model_"+name+".mdl")
パディングなしの場合と同様に、フィルタ数20までを表にします。
| フィルタ数 | 正解率 | 最大 | input | conv1 | pooling1 | flatten | 所要時間 |
|---|---|---|---|---|---|---|---|
| 1 | 97.77 | 97.81 | (28, 28, 1) | (28, 28, 1) | (14, 14, 1) | 196 | 31 分 24 秒 |
| 2 | 98.20 | 98.50 | (28, 28, 1) | (28, 28, 2) | (14, 14, 2) | 392 | 41 分 27 秒 |
| 3 | 98.74 | 98.78 | (28, 28, 1) | (28, 28, 3) | (14, 14, 3) | 588 | 46 分 9 秒 |
| 4 | 98.93 | 98.93 | (28, 28, 1) | (28, 28, 4) | (14, 14, 4) | 784 | 49 分 43 秒 |
| 5 | 98.80 | 98.88 | (28, 28, 1) | (28, 28, 5) | (14, 14, 5) | 980 | 55 分 56 秒 |
| 6 | 98.94 | 98.96 | (28, 28, 1) | (28, 28, 6) | (14, 14, 6) | 1176 | 59 分 49 秒 |
| 7 | 98.97 | 99.04 | (28, 28, 1) | (28, 28, 7) | (14, 14, 7) | 1372 | 66 分 21 秒 |
| 8 | 99.05 | 99.09 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 68 分 8 秒 |
| 9 | 99.05 | 99.10 | (28, 28, 1) | (28, 28, 9) | (14, 14, 9) | 1764 | 74 分 45 秒 |
| 10 | 98.94 | 98.95 | (28, 28, 1) | (28, 28, 10) | (14, 14, 10) | 1960 | 82 分 5 秒 |
| 11 | 98.98 | 99.08 | (28, 28, 1) | (28, 28, 11) | (14, 14, 11) | 2156 | 88 分 31 秒 |
| 12 | 98.90 | 99.01 | (28, 28, 1) | (28, 28, 12) | (14, 14, 12) | 2352 | 92 分 59 秒 |
| 13 | 98.95 | 99.02 | (28, 28, 1) | (28, 28, 13) | (14, 14, 13) | 2548 | 98 分 15 秒 |
| 14 | 99.12 | 99.17 | (28, 28, 1) | (28, 28, 14) | (14, 14, 14) | 2744 | 102 分 39 秒 |
| 15 | 99.08 | 99.12 | (28, 28, 1) | (28, 28, 15) | (14, 14, 15) | 2940 | 107 分 45 秒 |
| 16 | 99.01 | 99.05 | (28, 28, 1) | (28, 28, 16) | (14, 14, 16) | 3136 | 110 分 17 秒 |
| 17 | 98.98 | 99.07 | (28, 28, 1) | (28, 28, 17) | (14, 14, 17) | 3332 | 122 分 48 秒 |
| 18 | 99.06 | 99.10 | (28, 28, 1) | (28, 28, 18) | (14, 14, 18) | 3528 | 126 分 29 秒 |
| 19 | 99.02 | 99.09 | (28, 28, 1) | (28, 28, 19) | (14, 14, 19) | 3724 | 133 分 28 秒 |
| 20 | 99.04 | 99.12 | (28, 28, 1) | (28, 28, 20) | (14, 14, 20) | 3920 | 133 分 5 秒 |
正解率の最大をグラフ化します。
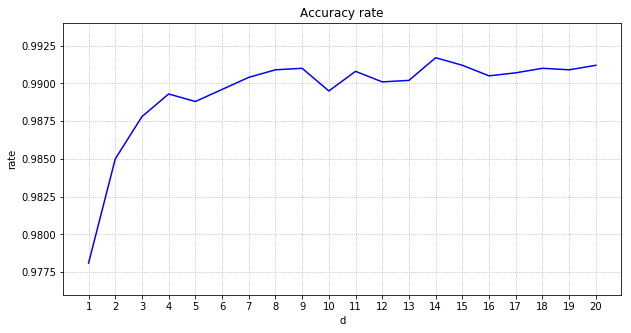
パディングなしの場合と同様に、11エポック以降は、テスト正解率は、すべて99%を超えました。
パディングを行う分だけ時間がかかります。
参考までに、フィルタ数20の場合の重さと、データを表示してみます。
CNN d=20 filter_size=7 padding=3
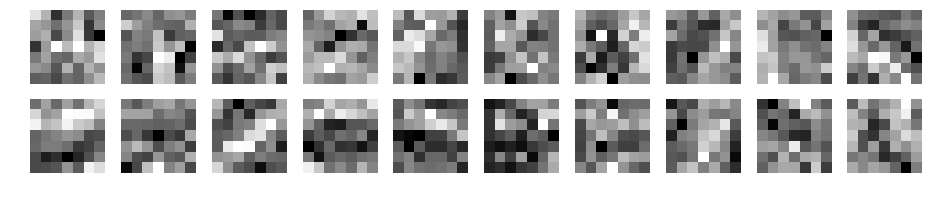
conv1

reluc1

pooling1

参考(affineのみ)
参考までに、affine変換の場合と比較します。CNNのフィルタ数ごとと同じノード数で試してみます。
for d in [196,392,588,784,980,1176,1372,1568,1764,1960,2156,2352,2548,2744,2940,3136,3332,3528,3724,3920]:
name = "CNN d=" + str(d) + " affine only"
print(name)
model = create_model((28*28))
model = add_layer(model, "affine0", affine, d)
model = add_layer(model, "relua0", relu)
model = add_layer(model, "affine1", affine, 100)
model = add_layer(model, "relua1", relu)
model = add_layer(model, "affine2", affine, 50)
model = add_layer(model, "relua2", relu)
model = add_layer(model, "affine3", affine, 10)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
epoch = 30
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
save_model(model, "cnn_model/model_"+name+".mdl")
| ノード数 | 正解率 | 最大 |
|---|---|---|
| 196 | 98.10 | 98.13 |
| 392 | 98.16 | 98.21 |
| 588 | 98.40 | 98.40 |
| 784 | 98.09 | 98.17 |
| 980 | 98.09 | 98.12 |
| 1176 | 98.16 | 98.19 |
| 1372 | 98.17 | 98.21 |
| 1568 | 98.26 | 98.28 |
| 1764 | 98.18 | 98.23 |
| 1960 | 98.25 | 98.28 |
| 2156 | 98.24 | 98.27 |
| 2352 | 98.09 | 98.15 |
| 2548 | 98.20 | 98.24 |
| 2744 | 98.42 | 98.43 |
| 2940 | 98.12 | 98.14 |
| 3136 | 98.21 | 98.28 |
| 3332 | 98.30 | 98.30 |
| 3528 | 98.29 | 98.30 |
| 3724 | 98.17 | 98.18 |
| 3920 | 98.21 | 98.30 |
少し精度は向上しましたが、やはり、CNNには遠くおよびませんでした。CNNのフィルタ数を増やした時と同様に、ノード数を増やしても一定以上精度は向上しませんでした。
フィルタサイズ
フィルタサイズは、15まで変更して確認していましたが、27まで増やして確認します。確認時のフィルタ数は、16程度がよいのですが、時間がかかるため、今回は、フィルタ数は8にしました。
パディングなし
以下のハイパーパラメータで実行します。
フィルタ数: 8
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。
| フィルタサイズ | 正解率 | 最大 | input | conv1 | pooling1 | flatten | 所要時間 |
|---|---|---|---|---|---|---|---|
| 1 | 97.11 | 97.58 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 49 分 41 秒 |
| 3 | 98.69 | 98.73 | (28, 28, 1) | (26, 26, 8) | (13, 13, 8) | 1352 | 49 分 36 秒 |
| 5 | 98.96 | 98.98 | (28, 28, 1) | (24, 24, 8) | (12, 12, 8) | 1152 | 45 分 17 秒 |
| 7 | 98.92 | 98.92 | (28, 28, 1) | (22, 22, 8) | (11, 11, 8) | 968 | 43 分 41 秒 |
| 9 | 99.02 | 99.10 | (28, 28, 1) | (20, 20, 8) | (10, 10, 8) | 800 | 42 分 50 秒 |
| 11 | 98.94 | 98.97 | (28, 28, 1) | (18, 18, 8) | ( 9, 9, 8) | 648 | 36 分 41 秒 |
| 13 | 98.82 | 98.82 | (28, 28, 1) | (16, 16, 8) | ( 8, 8, 8) | 512 | 31 分 49 秒 |
| 15 | 98.58 | 98.61 | (28, 28, 1) | (14, 14, 8) | ( 7, 7, 8) | 392 | 26 分 18 秒 |
| 17 | 98.45 | 98.46 | (28, 28, 1) | (12, 12, 8) | ( 6, 6, 8) | 288 | 24 分 46 秒 |
| 19 | 98.12 | 98.22 | (28, 28, 1) | (10, 10, 8) | ( 5, 5, 8) | 200 | 18 分 13 秒 |
| 21 | 98.13 | 98.13 | (28, 28, 1) | ( 8, 8, 8) | ( 4, 4, 8) | 128 | 13 分 30 秒 |
| 23 | 97.44 | 97.80 | (28, 28, 1) | ( 6, 6, 8) | ( 3, 3, 8) | 72 | 9 分 30 秒 |
| 25 | 96.85 | 97.03 | (28, 28, 1) | ( 4, 4, 8) | ( 2, 2, 8) | 32 | 4 分 59 秒 |
| 27 | 94.21 | 95.41 | (28, 28, 1) | ( 2, 2, 8) | ( 1, 1, 8) | 8 | 2 分 6 秒 |
フィルタサイズが増えるごとに、畳み込み後のサイズが小さくなり、所要時間が短くなります。精度もフィルタサイズが大きすぎると悪くなります。
sameパディング
以下のハイパーパラメータで実行します。
フィルタ数: 8
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。
| フィルタサイズ | パディング | 正解率 | 最大 | input | conv1 | pooling1 | flatten | 所要時間 |
|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 98.71 | 98.74 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 56 分 13 秒 |
| 5 | 2 | 98.98 | 99.01 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 62 分 26 秒 |
| 7 | 3 | 99.05 | 99.09 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 68 分 8 秒 |
| 9 | 4 | 99.02 | 99.06 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 78 分 57 秒 |
| 11 | 5 | 98.85 | 98.93 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 83 分 44 秒 |
| 13 | 6 | 98.91 | 98.97 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 90 分 42 秒 |
| 15 | 7 | 98.95 | 99.04 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 99 分 8 秒 |
| 17 | 8 | 98.94 | 98.99 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 126 分 16 秒 |
| 19 | 9 | 99.01 | 99.06 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 140 分 11 秒 |
| 21 | 10 | 98.83 | 98.90 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 154 分 27 秒 |
| 23 | 11 | 98.94 | 98.94 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 164 分 48 秒 |
| 25 | 12 | 98.82 | 98.91 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 176 分 37 秒 |
| 27 | 13 | 98.98 | 99.01 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 | 198 分 13 秒 |
フィルタサイズを増やせば、大幅に時間がかかります。精度は、フィルタサイズを増やしてもほぼ同等です。精度が同等であれば、時間がかからない方がよいですよね。
フィルタサイズ27の場合の重さ、データを確認してみましょう。
CNN d=8 filter_size=27 padding=13

conv1

reluc1

pooling1
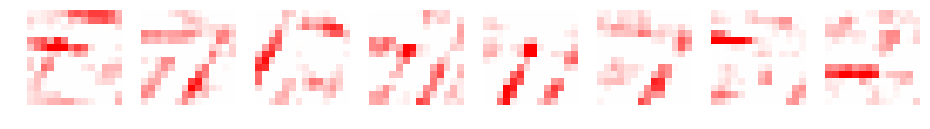
もう、もとの画像のイメージは消えているようにも思えますが、うっすら残っているようにも見えます。
2つめのデータも確認してみます。
conv1

reluc1

pooling1
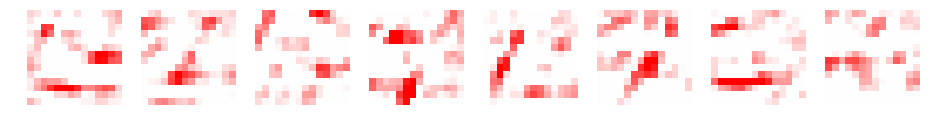
パディング
パディングのサイズを増やしてみましょう。フィルタサイズが7の場合です。
フィルタ数: 8
フィルタサイズ: 7
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。
| パディング | 正解率 | 最大 | input | conv1 | pooling1 | flatten |
|---|---|---|---|---|---|---|
| 0 | 98.92 | 98.92 | (28, 28, 1) | (22, 22, 8) | (11, 11, 8) | 968 |
| 1 | 98.99 | 99.03 | (28, 28, 1) | (24, 24, 8) | (12, 12, 8) | 1152 |
| 2 | 99.08 | 99.08 | (28, 28, 1) | (26, 26, 8) | (13, 13, 8) | 1352 |
| 3 | 99.05 | 99.09 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 |
| 4 | 99.08 | 99.16 | (28, 28, 1) | (30, 30, 8) | (15, 15, 8) | 1800 |
| 5 | 98.85 | 98.99 | (28, 28, 1) | (32, 32, 8) | (16, 16, 8) | 2048 |
| 6 | 98.93 | 98.94 | (28, 28, 1) | (34, 34, 8) | (17, 17, 8) | 2312 |
パディングを増やした場合もほぼ同等でした。パディングを増やすと時間もかかるので、増やすのであれば、sameパディングでよさそうです。
ストライド
ストライドは、基本1でした。ストライドを変えてみましょう。
フィルタ数: 8
フィルタサイズ: 7
パディング: 3
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。
| ストライド | 正解率 | 最大 | input | conv1 | pooling1 | flatten |
|---|---|---|---|---|---|---|
| 1 | 99.05 | 99.09 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 |
| 2 | 98.84 | 98.84 | (28, 28, 1) | (14, 14, 8) | ( 7, 7, 8) | 392 |
| 3 | 98.16 | 98.40 | (28, 28, 1) | (10, 10, 8) | ( 5, 5, 8) | 200 |
| 4 | 96.86 | 97.19 | (28, 28, 1) | ( 7, 7, 8) | ( 3, 3, 8) | 72 |
ストライドは、大きくすると精度が悪くなりました。ストラドは、基本1ですね。
畳み込み層のみ
マックスプーリングなしで畳み込み層の場合についても確認します。
フィルタ数: 8
フィルタサイズ: 7
パディング: 3
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
| 正解率 | 最大 | input | conv1 | flatten |
|---|---|---|---|---|
| 98.86 | 98.89 | (28, 28, 1) | (28, 28, 8) | 6272 |
プーリングを行わないと全結合へのノードが大きくなりすぎますね。
プーリング層(マックスプーリング)
プーリング層もハイパーパラメータを変更して試してみます。プーリングは、マックスプーリングです。
プールサイズ
プールサイズは、一般的に2が用いられるようですが、プールサイズを大きくしてみます。
フィルタ数: 8
フィルタサイズ: 7
パディング: 3
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。
| プールサイズ | 正解率 | 最大 | input | conv1 | pooling1 | flatten |
|---|---|---|---|---|---|---|
| 1 | 98.86 | 98.89 | (28, 28, 1) | (28, 28, 8) | (28, 28, 8) | 6272 |
| 2 | 99.05 | 99.09 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 |
| 3 | 99.06 | 99.06 | (28, 28, 1) | (28, 28, 8) | ( 9, 9, 8) | 648 |
| 4 | 99 04 | 99.09 | (28, 28, 1) | (28, 28, 8) | ( 7, 7, 8) | 392 |
| 5 | 98.88 | 98.95 | (28, 28, 1) | (28, 28, 8) | ( 5, 5, 8) | 200 |
| 6 | 98.67 | 98.80 | (28, 28, 1) | (28, 28, 8) | ( 4, 4, 8) | 128 |
| 7 | 98.93 | 99.01 | (28, 28, 1) | (28, 28, 8) | ( 4, 4, 8) | 128 |
プールサイズは、大きくしても精度はほとんど変化ありませんでした。
プールサイズ7の場合の重さ、データを確認してみましょう。
CNN d=8 filter_size=7 padding=3 pool_size=7
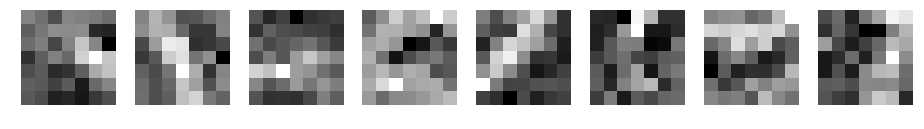
conv1

reluc1

pooling1

プーリング後のデータは、かなり雑なデータとなりました。これだけデータを縮小しても精度がでるのは、マックスプーリングの威力ですね。
ただ、MNISTが数字で単純だからですかね。
パディング
パディングを1として実行してみます。
フィルタ数: 8
フィルタサイズ: 7
パディング: 3
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。
| プールサイズ | パディング | 正解率 | 最大 | input | conv1 | pooling1 | flatten |
|---|---|---|---|---|---|---|---|
| 2 | - | 99.05 | 99.09 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 |
| 2 | 1 | 99.09 | 99.15 | (28, 28, 1) | (28, 28, 8) | (15, 15, 8) | 1800 |
たまたまかもしれませんが、良い値になりました。
ストライド
マックスプーリングのストライドを1~7まで変更してみます。
フィルタ数: 8
フィルタサイズ: 7
パディング: 3
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。
| ストライド | 正解率 | 最大 | input | conv1 | pooling1 | flatten |
|---|---|---|---|---|---|---|
| 1 | 99.05 | 99.05 | (28, 28, 1) | (28, 28, 8) | (27, 27, 8) | 5832 |
| 2 | 99.05 | 99.09 | (28, 28, 1) | (28, 28, 8) | (14, 14, 8) | 1568 |
| 3 | 98.99 | 99.01 | (28, 28, 1) | (28, 28, 8) | ( 9, 9, 8) | 648 |
| 4 | 98.74 | 98.79 | (28, 28, 1) | (28, 28, 8) | ( 7, 7, 8) | 392 |
| 5 | 98.57 | 98.50 | (28, 28, 1) | (28, 28, 8) | ( 6, 6, 8) | 288 |
| 6 | 98.10 | 98.27 | (28, 28, 1) | (28, 28, 8) | ( 5, 5, 8) | 200 |
| 7 | 98.04 | 98.04 | (28, 28, 1) | (28, 28, 8) | ( 4, 4, 8) | 128 |
プールサイズと同じ2とした方がよさそうです。
プーリング層(マックスプーリング)のみ
畳み込みを行わないで、マックスプーリングのみ行ってみます。
| 正解率 | 最大 | input | pooling1 | flatten |
|---|---|---|---|---|
| 97.48 | 97.52 | (28, 28, 1) | (14, 14, 1) | 196 |
精度がでませんね。
全結合層
ノード数
全結合層は、100-50で実行しました。ノード数を増やして試してみます。
参考までに、中間層がない場合も試します。
全結合層以外のハイパーパラメータは、以下です。
フィルタ数: 8
フィルタサイズ: 7
パディング: 3
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
| 中間層1 | 中間層2 | 正解率 | 最大 |
|---|---|---|---|
| なし | なし | 98.62 | 98.81 |
| 100 | 50 | 99.05 | 99.09 |
| 500 | 250 | 99.02 | 99.07 |
| 1000 | 500 | 99.13 | 99.13 |
中間層のノード数を増やすと若干精度が良くなりました。全結合層のノード数も調整する必要がありそうです。
dropout
全結合層にdropoutを適用してみます。
d = 8
filter_size = 7
pool_padding = 3
for dropout_ratio in [0.9,0.8,0.7,0.6,0.5]:
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding) + " dropout_ratio=" + str(dropout_ratio)
print(name)
model = create_model((28,28,1))
model = add_layer(model, "conv1", convolution2d, d, filter_size=filter_size, padding=padding)
model = add_layer(model, "reluc1", relu)
model = add_layer(model, "pooling1", max_pooling2d)
model = add_layer(model, "flatten", flatten2d)
model = add_layer(model, "dropouta1", dropout, dropout_ratio=dropout_ratio)
model = add_layer(model, "affine1", affine, 100)
model = add_layer(model, "relua1", relu)
model = add_layer(model, "dropouta2", dropout, dropout_ratio=dropout_ratio)
model = add_layer(model, "affine2", affine, 50)
model = add_layer(model, "relua2", relu)
model = add_layer(model, "dropouta3", dropout, dropout_ratio=dropout_ratio)
model = add_layer(model, "affine3", affine, 10)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
epoch = 30
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
save_model(model, "cnn_model/model_"+name+".mdl")
結果です。
| ドロップアウト率 | 正解率 | 最大 |
|---|---|---|
| なし | 99.05 | 99.09 |
| 0.9 | 99.09 | 99.18 |
| 0.8 | 99.06 | 99.14 |
| 0.7 | 99.11 | 99.11 |
| 0.6 | 98.85 | 98.96 |
| 0.5 | 98.58 | 98.61 |
ドロップアウト率が、0.9~0.7の場合、若干精度が向上しましたが、誤差範囲ですかね。
活性化関数
畳み込み後の活性化関数を変更してみます。
nx_train = nx_train.reshape((nx_train.shape[0], 28, 28, 1))
nx_test = nx_test.reshape((nx_test.shape[0], 28, 28, 1))
d = 8
filter_size = 7
padding = 3
for func in [sigmoid, tanh, softplus, softsign]
name = "CNN d=" + str(d) + " filter_size=" + str(filter_size) + " padding=" + str(padding) + " " + func.__name__
print(name)
model = create_model((28,28,1))
model = add_layer(model, "conv1", convolution2d, d, filter_size=filter_size, padding=padding)
model = add_layer(model, func.__name__, func)
model = add_layer(model, "pooling1", max_pooling2d)
model = add_layer(model, "flatten", flatten2d)
model = add_layer(model, "affine1", affine, 100)
model = add_layer(model, "relua1", relu)
model = add_layer(model, "affine2", affine, 50)
model = add_layer(model, "relua2", relu)
model = add_layer(model, "affine3", affine, 10)
model = set_output(model, softmax)
model = set_error(model, cross_entropy_error)
epoch = 30
batch_size = 100
np.random.seed(10)
model, optimizer, learn_info[name] = learn(model, nx_train, t_train, nx_test, t_test, batch_size=batch_size, epoch=epoch)
save_model(model, "cnn_model/model_"+name+".mdl")
結果です。
| 活性化関数 | 正解率 | 最大 |
|---|---|---|
| なし | 98.59 | 98.64 |
| relu | 99.05 | 99.09 |
| sigmoid | 98.70 | 98.81 |
| tanh | 98.71 | 98.76 |
| softplus | 98.67 | 98.82 |
| softsign | 98.84 | 98.84 |
活性化関数がないと精度が出ませんでした。また、ReLUが一番よかったです。
参考までに、sigmoidの重みとデータです。
CNN d=8 filter_size=7 padding=3 sigmoid
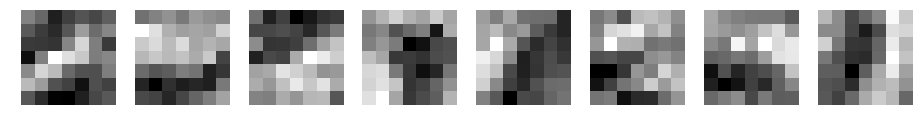
conv1

sigmoid

pooling1
sigmoidの特徴が出ていますね。
sigmoidは、0~1のため、sigmoid、pooling1は、-1~1に変更しています。
plt.imshow(us[layer]["z"][j,:,:,i], 'bwr' , vmin = -1, vmax = 1)
平均プーリング
最後に平均プーリングも試してみます。
パディングなし
以下のハイパーパラメータで実行してみます。
フィルタ数 : 8
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。比較のためマックスプーリングの結果も載せます。
| フィルタサイズ | 平均 正解率 | 平均 最大 | max 正解率 | max 最大 |
|---|---|---|---|---|
| 1 | 97.91 | 97.97 | 97.11 | 97.58 |
| 3 | 98.58 | 98.58 | 98.69 | 98.73 |
| 5 | 98.61 | 98.72 | 98.96 | 98.98 |
| 7 | 98.77 | 98.93 | 98.92 | 98.92 |
| 9 | 98.90 | 98.97 | 99.02 | 99.10 |
| 11 | 98.90 | 98.90 | 98.94 | 98.97 |
| 13 | 98.71 | 98.71 | 98.82 | 98.82 |
| 15 | 98.40 | 98.51 | 98.58 | 98.61 |
マックスプーリングの方が少し良さそうです。
sameパディング
フィルタ数: 8
バッチサイズ : 100
エポック数 : 30
勾配法 : SGD
学習係数 : 0.1(SGDの既定値)
結果です。比較のためマックスプーリングの結果も載せます。
| フィルタサイズ | パディング | 平均 正解率 | 平均 最大 | max 正解率 | max 最大 |
|---|---|---|---|---|---|
| 3 | 1 | 98.34 | 98.44 | 98.71 | 98.74 |
| 5 | 2 | 98.86 | 98.89 | 98.98 | 99.01 |
| 7 | 3 | 98.93 | 99.02 | 99.05 | 99.09 |
| 9 | 4 | 98.95 | 98.95 | 99.02 | 99.06 |
| 11 | 5 | 98.88 | 98.90 | 98.85 | 98.93 |
| 13 | 6 | 98.80 | 98.88 | 98.91 | 98.97 |
| 15 | 7 | 98.85 | 98.87 | 98.95 | 99.04 |
やはり、マックスプーリングの方が良さそうです。
参考までに、重さとデータです。
CNN d=8 filter_size=7 padding=3 average_pooling
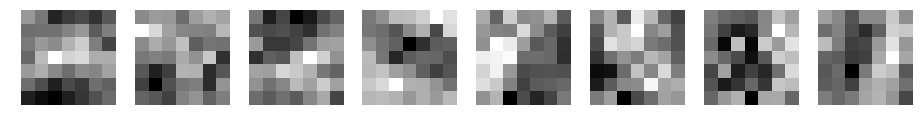
conv1

reluc1

pooling1

CNNの一層の場合について、いろいろ試してみました。ハイパーパラメータの調整は、各種必要です。しかし、1度の実行に時間がかかるため大変そうです。
また、重さやデータを表示し確認しました。なかなか興味深い結果となりました。