こんにちは。シーシャを吸いながら初稿を書いています。もくもくです。
Qiitaへの投稿はおよそ3ヶ月ぶりです。ご無沙汰しています。
あらすじ
茶太さんご存知でしょうか。まったりと同人歌手として活動しているのですが、「だんご大家族」を歌っていたので名前は知らなくても聴いたことがある人もいるかもしれません。
知人が茶太さんの楽曲データベースを作っていて、そのデータをいただくことができたのでpandasを使って分析してみたいと思います。
今回やること
分析といえるほどのものではないですが、茶太さんの曲が収録されたCDを発売年月で集計します。Seabornのcountplotを使ったシンプルな方法と年月ごとに集計してからbarplotで出力する少し遠回りな方法の2つでやってみます。
データセットについて
CD単位でまとめられたデータを使用します。
"CD名","サークル名1","サークル名2","発売年月日","メジャーレーベルフラグ","備考"からなり、csv形式で保存しています。
環境
Ubuntu 16.04
Python 3.5.2 :: Anaconda custom (64-bit)
では始まります。
#coding:utf-8
import csv
import pandas as pd
import seaborn as sns
if __name__ == "__main__":
# CSVを読み込む
dfCD = pd.read_csv("ChataData_CD.csv")
# 発売年月
releaseYear = []
# CSV格納データフレームを回して発売年月日を取得
# i:行名, row:series(行の値)
for i,row in dfCD.iterrows():
ymd = str(row['ReleaseYmd'])
# 発売年月日をスライスして発売年月にする
releaseYear.append(ymd[0:4])
# データフレームに発売年月リストを入れる
chataCD = pd.DataFrame({'year':releaseYear})
# seabornに日本語フォントをセット
sns.set(font='TakaoPGothic')
iterrowsで元データの入ったデータフレームを回してCDの発売年月を取得していきます。
iterrowsは行名と行の値からなるタプルを回すメソッドです。
データフレームを縦方向に回していくイメージでしょうか?
(参考:http://sinhrks.hatenablog.com/entry/2015/06/18/221747)
データセットには発売年月日として登録されているので、"yyyymm"となるようにスライスしてリストに入れます。
pd.DataFrame({ラベル名:Series})で発売年月のリストをデータフレームに入れます。
Seriesは1次元のリストです。私は最初、元データを回しながら発売年月(文字列)を追加していこうとして失敗しました。
Seabornに日本語フォントをセットして準備は終わりです。
ここではTakaoPGothicを指定しています。
日本語フォント指定については以下を参考にしました。
【Seaborn】日本語を表示する (フォントを変更する)
ではSeabornを使って可視化していきます。
まずはシンプルな方法から。
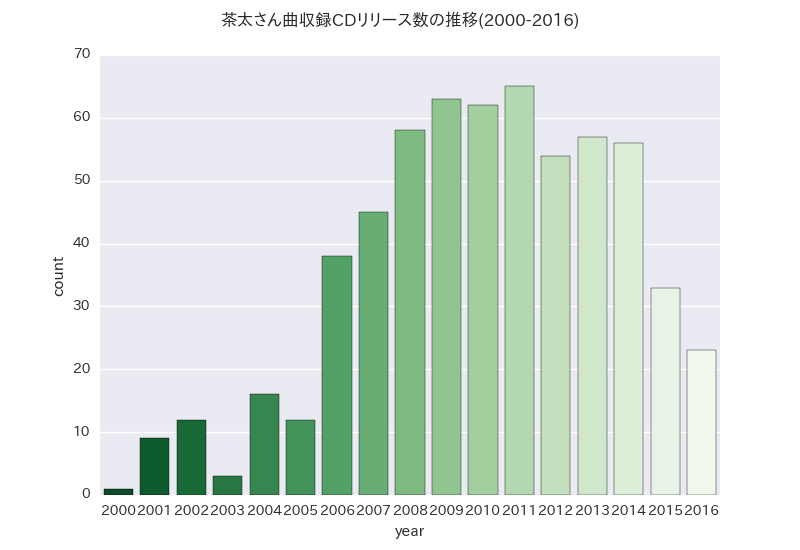
fig = sns.countplot(x='year',data=chataCD,palette='Greens_r').get_figure()
fig.suptitle('茶太さん曲収録CDリリース数の推移(2000-2016)')
sns.plt.savefig('countByYear_simple.png')
countplotはX軸もしくはY軸のデータをカウントしてくれるメソッドです。
CDごとの発売年月が入ったデータフレームを渡すだけで集計するので簡単ですね。
pythonで美しいグラフ描画 -seabornを使えばデータ分析と可視化が捗る その2
paletterではカラーパレットを指定します。
Seabornのカラーパレットの選び方が参考になりました。
以下が出力されたグラフです。
次に少し遠回りな方法です。手間は増えますがこちらの方がpandasの勉強になりそうです。
# 年月ごとのリリース数を求める
yrCount = chataCD['year'].value_counts(ascending=True).sort_index()
year = []
count = []
for row in yrCount.iteritems():
year.append(row[0])
count.append(row[1])
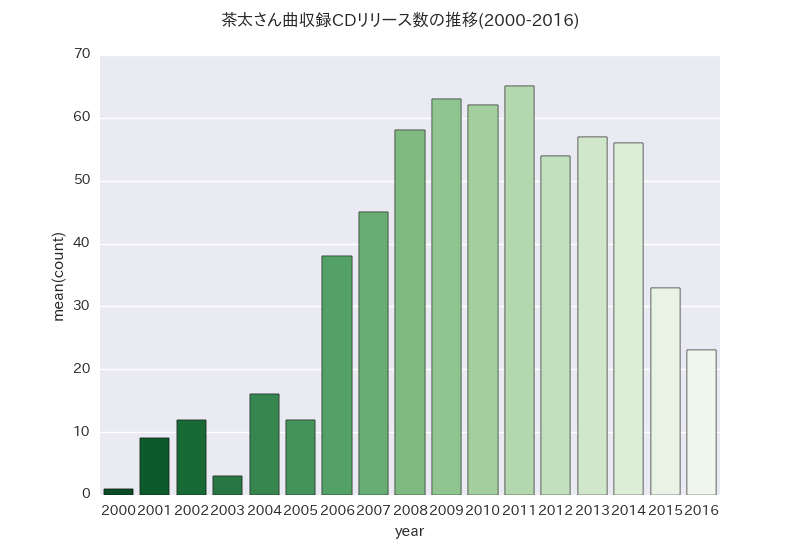
dfCount = pd.DataFrame({'year':year,'count':count})
barplot = sns.barplot(x='year',y='count',data=dfCount,palette='Greens_r').get_figure()
barplot.suptitle('茶太さん曲収録CDリリース数の推移(2000-2016)')
sns.plt.savefig('countByYear.png')
遠回りな方では発売年月とリリース数の2種類のデータを持つデータフレームを作ります。
まずDataFrame.value_countsで要素の数を集計します。
DataFrame.value_countsはSeriesを返します。今回の場合はindexが年月、valuesが枚数となります。
発売年月とリリース数それぞれのリストを作り、そこに値を入れます。
iteritemsはindexとvaluesからなるタプルを回すので、発売年月にはrow[0]、リリース数にはrow[1]を加えていきます。
発売年月とリリース数のリストからデータフレームを作ったら後はSeabornで可視化です。
いわゆる棒グラフを描画するbarplotを使います。
話は逸れますが
Seabornをインポートして実行すると以下のWarningが出るのですが原因がわからず困っています…
/.pyenv/versions/anaconda3-4.1.0/lib/python3.5/site-packages/PIL/Image.py:85: RuntimeWarning: The _imaging extension was built for another version of Pillow or PIL
warnings.warn(str(v), RuntimeWarning)
コメントにて原因をご教示いただけたら幸いです。