前回、入力画像サイズフリーにできるPoolingとして、SPPをWide_ResnetとWide_resnet_Autoencoderに適用してみた。
今回は、SPPの構造を詳細に見ることで、どのように利用すべきなのかを考察しようと思う。
同時に、ほかにSPP的に入力画像サイズフリーにできるPoolingの可能性を提案したいと思う。
構造・原理概略
論文からの引用として、以下の図がわかりやすい。
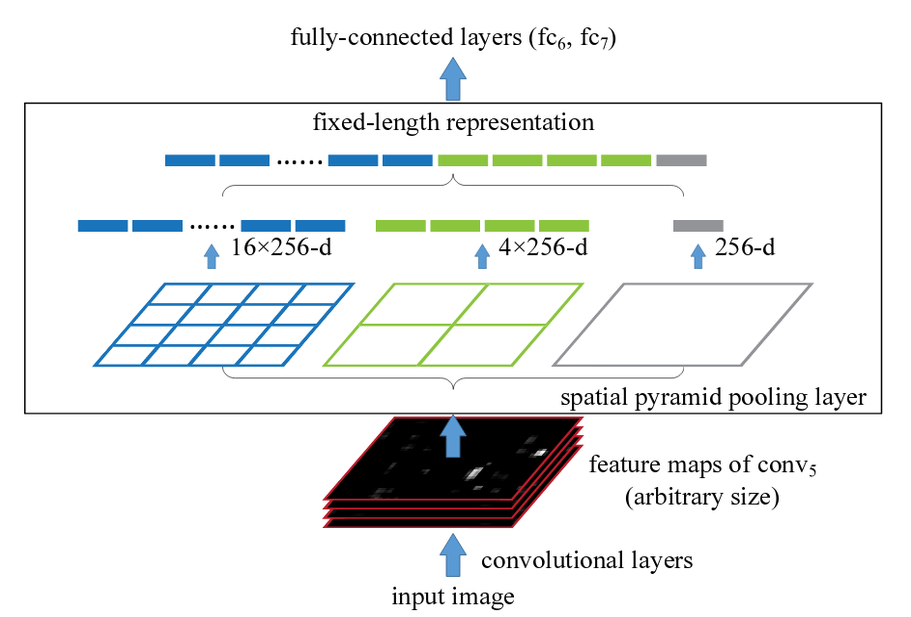
上図は、下の方から
①画像サイズフリーな画像を入力とする
②SpatialPyramidPoolingとして、Pooling_list[1,2,4]に基づいてそれぞれPoolingを実施して、1x256次元、4(=2x2)x256次元、そして16(=4x4)x256次元のベクトルをそれぞれ作成する
③上記の3つのベクトルを単連結して出力する
という構造であることを示している。
一番重要でかつ解釈として理解できないところは②のプロセスなので、ここを以下実際のプログラムで見てみようと思う。
SpatialPyramidPoolingのプログラム的構造
対応するコードは以下のとおりである。分割しつつ見ていこう。
49 def call(self, x, mask=None):
50
51 input_shape = K.shape(x)
52
53 if self.dim_ordering == 'th':
54 num_rows = input_shape[2]
55 num_cols = input_shape[3]
56 elif self.dim_ordering == 'tf':
57 num_rows = input_shape[1]
58 num_cols = input_shape[2]
59
まず、入力画像がchannel_first かchannel_lastかを見ている。
theano構造:(3,None,None) または、tenserflow構造:(None,None,3)
※すなわち、このフィルターを使うのは、一定のテンソル構造がないと意味が無いようである
60 row_length = [K.cast(num_rows, 'float32') / i for i in self.pool_list]
61 col_length = [K.cast(num_cols, 'float32') / i for i in self.pool_list]
62
次に、pool_list=[1,2,4]に基づいて、num_rows(num_cols)を除算してrow_length(col_length)を作成する。
'th'と'tf'は以下同じ構造なので、'tf'のプログラム構造を見ることとする。
63 outputs = []
84
85 elif self.dim_ordering == 'tf':
86 for pool_num, num_pool_regions in enumerate(self.pool_list):
87 for jy in range(num_pool_regions):
88 for ix in range(num_pool_regions):
89 x1 = ix * col_length[pool_num]
90 x2 = ix * col_length[pool_num] + col_length[pool_num]
91 y1 = jy * row_length[pool_num]
92 y2 = jy * row_length[pool_num] + row_length[pool_num]
for pool_num, num_pool_regions in enumerate(self.pool_list):ここで、pool_numはpool_listの順番で、num_pool_regionはその内容であり、これから順番にforするよということ。
【参考】
forループで便利な zip, enumerate関数
ということで、pool_num=2, num_pool_regions=2の場合
jyに0-2が入り、ixに0-2が入る。つまり、それぞれのpool_regionsの範囲をカバーするようにぐるぐる回る。
そして、例えばpool_num=2、num_pool_retions=2のときjy=2, ix=2とすると
x1 = 2 * col_length[2]
x2 = 2 * col_length[2] + col_length[2]
y1 = 2 * row_length[2]
y2 = jy * row_length[2] + row_length[2]
ということで、x1はx軸の開始位置(図形のx軸左の位置)、x2はx軸の終了位置(図形のx軸右の位置)y1はy軸の開始位置(図形のy軸左の位置),y2(図形のy軸右の位置)のように、すべての図形を切り出すための座標を計算している。
94 x1 = K.cast(K.round(x1), 'int32')
95 x2 = K.cast(K.round(x2), 'int32')
96 y1 = K.cast(K.round(y1), 'int32')
97 y2 = K.cast(K.round(y2), 'int32')
そして、それぞれを丸めつつ(int32)の整数型にする。
99 new_shape = [input_shape[0], y2 - y1,
100 x2 - x1, input_shape[3]]
そして、図形を先ほどの切り出し範囲を切り出すので、サイズは上記の通りとなる。
102 x_crop = x[:, y1:y2, x1:x2, :]
103 xm = K.reshape(x_crop, new_shape)
ここで実際に切り出す。
104 pooled_val = K.max(xm, axis=(1, 2))
105 outputs.append(pooled_val)
切り出した図形に対して、max_poolingを実施している。つまり、SPPはいろいろなサイズ(入力の[1,2,4]に基づいて)で、切り出してそれぞれmaxpooling2Dを実施しているのがわかる。
そして、結果を結合している。
109 elif self.dim_ordering == 'tf':
111 outputs = K.concatenate(outputs)
116 return outputs
最後に全体を結合して出力としている。
ということで、ある程度やっていることが分かった。
使い方と提案
前回やったように、SPP[1,2,4]以外のSPP[1]、SPP[8]なども可能であることがわかる。そして、SPP[1]の結果は本来単独でMax_poolingしたのと同じことを実施していると言える。
やはり、この処理はSPP[1,2,4]のように構造をサイズに切り出して、それぞれの特徴を抽出しつつ結合していくことがメリットを生かすこととなると思う。その意味では、CapsNetと同じように空間的な特徴を最下層のFlattenではなく、構造化して判断するための処理だと言える。
ある意味、もっと少ない層で威力を発揮するのかもしれない。
また、このSPPではコード番号104の通り、画像領域のmaxをとっているが、ここをmeanに変更することにより、average_poolingを行えるものと考察される。
ということで、もともとWide_Resnetなどでも最終層で採用されているのがAveragePoolingであることもあり、今回はAverage版のSPPを提案したい。
特に、SPP[1]はWide_Resnetで置き換えたaverage_pooling2dとFlattenの代替として利用できると思い実施してみた。
結果
原理説明が主な目的であったので、何が結果というのがあるが、とりあえず提案してSPPAverage版をSPP[1]として、Wide_Resnetに適用した結果を示す。
| epoch/ACC | AveragePooling+Flatten | SPPAve[1] | SPP[1,2,4] | SPP[1] |
|---|---|---|---|---|
| 1 | 0.543000 | 0.478100 | 0.457000 | 0.516600 |
| 10 | 0.766100 | 0.703800 | 0.660500 | 0.682900 |
| 50 | 0.860300 | 0.851200 | 0.841000 | 0.846400 |
| P.size | AveragePooling+Flatten | SPPAve[1] | SPP[1,2,4] | SPP[1] |
|---|---|---|---|---|
| Total | 2,279,882 | 2,279,882 | 2,311,882 | 2,279,882 |
| Trainable | 2,275,370 | 2,275,370 | 2,307,370 | 2,275,370 |
まとめ
・今回は、SPPの構造を見ることによって、原理を理解した。
・その結果として、SPPAverage版を作成してWide_resnetに適用してほぼオリジナルと同様な精度になることを見た
課題
・実際には少し誤差が出ており、原因は追究したい
・他の入力画像サイズフリーを実現できる方式も提案可能だと考えられるので探求したい
・適用領域はもっと浅い簡単なモデルに適用したとき有効であると予想されるので実証したい
・同様構造なCapsNetも入力画像フリーでした。また、Keras_Exampleに掲載のkeras / examples / cifar10_cnn_capsule.pyが高精度なので、次回比較したいと思います。