Scalaで累積和を計算するのがかっこよかったのでPythonでも同じことをやってみたという話.
累積和とは?
数列が与えられたとき0番目から $k$ 番目までの総和を予め計算しておくことにより $k$番目から $l$番目までの総和を定数時間で取得できる,という競プロでおなじみの処理です.
こんな感じ
a_i\ (i=0,\ldots, N-1),\quad s_k = \sum_{i=0}^{k} a_i \\
a_k+\cdots+a_l = \sum_{i=k}^{l}a_i = s_k - s_{k-1}
「+」に限らず逆演算が簡単にできる2項演算なら同じことが出来るので汎用性の高い処理ですね.1
累積和について詳しい解説はこちらの記事あたりがわかりやすいと思います.
Scalaでの累積和計算
多くのプログラミング言語2では以下のように別途配列を用意してfor文を回す処理を書くことが多いでしょう.
cumsum = [0]
for ai in [1, 2, 3, 4]:
cumsum.append( cumsum[-1]+ai )
# cumsum = [0, 1, 3, 6, 10]
Scalaで累積和は以下のようにすっきり1行で累積和のリストが得られます.
List(1, 2, 3, 4).scanLeft(0)(_+_)
// => List(0, 1, 3, 6, 10)
「0」は累積和配列の初期要素,_+_は(x,y)=>x+yという無名関数の略記だそうです.ちゃんと知りたい人はラムダ式とかワイルドカードとかで調べてみてください.
途中の計算結果は捨てて最終結果だけを返すfoldLeftというメソッドもあります.足し算の場合は配列の総和が求まりますね.
List(1, 2, 3, 4).foldLeft(0)(_+_)
// => 10
もちろん累積和に限った話ではなく,例えば「左から順に,それより左で一番小さい要素」を求める,なんてこともできます.
List(4, 3, 2, 3, 2, 1).scanLeft(1000000007).scanLeft(math.min(_,_))
// => List(1000000007, 4, 3, 2, 2, 2, 1)
Pythonでやりたい
Pythonにも高階関数がありコレクションに関数を適用するという操作ができます.
例えばmap(int, lst)でリストの要素をint型にキャストするというような処理は競プロで入力を受け取るときによく使われると思います.
ScalaのfoldLeftに相当するのはfunctools.reduceなのですがscanLeftに相当するような関数はitertools.accumulateです.なぜ同じモジュールにまとまってないのか. ついでに返り値はイテレータなのでインデックスアクセスしたいときはリストに変換しておく必要があります.
あと,初期値をもたせる方法が見当たりません.最初の演算は最初の要素がそのまま返ってくるようです.
import itertools
itertools.accumulate([1, 2, 3, 4], lambda x,y:x+y)
# => [1, 3, 6, 10]
itertools.accumulate([1], lambda x,y:x+y)
# => [1]
(2021/05/14 追記)
Python 3.8 以降ではitertools.accumulateに引数initialで初期値を設定できるようになりました.( https://note.nkmk.me/python-itertools-accumulate/#initial )
itertools.accumulate([1, 2, 3, 4], lambda x,y:x+y, initial=0)
# => [0, 1, 3, 6, 10]
(追記終わり)
ベンチマーク
Pythonは遅いことで有名ですが特にforループを使うとかなり遅くなります.
forループを回すのと高階関数での処理でどれくらい速度が変わるのでしょうか.時間を測ってみました.
ついでにnumpyにもnumpy.ufunc.accumulateが存在し,ユニバーサル化した関数で累積計算をさせることができます.うまいことnumpyで計算を完結させると爆速になるのでこちらもやってみました.
import numpy as np
import time
def accumulate_for(lst, func, init=0):
cumsum = [init]
for t in lst:
cumsum += [func(cumsum[-1],t)]
return cumsum
plus = lambda x,y:x+y
npplus = np.frompyfunc(plus, 2, 1)
space = [(i+1)*10**5 for i in range(10)]
time1s = []
time2s = []
time3s = []
for size in space:
test = np.random.random(size)
start = time.time()
# for文を使用
cumsum1 = accumulate_for(test, plus)
time1 = time.time() - start
start = time.time()
# itertools.accumulate を使用,イテレータからリストに変換
*cumsum2, = itertools.accumulate(test, plus)
time2 = time.time() - start
start = time.time()
# numpyのユニバーサル関数によるaccumulate
cumsum3 = uplus.accumulate(test, dtype=np.object).astype(np.float)
time3 = time.time() - start
time1s += [time1]
time2s += [time2]
time3s += [time3]
結果はこちら.繰り返しをやってないのでそんなに正確でもないですがだいたい1.5~2倍くらい差が付きますね.
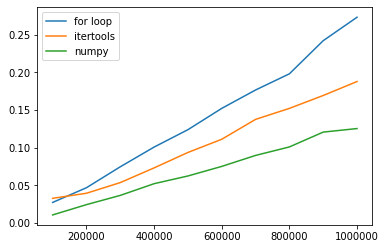
ちなみにnumpyでの処理は入力がリストだったり出力をリストに変換したりしているとfor文と同レベルまで遅くなります.最初から最後までnumpyで処理するという強い意志が必要です.
さらにnumpy組み込みのユニバーサル関数以外の.accumulateにはバグがあるらしく,, dtype=np.object).astype(np.float)の下りはこれへの対処です.参考
組み込みでは無いのでインポートしてこないといけないとか,そもそもリストのメソッドチェーンで処理できない3のでScalaに比べるとスマートさに欠けますが一応速くなりました.めでたしめでたし.
(2021/05/14 追記)
条件を整えてベンチマークをやり直してみました.
Jupyter notebook(正確にはIPythonの機能)では%timeitというマジックコマンドで自動的に実行時間のベンチマークを取ることができます.
特に,-oコマンドを使用すると計測結果を受け取ることができ便利です.( https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-timeit )
space = [(i+1)*10**5 for i in range(10)]
results = []
for size in space:
print(size)
test = np.random.random(size)
# for文を使用
res = %timeit -o cumsum = accumulate_for(test, plus)
results.append(res)
# => 100000
# => 22.2 ms ± 1.91 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
# => ...
のようにすると cumsum1 = accumulate_for(test, plus) の部分をN回実行した実行時間のR回の統計量を算出してくれます.
実行する部分の実行時間によってNを自動で調整してくれるので大変楽です.
これを使って以下の操作の実行時間を計測しました.
# loop: for文を使用
res1 = %timeit -o cumsum = accumulate_for(test, plus)
# expansion: itertools.accumulate を使用,イテレータから展開代入
res2 = %timeit -o *cumsum, = itertools.accumulate(test, plus)
# tolist: itertools.accumulate を使用,イテレータからリストに変換
res3 = %timeit -o cumsum = list(itertools.accumulate(test, plus))
# np.add: numpyのユニバーサル関数によるaccumulate
res4 = %timeit -o cumsum = np.add.accumulate(test)
# uplus: numpyのユニバーサル関数によるaccumulate (ユーザー定義の場合は型キャストが必要)
res5 = %timeit -o cumsum = uplus.accumulate(test, dtype=np.object).astype(np.float)
上で計測したものに加え,itertools.accumulate でlistに変換する際展開代入を使わずlist()を使ったもの,numpy組み込みであるnp.add のaccumulateを使用したものを追加しました.
展開代入でオーバーヘッドがないかどうかの確認と,ユーザー定義のユニバーサル関数はバグのため型キャストを行っており本来の速度が出せていないことによるものです.
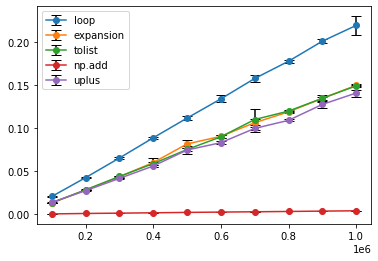
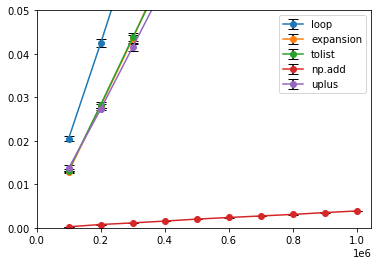
結果は以下の図のようになりました.for文が比較的遅いですが,そんなことがどうでもよくなるくらいにnumpyオンリーの場合が速いですね.
単なる累積和でnumpyが使える場合はこれ一択でしょう.
(追記終わり)
蛇足
初期値をもたせたいとかfunctoolsに無いので存在しないと思い込んでいたとかfunctools.reduceからscanLeftに相当する関数を作ることができます.途中の計算結果をもたせたリストを演算結果とすればよいのです.
scanLeft = lambda func, lst, init: functools.reduce(lambda acc,x:acc+[func(acc[-1],x)], lst, [init])
scanLeft([1, 2, 3, 4], lambda x,y:x+y, 0)
# => [0, 1, 3, 6, 10]
そんなふうに考えていた時期が私にもありました.
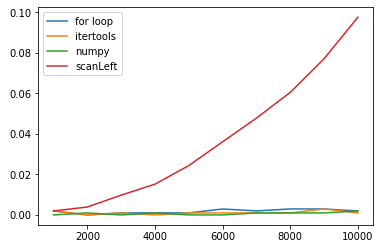
速度を比べてみたらどうも$O(N^2)$っぽいです.末尾再帰になってないとかそういう感じなんでしょうか.これについてはよくわからないので今後の課題とさせていただきます()
(2021/05/14 追記)
これほどに遅い原因は,値の更新でacc+[func(acc[-1],x)]としているところが毎度新たにlistオブジェクトを作り直していることにより $O(N)$ 掛かっているためであると予想されます.
同じlistにpushを繰り返し行いたいですが,残念ながら list.append は自身を返さないため複文となってしまいlambda式のままでは扱えません.
よってlistにpushしてそのlistオブジェクトをそのまま返すappend関数を定義してこれを利用します.
def append(lst, x):
lst.append(x)
return lst
scanLeft = lambda func, lst, init: functools.reduce(lambda acc,x:append(acc, func(acc[-1],x)), lst, [init])
cumsum = scanLeft(plus, test, 0)
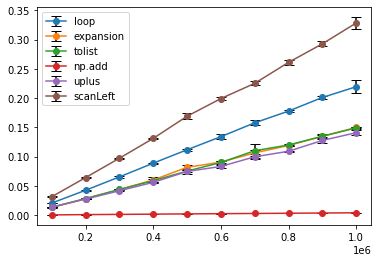
上記と同様にベンチマークを行うと以下の様になります.
無事 $O(N)$ で動作するようになりましたが単純にfor文で書くよりも遅くなってしまいました……
素直にaccumulateを使ったほうが良さそうですね.
(追記終わり)