Introduction
2019年もあと数時間で終わりであり、来年への関心が高まっている。
来年は何年なのか、AIによる予測を行った。
Method
学習データ
今年から2019年前までの2019個のデータで学習した。
学習
rbfカーネルのKernelRidgeで学習した。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df = pd.read_csv('years.csv',names=("years", "result"))
features = df.drop(["result"], axis=1)
target = df["result"]
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(features, target, test_size=0.2, random_state=0)
from sklearn.model_selection import GridSearchCV
from sklearn.kernel_ridge import KernelRidge
param_grid = {'alpha': [i*10**j for i in [1,3] for j in [-9,-8,-7]],
'gamma': [i*10**j for i in [1,2,4,7] for j in [-6,-5,-4]]}
gs = GridSearchCV(KernelRidge(kernel='rbf'), param_grid, cv=5, n_jobs=3)
gs.fit(train_x, train_y)
rgr = gs.best_estimator_
学習データをランダムに学習用とテスト用に分割し、学習用データで学習させた。
KernelRidgeはハイパーパラメータalphaとgammaがあるのでグリッドサーチで最適化した。
Result
交差検証
GridSearchCVでは与えたデータを更に分割して、汎化性能を最大化するパラメータを探索する。最適のパラメータにおける予測器の性能を判定する。
print(gs.best_estimator_)
print(gs.best_score_)
KernelRidge(alpha=1e-09, coef0=1, degree=3, gamma=2e-05, kernel='rbf',
kernel_params=None)
0.9999999999996596
汎化性能のスコアは十分高い値となった。
yyplot
plt.scatter(rgr.predict(train_x), train_y, marker='.', label='train')
plt.scatter(rgr.predict(test_x), test_y, marker='.', label='test')
plt.legend()
plt.show()
学習・テスト用データに対し、正当な予測ができているかどうかを可視化するためyyplotを描画した。
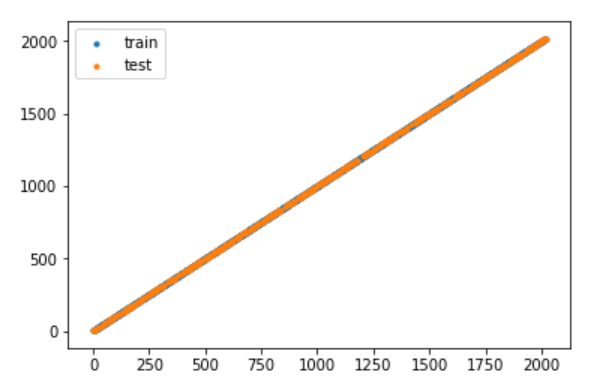
多くの既存データに対し正しい予測ができていることが見て取れる。
学習曲線
過学習しているかどうかを判別するため学習曲線を描画し検証した。
from sklearn.model_selection import (learning_curve,ShuffleSplit)
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=None, train_sizes=np.linspace(.1, 1.0, 5), verbose=0):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
cv = ShuffleSplit(n_splits=5, test_size=0.2, random_state=0)
t_size = np.linspace(0.01, 1.00, 20)
plot_learning_curve(RandomForestRegressor(n_estimators=50),
"Learning Curve", features, target, cv=cv, ylim=[0.98,1.005], train_sizes=t_size, verbose=10)
plt.show()
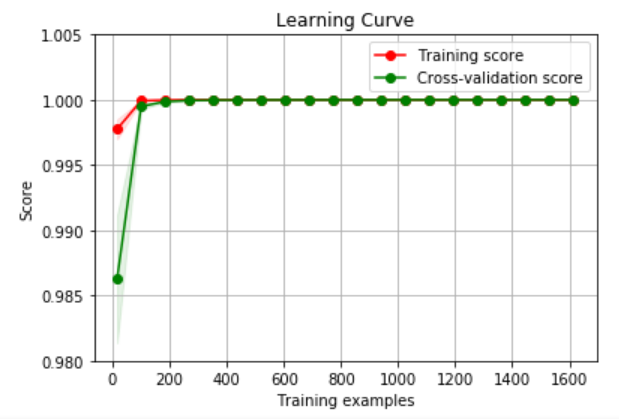
学習性能・汎化性能ともに高い値に収束しているため過学習している可能性は低いと判断できる。
来年の年の予測
print(rgr.predict([[2019+1]]))
今年の次の年のパラメータを入力して来年の年を予測した。
[2019.99488853]
結果は$2.020\times 10^3$年となった。これにより来年の年は2020年と予想される。
Discussion
rbfカーネルのKernelRidge法は無限次元Gaussian関数空間から損失関数を最小化する関数を求める手法であり、明示的な関数形が仮定される問題について高い汎化性能を発揮する。来年が2020年であるという予測は蓋然性が高いと言える。