音声分析合成ってなぁに?
音声分析合成というのは、何らかの音声を合成して、それを分析し何らかのデータにして、それを複合して元の音声を生成する、という研究分野です。
ある意味では音声合成(Text-to-speech)はこの一分野としてみなすことができるかもしれません。
但し本研究はテキストから音声を合成することは出来ないと思われます。
音声分析合成の関連研究はどんなものがあるの?
日本語でかなり有名なものとして、WORLDというものがあります。
このあたり 1 2 が参考資料としてよいでしょう。
ここにはないものとして、LPCNet というものがあり、論文では触れられていますが、こちらについてはそのうち書きます。(Mozillaあたりの研究で、それなりのネームバリューがあります)
RawNet の概要は何?
RawNet は 深層学習を用いた 高速な Vocoder です。Vocoder とは何かと言われると日本語でうまいこと表現する語が思いつきませんが、音声合成するもの、と思っていただければ大丈夫でしょう。
ちょっと論文の概要を翻訳してみましょう。
昨今、深層学習を用いた vocoder は高品質の音声を生成することが可能であることがわかってきました。これらのモデルはおおよそメルスペクトラムといったスペクトル特性を用いてサンプルデータを生成します。しかし、それらの特性は人間の知識を元にしてできた(手打ちで作られた)プロセスを含んだ音声分析モジュールを用いて抽出されています。
つまり、昨今の深層学習を用いた vocoder は学習データを作成する際に人手を使っておりコストがかかってしまっていることを指摘しています。
本研究では RawNet と呼ばれるモデルを提案します。これは真に end-to-end な vocoder で、信号のより高次元な表現を学習するために coder ネットワークを使用し、そのサンプルごとに音声サンプルを生成する autoregressive voder ネットワークを使用しています。
vocoder とは coder と voder で構成されており、 coder は音声を符号化する機能を持っており、voder はそれを複合する機能を持っていると考えてください。このあたりは mp3 のような codec を想定してもらうとわかりやすいでしょう。mp3 では入力される音声をルールに従って圧縮したバイナリデータに変換し、これを同じルールに従って復号することで音声として我々が聞き取ります。
autoregressive ネットワークとは、日本語では自己回帰ネットワークとも言われ、例えば RNN (recurent neural network) を挙げられるでしょう。
coder と voder は合わせて auto-encoder network のように振る舞います。そしてこれらは、人間による何らかのプロセスを含まずに、実際の音声データを用いて一緒に訓練されます。
auto-encoder!私は arxiv でこれが一行でも出てくるような新規論文には必ず目を通すくらいには好きな深層学習の分野です。(実際この論文を真面目に読もうと思ったのもこの一行のためです)これは生成モデルと呼ばれる深層学習モデルの一つで、主には入力データと同じようなデータを作成することを目的にしています。例えば自動でイラストを作ってくれるモデルなんかはこの分野の研究分野の産物と言えるでしょう(正確にはこの分野で現在脚光を浴びているのはGANs(Generative Adversarial Nets) と呼ばれるモデルの分野だったはずです)。
Copy-Sysnthesis タスクに関する実験は、RawNetが LPCNet に比べてより小さいモデルながら高品質な音声品質を合成することが出来た他、推論時により高速に音声合成ができることが明らかになりました。
つまり比較実験として LPCNet を用いたところ、小さいモデルで高品質、そして推論時により高速に音声が作れた、というわけです。
RawNet は何が出来たの?
一行で言うと、深層学習を用いたより高性能な vocoder を提案しました。
また、
そしていくつかの技術を用いることで voder と coder を同時に訓練する困難さを和らげモデルのパフォーマンスを向上させたことや、
その結果人間からの評価としてこのモデルがより LPCNet に比べてより自然で高評価が得られる音声を生成できること、
音声特徴を視覚化して確認したところ良い感じの特徴が抽出できていることが確認できたこと
も挙げられるでしょう。
また、本論文ではこの研究を元にして他の音声合成フレームワークやその他の音声合成関連のタスクで応用されることを期待しているとのことです。この手の分野の研究がより進んでくれると 対話システムの研究でも 役立つのでぜひとも進めてほしいです(個人的な願望)。
RawNet の中身は?
ここからは詳しい内容を見てみましょう。
まずはじめにモデルの概要図を論文中から引用しましょう。このモデルは数式がほとんど出てきませんが、そういうものだと思ってください。
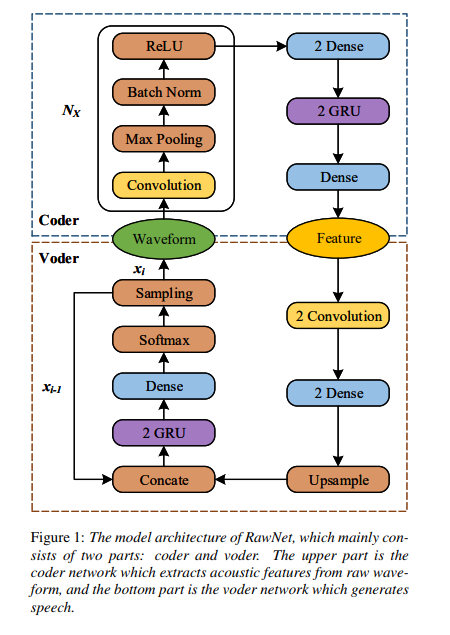
上部分が coder (auto-encoder でいう encoder) で、下部分が voder (auto-encoder でいう decoder) です。 waveform というのは音声波形になります。
waveform から coder を流れていき、feature、特徴量を獲得し、そこから voder を流れることで元の waveform を得る、これがこのモデルの流れになります。
順番に見ていきましょう。
Coder と Voder
-
Coder
Coder は入力されるデータである音声波形から特徴量を抽出するための機構であり、その主な構成物は、多層型の畳込みレイヤと、Dense layer、そして GRU (RNN の一種、特に速度が早い) レイヤーです。多層型の畳込みレイヤによって高レベルの表現を学習することができると期待されており、言い換えれば一連の低レベルの(薄い)フィルタを何枚も通されることによって高レベルの表現の学習が期待されています。(このアイデアは SoundNet から得られたものだそうです。音声(動画?)分類問題の教師なし学習のタスクという面白い研究なのでちらっと見ると面白いかもしれません。)また後半の Dense layer と GRU が組み込まれている理由は音声波形の長期的な関係を学習するためのものだそうです。
GRUが長期的な関係を学習するために役立つ頃は容易にわかりますが、Dense Layerは手続き上必要なもの以上の意味を感じ取れませんでした…
またこの部分では可変長である音声波形の入力データを処理するために、畳込みレイヤーのストライド間隔、Pooling Layer の Pooling サイズを調節したそうです(参考資料)。畳み込みレイヤはその位置に対して不変であるため(CNN の位置不変性と呼ばれることもあります)、出力長を制御するためにその各レイヤを畳み込むことができます。そのため、feature のフレームサイズは畳み込み層や Pooling Layer でのみ決定できることになります。
言っていることはわかるんですが、これどうやって実装したんでしょうね…?多分学習データの最長のものをカバーできるだけの畳込み層のサイズを用意したか、各データごとに畳み込みやらのサイズを変更したんだろうと思うんですが、実際どうなんでしょう。後者をするなら一般的なフレームワークでは解決できないような気がしています。(実際PyTorch では こんな議論がなされています。)
-
Voder
Voder は feature つまり音響特性から、音声を生成するための機構です。この構造は LPCNet と類似していますが、いくつかの修正を施しています。次のサンプルを生成する際、($x_i$ → $x_{i+1}$ where x はサンプルした音声波形の一点、 i は時刻) LPCNet は入力として現在の予測サンプル、現在の予測された励起(恐らく隠れ層のベクトルのことだと思います)、フレームレートネットワークからのグローバルな特徴、そして現在のサンプルの線形予測を用います。(LPCNet については今後まとめるのでこのあたりはほとんど直球で訳しています。) LPCNet の複雑な入力情報とは異なって、RawNet では現在の予測サンプルと、コンディショニング音響特性(conditioning acoustic features、feature を 畳み込み、Dense Layer、Upsampling したもの?) のみを入力として使用され、これは連結されて (時系列的に) 次のレイヤーで用いられます。
抽出された音響特性は最初に2層の畳込み層を通過し、その後に2層のDense Layerが続きます。Dense Layer の出力は frame 長と同じくらいの長さで、そして audio-sample の長さに Upsampling します。本実験では単純な Upsampling 手法を用いました。つまりフレームサイズ K のデータに対してそれを K 回繰り返します(2乗サイズにするということだと思われる?)。Upsample された feature は時系列的に前の予測されたサンプル x_{i-1} と連結され、それを 2層のGLU、Dense Layer(論文中では2層の Fully Connected Layer と説明されています)、そして活性化層として Softmax 層に通されます。最後にサンプリングを行うことでサンプル x_i を生成します。
またサンプルの値をネットワークに与える前にサンプルされたその値を固定範囲または固定値にスケールさせるのではなく、サンプルした値に圧縮変換を適用するために $\mu$ -law というテクニックを用いています。このモデルは各 $\mu$ -law レベルで学習されることになり、つまり本質的には $\mu$ -law 値、非線形関数を通されたサンプル値について学習することになります。
自然言語処理畑育ちのせいか、私には Upsampling というのは初見でしたが、幸いわかりやすい記事、DeepLearning でアップサンプリングする がありました。Deconvolution (= Transposed Convolution) と似たような機能だと思うんですが、入れ替えると性能にどう影響するのかがちょっと気になります。
また $\mu$ -law については大学の授業でちらっと触れていたような記憶がありますが、確か音声のサンプルされた値を対数的に圧縮することで人間的な音質の低下を抑えながらデータを圧縮することができる、というような技術のはずです。元データは恐らく データサイズが大きいPCM だと思われるので、この圧縮でデータ・学習のコストを下げているのかなとも思っています。
Sampling Method
LPCNet と FFTNet の論文では、出力分布から直接データをサンプリングすると過度のノイズが発生してしまうことがあると報告されています。この問題への対処として、FFTNet は有声音を強調する手法を提案しました。LPCNet では2値化判定をピッチ相関 (pitch correlation) に置き換えました。ピッチ相関 (pitch correlation) は、出力 logit を継続的にスケーリングするために利用されます。
本実験では、multinomial sampling, 条件付きサンプリング(conditional sampling), そして LPCNet のピッチ相関をベースとしたサンプリング、そして単純な argmax を用いたサンプリングを行い比較を行っています。しかし結局のところ argmax を用いた手法が最もクリアな音声を生成することが出来たようです。(この結果は WaveNet でも同様な結果が報告されているようです。)
ピッチ相関ってなんですかねっていう顔をしています。LPCNet の論文はこの後読む予定なので、きっとそこで明らかになることを期待しています…。それとこれはピッチ相関、という訳であっているんでしょうか?調べてもまるで出てこないので恐らく違うような気がしています。
Noise injection
訓練時のエラーのせいで、合成されたサンプルデータには幾ばくかのノイズが常に含まれてしまいます。更にサンプルを生成する際に、このネットワークは auto-regressive の特性のために、時系列的に後のデータになるにつれどんどんノイズが多くなってしまうという欠点も存在しています。Voder のネットワークがこれらのノイズの多いサンプルを入力データとして受け取ってしまい、その次のサンプルを生成しようとしたとき、このノイズを更に増幅させてしまいます。その結果、出力されるサンプルには clicking artifacts (恐らく これ のこと)が含まれてしまうことがあります。この問題に対処するために、訓練中に入力データにランダムなノイズを加えるという処理を行いました。
より詳細に説明すると、訓練時に入力データ、つまり生の波形に対して N(0, 0.2) の正規分布からのノイズを注入してから voder ネットワークで学習を行いました。また、N(0, 0.1) からのノイズを coder ネットワークに与える前の入力データに注入しました。このノイズを注入するテクニックは、モデルが書くトレーニングで行われる反復時に異なるトレーニングデータを参照することが出来(もっと言えば学習データの増加も見込める)、効果的に過剰適合を抑えることができるという利点があることがわかっています。
前半は少し理解が難しいですが、きれいなデータがだんだん汚れていってしまうよりかはある程度汚しておいたほうが学習がうまく行く、ということなのかな、と解釈しています。(違ったらすみません)後半に関しては Denoising auto-encoder(DAE) の発想に非常に近いものを感じます。 DAEはAutoencoderの入力にノイズをかけることで多様性を確保する、過学習を抑制する手法の一つとして知られており、NLPでも例えば文のスタイル変換(Sequence to better Sequence とか)なんかで使えそうなテクニックとして私は捉えています。(とはいえこれを卒業研究でやったところやたらと評判が悪かったですが)
Post-synthesis denoising
ノイズを注入するということで得られる利益は上記したように様々にありますが、これによって得られる損失として、特に無声区間にノイズが乗ってしまう、というものがあります。この問題に対処するために、音声活動検出(voice activity detection) にエネルギーベースの手法を用いました。これは極めて簡単に行うことができる上に、殆どの雑音を除去することが出来ました。
ここに関しては、音声はこのように処理できるのかぁと驚きました。なかなか画像が自然言語ではこういう対処は見たことがなく、音声ならではの手法だと思います。
実装はどこにあるの?
レポジトリ が github にあるようですが、現在は中身がないようです。暇な人、実装してください orz
感想
この論文自体はかなり面白いと思っているのですが、それ以上に様々な応用が考えられそうな内容であると私は思っています。
例えば、上でも少し提案していましたが、feature の部分を応用してText-to-Speech が作れそう、という案が挙げられます。それは例えばテキストから直接 feature を作ることや、テキストの潜在表現と feature をつなぐとかです(恐らくこれは短文や句点区切りのデータのみにドメインを絞ることである程度の品質が見込めると思っています)。これがなぜできると想像しているのかと言うと、機械翻訳の分野である言語を VAE で学習し、それを2つ用意して、潜在表現間をDNNでつなぐという研究を読んだことがあるからです(この論文のタイトルを忘れてしまったので誰か知っていらっしゃれば教えてください)
とはいえ、このあたりの研究は私では出来ない(十分な計算機、データ収集やアンケートの実施のための資金が降ってこない)ので、どこかの大学の方、研究所の方、研究の種にしていただけると幸いです。
ソース(文とか翻訳記事とかなんとか)
ここ(研究室ではこの分野あんまり興味持ってもらえなかったので最低でも月1回位は更新してセルフゼミしようかなと思っています・・・issue なんかで色々教えて頂けると喜びます)
https://github.com/MokkeMeguru/seminar/tree/master/gunrock