はじめに
macOS向けアプリ開発でCPU使用率とかキーボードのショートカット入力とかタッチパッドの値とか色々と監視する手法を探る日々の中で,クリップボードの値を取得して書き換えられることを後輩を通じて知りました.そして,ふと忙しないTwitterのTLを見ると「にゃーん」と呟くエンジニアを複数発見しました.
そこで思ったのです.
「そうだ,彼らのツイートをもっとネコにしてあげたい」と...
そんな成り行きで1つのツールが生まれました.
Nekobot

クリップボードにコピーしてある文章をネコ語っぽくしてペーストできる.たったそれだけの機能を持った常駐型のアプリです.
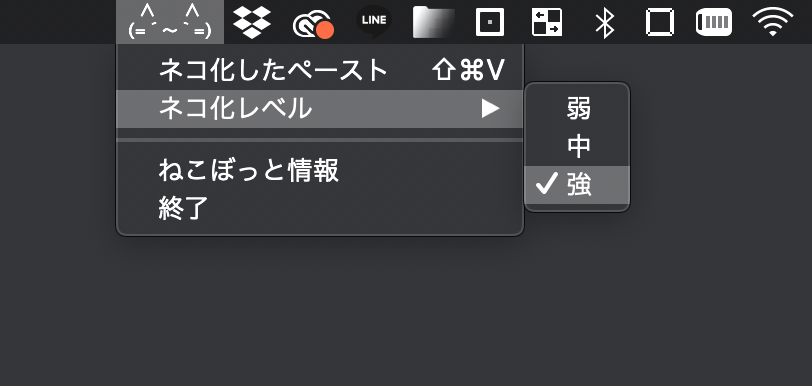
ネコ度合いは3段階で,文章中のひらがなの「な」を「にゃ」に変えるだけのネコ度:弱,文章中の漢字の読みに含まれる「な」も「にゃ」に変えるネコ度:中,もはや原型がわからないほどにゃんにゃんするネコ度:強があります.
原文:穴があったら入りたいな
ネコ度弱:穴があったら入りたいにゃ
ネコ度中:あにゃがあったら入りたいにゃ
ネコ度強:ニャンニャニャニャッニャニャニャニニニャニンニャ
ダウンロード
Nekobot配布サイト
実行環境はmacOS Mojave 10.14.*です.(古いバージョンで動くか確認するの面倒だったので)
ネコ語エンジン
今回適当に作ったネコ語エンジンですが,意外にもテクいことをしています.文章に含まれるワードがひらがなかカタカナか漢字かを検出したり,品詞分解したり,日本語の読みをローマ字に分解したりなど厄介でした.
import Foundation
final class TextConverter {
enum Level: Int {
case weak
case normal
case strong
}
private func isHiragana(_ str: String) -> Bool {
let regex = "^[ぁ-ゞ]+$"
let predicate = NSPredicate(format:"SELF MATCHES %@", regex)
return predicate.evaluate(with: str)
}
private func isKatakana(_ str: String) -> Bool {
let regex = "^[ァ-ヾ]+$"
let predicate = NSPredicate(format:"SELF MATCHES %@", regex)
return predicate.evaluate(with: str)
}
private func containsKanji(_ str: String) -> Bool {
let regex = "^.*[\u{3005}\u{3007}\u{303b}\u{3400}-\u{9fff}\u{f900}-\u{faff}\u{20000}-\u{2ffff}]+.*$"
let predicate = NSPredicate(format:"SELF MATCHES %@", regex)
return predicate.evaluate(with: str)
}
public func convert(_ text: String, _ level: Level) -> String {
switch level {
case .weak: return convertWeak(text)
case .normal: return convertNormal(text)
case .strong: return convertStrong(text)
}
}
private func convertWeak(_ text: String) -> String {
return text.map({ (char) -> String in
if char == "な" { return "にゃ" }
if char == "ナ" { return "ニャ" }
return String(char)
}).joined()
}
private func convertKanjiHiragana(_ text: String) -> String {
let input: String = text.trimmingCharacters(in: CharacterSet.whitespacesAndNewlines)
let identifier = CFLocaleCreateCanonicalLanguageIdentifierFromString(kCFAllocatorDefault, "ja" as CFString)
let tokenizer = CFStringTokenizerCreate(kCFAllocatorDefault,
input as CFString,
CFRangeMake(0, input.utf16.count),
kCFStringTokenizerUnitWordBoundary,
CFLocaleCreate(kCFAllocatorDefault, identifier))
var output: String = ""
var tokenType = CFStringTokenizerGoToTokenAtIndex(tokenizer, 0)
while tokenType.rawValue != 0 {
if let text = CFStringTokenizerCopyCurrentTokenAttribute(tokenizer, kCFStringTokenizerAttributeLatinTranscription) as? NSString {
let mutableString = text.mutableCopy() as! NSMutableString
CFStringTransform(mutableString as CFMutableString, nil, kCFStringTransformLatinHiragana, false)
output.append(mutableString as String)
}
tokenType = CFStringTokenizerAdvanceToNextToken(tokenizer)
}
return output
}
private func convertNormal(_ text: String) -> String {
var output: String = ""
let tagger = NSLinguisticTagger(tagSchemes: NSLinguisticTagger.availableTagSchemes(forLanguage: "en"), options: 0)
tagger.string = text
tagger.enumerateTags(in: NSRange(location: 0, length: text.count), scheme: .tokenType, options: []) { tag, tokenRange, sentenceRange, _ in
let subString = (text as NSString).substring(with: tokenRange)
if containsKanji(subString) {
let hiragana = convertKanjiHiragana(subString)
if hiragana.contains("な") {
output.append(hiragana.replacingOccurrences(of: "な", with: "にゃ"))
} else {
output.append(subString)
}
} else if isKatakana(subString) {
output.append(subString.replacingOccurrences(of: "ナ", with: "ニャ"))
} else if isHiragana(subString) {
output.append(subString.replacingOccurrences(of: "な", with: "にゃ"))
} else {
output.append(subString)
}
}
return output
}
private func transliterateString(source: String, transform: CFString, reverse: Bool) -> String {
let string = CFStringCreateMutableCopy(kCFAllocatorDefault, 0, source as CFString)
if CFStringTransform(string, nil, transform, reverse) {
return String(describing: string!)
} else {
return source
}
}
private func convertStrong(_ text: String) -> String {
var list1 = text.components(separatedBy: "ー")
for n in (0 ..< list1.count) {
var list2 = list1[n].components(separatedBy: CharacterSet(charactersIn: "っッ"))
for m in (0 ..< list2.count) {
let hiragana = convertKanjiHiragana(list2[m])
let roman = transliterateString(source: hiragana,
transform: kCFStringTransformLatinHiragana,
reverse: true)
var vowel = roman.removeCharacters(from: "bcdfghjklmpqrstvxyz")
vowel = vowel.replacingOccurrences(of: "'n", with: "")
vowel = vowel.replacingOccurrences(of: "a", with: "ニャ")
vowel = vowel.replacingOccurrences(of: "i", with: "ニ")
vowel = vowel.replacingOccurrences(of: "u", with: "ウ")
vowel = vowel.replacingOccurrences(of: "w", with: "ヴ")
vowel = vowel.replacingOccurrences(of: "e", with: "ャ")
vowel = vowel.replacingOccurrences(of: "o", with: "オ")
vowel = vowel.replacingOccurrences(of: "n", with: "ン")
list2[m] = vowel
}
list1[n] = list2.joined(separator: "ッ")
}
return list1.joined(separator: "ー")
}
}
備考
ペーストをグローバルに発動するために,アクセシビリティの許可を要求しているのですが,この要求が必要ない方法はないものでしょうか...
参考
文字列が人名かどうかをバリデーションする方法
Swift:ローマ字の文字列をひらがな・カタカナに変換するクラス作った
Swift:文字列を複数の区切り文字で分割する