Introduction
私は、デザイナーからあがってきたイラストレーターのUI画面の文字を、手作業で多言語対応させていました。
画面説明で必要だから、売るところは多岐にわたるから、という感じです。
もともとは、完成したUIのスクリーンショットを撮れといわれやっていました。
かなりの枚数なので、英語・日本語だけならイラレからpng出力にしたほうが毎回切り貼りみたいなことをせず楽になるのでそうしたのですが、他言語対応となると話しは別です。
毎度言葉を変更して出力するなら、言語対応を実装したスクショのほうが楽では・・・となってしまう・・・
ということで、ある程度自動化しました。
イラストレータのスクリプト
イラストレータには、『スクリプト』機能があります。
上の画像だと、私が個人的に入れているフォルダまで表示されていますが、
このスクリプトを実行すると、トレースなどがショートカット的にできるということですね。
これらのスクリプトは、以下に格納されています(私の場合は)
C:\Program Files\Adobe\Adobe Illustrator CC 2017\Presets\ja_JP\スクリプト
この場所で適当なスクリプトをエディタで開けば、その中身を見ることが出来ます。
ファイルの拡張子は.jsxとなっていて、そのあたりについては下記リンクが分かりやすいです。
http://3fl.jp/d/is-howto-notice
一応引用しておくと
「JavaScript、AppleScript、ExtendScript など書かれた外部ファイル(.js や .jsx)です。Illustrator スクリプトを実行することにより、Illustrator に不足している機能を追加したり、操作の自動処理などを行うことができます。」
ということで、これを適当に自作して、自動化します。
【脱線】
JSXファイル、たくさんあるみたいなので、こちらも参考にどうぞ。
https://qiita.com/ConquestArrow/items/29fc478f48862a4d14fb
エディタ
どんなエディタで開いても問題はありませんが、Adobe Creative cloudで契約されているのであれば専用のエディタがあります。

これを使うと、開いているIllustratorやPhotoshopでテスト的に実行しながら動きを確認しならが楽しめます。
使い方みたいなのは、あえてここでは触れませんので、興味がある方は調べてみてください。
実装
やりたいことは、英語 vs XX後 の対になっている何かしらのデータを読み込んで、英語に対応する文字がヒットしたら、ついになる言葉に変更します。
置換を自動でやるドキュメント用ソフトがありますが、そのイメージです。
結果的にいくつかの制約が生まれましたが、作ることは出来ました。
try {
if (app.documents.length > 0) {
var data = [];
var targetObj = [];
// CSV Fileを選択する
fileName = File.openDialog('CSVファイルを選択してください。(Select File.)', '*.csv ', false);
fileObj = new File(fileName);
var dataFlag = fileObj.open("r");
if (dataFlag) {
var csvData = fileObj.read();
fileObj.close();
// 置換用の配列を作る
var line = csvData.split("\n");
for (k = 0; k < line.length; k++) {
var cell = line[k].split(",");
var celldata = "\^" + cell[0] + "\$"; //完全一致の文字列とする
//var celldata = cell[0]; //部分一致の文字列
//alert(celldata);
data[k] = new CellData(celldata, cell[1]);
}
//alert("data size: " + data.length);
// ドキュメント内からテキストのみを取り出す
var docObj = activeDocument;
for (var n = 0; n < docObj.pageItems.length; n++) {
typ = docObj.pageItems[n].typename;
if (typ != "TextFrame") continue; // テキスト以外は無視
targetObj.push(docObj.pageItems[n]); // 対象を格納
}
//alert(targetObj.length);
// テキストの該当文字を置換
for (var i = 0; i < targetObj.length; i++) {
//alert(targetObj[i].contents);
for (var j = 0; j < data.length; j++) {
var regSrc = new RegExp(data[j].key, "gm"); //RegExp : 正規表現を扱えるようにする
targetObj[i].contents = targetObj[i].contents.replace(regSrc, data[j].src);
}
}
}
alert("complete");
}
else { throw new Error('Documents does not open! '); }
}
catch (e) {
alert(e.message, "Error ", true);
}
/**
* キーとソースの登録クラス
* @param {any} _key key
* @param {any} _src src
*/
function CellData(_key, _src) {
this.key = _key;
this.src = _src;
}
CSVファイルからの取り込み
fileName = File.openDialog('CSVファイルを選択してください。(Select File.)', '*.csv ', false);
fileObj = new File(fileName);
var dataFlag = fileObj.open("r");
if (dataFlag) {
var csvData = fileObj.read();
fileObj.close();
この部分では、任意のCSVファイルを選択するダイアログを表示し、読み込み専用でデータを取得します。
Json形式なども考えましたが、csvなら対訳表をエクセルで作る場合に、何も考えずできるので便利です。
※ちなみに、Microsoft Excel 2016 を使用しています。UTF-8形式で保存できるところがGOODです。
置換用に配列を作る
var line = csvData.split("\n");
for (k = 0; k < line.length; k++) {
var cell = line[k].split(",");
var celldata = "\^" + cell[0] + "\$"; //完全一致の文字列とする
//var celldata = cell[0]; //部分一致の文字列
//alert(celldata);
data[k] = new CellData(celldata, cell[1]);
}
先ほど、csvDataに読み込んだcsvのファイルが格納されていますので、それを処理します。
CSVはカンマ区切りである前提ですが、リターンとカンマをトリガーに「英語,XXX語」のペア配列を作っていきます。
ここで正規表現を加えておくと、後述の検索の際に、完全一致として検索がかけられます。
ドキュメント内からテキストのみを取り出す
var docObj = activeDocument;
for (var n = 0; n < docObj.pageItems.length; n++) {
typ = docObj.pageItems[n].typename;
if (typ != "TextFrame") continue; // テキスト以外は無視
targetObj.push(docObj.pageItems[n]); // 対象を格納
}
ここが、イラストレータ独特の処理かなと思います。
この手の、ドキュメントからテキスト部分を処理するスクリプトは探せば出てくるのでほぼ使い回しです。
要するに、イラストレータの全てのデータから docObj.pageItems[n].typename で取得した、アイテムのタイプがテキスト以外のものは無視していくようにし、docObjにデータを重ねていく作業です。
全てのデータを漁るので、実行時間はデータ量に比例します。
また、グループ化やシンボル化されている場合、うまく処理できていないような気もしましたが、実用上あまり問題ないためスルーしています。
置換作業
for (var i = 0; i < targetObj.length; i++) {
//alert(targetObj[i].contents);
for (var j = 0; j < data.length; j++) {
var regSrc = new RegExp(data[j].key, "gm"); //RegExp : 正規表現を扱えるようにする
targetObj[i].contents = targetObj[i].contents.replace(regSrc, data[j].src);
}
}
アイテムが、英語の文字と「完全一致」したとき、置換を実行します。
ひとつのアイテムに対して、対訳データの全てを当たっていくわけなので、対訳データの数が多いと時間がかかります。
注意点
このソースをそのまま使うための注意点があります。
まず、文章の翻訳などにはまったく向いていません。
単語レベルで出来る『機能名』などの変換のために作られています。
また、完全一致をさせるようにしています。
理由としては、これは対訳データを作る際の順番次第でもあるんですが、部分一致で実装すると
Name という単語を名前と変換する対訳があった場合、Model NameはModel 名前で変換されてしまい
Model Name,モデル名と いうデータがあっても、それは変換できません。
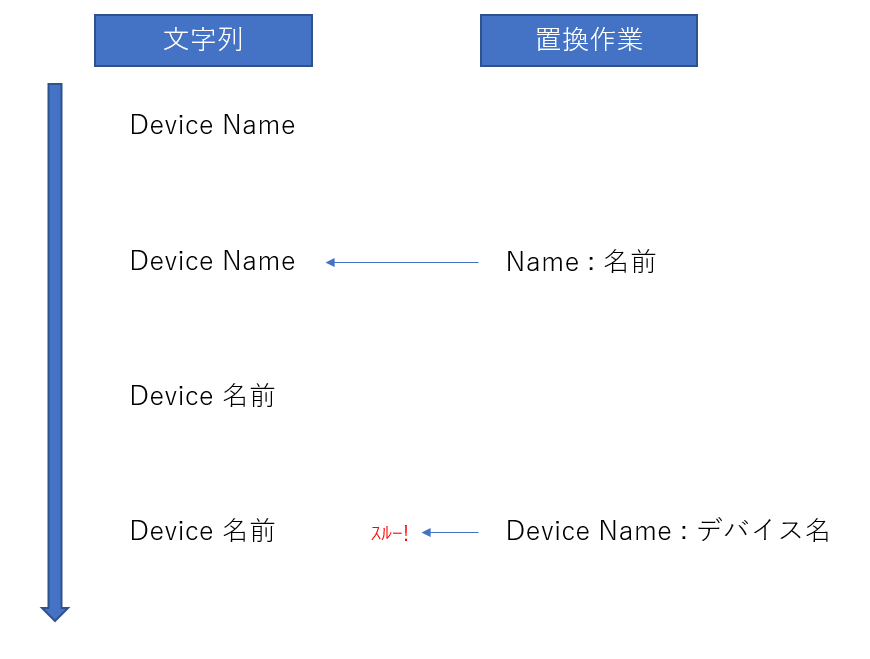
扱うワードの数が増えれば増えるほど、この辺が衝突してしまったので、完全一致にしています。
また、なん10ページもあると、普通にしばらくフリーズしますので、小規模に切り分ける必要があります。
完全に私の用途に対するオーダーメイドの部分が多いですが、要所要所の置換作業やアイテム抽出の部分が、他に転用できれば幸いかと思います。