今回データエンジニア向け「データブリックス4日間集中トレーニング」こちらに参加させていただきました。
そこで知ったDatabricksの強みや業務イメージ等を共有出来たらいいなと思います。
Day1-3 ETLしてテーブルを作成する
Day1-3では様々なデータを収集、処理しテーブルにするという流れについてをトレーニングしました。
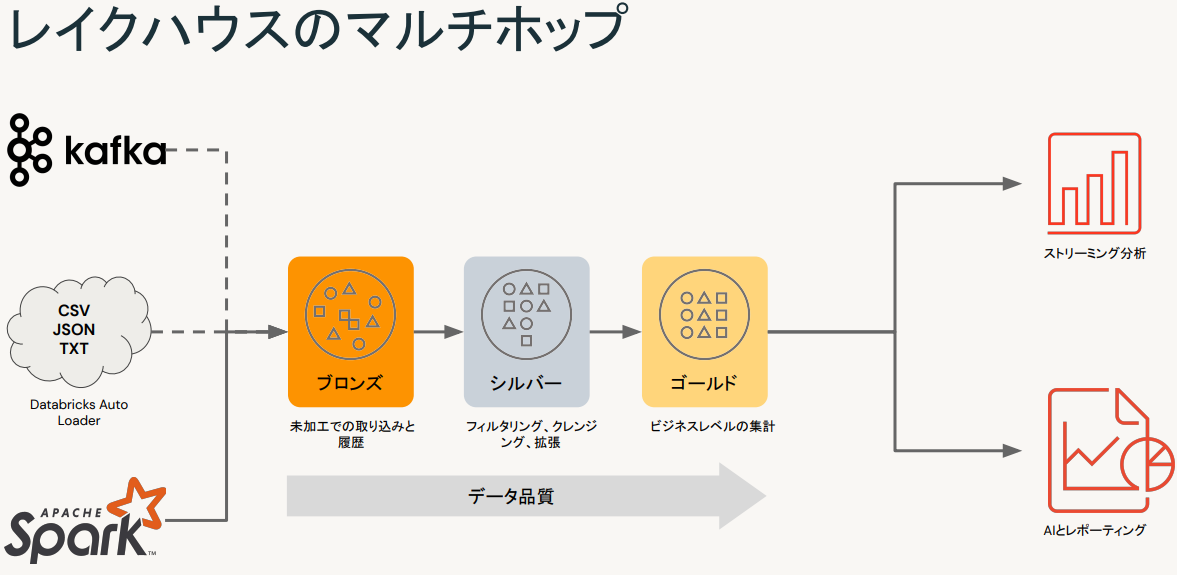
Databricksでは、多くのストレージサービスにあるファイルを取り込むことができます。(ブロンズレイヤー)
そのデータの複雑性、レイテンシ、冗長性を減らしたり、重複レコードを排除するなど扱いやすいように処理します(シルバーレイヤー )
その後それらのデータを結合して業務に利用できるようなデータを作成するという流れを行えます。(ゴールドレイヤー)
通常ファイルのようなデータを継続的に取り込んでいると、エラーが出た際にゴミデータが発生し問題が出てしまいます。
Databricksではトランザクションを設けることでファイルシステムでもゴミファイルが出ずに安心して利用することができます。
さらに、継続的に読み込むAutoloaderでは動作の可視化を行うこともできます。
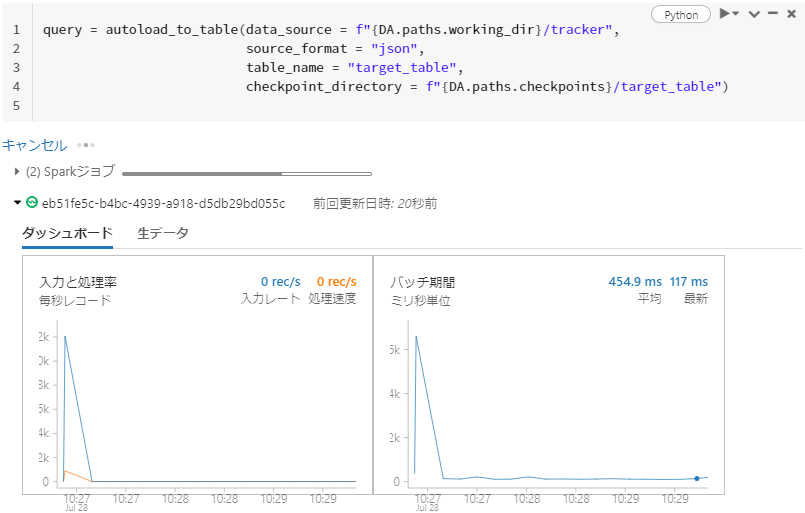
これらの継続的に行う処理についてはノートブックで処理内容を記述することができます。
ノートブックには過去の編集者や履歴、ロールバックも行えるのでコードの安全性も高いです。
定期実行はワークフローによって管理できます。
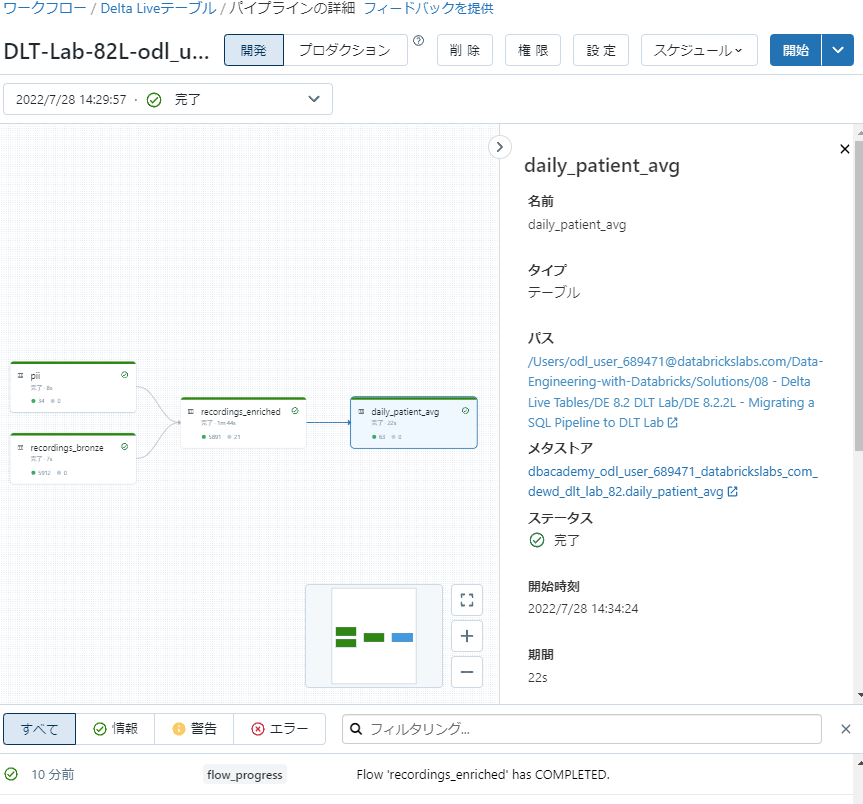
ワークフローでは、UI上でノートブックを指定し、そのノートブックにある処理の内容を指定したストレージの場所からデータを取得し、処理を実行、ターゲットのDBに書き出すことが可能です。
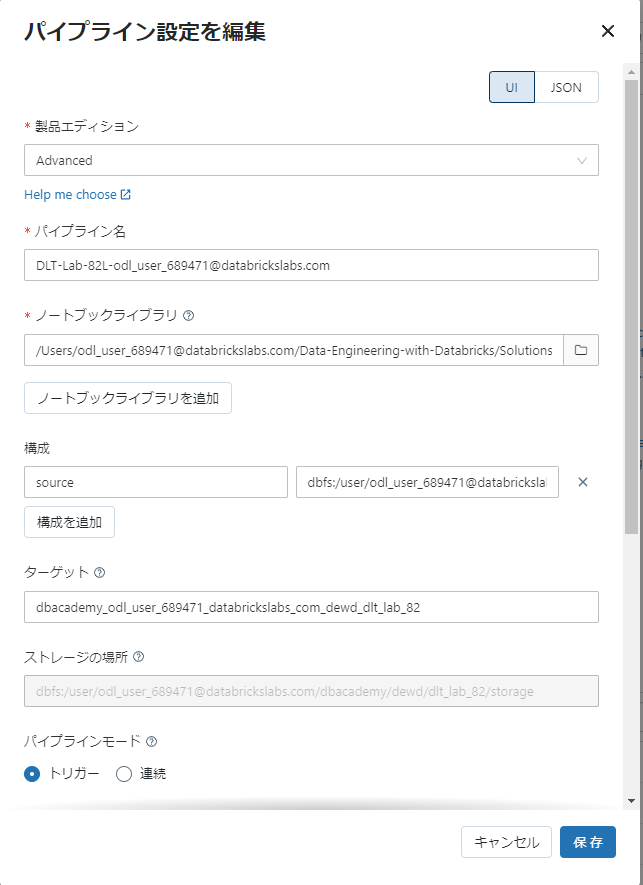
このように現在の処理の内容や進捗、エラーを視覚的に理解することが可能です。
Day4 SQLウェアハウス
Day4では先日までに作成したデータをアナリストがDWH的に分析することを考えたトレーニングとなっていました。
データの可視化にはダッシュボードを利用します。こちらにはクエリしたデータを用いて様々な方法で可視化を行うことができます。
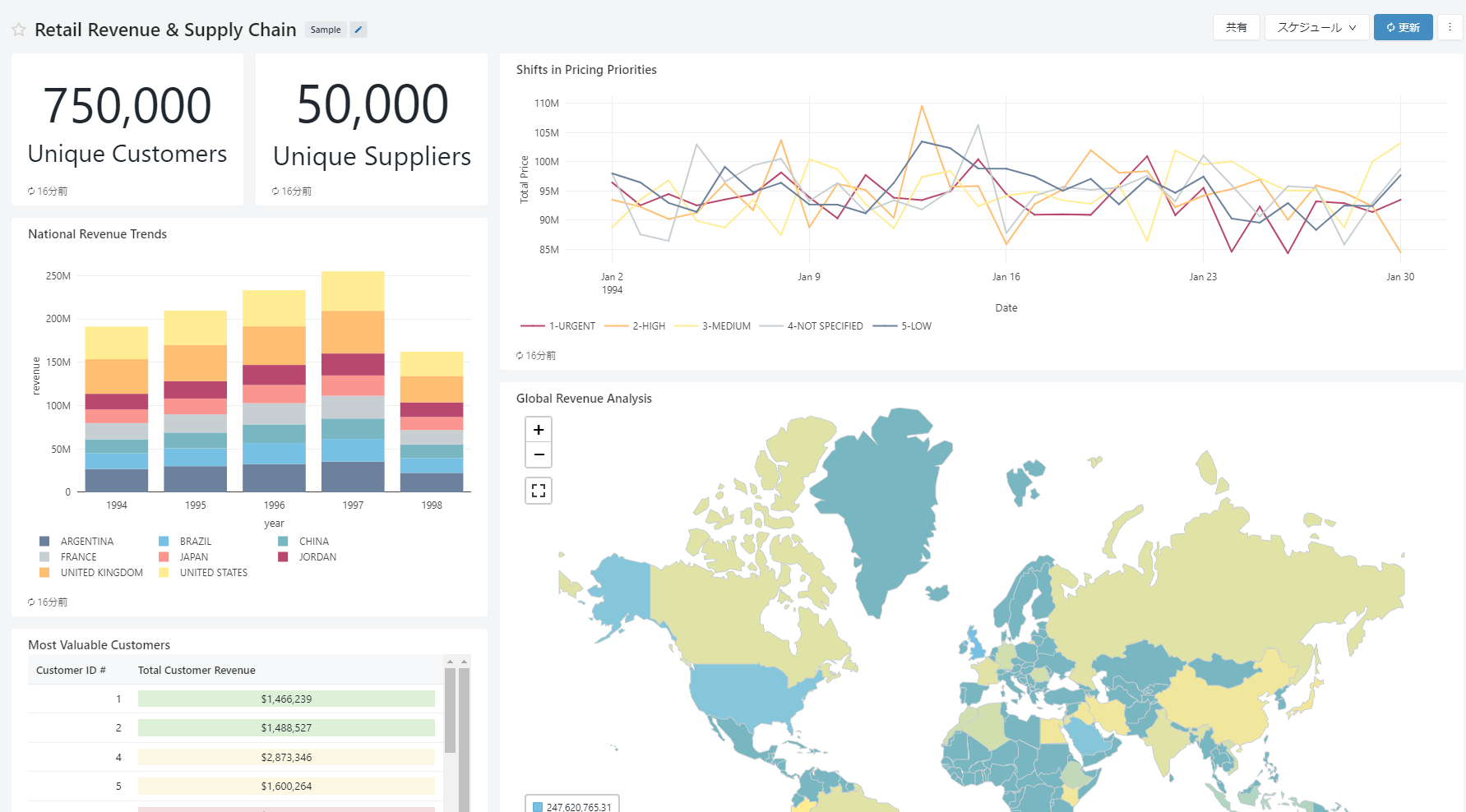
グラフの内容やクエリの内容はユーザーが作成、編集することができます。
グラフを新規に追加する際または変更する際に直接SQLを記述することができます。
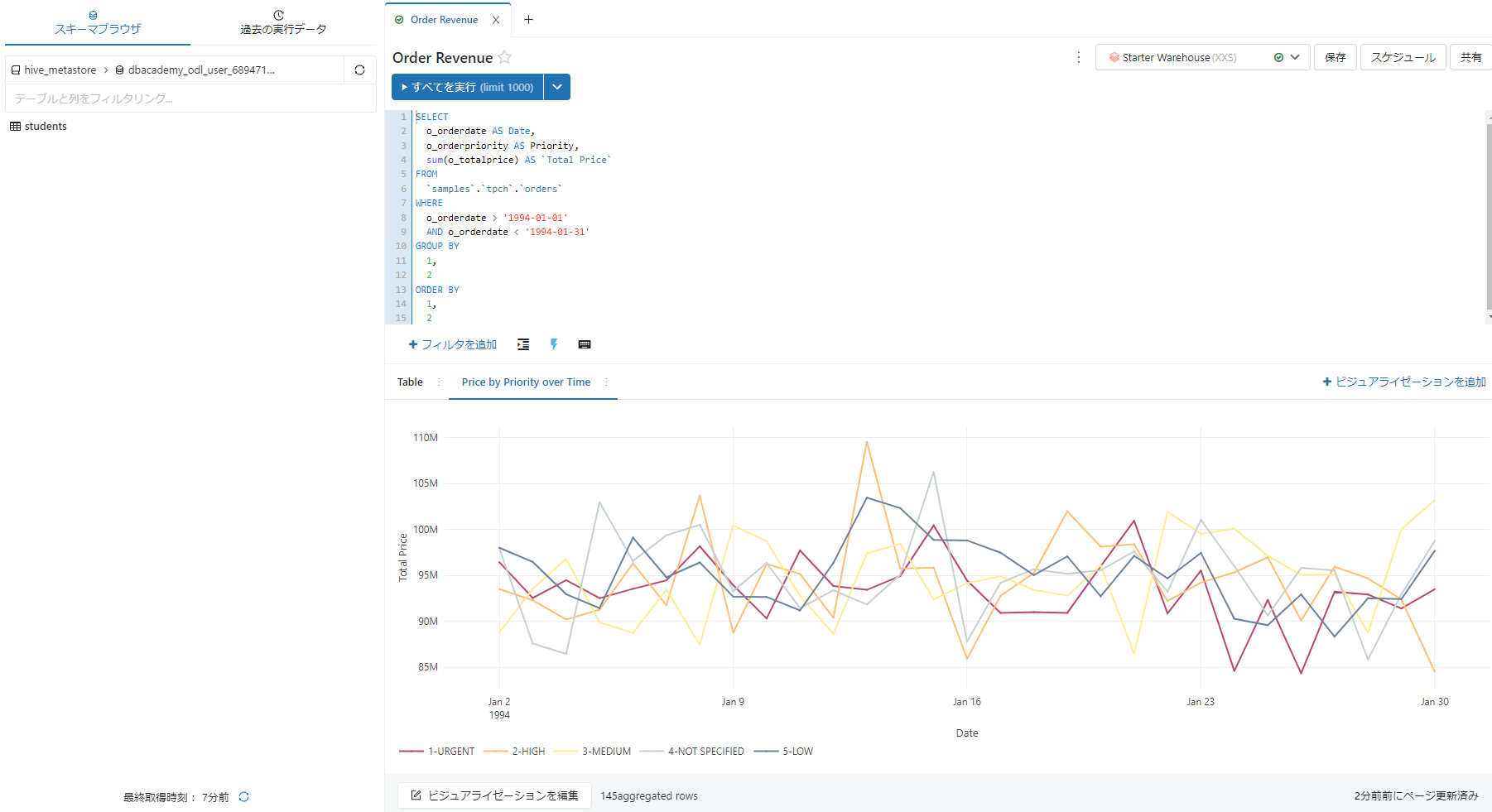
グラフについても編集可能で、利用するデータやグラフの形式など自由に編集可能です。
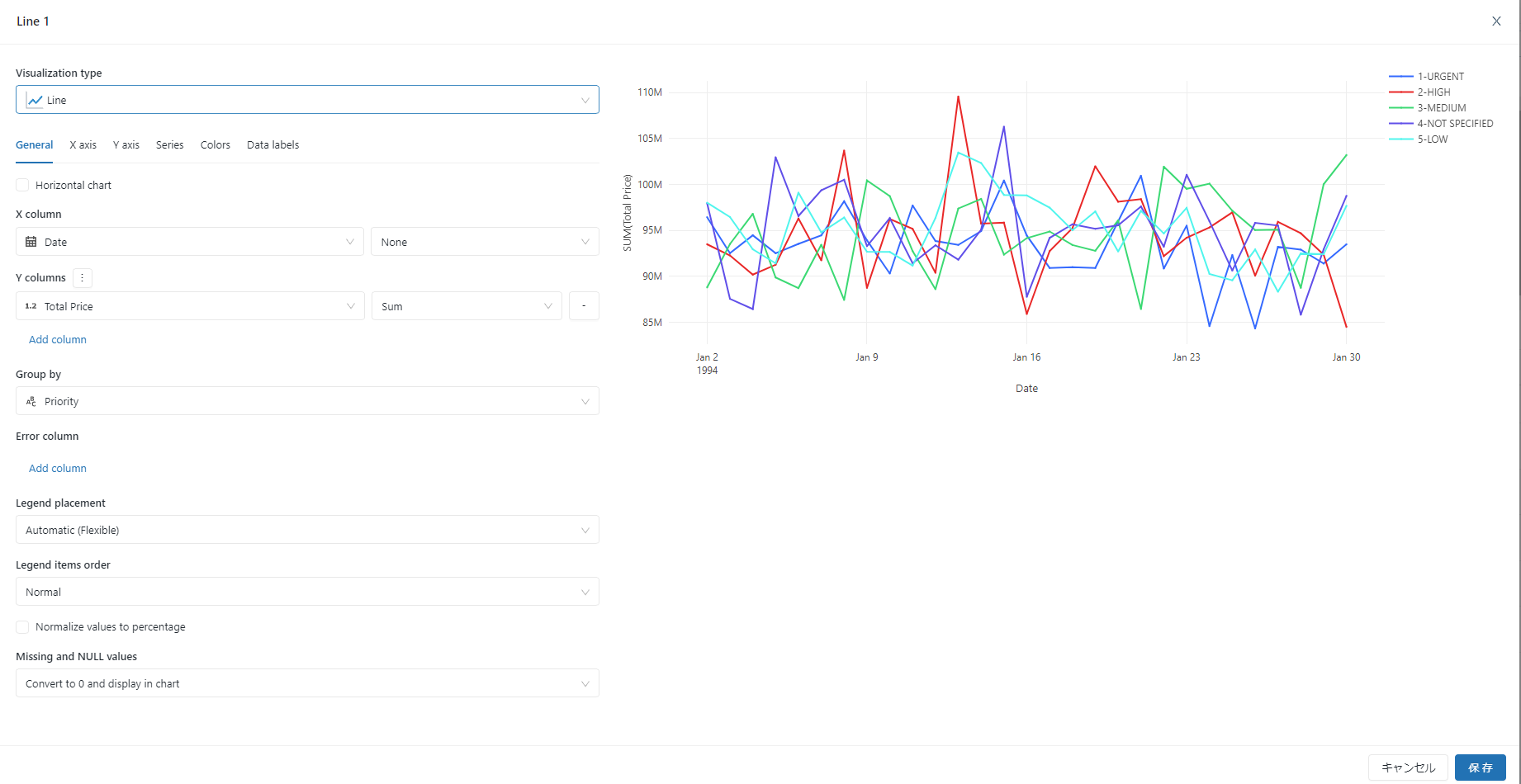
このダッシュボードはほかユーザーと共有することができ、権限によっては共同編集することもできるようです。
また、ダッシュボードの更新等も先述のワークフローに組み込むことができるので自動で更新することも可能ですね。
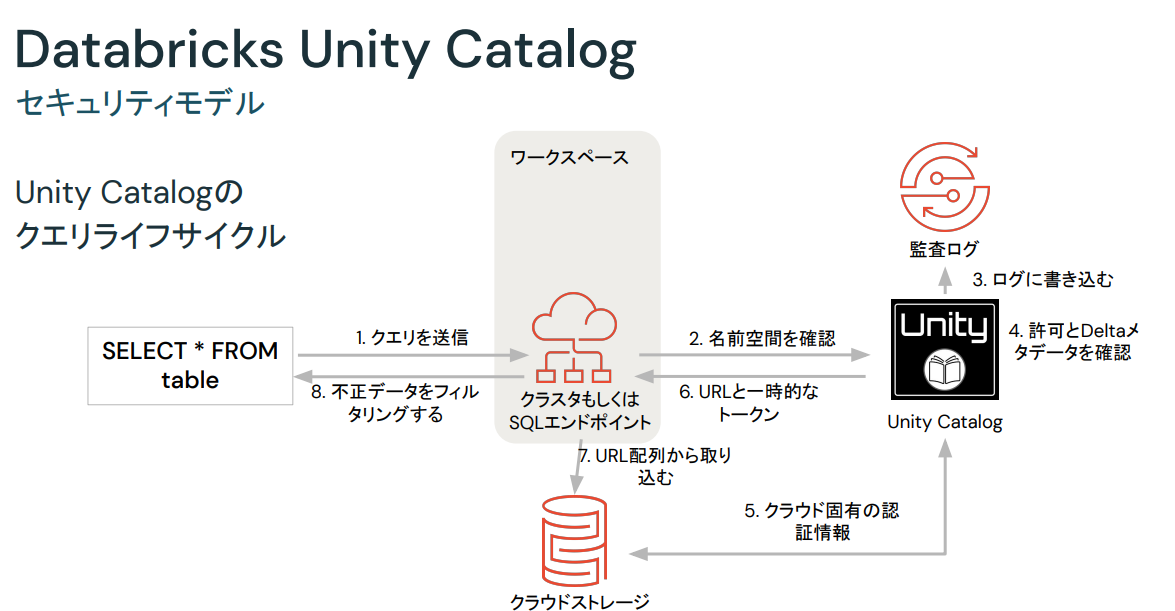
## Unity Catalog
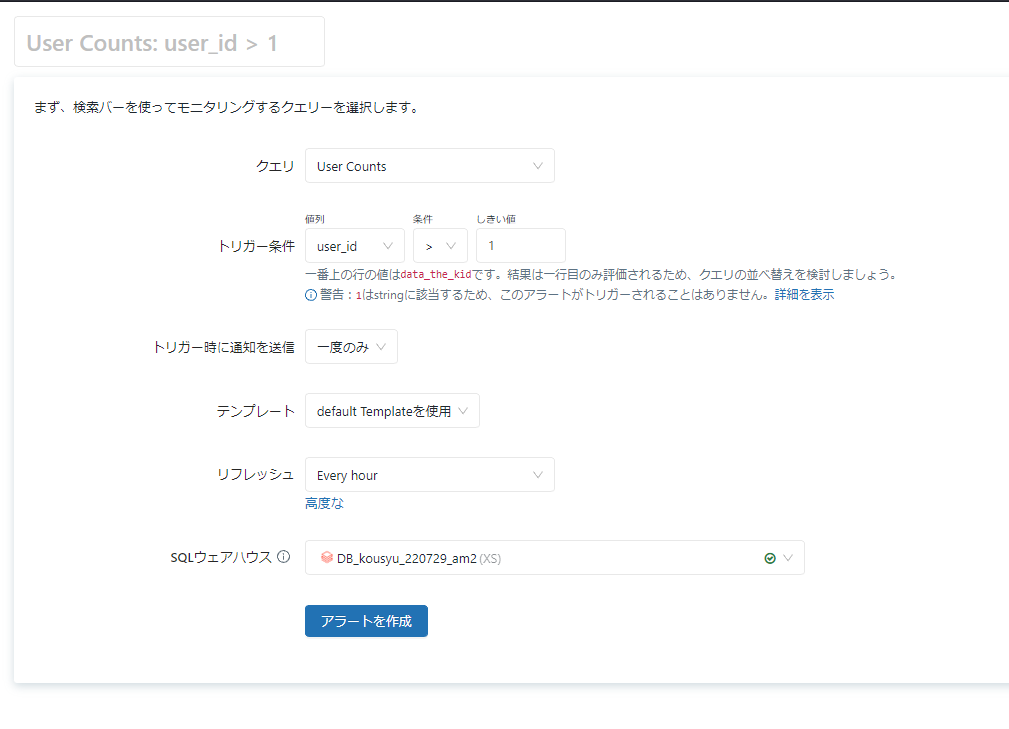
Unity Catalogを利用することで異常なデータのばあいアラートを出すことができ、不正データ等をはじくことができます。
設定には監視するウェアハウス、クエリの内容、アラートの閾値などを指定することで簡単に設定できます。
まとめ
今回データブリックス4日間集中トレーニングに参加したことで漠然としたデータレイクによる利点についてが少し明確になったかなと思います。
あらゆるところに散在するファイルデータを一つのプラットフォームで集約管理、利用できるという点が大きな特徴なのかなと思います。
その管理についてもノートブックにより安全にわかりやすい形でできますし、結果としてできたデータの運用につても自動化や可視化等行えるところがいい部分だと感じました。
今後はこれらで使ったデータをML等に生かしていく流れなどを学ぶことができたらいいなと思いました。