一、はじめに
scrapyとは、、Pythonで書かれた無料のオープンソースのWebクロールフレームワークです。
今、ユーザーランキングの週間のTOP1のユーザが@shimajiri さんです。
これからはpython3+scrapyを使って@shimajiri さんのすべての記事を収集してみよう。
二、事前準備
1.環境構築:
- OS:Windows 10
- 言語:python 3.7.4
- フレームワーク:scrapy 1.7.3
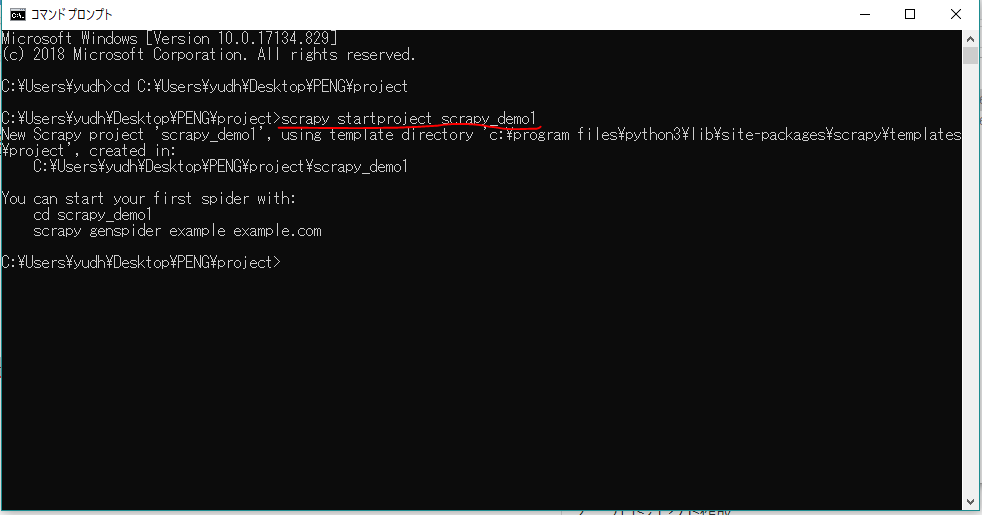
2.プロジェクト作成
以下のコマンドでプロジェクトを作ろう。
scrapy startproject scrapy_demo1
三、ソース実装
1.items.pyの実装
今回は主に記事のdate、title、urlなどの情報を収集するため、それらの情報を基に、itemのクラスを作ろう
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyDemo1Item(scrapy.Item):
# define the fields for your item here like:
# 日時
date = scrapy.Field()
# タイトル
title = scrapy.Field()
# URL
url = scrapy.Field()
2.spider_demo1.pyの実装
spider_demo1.pyとは、ターゲットURLをクロールして、情報を抽出し、解析すること。
まずは、scrapy_demo1\spidersのフォルダに入って以下のコマンドでspider_demo1.pyを作成する
scrapy genspider -t basic spider_demo1 qiita.com
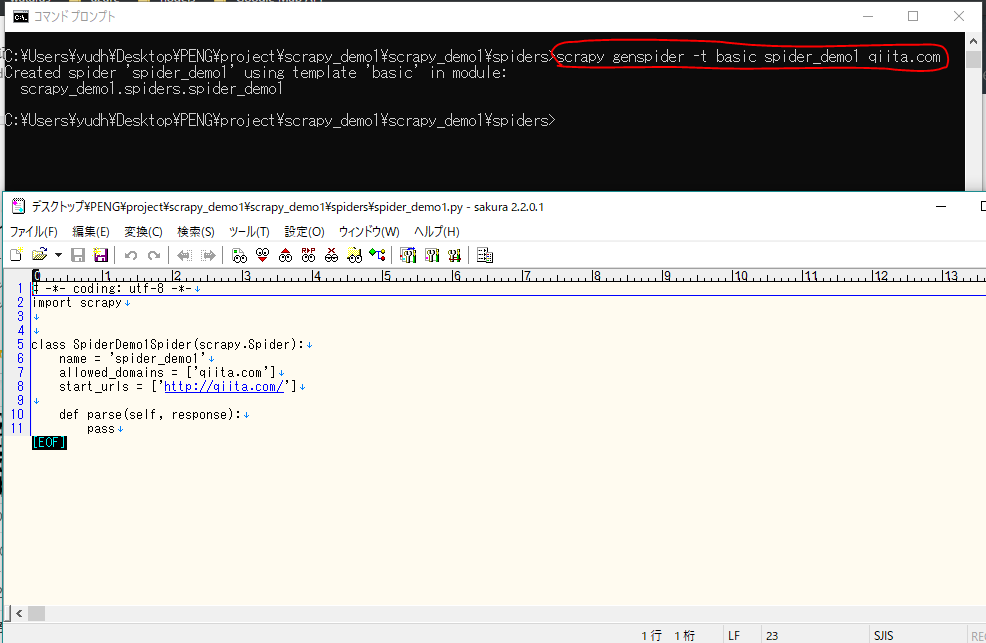
こらから、spider_demo1.pyの業務流れを理解し、実装します。
Target Urlはこちらです。ブラウザで開いて、F12のDEBUGモードで画面の構造がわかることになります。
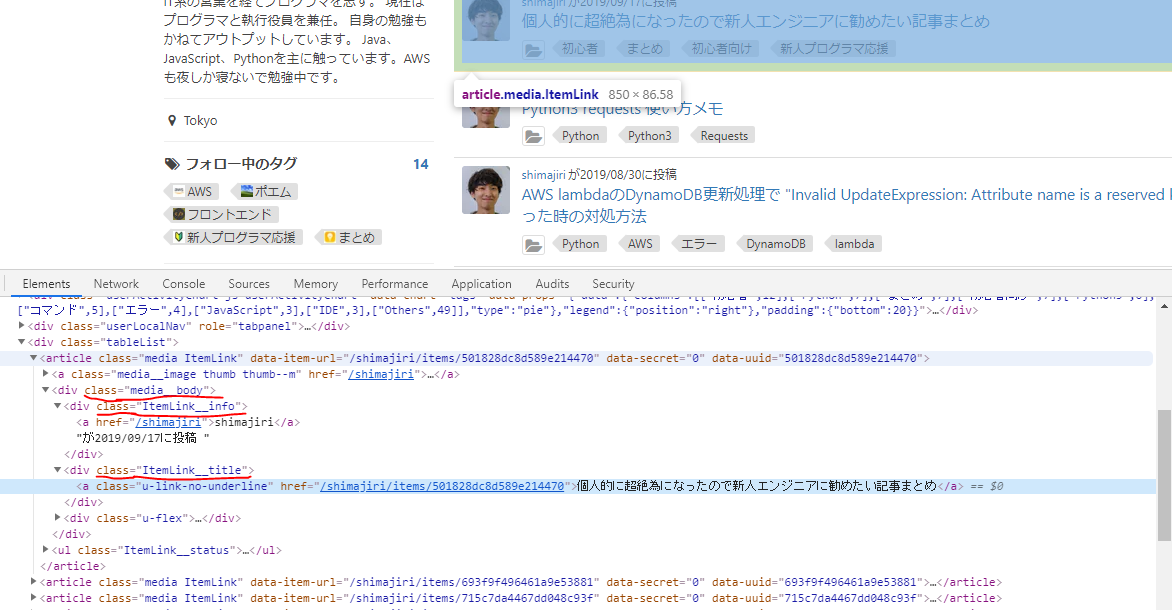
だから、実装を続いて、主にparseメソッドを実装する、最後に以下のようにします。
xpathの使い方はこちらで参考しましょう。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#import sys
#reload(sys)
#sys.setdefaultencoding("utf-8")
import scrapy
from scrapy_demo1.items import ScrapyDemo1Item
class SpiderDemo1Spider(scrapy.Spider):
# Spiderの名前(必須)
name = "spider_demo1"
# 対象ホスト
allowed_domains = ["qiita.com"]
# 対象URLリスト
start_urls = ["https://qiita.com/shimajiri?page=2","https://qiita.com/shimajiri",]
def parse(self, response):
node_list = response.xpath("//article[@class='media ItemLink']")
print("node_list--------------:",node_list)
for node in node_list:
# itemクラスのインスタンスを作り、収集した情報をここに保存
item = ScrapyDemo1Item()
# .extract()で 内容をUnicode文字に転換
url = node.xpath("./div[@class='media__body']/div[@class='ItemLink__title']/a/@href").extract()
date = node.xpath("./div[@class='media__body']/div[@class='ItemLink__info']/text()").extract()
title = node.xpath("./div[@class='media__body']/div[@class='ItemLink__title']/a/text()").extract()
# 日時
item['date'] = date[0]
# タイトル
item['title'] = title[0]
# リンク
item['url'] = "https://qiita.com" + url[0]
# itemのデータをpipelines.pyクラスに渡し、次の処理を続け
yield item
3.pipelines.pyの実装
pipelines.pyクラスとは、SpiderDemo1Spiderからの情報(item)をファイルに書き出す。
以下のようにします。実行すれば、収集したデートはscrapydemo1_data.jsonに保存すべきだ。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class ScrapyDemo1Pipeline(object):
def __init__(self):
self.f = open("scrapydemo1_data.json", "w")
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii = False) + ", \n"
self.f.write(content)
return item
def close_spider(self, spider):
self.f.close()
ここまで、すべての製造が終わる
四、実行結果
まあ、プロジェクトの下にdataフォルダを作って、以下のコマンドでプロジェクトを実行してみよう。
scrapy crawl spider_demo1
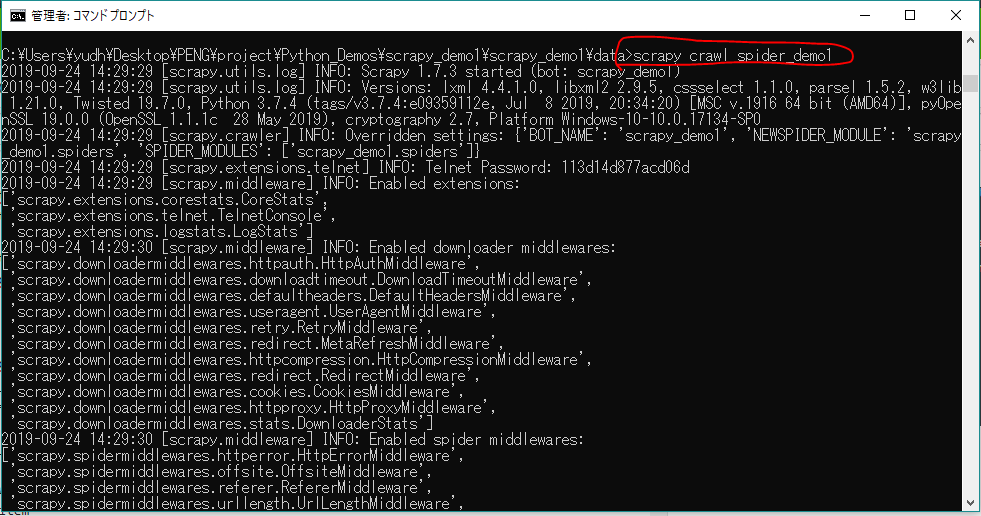
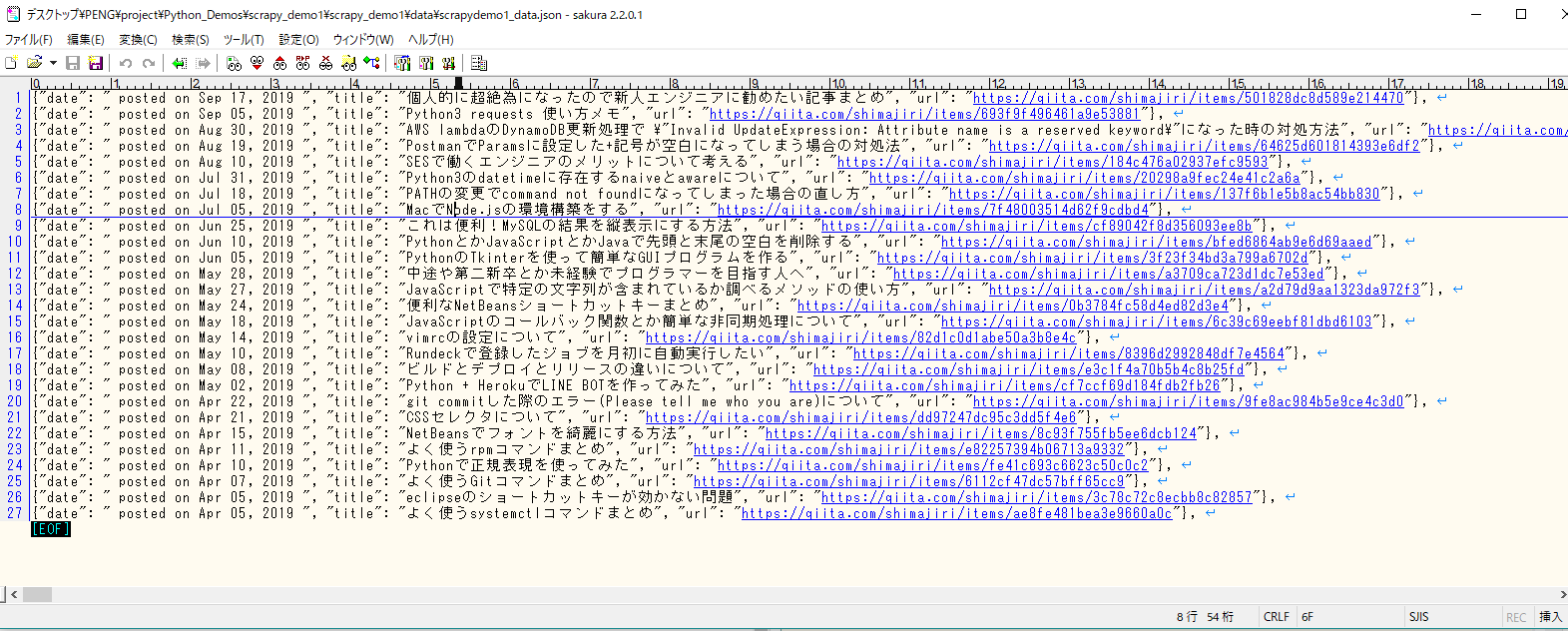
問題なければ、scrapydemo1_data.jsonを生成し、その中で@shimajiri さんのすべての記事を収集するはずです。
結果は下記のように出力されます。記事が全部で27件となります。
五、最後に
最後まで読んでいただき、ありがとうございます。
@shimajiri さん、ご迷惑をかけましたら、申し訳ございません。
ソースコードはこちらでダウンロード可能です