1. 開発背景と概要
1.1 背景
先月ある会社の説明会に参加した時、「フットワークが軽い」という単語が出て、その意味を調べました。前日もう一つの会社の説明会で同じ単語に出会ったんですけどどうしてもその意味を思い浮かべませんでした。
仕方なくもう一度調べましたが、その時ふっとこう思いました:
「同じ単語を何度も調べるなんて、時間的にもったいないじゃないですか。
一度調べた単語を自動的に収集され、随時復習できるようなシステムを作るのはどうですか」
そこでLangChainを活用して、「単語帳自動生成エージェント」を作ることにしました。
1.2 概要
このプロジェクトは、日本語単語を入力すると自動で単語帳を生成するエージェントです。
ユーザが知らない日本語単語を入力すると、エージェントが事前に定まった構造に従って以下の4項目を出力します:
(1) 単語
(2) 中国語の意味
(3) 日本語の意味
(4) その単語を使った日本語の例文
その後、生成された結果は自動的に
・Markdown ファイル(単語帳)に追記される
・PostgreSQL データベースにも保存される
さらに、LangChainのRunnableWithMessageHistoryを利用しているため、エージェントが会話の履歴を記憶できており、文脈を踏まえた応答が可能になります。
2. コード全体
import os
from dotenv import load_dotenv
import datetime as dt
# ========== LangChain関連 ==========
from langchain.chat_models import init_chat_model
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableWithMessageHistory
# ========== データベース関連 ==========
from sqlalchemy import create_engine, text
from sqlalchemy.engine import Engine
# ========== 追加機能関連 ==========
from typing import Dict, Any
from langchain_core.pydantic_v1 import BaseModel, Field
# .envファイルを読み込む
load_dotenv()
# 出力先Markdownファイル(環境変数から取得。なければデフォルトパス)
OUTPUT_MD_PATH = os.getenv("OUTPUT_MD_PATH", "./vocab_notes.md")
# PostgreSQL接続情報
PG_DSN = os.getenv("PG_DSN")
# データベース初期化
def ensure_table(engine: Engine):
"""
単語テーブルを作成(存在しない場合のみ)。
"""
ddl = """
CREATE TABLE IF NOT EXISTS vocab (
id SERIAL PRIMARY KEY,
word TEXT NOT NULL UNIQUE,
zh_meaning TEXT NOT NULL,
jp_meaning TEXT NOT NULL,
example_jp TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
)
"""
with engine.begin() as conn:
conn.execute(text(ddl))
engine = create_engine(PG_DSN, pool_pre_ping=True, future=True)
ensure_table(engine)
# 構造化出力モデル
class VocabEntry(BaseModel):
word: str = Field(..., description="ユーザーが入力した日本語単語(標準表記)")
zh_meaning: str = Field(..., description="正確で簡潔な中国語の意味")
jp_meaning: str = Field(..., description="自然で簡潔な日本語の意味")
example_jp: str = Field(..., description="その単語を含む自然な日本語の例文")
# LLMモデルの初期化
llm = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key="sk-fc3eee78f40749e4babd382ad0c5516c",
base_url="https://api.deepseek.com/v1"
)
# プロンプトテンプレート
prompt = ChatPromptTemplate.from_messages([
("system", """
あなたは日本語と中国語に精通した言語エキスパートです。\n
出力は必ず指定フォーマットに従い、正確さ・自然さ・簡潔さを重視してください。\n
要件:ユーザーが入力した日本語単語に対して、次の4つの情報を返してください。\n
1) 単語, 2) 中国語の意味, 3) 日本語での解釈, 4) その単語を使った自然な例文\n
例文は自然で日常的な文体を使用してください。\n
複数の意味がある場合は、最も一般的で通用する意味を選び、日本語と中国語両方の意味を一致させてください。\n
"""),
MessagesPlaceholder("history"),
("human", """
わからない単語:{word}\n
出力は必ず以下のフィールドで返してください:word / zh_meaning / jp_meaning / example_jp\n
""")
])
# モデル出力を構造化形式(VocabEntry)に変換
llm_structured = llm.with_structured_output(VocabEntry)
# ========== Markdown出力関連 ==========
def render_markdown(entry: VocabEntry) -> str:
"""
Markdown形式で語彙ノートを作成
"""
ts = dt.datetime.now().strftime("%Y-%m-%d %H:%M")
md = (
f"### {entry.word}\n"
f"- **中文释义**:{entry.zh_meaning}\n"
f"- **日本語の意味**:{entry.jp_meaning}\n"
f"- **例文**:{entry.example_jp}\n"
f"<sub>追加時間:{ts}</sub>\n\n"
"---\n\n"
)
return md
def append_markdown(md_text: str):
"""
Markdownファイルに追記する('a'はappend=追記モード)
"""
with open(OUTPUT_MD_PATH, "a", encoding="utf-8") as f:
f.write(md_text)
# PostgreSQLへの挿入
def insert_pg(engine: Engine, entry: VocabEntry):
"""
語彙データをPostgreSQLに挿入
"""
sql = text("""
INSERT INTO vocab (word, zh_meaning, jp_meaning, example_jp)
VALUES (:word, :zh, :jp, :ex)
RETURNING id, created_at
""")
with engine.begin() as conn:
row = conn.execute(sql, {
"word": entry.word.strip(),
"zh": entry.zh_meaning.strip(),
"jp": entry.jp_meaning.strip(),
"ex": entry.example_jp.strip(),
}).mappings().first()
return dict(row)
core_chain = (
prompt
| llm_structured
)
# Memory管理
_session_store: Dict[str, InMemoryChatMessageHistory] = {}
def get_session_history(session_id: str) -> InMemoryChatMessageHistory:
"""
セッションIDごとに履歴を保持する
"""
if session_id not in _session_store:
_session_store[session_id] = InMemoryChatMessageHistory()
return _session_store[session_id]
# RunnableWithMessageHistoryでMemoryを有効化
chain = RunnableWithMessageHistory(
core_chain,
get_session_history,
input_messages_key="word",
history_messages_key="history"
)
def main():
print("✅ 日本語アシスタントを起動しました")
sid = input("会話ID(継続対話の場合は同じIDを使用): ").strip() or "default"
print("exit / quit で終了します。\n")
engine = create_engine(PG_DSN, pool_pre_ping=True, future=True)
while True:
w = input("日本語の単語を入力してください:").strip()
if w.lower() in {"exit", "quit"}:
print("👋 終了します。")
break
try:
resp = chain.invoke(
{"word": w},
config={"configurable": {"session_id": sid}}
)
# Markdownに追記 & DBに挿入
append_markdown(render_markdown(resp))
insert_pg(engine, resp)
print(f"✅ {w} を記録しました。\n")
except Exception as e:
print("⚠️ エラーが発生しました:", e, "\n")
if __name__ == "__main__":
main()
3. 機能ごとの解説
3.1 Agentの組み立て
3.1.1 構造化出力の定義
class VocabEntry(BaseModel):
word: str = Field(..., description="ユーザーが入力した日本語単語(標準表記)")
zh_meaning: str = Field(..., description="正確で簡潔な中国語の意味")
jp_meaning: str = Field(..., description="自然で簡潔な日本語の意味")
example_jp: str = Field(..., description="その単語を含む自然な日本語の例文")
PydanticのBaseModelを使って、構造化出力(Structured Output)を定義します。ここで二つのポイントがあります:
・ with_structured_output(VocabEntry) を使うことで、「必ずこのスキーマ合う形で出力せよ」をモデルに伝える
・ descriptionという指示ヒントを書くことで、曖昧な出力を減らせる
3.1.2 LLM の定義
llm = init_chat_model(
model="deepseek-chat",
model_provider="deepseek",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1"
)
llm_structured = llm.with_structured_output(VocabEntry)
モデルはDeepseekだけではなく、OpenAIといったモデルも使用できます。ただし1tokenあたりの費用として、OpenAIは約Deepseekの11~12倍になっているので、個人学習であまりお金費やしたくない方はDeepseekのほうがおすすめです。
3.1.3 プロンプト設計
prompt = ChatPromptTemplate.from_messages([
("system", """
あなたは中日両方の語彙に精通した言語エキスパートです。
出力は必ず指定フォーマットに従い、正確さ・自然さ・簡潔さを重視してください。
要件:ユーザーが入力した日本語単語に対して、
1) 単語, 2) 中国語の意味, 3) 日本語の意味, 4) その単語を使った自然な例文 を返してください。
複数の意味がある場合は、最も一般的な意味を選び、中日で意味の整合性を取ってください。
"""),
MessagesPlaceholder("history"), # ← RunnableWithMessageHistory が差し込む会話履歴
("human", """
わからない単語:{word}
出力は必ず以下のフィールドで返してください:word / zh_meaning / jp_meaning / example_jp
""")
])
ここでのポイントは:
・ MessagesPlaceholder("history")により、前回までの対話の履歴をプロンプトへ挿入できる
・ プロンプトを書くとき、箇条書き + 明確さが大事である
3.2 データベースとの連携
3.2.1 接続とテーブルの用意
PG_DSN = os.getenv("PG_DSN") # 例: postgresql+psycopg2://user:pass@host:5432/db
engine = create_engine(PG_DSN, pool_pre_ping=True, future=True)
def ensure_table(engine: Engine):
"""
語彙テーブルが無ければ作成する。
UNIQUE(word) により同一語の重複登録を防止。
"""
ddl = """
CREATE TABLE IF NOT EXISTS vocab (
id SERIAL PRIMARY KEY,
word TEXT NOT NULL UNIQUE,
zh_meaning TEXT NOT NULL,
jp_meaning TEXT NOT NULL,
example_jp TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
)
"""
with engine.begin() as conn: # ← トランザクション開始
conn.execute(text(ddl)) # ← DDL 実行(既存なら no-op)
ここでのengineは、コードとデータベースをつなぐ「かけ橋」に相当し、engineを操作することでテーブルのcreate, insertなどができます。
3.2.2 新規単語のinsert処理
def insert_pg(engine: Engine, entry: VocabEntry):
"""
語彙データを1行挿入し、生成された id / created_at を返す。
失敗時(UNIQUE制約違反など)は例外が発生するため呼び出し側でハンドリング。
"""
sql = text("""
INSERT INTO vocab (word, zh_meaning, jp_meaning, example_jp)
VALUES (:word, :zh, :jp, :ex)
RETURNING id, created_at
""")
with engine.begin() as conn: # ← 自動コミットされるスコープ
row = conn.execute(sql, {
"word": entry.word.strip(),
"zh": entry.zh_meaning.strip(),
"jp": entry.jp_meaning.strip(),
"ex": entry.example_jp.strip(),
}).mappings().first()
return dict(row)
ここでの**engine.begin()**は、トランザクションを新たに作るという意味で、engine.begin()以内の操作の「原子性」が担保されます。
**.mapping()**は、クエリの結果を辞書型に変換することで、属性での訪問をできるようにします。
**.first()**は、クエリの結果の一行目だけを返すことを意味します。何も検索できなかった時はNoneを返します。
3.3 Markdownへの書き込み
# 追加のテキストを作成する
def render_markdown(entry: VocabEntry) -> str:
"""
単語カードを Markdown 断片に変換。
Markdown テーブルにしたい場合はここを書き換えればOK。
"""
ts = dt.datetime.now().strftime("%Y-%m-%d %H:%M")
md = (
f"### {entry.word}\n"
f"- **中文释义**:{entry.zh_meaning}\n"
f"- **日本語の意味**:{entry.jp_meaning}\n"
f"- **例文**:{entry.example_jp}\n"
f"<sub>追加時間:{ts}</sub>\n\n"
"---\n\n"
)
return md
# 追加のテキストを書き込む
def append_markdown(md_text: str):
"""
'a' は append(追記)モード。
既存のノートを壊さず、末尾に次々と語彙カードを追加していく。
"""
with open(OUTPUT_MD_PATH, "a", encoding="utf-8") as f:
f.write(md_text)
3.4 メモリ化
_session_store: Dict[str, InMemoryChatMessageHistory] = {}
def get_session_history(session_id:str) -> InMemoryChatMessageHistory:
if session_id not in _session_store:
_session_store[session_id] = InMemoryChatMessageHistory()
return _session_store[session_id]
chain = RunnableWithMessageHistory(
core_chain,
get_session_history,
input_messages_key="word",
history_messages_key="history"
)
LangChainのRunnableWithMessageHistoryを使うことで会話の文脈を保持します。
get_session_history 関数は、指定されたセッションIDの履歴がなければ新しく作成し、既にあれば既存の履歴オブジェクトを返します。
input_messages_key は、ユーザからの入力 を前に作成したプロンプトのどのplaceholderに使うかを指定します。
history_messages_key は、今まで対話の履歴 を前に作成したプロンプトのどのplaceholderに使うかを指定します。
4. デモ
「八つ当たり」「快勝」を入力してみます。

vocab_agent.mdを確認したところ、無事書き込みがされました。
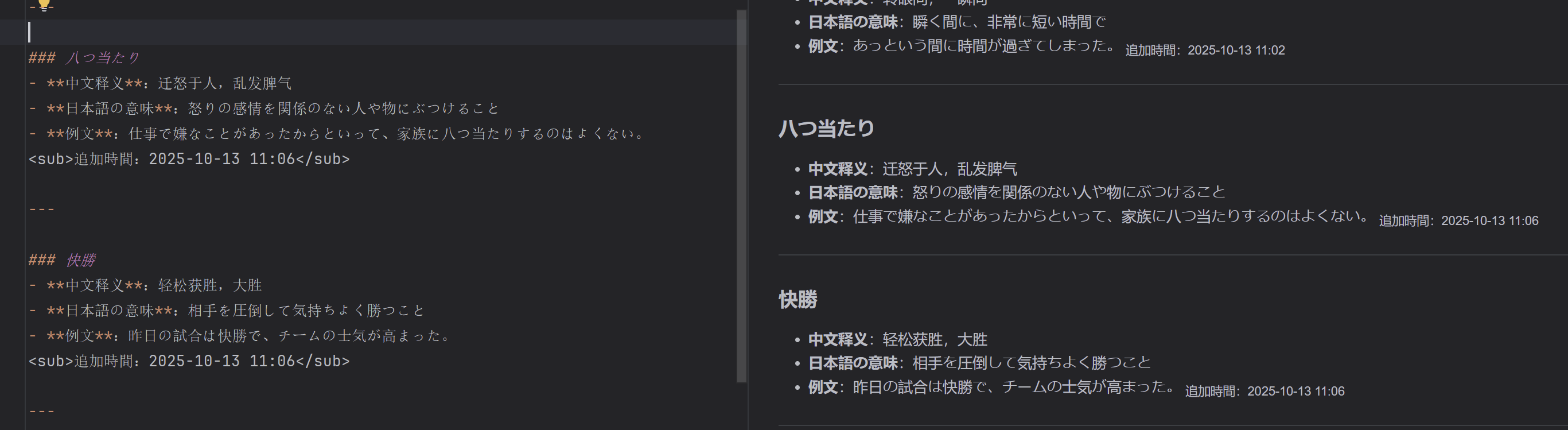
そしてデータベースのほうも確認します。
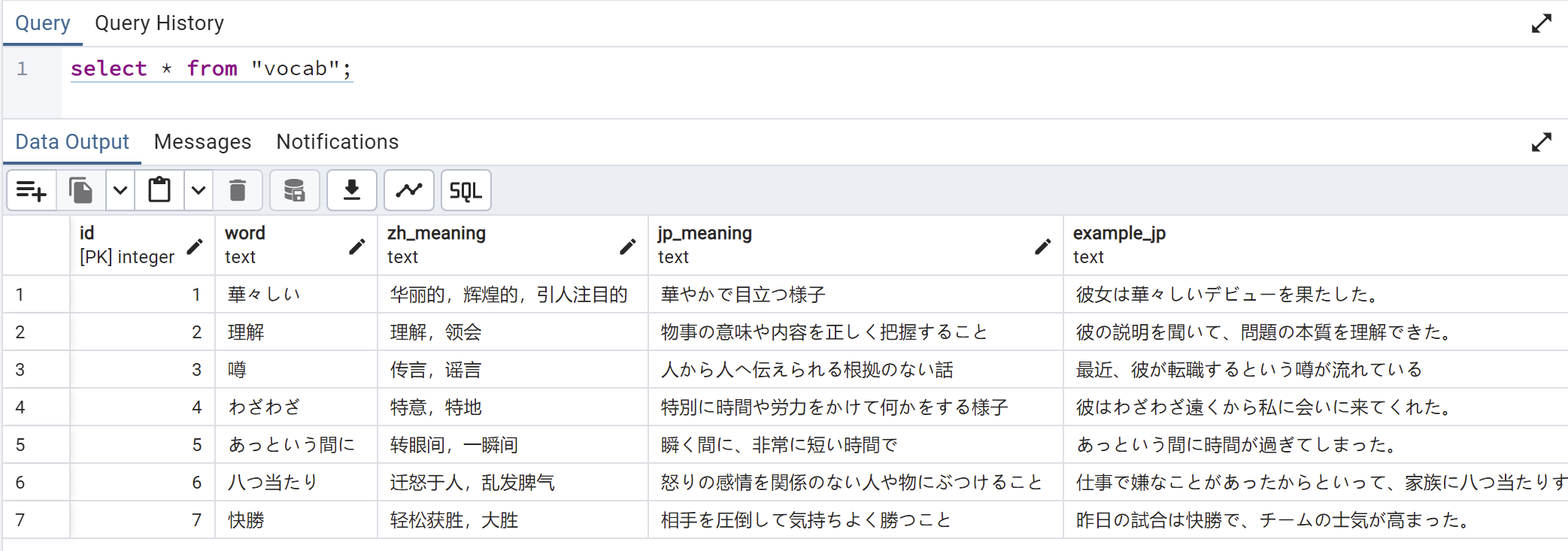
確かにDBのほうも無事追加されましたね🙂