前置き
のCode Example 1を動かしてみる。
※ソースコードの要所要所にコメント残してみた。
ソースコード
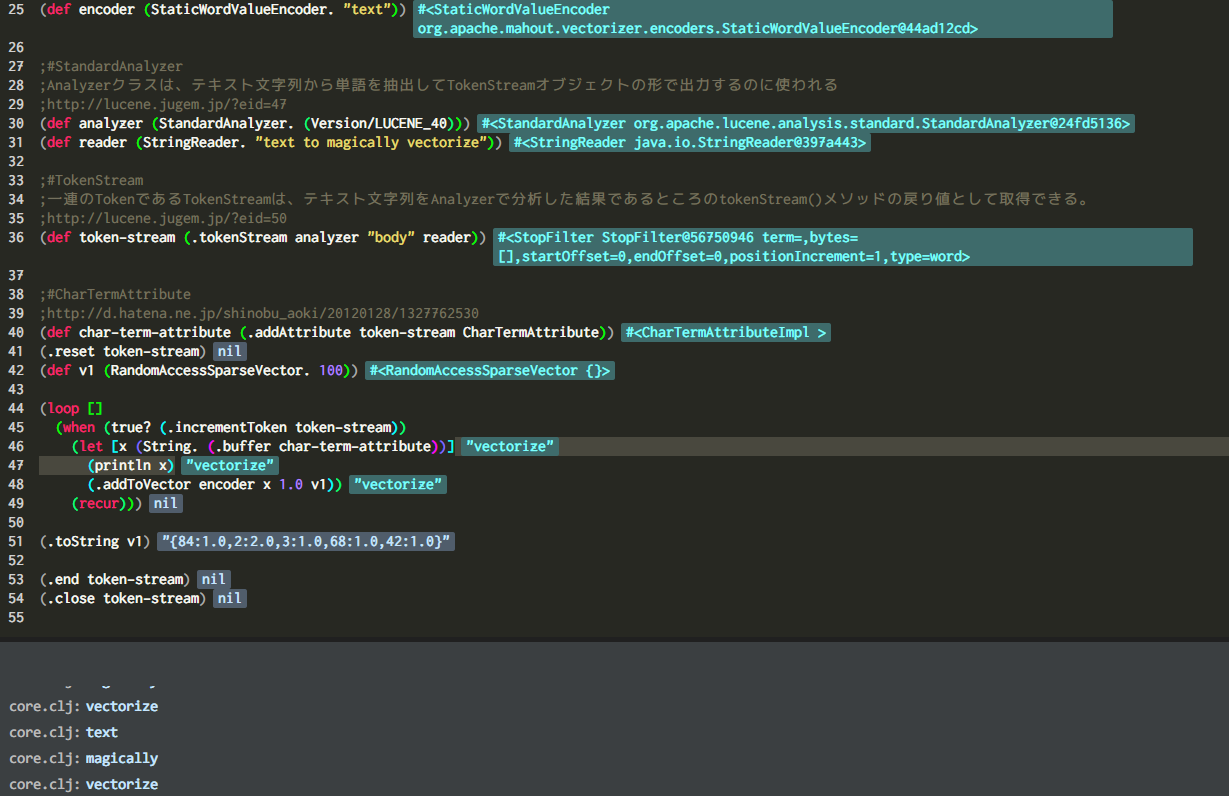
(ns mahout-clj.core
(:import [org.apache.mahout.vectorizer.encoders StaticWordValueEncoder]
[org.apache.lucene.analysis.standard StandardAnalyzer]
[org.apache.lucene.util Version]
[java.io StringReader]
[org.apache.lucene.analysis.tokenattributes CharTermAttribute]
[org.apache.mahout.math RandomAccessSparseVector]
[org.apache.mahout.math SequentialAccessSparseVector]))
;; http://www.programcreek.com/java-api-examples/index.php?api=org.apache.mahout.vectorizer.encoders.FeatureVectorEncoder
;#StaticWordValueEncoder
;
;Encodes a categorical values with an unbounded vocabulary.
;無制限の語彙でカテゴリ値を符号化する。
;Values are encoding by incrementing a few locations in the output vector with a weight that is either defaulted to 1 or that is looked up in a weight dictionary.
;値はデフォルト1もしくは重み付け辞書のどちらかの重みによって出力ベクトルのいくつかの場所をインクリメント
;↑全く分からん(´;ω;`)
;By default, only one probe is used which should be fine but could cause a decrease in the speed of learning because more features will be non-zero.
;デフォルトでは唯一の探査は上手く動くだろう。しかし、より多くのfeatureはゼロではないため、学習スピードの低下を引き起こす。
;If a large feature vector is used so that the probability of feature collisions is suitably small, then this can be decreased to 1.
;もし機能衝突の確率が適当に小さい大きなfeature vectorが使用された場合、1に減少させることが出来る。
;If a very small feature vector is used, the number of probes should probably be increased to 3.
;もしとても小さなfeature vectorが使用された場合、探査の数はおそらく3に増やす必要がある。
(def encoder (StaticWordValueEncoder. "text"))
;#StandardAnalyzer
;Analyzerクラスは、テキスト文字列から単語を抽出してTokenStreamオブジェクトの形で出力するのに使われる
;http://lucene.jugem.jp/?eid=47
(def analyzer (StandardAnalyzer. (Version/LUCENE_40)))
(def reader (StringReader. "text to magically vectorize"))
;#TokenStream
;一連のTokenであるTokenStreamは、テキスト文字列をAnalyzerで分析した結果であるところのtokenStream()メソッドの戻り値として取得できる。
;http://lucene.jugem.jp/?eid=50
(def token-stream (.tokenStream analyzer "body" reader))
;#CharTermAttribute
;http://d.hatena.ne.jp/shinobu_aoki/20120128/1327762530
(def char-term-attribute (.addAttribute token-stream CharTermAttribute))
(.reset token-stream)
(def v1 (RandomAccessSparseVector. 100))
(loop []
(when (true? (.incrementToken token-stream))
(let [x (String. (.buffer char-term-attribute))]
(println x)
(.addToVector encoder x 1.0 v1))
(recur)))
(.toString v1)
(.end token-stream)
(.close token-stream)
終わりに
なんやこれ、何がしたいんや(困惑)
kuromoji使えばええやんけ
あと、、、
・・・とりあえず英語が出来ないことを改めて認識した。