はじめに
CVPR 2018に採択されていた
Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN
という論文を読んだのですが,面白かったので解説記事を書いておきます.
arXiv: https://arxiv.org/abs/1803.04831
この論文を簡単に説明すると
RNNで問題となる勾配の爆発・消失問題を解消する新たなRNNのアーキテクチャIndRNNを提案.
IndRNNでは,1つの層にあるそれぞれのニューロンがそれぞれに独立した内部状態hを保持しており,独立して状態更新を行っている.
また,層ごとのそれぞれのneuronが独立に内部状態hを持つので,各層におけるそれぞれのneuronの解釈が容易になる.
Abstract
Recurrent neural networks (RNNs) have been widely used for processing sequential data.
However, RNNs are commonly difficult to train due to the well-known gradient vanishing and exploding problems and hard to learn long- term patterns.
Long short-term memory (LSTM) and gated recurrent unit (GRU) were developed to address these problems, but the use of hyperbolic tangent and the sigmoid action functions results in gradient decay over layers.
Consequently, construction of an efficiently trainable deep net- work is challenging. In addition, all the neurons in an RNN layer are entangled together and their behaviour is hard to interpret.
To address these problems, a new type of RNN, referred to as independently recurrent neural network (In- dRNN), is proposed in this paper, where neurons in the same layer are independent of each other and they are connected across layers.
We have shown that an IndRNN can be easily regulated to prevent the gradient exploding and vanish- ing problems while allowing the network to learn long-term dependencies.
Moreover, an IndRNN can work with non-saturated activation functions such as relu (rectified linear unit) and be still trained robustly.
Multiple IndRNNs can be stacked to construct a network that is deeper than the existing RNNs.
Experimental results have shown that the pro- posed IndRNN is able to process very long sequences (over 5000 time steps), can be used to construct very deep net- works (21 layers used in the experiment) and still be trained robustly.
Better performances have been achieved on various tasks by using IndRNNs compared with the traditional RNN.
IndRNNの概要
普通のRNNの状態更新式は以下のような式である.
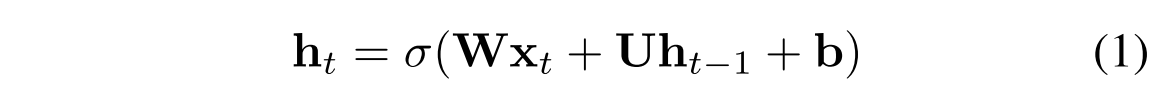
一方,IndRNNでは以下のような更新式を用いる.
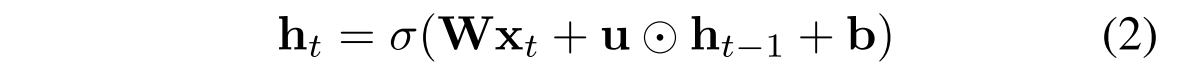
つまり,時刻tにおけるn番目のneuronは,以下のように更新される.
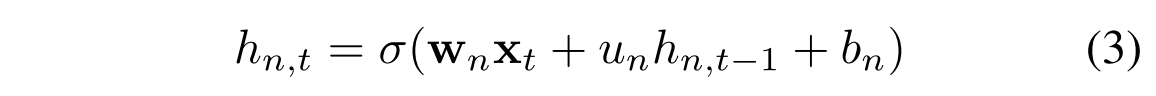
また,long term memoryを保っておくために,それぞれのneuronごとに学習幅の上限と下限を設定し,勾配による変化の上限値と下限値を設定している.
従来のRNNとIndRNNの関係についてだが,2層のIndRNNを用意して,片方の層の回帰パラメータの重みを0とすると,そのそうは単純な全結合層と同様であると見做すことができ,従来のRNNと構造的に同じとなるので,従来のRNNはIndRNNの特別なケースであると言える(活性化関数は線形とする).
以下は,単純なIndRNNの構造.
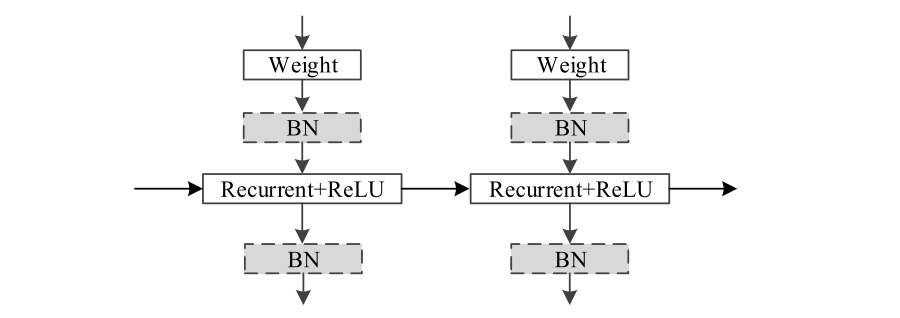
BNは"batch normalization"のこと.
LSTMベースのアーキテクチャでは,活性化関数としてtanhやシグモイドをしようしているため,層を重ねるたびに勾配の減衰が生じる.一方で,IndRNNではReluのような"non-saturated"(?)な活性化関数を使用しているため,層を重ねても勾配の減少は起こらない.
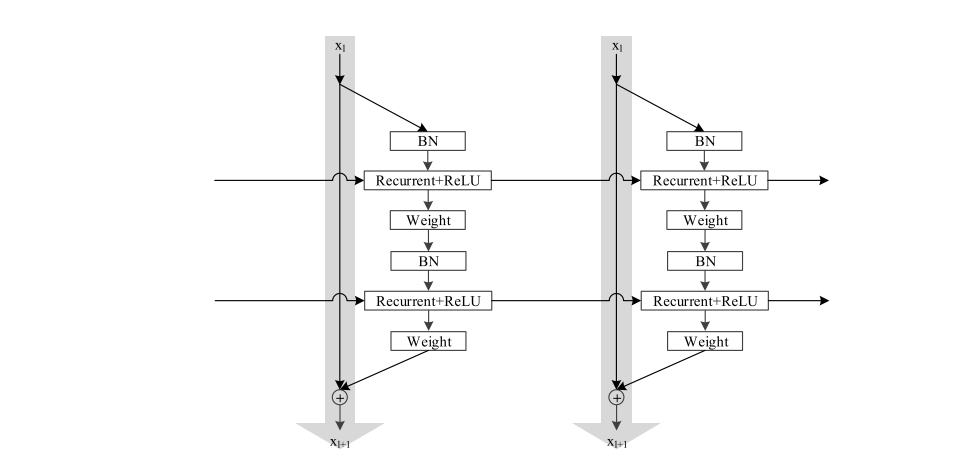
IndRNNは拡張性が高く,(既存のRNNがそうであったように,CNNなどの)どんなアーキテクチャにも拡張可能.ここでは例としてresidualなIndRNNの構造.
Results
実験1
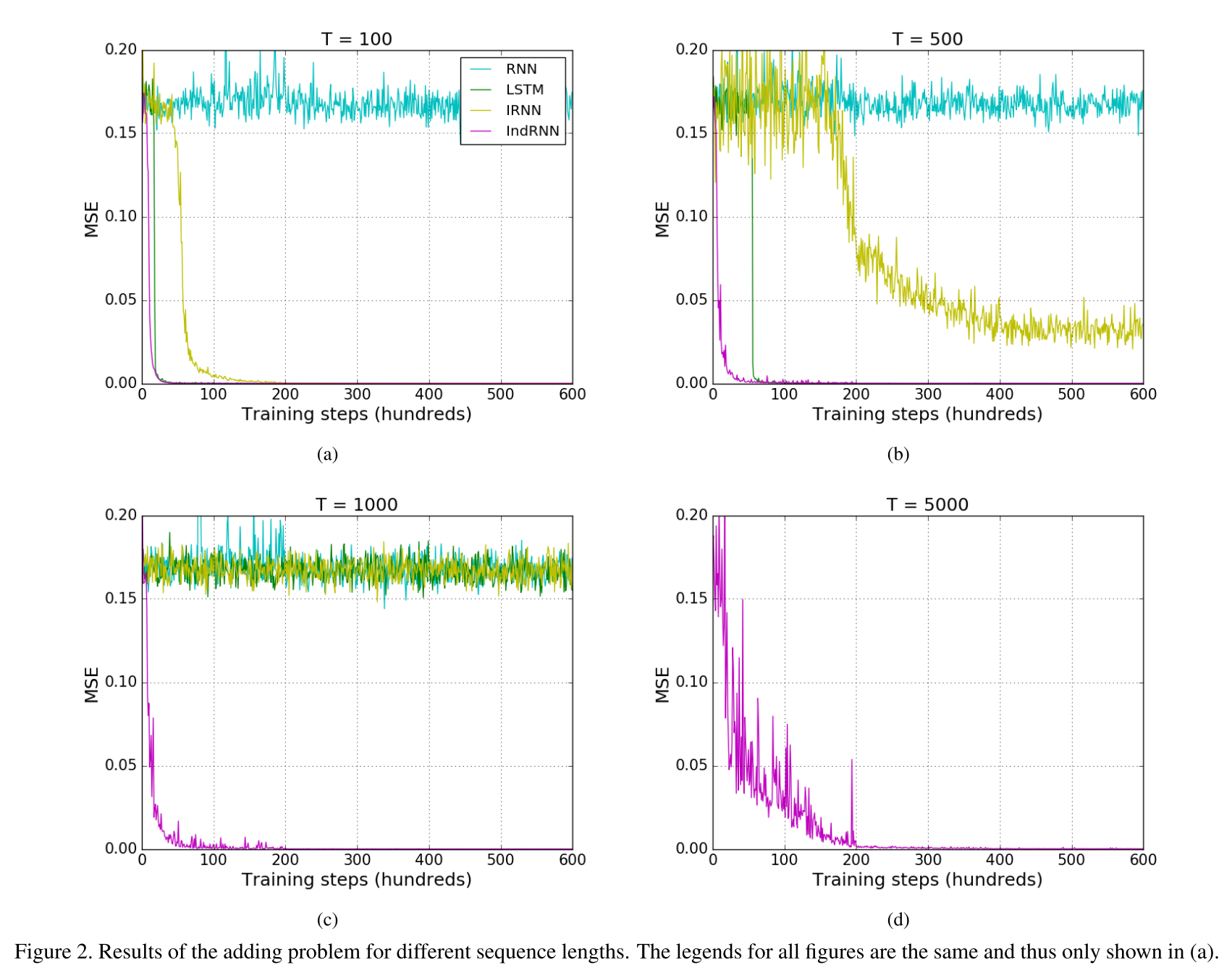
range(0,1)のsequence1と0,1のsequence2を入力とし,sequence2が1である時のsequence1の数の和を出力するタスク.Tはsequenceの長さ.
IndRNN以外のモデルは1層,IndRNNは2層のモデルを使用(他のモデルが1層で行う処理を2層で行なっているため).
RNN, LSTM, and two-layer IndRNNのパラメータの数はそれぞれ16K,67K,17K.
良いスコアが出ている.
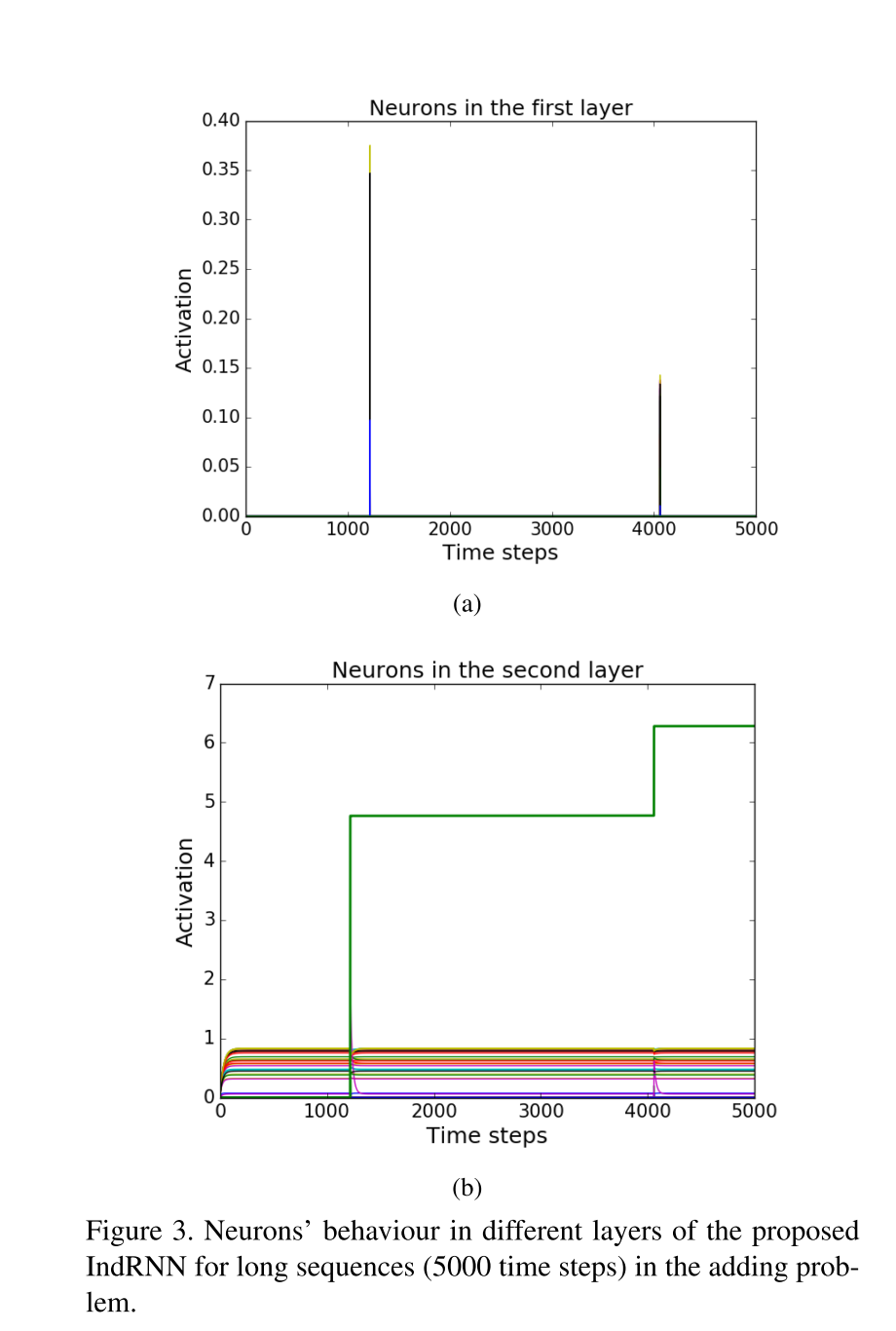
このタスクにおいて,層1,層2のニューロンの状態を可視化したもの.
層1のニューロンは,bitが立った瞬間に活性化しているのがわかる.層2のニューロンは,1つのニューロンのみが現在までの総和をkeepしており,他のニューロンは状態の変化が見られない.このことから,「層2のニューロンは1つで良い」という推測ができる.この推測をもとに,実際に層2のニューロンを1つだけにして学習を行なった結果が以下になる.
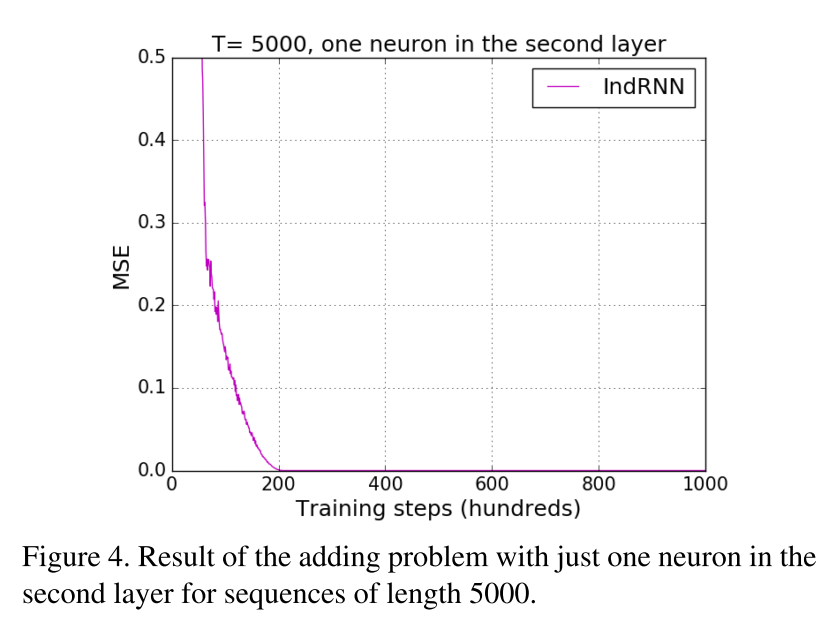
RNNsではこのような分析はできなかったが,IndRNNではこのようにニューロンの解釈が可能となる.
説明可能性〜〜〜.
実験2

sequencial MNISTのタスクにおける精度.
(sequencial MNISTとは,画像のpixelを1つずつ時系列データとして入力に与えて,ラベルを推測するタスク)
LSTMよりも精度が良い.
実験3
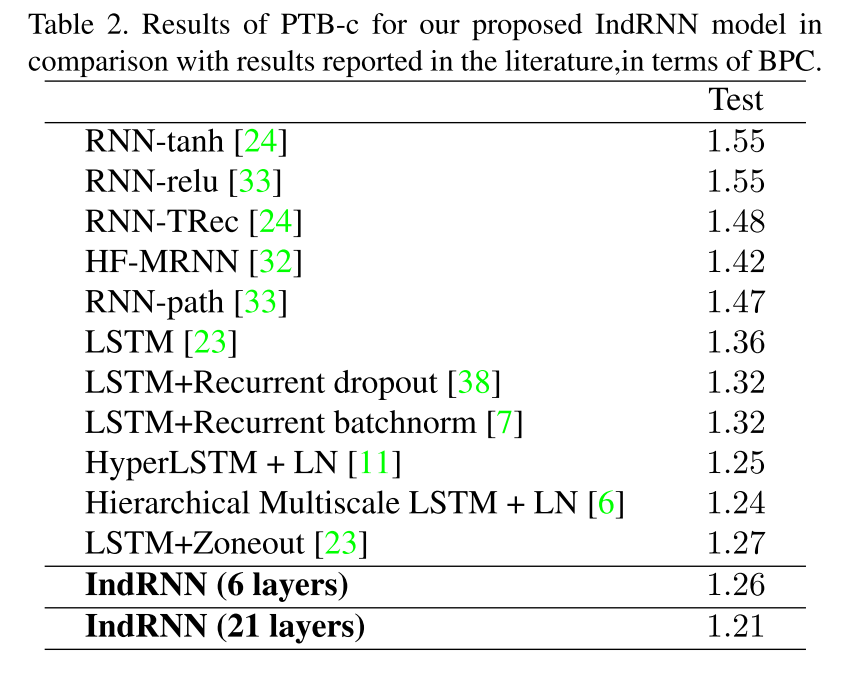
character-level Penn Treebank datasetを利用した言語モデルタスクにおける精度.
(文字羅列を入力とし,次の文字を推測するタスク)
良い.
実験4
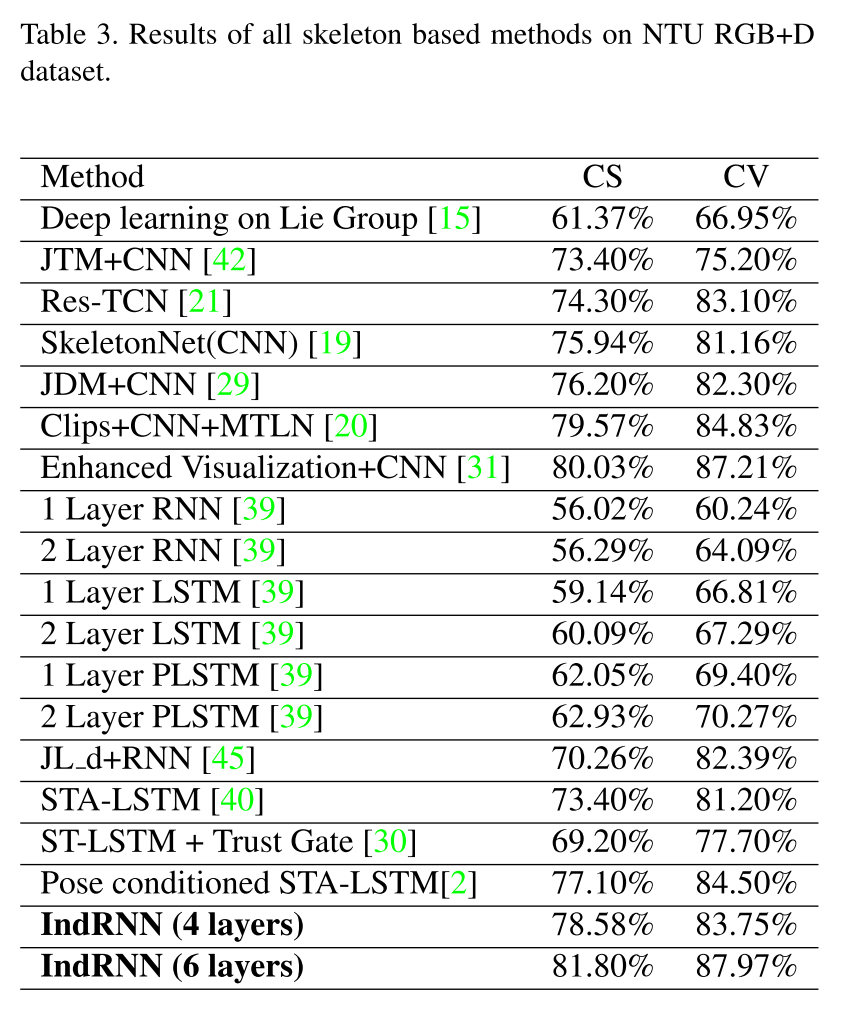
NTU RGB+D datasetを利用した三次元行動推定タスクにおける精度.
コメント
各neuronが独立に更新されるので,それぞれのneuronの回帰部分の重みを調節する事で例えばこのneuronは長期のデータを貯めて,このneuronは短期のデータを貯めて,みたいな分離が可能になったのがポイントかなーと感じた.
結構面白いと思う.