前置き
O'Reilly Japan の「PythonとJavaScriptではじめるデータビジュアライゼーション」を参考に、勉強をしています。
今回は、Beautiful Soupを使って、Webページの簡単なスクレイピングを実施します。
Beautiful Soupでスクレイピング
Yahoo! JAPANページのニュース欄に表示されている記事のタイトルを取得してみます。
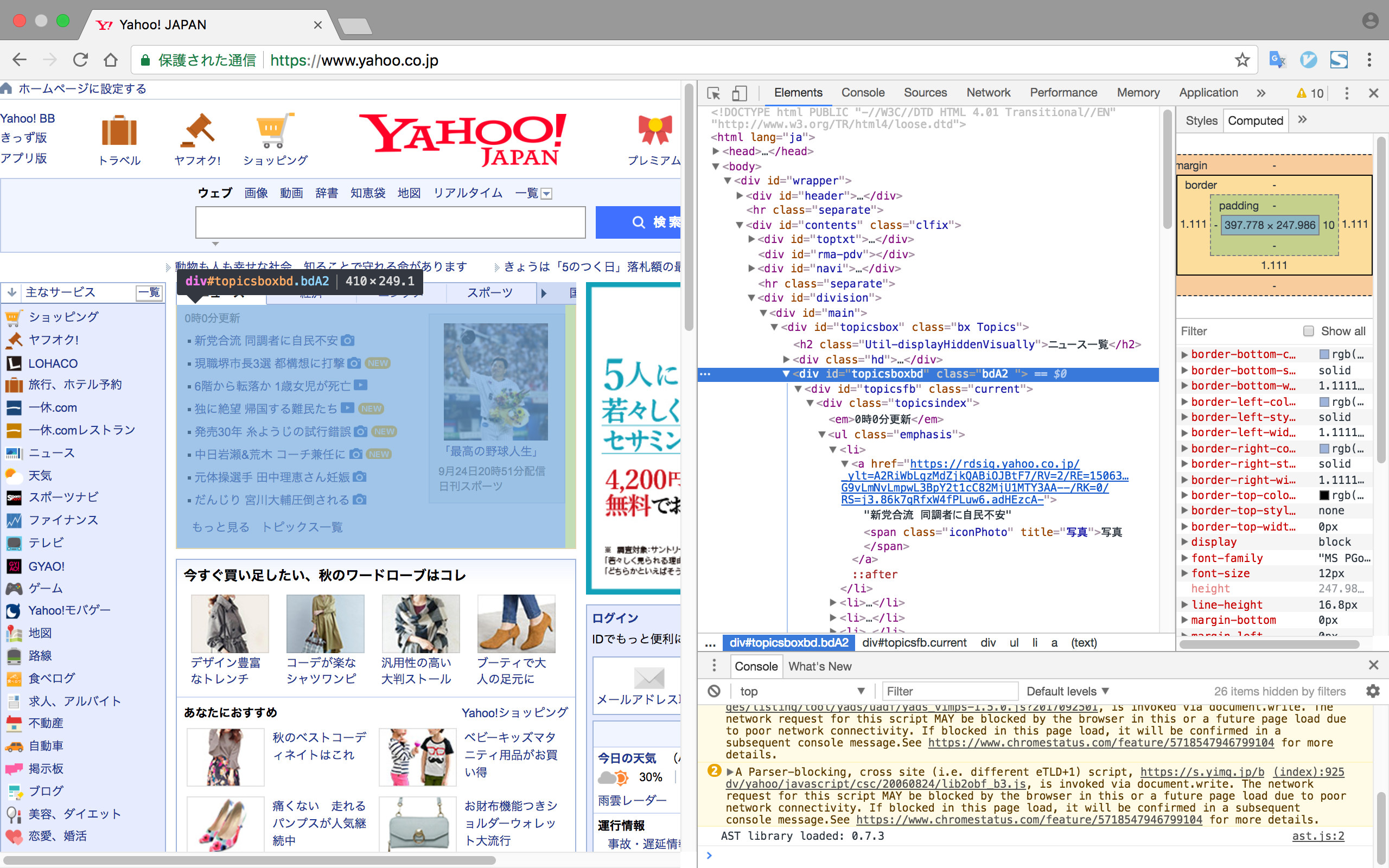
Chrome Developer Toolsにより、スクレイピング当時のタグや属性の情報が確認できるキャプチャを下記に添付します。
事前準備
pip install beautifulsoup4
pip install lxml
関数作成
WebページをBeautifulSoupオブジェクトにして取得する関数
bsoup4.py
from bs4 import BeautifulSoup
import requests
ua = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6)" \
"AppleWebKit/537.36 (KHTML, like Gecko)" \
"Chrome/60.0.3112.113"
def get_soup(url):
response = requests.get(url, headers={"User-Agent": ua})
return BeautifulSoup(response.content, "lxml")
「User-Agent」属性を設定しない場合、Yahoo! JAPANからは簡易なWebページが返却されました。
この属性を設定していない場合、Wikipedia等のようにリクエストを拒否するページもあるようです。
Webページのスクレイピング実施
>>> import bsoup4
>>>
>>> # BeautifulSoupオブジェクトの取得
>>> soup = bsoup4.get_soup('https://www.yahoo.co.jp/')
>>> # BeautifulSoupオブジェクトから、ニュース欄部分を抽出
>>> topicsfb = soup.find_all('div', attrs={'id':'topicsfb'})
>>> # ネストしているタグから、必要なデータを抽出
>>> for topic in topicsfb:
... for ultags in topic.find_all('ul', attrs={'class':'emphasis'}):
... for atags in ultags.find_all('a'):
... print(atags.text)
...
新党合流 同調者に自民不安写真
現職堺市長3選 都構想に打撃写真NEW
6階から転落か 1歳女児が死亡動画
独に絶望 帰国する難民たち動画NEW
発売30年 糸ようじの試行錯誤写真NEW
中日岩瀬&荒木 コーチ兼任に写真NEW
元体操選手 田中理恵さん妊娠写真
だんじり 宮川大輔圧倒される写真
※Webページのアイコン部分の文字が出力されてしまっています。
参考
Beautiful Soupドキュメント
http://tdoc.info/beautifulsoup/